总结day13 ----内置函数
内置函数
我们一起来看看python里的内置函数。什么是内置函数?就是Python给你提供的,拿来直接用的函数,比如print,input等等。截止到python版本3.6.2,现在python一共为我们提供了68个内置函数。它们就是python提供给你直接可以拿来使用的所有函数。这些函数有些我们已经用过了,有些我们还没用到过,还有一些是被封印了,必须等我们学了新知识才能解开封印的。那今天我们就一起来认识一下python的内置函数。这么多函数,我们该从何学起呢?
| 内置函数 | ||||
| abs() | dict() | help() | min() | setattr() |
| all() | dir() | hex() | next() | slice() |
| any() | divmod() | id() | object() | sorted() |
| ascii() | enumerate() | input() | oct() | staticmethod() |
| bin() | eval() | int() | open() | str() |
| bool() | exec() | isinstance() | ord() | sum() |
| bytearray() | filter() | issubclass() | pow() | super() |
| bytes() | float() | iter() | print() | tuple() |
| callable() | format() | len() | property() | type() |
| chr() | frozenset() | list() | range() | vars() |
| classmethod() | getattr() | locals() | repr() | zip() |
| compile() | globals() | map() | reversed() | __import__() |
| complex() | hasattr() | max() | round() | |
| delattr() | hash() | memoryview() | set() |
1.1作用域相关
locals :函数会以字典的类型返回当前位置的全部局部变量。
globals:函数以字典的类型返回全部全局变量。

a = 1
b = 2
print(locals())
print(globals())
# 这两个一样,因为是在全局执行的。 ########################## def func(argv):
c = 2
print(locals())
print(globals())
func(3) #这两个不一样,locals() {'argv': 3, 'c': 2}
#globals() {'__doc__': None, '__builtins__': <module 'builtins' (built-in)>, '__cached__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000024409148978>, '__spec__': None, '__file__': 'D:/lnh.python/.../内置函数.py', 'func': <function func at 0x0000024408CF90D0>, '__name__': '__main__', '__package__': None}
代码示例
1.2其他相关
1.2.1 字符串类型代码的执行 eval,exec,complie
eval:执行字符串类型的代码,并返回最终结果。
eval('2 + 2') # 4
n=81
eval("n + 4") # 85
eval('print(666)') # 666
exec:执行字符串类型的代码。
s = '''
for i in [1,2,3]:
print(i)
'''
exec(s)
compile:将字符串类型的代码编译。代码对象能够通过exec语句来执行或者eval()进行求值。
'''
参数说明: 1. 参数source:字符串或者AST(Abstract Syntax Trees)对象。即需要动态执行的代码段。 2. 参数 filename:代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。当传入了source参数时,filename参数传入空字符即可。 3. 参数model:指定编译代码的种类,可以指定为 ‘exec’,’eval’,’single’。当source中包含流程语句时,model应指定为‘exec’;当source中只包含一个简单的求值表达式,model应指定为‘eval’;当source中包含了交互式命令语句,model应指定为'single'。
'''
>>> #流程语句使用exec
>>> code1 = 'for i in range(0,10): print (i)'
>>> compile1 = compile(code1,'','exec')
>>> exec (compile1) >>> #简单求值表达式用eval
>>> code2 = '1 + 2 + 3 + 4'
>>> compile2 = compile(code2,'','eval')
>>> eval(compile2) >>> #交互语句用single
>>> code3 = 'name = input("please input your name:")'
>>> compile3 = compile(code3,'','single')
>>> name #执行前name变量不存在
Traceback (most recent call last):
File "<pyshell#29>", line 1, in <module>
name
NameError: name 'name' is not defined
>>> exec(compile3) #执行时显示交互命令,提示输入
please input your name:'pythoner'
>>> name #执行后name变量有值
"'pythoner'"
有返回值的字符串形式的代码用eval,没有返回值的字符串形式的代码用exec,一般不用compile。
1.2.2 输入输出相关 input,print
input:函数接受一个标准输入数据,返回为 string 类型。
print:打印输出。
''' 源码分析
def print(self, *args, sep=' ', end='\n', file=None): # known special case of print
"""
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
file: 默认是输出到屏幕,如果设置为文件句柄,输出到文件
sep: 打印多个值之间的分隔符,默认为空格
end: 每一次打印的结尾,默认为换行符
flush: 立即把内容输出到流文件,不作缓存
"""
''' print(111,222,333,sep='*') # 111*222*333 print(111,end='')
print(222) #两行的结果 111222 f = open('log','w',encoding='utf-8')
print('写入文件',file=f,flush=True)
1.2.3内存相关 hash id
hash:获取一个对象(可哈希对象:int,str,Bool,tuple)的哈希值。
print(hash(12322))
print(hash('123'))
print(hash('arg'))
print(hash('alex'))
print(hash(True))
print(hash(False))
print(hash((1,2,3))) '''
12322
-2996001552409009098
-4637515981888139739
2311495795356652852
1
0
2528502973977326415
'''
id:用于获取对象的内存地址。
print(id(123)) # 1674055952
print(id('abc')) # 2033192957072
1.2.3文件操作相关
open:函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写。
1.2.4模块相关__import__
__import__:函数用于动态加载类和函数 。
1.2.5帮助
help:函数用于查看函数或模块用途的详细说明。
print(help(list))
Help on class list in module builtins: class list(object)
| list() -> new empty list
| list(iterable) -> new list initialized from iterable's items
|
| Methods defined here:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __delitem__(self, key, /)
| Delete self[key].
