MLflow系列1:MLflow入门教程(Python)
英文链接:https://mlflow.org/docs/latest/tutorial.html
本文链接:https://www.cnblogs.com/CheeseZH/p/11943280.html
这篇教程展示了如何:
- 训练一个线性回归模型
- 将训练代码打包成一个可复用可复现的模型格式
- 将模型部署成一个简单的HTTP服务用于进行预测
这篇教程使用的数据来自UCI的红酒质量数据集,主要用于根据红酒的PH值,酸度,残糖量等指标来评估红酒的质量。
我们会用到什么?
- 如果使用的是MacOS,官方推荐使用python3环境。
- 安装MLflow和scikit-learn,推荐两种安装方式:
- 安装MLflow及其依赖:
pip install mlflow[extras] - 分别安装MLflow(
pip install mlflow)和scikit-learn(pip install scikit-learn)
- 安装MLflow及其依赖:
- 安装conda
- 我安装的是miniconda
训练模型
我们要训练的线性回归模型包含两个超参数:alpha和l1_ratio。
我们使用下边的train.py代码进行训练
# The data set used in this example is from http://archive.ics.uci.edu/ml/datasets/Wine+Quality
# P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J. Reis.
# Modeling wine preferences by data mining from physicochemical properties. In Decision Support Systems, Elsevier, 47(4):547-553, 2009.
import os
import warnings
import sys
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
import mlflow
import mlflow.sklearn
import logging
logging.basicConfig(level=logging.WARN)
logger = logging.getLogger(__name__)
def eval_metrics(actual, pred):
rmse = np.sqrt(mean_squared_error(actual, pred))
mae = mean_absolute_error(actual, pred)
r2 = r2_score(actual, pred)
return rmse, mae, r2
if __name__ == "__main__":
warnings.filterwarnings("ignore")
np.random.seed(40)
# Read the wine-quality csv file from the URL
csv_url =\
'http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv'
try:
data = pd.read_csv(csv_url, sep=';')
except Exception as e:
logger.exception(
"Unable to download training & test CSV, check your internet connection. Error: %s", e)
# Split the data into training and test sets. (0.75, 0.25) split.
train, test = train_test_split(data)