|
| __eq__(self, value, /)
| Return self==value.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __getitem__(...)
| x.__getitem__(y) <==> x[y]
|
| __gt__(self, value, /)
| Return self>value.
|
| __iadd__(self, value, /)
| Implement self+=value.
|
| __imul__(self, value, /)
| Implement self*=value.
|
| __init__(self, /, *args, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self<value.
|
| __mul__(self, value, /)
| Return self*value.n
|
| __ne__(self, value, /)
| Return self!=value.
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| __repr__(self, /)
| Return repr(self).
|
| __reversed__(...)
| L.__reversed__() -- return a reverse iterator over the list
|
| __rmul__(self, value, /)
| Return self*value.
|
| __setitem__(self, key, value, /)
| Set self[key] to value.
|
| __sizeof__(...)
| L.__sizeof__() -- size of L in memory, in bytes
|
| append(...)
| L.append(object) -> None -- append object to end
|
| clear(...)
| L.clear() -> None -- remove all items from L
|
| copy(...)
| L.copy() -> list -- a shallow copy of L
|
| count(...)
| L.count(value) -> integer -- return number of occurrences of value
|
| extend(...)
| L.extend(iterable) -> None -- extend list by appending elements from the iterable
|
| index(...)
| L.index(value, [start, [stop]]) -> integer -- return first index of value.
| Raises ValueError if the value is not present.
|
| insert(...)
| L.insert(index, object) -- insert object before index
|
| pop(...)
| L.pop([index]) -> item -- remove and return item at index (default last).
| Raises IndexError if list is empty or index is out of range.
|
| remove(...)
| L.remove(value) -> None -- remove first occurrence of value.
| Raises ValueError if the value is not present.
|
| reverse(...)
| L.reverse() -- reverse *IN PLACE*
|
| sort(...)
| L.sort(key=None, reverse=False) -> None -- stable sort *IN PLACE*
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __hash__ = None None Process finished with exit code 0
1.2.6调用相关
callable:函数用于检查一个对象是否是可调用的。如果返回True,object仍然可能调用失败;但如果返回False,调用对象ojbect绝对不会成功。
>>>callable(0)
False
>>> callable("runoob")
False >>> def add(a, b):
... return a + b
...
>>> callable(add) # 函数返回 True
True
>>> class A: # 类
... def method(self):
... return 0
...
>>> callable(A) # 类返回 True
True
>>> a = A()
>>> callable(a) # 没有实现 __call__, 返回 False
False
>>> class B:
... def __call__(self):
... return 0
...
>>> callable(B)
True
>>> b = B()
>>> callable(b) # 实现 __call__, 返回 True
1.2.7查看内置属性
dir:函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用。如果参数不包含__dir__(),该方法将最大限度地收集参数信息。
>>>dir() # 获得当前模块的属性列表
['__builtins__', '__doc__', '__name__', '__package__', 'arr', 'myslice']
>>> dir([ ]) # 查看列表的方法
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__delslice__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getslice__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__setslice__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
1.3 迭代器生成器相关
range:函数可创建一个整数对象,一般用在 for 循环中。
next:内部实际使用了__next__方法,返回迭代器的下一个项目。
# 首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it)
print(x)
except StopIteration:
# 遇到StopIteration就退出循环
break
iter:函数用来生成迭代器(讲一个可迭代对象,生成迭代器)。
from collections import Iterable
from collections import Iterator
l = [1,2,3]
print(isinstance(l,Iterable)) # True
print(isinstance(l,Iterator)) # False l1 = iter(l)
print(isinstance(l1,Iterable)) # True
print(isinstance(l1,Iterator)) # True
1.4 基础数据类型相关
1.4.1数字相关(14)
数据类型(4):
bool :用于将给定参数转换为布尔类型,如果没有参数,返回 False。
int:函数用于将一个字符串或数字转换为整型。
print(int()) # 0
print(int('12')) # 12
print(int(3.6)) # 3
print(int('0100',base=2)) # 将2进制的 0100 转化成十进制。结果为 4
float:函数用于将整数和字符串转换成浮点数。
complex:函数用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。。
>>>complex(1, 2)
(1 + 2j) >>> complex(1) # 数字
(1 + 0j) >>> complex("1") # 当做字符串处理
(1 + 0j) # 注意:这个地方在"+"号两边不能有空格,也就是不能写成"1 + 2j",应该是"1+2j",否则会报错
>>> complex("1+2j")
(1 + 2j)
进制转换(3):
bin:将十进制转换成二进制并返回。
oct:将十进制转化成八进制字符串并返回。
hex:将十进制转化成十六进制字符串并返回。
print(bin(10),type(bin(10))) # 0b1010 <class 'str'>
print(oct(10),type(oct(10))) # 0o12 <class 'str'>
print(hex(10),type(hex(10))) # 0xa <class 'str'>
数学运算(7):
abs:函数返回数字的绝对值。
divmod:计算除数与被除数的结果,返回一个包含商和余数的元组(a // b, a % b)。
round:保留浮点数的小数位数,默认保留整数。
pow:求x**y次幂。(三个参数为x**y的结果对z取余)
print(abs(-5)) # 5 print(divmod(7,2)) # (3, 1) print(round(7/3,2)) # 2.33
print(round(7/3)) # 2
print(round(3.32567,3)) # 3.326 print(pow(2,3)) # 两个参数为2**3次幂
print(pow(2,3,3)) # 三个参数为2**3次幂,对3取余。
sum:对可迭代对象进行求和计算(可设置初始值)。
min:返回可迭代对象的最小值(可加key,key为函数名,通过函数的规则,返回最小值)。
max:返回可迭代对象的最大值(可加key,key为函数名,通过函数的规则,返回最大值)。
print(sum([1,2,3]))
print(sum((1,2,3),100)) print(min([1,2,3])) # 返回此序列最小值 ret = min([1,2,-5,],key=abs) # 按照绝对值的大小,返回此序列最小值
print(ret) dic = {'a':3,'b':2,'c':1}
print(min(dic,key=lambda x:dic[x]))
# x为dic的key,lambda的返回值(即dic的值进行比较)返回最小的值对应的键 print(max([1,2,3])) # 返回此序列最大值 ret = max([1,2,-5,],key=abs) # 按照绝对值的大小,返回此序列最大值
print(ret) dic = {'a':3,'b':2,'c':1}
print(max(dic,key=lambda x:dic[x]))
# x为dic的key,lambda的返回值(即dic的值进行比较)返回最大的值对应的键
1.4.2和数据结构相关(24)
列表和元祖(2)
list:将一个可迭代对象转化成列表(如果是字典,默认将key作为列表的元素)。
tuple:将一个可迭代对象转化成元祖(如果是字典,默认将key作为元祖的元素)。
l = list((1,2,3))
print(l) l = list({1,2,3})
print(l) l = list({'k1':1,'k2':2})
print(l) tu = tuple((1,2,3))
print(tu) tu = tuple([1,2,3])