# The predicted column is "quality" which is a scalar from [3, 9]
train_x = train.drop(["quality"], axis=1)
test_x = test.drop(["quality"], axis=1)
train_y = train[["quality"]]
test_y = test[["quality"]]
alpha = float(sys.argv[1]) if len(sys.argv) > 1 else 0.5
l1_ratio = float(sys.argv[2]) if len(sys.argv) > 2 else 0.5
with mlflow.start_run():
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
print("Elasticnet model (alpha=%f, l1_ratio=%f):" % (alpha, l1_ratio))
print(" RMSE: %s" % rmse)
print(" MAE: %s" % mae)
print(" R2: %s" % r2)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.sklearn.log_model(lr, "model")
这个例子用pandas,numpy,sklearn的API构建了一个简单的机器学习模型。通过MLflow tracking APIs来记录每次训练的信息,比如模型超参数和模型的评价指标。这个例子还将模型进行了序列化以便后续部署。
我们用不同的超参数训练几次模型
python train.py 0.5 0.5
python train.py 0.4 0.4
python train.py 0.6 0.6
每次运行完训练脚本,MLflow都会将信息保存在目录mlruns中。
对比模型
在mlruns目录的上级目录中运行下边的命令:
mlflow ui
然后就可以通过http://localhost:5000来查看每个版本的模型了。
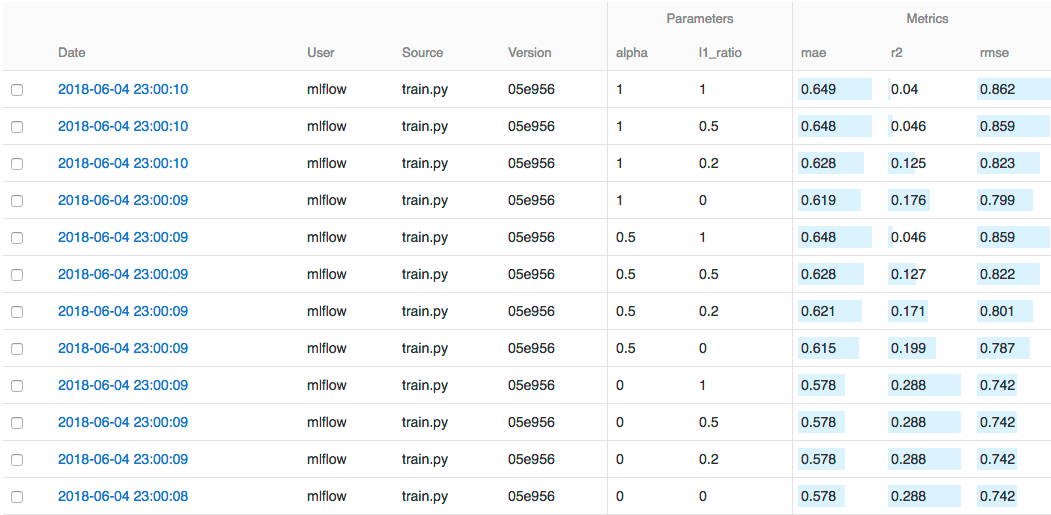
我们可以通过搜索功能快速筛选感兴趣的模型,比如搜索条件设置为metrics.rmse<0.8可以将rmse小于0.8的模型找出来,如果更复杂的搜索条件,可以下载CSV文件并用其他软件进行分析。
打包模型
我们已经写好了训练代码,可以将其打包提供给其他的数据科学家来复用,或者可以进行远程训练。
我们根据MLflow Projects的惯例来指定代码的依赖和代码的入口。比如创建一个sklearn_elasticnet_wine目录,在这个目录下创建一个MLproject文件来指定项目的conda依赖和包含两个参数alpha/l1_ratio的入口文件。
# sklearn_elasticnet_wine/MLproject
name: tutorial
conda_env: conda.yaml
entry_points:
main:
parameters:
alpha: float
l1_ratio: {type: float, default: 0.1}
command: "python train.py {alpha} {l1_ratio}"
conda.yaml文件列举了所有依赖:
# sklearn_elasticnet_wine/conda.yaml
name: tutorial
channels:
- defaults
dependencies:
- numpy=1.14.3
- pandas=0.22.0
- scikit-learn=0.19.1
- pip:
- mlflow
通过执行mlflow run examples/sklearn_elasticnet_wine -P alpha=0.42可以运行这个项目,MLflow会根据conda.yaml的配置在指定的conda环境中训练模型。