print(tu) tu = tuple({'k1':1,'k2':2})
print(tu)
相关内置函数(2)
reversed:将一个序列翻转,并返回此翻转序列的迭代器。
slice:构造一个切片对象,用于列表的切片。
ite = reversed(['a',2,3,'c',4,2])
for i in ite:
print(i) li = ['a','b','c','d','e','f','g']
sli_obj = slice(3)
print(li[sli_obj]) sli_obj = slice(0,7,2)
print(li[sli_obj])
字符串相关(9)
str:将数据转化成字符串。
format:与具体数据相关,用于计算各种小数,精算等。
#字符串可以提供的参数,指定对齐方式,<是左对齐, >是右对齐,^是居中对齐
print(format('test', '<20'))
print(format('test', '>20'))
print(format('test', '^20')) #整形数值可以提供的参数有 'b' 'c' 'd' 'o' 'x' 'X' 'n' None
>>> format(3,'b') #转换成二进制
'11'
>>> format(97,'c') #转换unicode成字符
'a'
>>> format(11,'d') #转换成10进制
'11'
>>> format(11,'o') #转换成8进制
'13'
>>> format(11,'x') #转换成16进制 小写字母表示
'b'
>>> format(11,'X') #转换成16进制 大写字母表示
'B'
>>> format(11,'n') #和d一样
'11'
>>> format(11) #默认和d一样
'11' #浮点数可以提供的参数有 'e' 'E' 'f' 'F' 'g' 'G' 'n' '%' None
>>> format(314159267,'e') #科学计数法,默认保留6位小数
'3.141593e+08'
>>> format(314159267,'0.2e') #科学计数法,指定保留2位小数
'3.14e+08'
>>> format(314159267,'0.2E') #科学计数法,指定保留2位小数,采用大写E表示
'3.14E+08'
>>> format(314159267,'f') #小数点计数法,默认保留6位小数
'314159267.000000'
>>> format(3.14159267000,'f') #小数点计数法,默认保留6位小数
'3.141593'
>>> format(3.14159267000,'0.8f') #小数点计数法,指定保留8位小数
'3.14159267'
>>> format(3.14159267000,'0.10f') #小数点计数法,指定保留10位小数
'3.1415926700'
>>> format(3.14e+1000000,'F') #小数点计数法,无穷大转换成大小字母
'INF' #g的格式化比较特殊,假设p为格式中指定的保留小数位数,先尝试采用科学计数法格式化,得到幂指数exp,如果-4<=exp<p,则采用小数计数法,并保留p-1-exp位小数,否则按小数计数法计数,并按p-1保留小数位数
>>> format(0.00003141566,'.1g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留0位小数点
'3e-05'
>>> format(0.00003141566,'.2g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留1位小数点
'3.1e-05'
>>> format(0.00003141566,'.3g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留2位小数点
'3.14e-05'
>>> format(0.00003141566,'.3G') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留0位小数点,E使用大写
'3.14E-05'
>>> format(3.1415926777,'.1g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留0位小数点
'3'
>>> format(3.1415926777,'.2g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留1位小数点
'3.1'
>>> format(3.1415926777,'.3g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留2位小数点
'3.14'
>>> format(0.00003141566,'.1n') #和g相同
'3e-05'
>>> format(0.00003141566,'.3n') #和g相同
'3.14e-05'
>>> format(0.00003141566) #和g相同
'3.141566e-05'
bytes:用于不同编码之间的转化。
# s = '你好'
# bs = s.encode('utf-8')
# print(bs)
# s1 = bs.decode('utf-8')
# print(s1)
# bs = bytes(s,encoding='utf-8')
# print(bs)
# b = '你好'.encode('gbk')
# b1 = b.decode('gbk')
# print(b1.encode('utf-8'))
bytearry:返回一个新字节数组。这个数组里的元素是可变的,并且每个元素的值范围: 0 <= x < 256。
ret = bytearray('alex',encoding='utf-8')
print(id(ret))
print(ret)
print(ret[0])
ret[0] = 65
print(ret)
print(id(ret))
memoryview
ret = memoryview(bytes('你好',encoding='utf-8'))
print(len(ret))
print(ret)
print(bytes(ret[:3]).decode('utf-8'))
print(bytes(ret[3:]).decode('utf-8'))
ord:输入字符找该字符编码的位置
chr:输入位置数字找出其对应的字符
ascii:是ascii码中的返回该值,不是就返回/u...
# ord 输入字符找该字符编码的位置
# print(ord('a'))
# print(ord('中')) # chr 输入位置数字找出其对应的字符
# print(chr(97))
# print(chr(20013)) # 是ascii码中的返回该值,不是就返回/u...
# print(ascii('a'))
# print(ascii('中'))
repr:返回一个对象的string形式(原形毕露)。
# %r 原封不动的写出来
# name = 'taibai'
# print('我叫%r'%name) # repr 原形毕露
print(repr('{"name":"alex"}'))
print('{"name":"alex"}')
数据集合(3)
dict:创建一个字典。
set:创建一个集合。
frozenset:返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
相关内置函数(8)
len:返回一个对象中元素的个数。
sorted:对所有可迭代的对象进行排序操作。
L = [('a', 1), ('c', 3), ('d', 4),('b', 2), ]
sorted(L, key=lambda x:x[1]) # 利用key
[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
sorted(students, key=lambda s: s[2]) # 按年龄排序
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
sorted(students, key=lambda s: s[2], reverse=True) # 按降序
[('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
enumerate:枚举,返回一个枚举对象。
print(enumerate([1,2,3]))
for i in enumerate([1,2,3]):
print(i)
for i in enumerate([1,2,3],100):
print(i)
all:可迭代对象中,全都是True才是True
any:可迭代对象中,有一个True 就是True
# all 可迭代对象中,全都是True才是True
# any 可迭代对象中,有一个True 就是True
# print(all([1,2,True,0]))
# print(any([1,'',0]))
zip:函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。
l1 = [1,2,3,]
l2 = ['a','b','c',5]
l3 = ('*','**',(1,2,3))
for i in zip(l1,l2,l3):
print(i)
filter:过滤·。
#filter 过滤 通过你的函数,过滤一个可迭代对象,返回的是True
#类似于[i for i in range(10) if i > 3]
# def func(x):return x%2 == 0
# ret = filter(func,[1,2,3,4,5,6,7])
# print(ret)
# for i in ret:
# print(i)
map:会根据提供的函数对指定序列做映射。
>>>def square(x) : # 计算平方数
... return x ** 2
...
>>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方
[1, 4, 9, 16, 25]
>>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数
[1, 4, 9, 16, 25] # 提供了两个列表,对相同位置的列表数据进行相加
>>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])
[3, 7, 11, 15, 19]
匿名函数
匿名函数:为了解决那些功能很简单的需求而设计的一句话函数。
#这段代码
def calc(n):
return n**n
print(calc(10)) #换成匿名函数
calc = lambda n:n**n
print(calc(10))
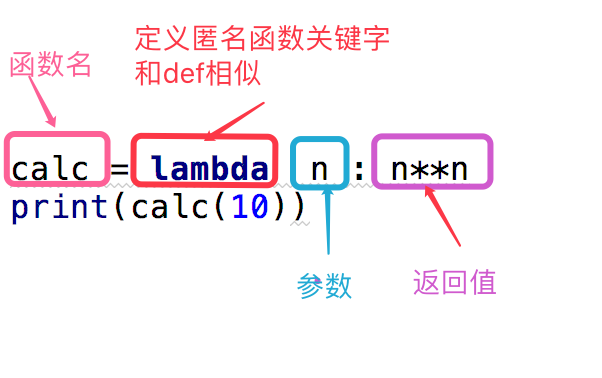
上面是我们对calc这个匿名函数的分析,下面给出了一个关于匿名函数格式的说明
函数名 = lambda 参数 :返回值 #参数可以有多个,用逗号隔开
#匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值
#返回值和正常的函数一样可以是任意数据类型
我们可以看出,匿名函数并不是真的不能有名字。
匿名函数的调用和正常的调用也没有什么分别。 就是 函数名(参数) 就可以了~~~
匿名函数与内置函数举例:
l=[3,2,100,999,213,1111,31121,333]
print(max(l)) dic={'k1':10,'k2':100,'k3':30} print(max(dic))
print(dic[max(dic,key=lambda k:dic[k])])
res = map(lambda x:x**2,[1,5,7,4,8])
for i in res:
print(i)
res = filter(lambda x:x>10,[5,8,11,9,15])
for i in res:
print(i)
总结day13 ----内置函数的更多相关文章
- python全栈开发-Day13 内置函数
一.内置函数 注意:内置函数id()可以返回一个对象的身份,返回值为整数. 这个整数通常对应与该对象在内存中的位置,但这与python的具体实现有关,不应该作为对身份的定义,即不够精准,最精准的还是以 ...
- day13 内置函数
参考资料: https://www.processon.com/view/link/5b4ee15be4b0edb750de96ac 内置函数: 作⽤域相关: locals() 返回当前作用域 ...
- day13内置函数
内置函数 一.三元表达式 def max2(x,y): if x>y: return x else: return y res=max2(10,11) print(res) 三元表达式仅应用于: ...