如果代码仓库的根目录有MLproject文件,也可以直接通过Github来运行,比如代码仓库:https://github.com/mlflow/mlflow-example。我们可以执行这个命令mlflow run git@github.com:mlflow/mlflow-example.git -P alpha=0.42来训练模型。
部署模型
我们通过MLflow Models来部署模型。一个MLflow Model是一种打包机器学习模型的标准格式,可以被用于多种下游工具,比如实时推理的REST API或者批量推理的Apache Spark。
在训练代码中,这行代码用于保存模型(原文称为artifact,暂且翻译成模型产品吧):
mlflow.sklearn.log_model(lr, "model")
我们可以在UI中通过点击Date链接来查看每次训练的模型产品,例如:
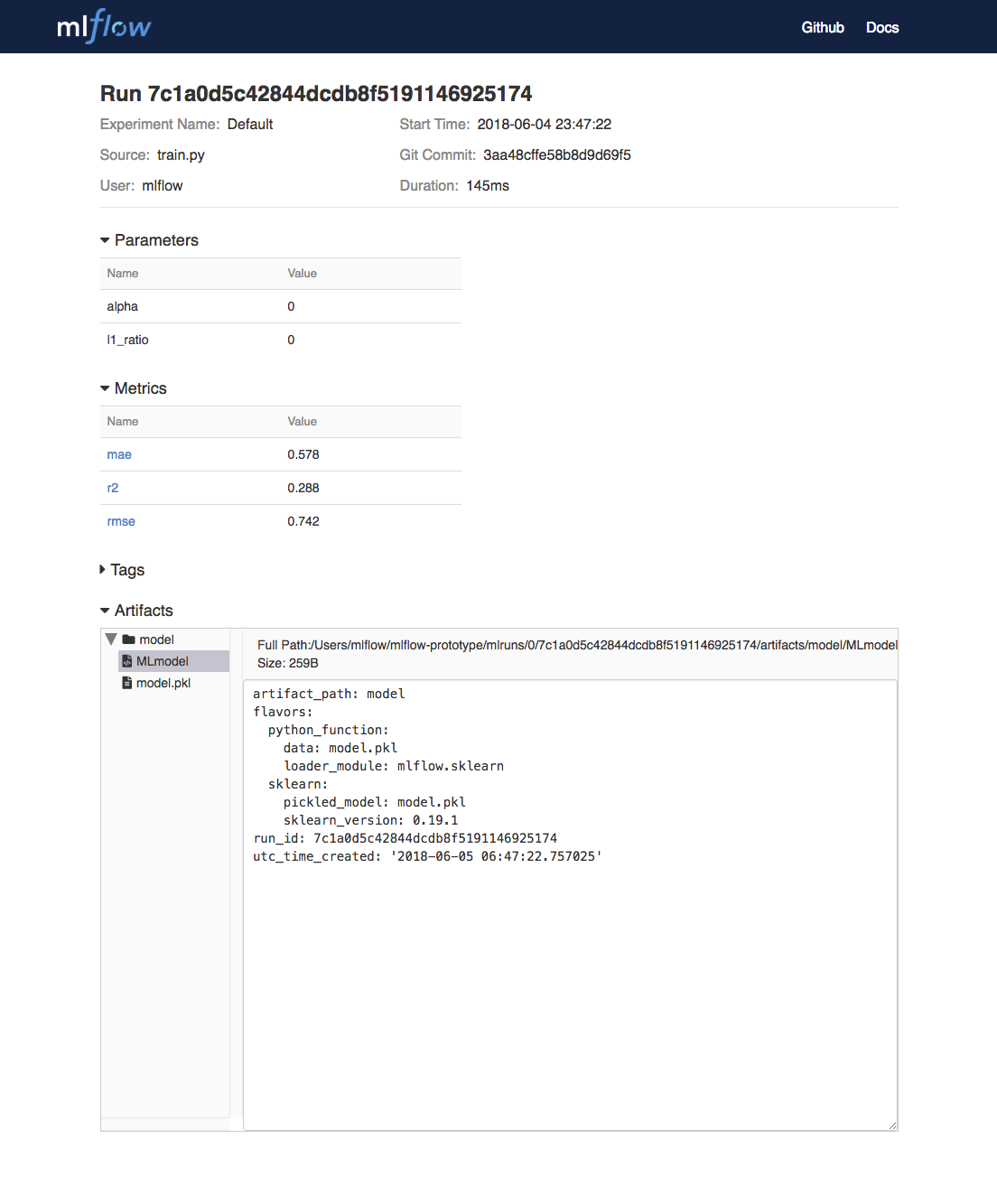
在底部,我们可以看到通过调用mlflow.sklearn.log_model产生了两个文件,位于类似目录/Users/mlflow/mlflow-prototype/mlruns/0/7c1a0d5c42844dcdb8f5191146925174/artifacts/model。MLmodel元数据文件是告诉MLflow如何加载模型。model.pkl文件是训练好的序列化的线性回归模型。
运行下边的命令,可以将模型部署成本地REST服务(要确保训练模型和部署模型所用的python版本一致,否则会报错):
# 需要替换成你自己的目录
mlflow models serve -m /Users/mlflow/mlflow-prototype/mlruns/0/7c1a0d5c42844dcdb8f5191146925174/artifacts/model -p 1234
部署好服务之后,可以通过curl命令发送json序列化的pandas DataFrame来测试下。模型服务器接受的数据格式可以参考MLflow deployment tools documentation.
curl -X POST -H "Content-Type:application/json; format=pandas-split" \
--data '{"columns":["alcohol", "chlorides", "citric acid", "density", "fixed acidity", "free sulfur dioxide", "pH", "residual sugar", "sulphates", "total sulfur dioxide", "volatile acidity"],"data":[[12.8, 0.029, 0.48, 0.98, 6.2, 29, 3.33, 1.2, 0.39, 75, 0.66]]}' \
http://127.0.0.1:1234/invocations
服务器会返回类似输出:
[6.379428821398614]
MLflow系列1:MLflow入门教程(Python)的更多相关文章
- BIML 101 - ETL数据清洗 系列 - BIML 快速入门教程 - 序
BIML 101 - BIML 快速入门教程 做大数据的项目,最花时间的就是数据清洗. 没有一个相对可靠的数据,数据分析就是无木之舟,无水之源. 如果你已经进了ETL这个坑,而且预算有限,并且有大量的 ...
- BIML 101 - ETL数据清洗 系列 - BIML 快速入门教程 - 连接数据库执行SQL语句
BIML 101 - BIML 快速入门教程 第一节 连接数据库执行SQL语句 本小节将用BIML建一个简单的可以执行的包. 新建一个biml文件,贴入下面的代码 1 <Biml xmlns=& ...
- 系列文章 -- OpenCV入门教程
<OpenCV3编程入门>内容简介&勘误&配套源代码下载 [OpenCV入门教程之十八]OpenCV仿射变换 & SURF特征点描述合辑 [OpenCV入门教程之 ...
- boost.python入门教程 ----python 嵌入c++
Python语言简介 Python是一种脚本语言.以开放的开发接口和独特的语法著称.尽管Python在国内引起注意只有几年的时间,但实际上Python出现于上世纪90年代(据www.python.or ...
- python gui tkinter快速入门教程 | python tkinter tutorial
本文首发于个人博客https://kezunlin.me/post/d5c57f56/,欢迎阅读最新内容! python tkinter tutorial Guide main ui messageb ...
- [ Python入门教程 ] Python字典数据类型及基本操作
字典是Python中重要的数据类型,字典是由"键-值"对组成的集合,"键-值"对之间用逗号隔开,包含在一对花括号中.字典中的"值"通过&qu ...
- [ Python入门教程 ] Python的控制语句
Python控制语句由条件语句.循环语句构成.控制语句根据条件表达式控制程序的流转.本章将介绍Python中控制语句的基本语法. 条件判断语句 (1)if条件语句 if语句用于检测某个条件是否成立.如 ...
- [ Python入门教程 ] Python基础语法
Python的语法非常简练,因此用Python编写的程序可读性强.容易理解.本章将介绍Python的基本语法和概念. Python文件类型 1.源代码.Python的源代码的扩展名以py结尾,可直接运 ...
- [ Python入门教程 ] Python文件基本操作
本文将python文件操作实例进行整理,以便后续取用. 文件打开和创建 Python中使用open()函数打开或创建文件.open()的声明如下: open(name[, mode[, bufferi ...
- [ Python入门教程 ] Python中JSON模块基本使用方法
JSON (JavaScript Object Notation)是一种使用广泛的轻量数据格式,Python标准库中的json模块提供了一种简单的方法来编码和解码JSON格式的数据.用于完成字符串和p ...
随机推荐
- Java中遇到Case cannot be resolved to a variable问题
Java中遇到Case cannot be resolved to a variable问题 记录一下这两天项目中遇到的一个小问题. 在项目中遇到一个问题,一直显示 Case cannot be ...
- jQuery循环之each()
/** *定义和用法:$(selector).each(function(index,element)) *each()函数会对每个匹配到的元素运行函数(返回false可终止循环). *each()函 ...
- C++学习(7)—— 函数提高
1. 函数默认参数 在C++中,函数的形参列表中的形参是可以有默认值的 语法:返回值类型 函数名 (参数=默认值){} 注意 如果某个位置已经有了默认参数,那么从这个位置往后,从左到右都必须有默认值 ...
- PAT 乙级 1071.小赌怡情 C++/Java
题目来源 常言道“小赌怡情”.这是一个很简单的小游戏:首先由计算机给出第一个整数:然后玩家下注赌第二个整数将会比第一个数大还是小:玩家下注 t 个筹码后,计算机给出第二个数.若玩家猜对了,则系统奖励玩 ...
- Linux 定时任务的控制台导出导入到文件
这个不但适用于定时任务,也适用于一般的脚本. 以前喜欢用>>这样的快捷方式, 今天看到用tee命令的,也记下. 55 23 * * * /bin/sh /sql_bak/restore_s ...
- 2019年杭电多校第二场 1002题Beauty Of Unimodal Sequence(LIS+单调栈)
题目链接 传送门 思路 首先我们对\(a\)正反各跑一边\(LIS\),记录每个位置在前一半的\(LIS\)中应该放的位置\(ans1[i]\),后一半的位置\(ans2[i]\). 对于字典序最小的 ...
- 离线安装python的ibm_db模块
目前手头的项目是一个UI自动化框架,其中有些模块的功能需要与DB2数据库交互,于是百度了一下python操作DB2的模块是 ibm_db. 然而我的工作机器是一台windows堡垒机,不能联网,固不能 ...
- 项目Alpha冲刺随笔集合
班级:软件工程1916|W 作业:项目Alpha冲刺 团队名称:SkyReach 目标:完成项目Alpha版本 项目Github地址 评审表 团队博客汇总 队员学号 队员姓名 个人博客地址 备注 22 ...
- Spring Boot 之:接口参数校验
Spring Boot 之:接口参数校验,学习资料 网址 SpringBoot(八) JSR-303 数据验证(写的比较好) https://qq343509740.gitee.io/2018/07/ ...
- react native 从创建到部署
source code: 开源库 rn源代码 native源代码 sourcecode tool: npm react-native vscode xocde.vscode ide+tools ...