- day13 内置函数二 递归,匿名函数,二分法
.匿名函数(名字统一叫lambda) .语法 lambda 参数:返回值 .参数可以有多个,用逗号隔开 .只能写一行,执行结束后直接返回值 4返回值和正常函数一样,可以是任意值 .列: f=lambd ...
- day13 内置函数一
见如下网址 https://www.processon.com/mindmap/5bdc3f49e4b0844e0bc6b5d3
- day13——重要内置函数、匿名函数、闭包
day13 内置函数2 重要的 abs():求绝对值--返回的都是正数 # lst = [-1,-2,-3] # for i in lst: # print(abs(i)) # print([abs( ...
- 记录我的 python 学习历程-Day13 匿名函数、内置函数 II、闭包
一.匿名函数 以后面试或者工作中经常用匿名函数 lambda,也叫一句话函数. 课上练习: # 正常函数: def func(a, b): return a + b print(func(4, 6)) ...
- day11 - 15(装饰器、生成器、迭代器、内置函数、推导式)
day11:装饰器(装饰器形成.装饰器作用.@语法糖.原则.固定模式) 装饰器形成:最简单的.有返回值的.有一个参数的.万能参数 函数起的作用:装饰器用于在已经完成的函数前后增加功能 语法糖:使代码变 ...
- Entity Framework 6 Recipes 2nd Edition(11-12)译 -> 定义内置函数
11-12. 定义内置函数 问题 想要定义一个在eSQL 和LINQ 查询里使用的内置函数. 解决方案 我们要在数据库中使用IsNull 函数,但是EF没有为eSQL 或LINQ发布这个函数. 假设我 ...
随机推荐
- xshell上传下载文件(Windows、Linux)
经常有这样的需求,我们在Windows下载的软件包,如何上传到远程Linux主机上?还有如何从Linux主机下载软件包到Windows下:之前我的做法现在看来好笨好繁琐,不过也达到了目的,笨人有本方法 ...
- idea中代码补全
在IDEA中,默认的代码自动提示不够智能,现在配置成更加智能的方式. File-Settings-Editor-General-Code Completion中 把最上面的大小写敏感度改成none,下 ...
- 【分享】Java后台开发精选知识图谱
地址 引言: 学习一个新的技术时,其实不在于跟着某个教程敲出了几行.几百行代码,这样你最多只能知其然而不知其所以然,进步缓慢且深度有限,最重要的是一开始就对整个学习路线有宏观.简洁的认识,确定大的学习 ...
- metasploit-数据库支持
db_status db_disconnect db_connect 用户名:口令@服务器地址:端口/数据库名称 createdb msf4 -E UTF8 -T template0 -o msf3 ...
- linux每天一小步---touch命令详解
1 命令功能: 创建文件和修改文件或者目录的时间戳 2 命令语法: touch [选项] [文件名或者目录名] 3 命令参数: -a 只修改文件的access(访问)时间. -c 或-- ...
- [Selenium With C#基础教程] Lesson-02 Web元素定位
作者:Surpassme 来源:http://www.jianshu.com/p/cfd4ed1daabd 声明:本文为原创文章,如需转载请在文章页面明显位置给出原文链接,谢谢. 使用Selenium ...
- jmeter 正则表达式
1.抓好请求,对着接口文档筛选好请求后,添加正则表达式 2.查看结果树,找到要提取的参数 3.书写正则 4.关联一下 5.直接跑一边就好,包成功,从数据库取的话,如果name:user,就直接参数化: ...
- 終于解決调用wordpress 4.3 xmlrpc api 发布包含分类的文章时返回“抱歉,文章类型不支持您的分类法”错误的問題
這個問題我找了很多資料都沒有明說是如何解決,后來突發奇想得出我的解決方案如下,所以特此記錄一下: object postId = blogService.NewPost(0,"admin&q ...
- Github 的注册教程和初步使用体验
我叫许晴,是网工143的学生,学号是1413042064,兴趣包括手绘,看书和手游.学习过c++和汇编语言课程,但在编程方面没什么独立实践经验. 我的Githup用户名是 XQ123 .下面是我在gi ...
- TFS文件编码检查机制和修改(Team Foundation Server 2013)
TFS的版本控制系统会自动按照下面的标准检测代码文件的编码格式: 1. 首先,如果代码文件包含了BOM部分,则使用BOM中制定的编码格式打开文档 什么是BOM (Byte order mark)? h ...