MapReduce(五) mapreduce的shuffle机制 与 Yarn
一、shuffle机制
1、概述
(1)MapReduce 中, map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 Shuffle;
(2)Shuffle: 数据混洗 ——(核心机制:数据分区,排序,缓存);
(3) 具体来说:就是将 maptask 输出的处理结果数据,分发给 reducetask,并在分发的过程 中,对数据按 key 进行了分区和排序;
2、主要流程

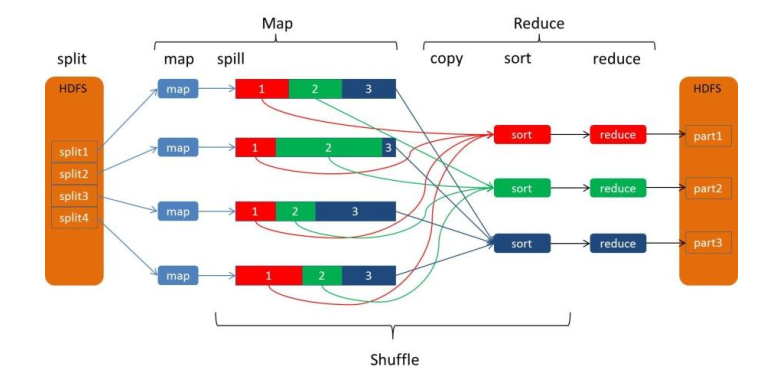
3、详细流程
(1)maptask 收集我们的 map()方法输出的 kv 对,放到内存缓冲区中
(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件 (至少一个)
(3)多个溢出文件会被合并成大的溢出文件 (慢慢排序,不是都结束之后才排序)
(4)在溢出过程中,及合并的过程中,都要调用 partitoner 进行分组和针对 key 进行排序
(5)reducetask 根据自己的分区号,去各个 maptask 机器上取相应的结果分区数据
(6)reducetask 会取到同一个分区的来自不同 maptask 的结果文件, reducetask 会将这些文件 再进行合并(归并排序)
(7)合并成大文件后, shuffle 的过程也就结束了,后面进入 reducetask 的逻辑运算过程(从 文件中取出一个一个的键值对 group,调用用户自定义的 reduce()方法)
Shuffle 中的缓冲区大小会影响到 mapreduce 程序的执行效率,原则上说,缓冲区越大,磁 盘 io 的次数越少,执行速度就越快
缓冲区的大小可以通过参数调整, 参数: io.sort.mb 默认 100M (溢出条件0.8(80%))
4、流程图
二、Yarn
1、yarn 概述
YARN( Yet Another Resource Negotiator)
Yarn 是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作 系统平台,而 MapReduce 等运算程序则相当于运行于操作系统之上的应用程序
(1)yarn 并不清楚用户提交的程序的运行机制
(2)yarn 只提供运算资源的调度(用户程序向 yarn 申请资源, yarn 就负责分配资源)
(3)yarn 中的主管角色叫 ResourceManager
(4)yarn 中具体提供运算资源的角色叫 NodeManager
(5)这样一来, yarn 其实就与运行的用户程序完全解耦,就意味着 yarn 上可以运行各种类型 的分布式运算程序( mapreduce 只是其中的一种),比如 mapreduce、 storm 程序, spark 程序, tez ……
(6)所以, spark、 storm 等运算框架都可以整合在 yarn 上运行,只要他们各自的框架中有符 合 yarn 规范的资源请求机制即可
(7)yarn 就成为一个通用的资源调度平台,从此,企业中以前存在的各种运算集群都可以整 合在一个物理集群上,提高资源利用率,方便数据共享
2、yarn的重要概念
(1)ResourceManager
ResourceManager 是基于应用程序对集群资源的需求进行调度的 Yarn 集群主控节点,负责协 调和管理整个集群( 所有 NodeManager) 的资源,响应用户提交的不同类型应用程序的解 析,调度,监控等工作。ResourceManager 会为每一个 Application 启动一个 ApplicationMaster,
并且 ApplicationMaster 分散在各个 NodeManager 节点
它主要由两个组件构成:调度器( Scheduler)和应用程序管理器( ApplicationsManager, ASM)
(2)NodoManager
NodeManager 是 YARN 集群当中真正资源的提供者,是真正执行应用程序的容器的提供者, 监控应用程序的资源使用情况( CPU,内存,硬盘,网络), 并通过心跳向集群资源调度器 ResourceManager 进行汇报。
(3)ApplicationMaster (申请容器、监控任务)
ApplicationMaster 对应一个应用程序,职责是: 向资源调度器申请执行任务的资源容器,运 行任务,监控整个任务的执行,跟踪整个任务的状态,处理任务失败以异常情况
(4)Container
Container 是一个抽象出来的逻辑资源单位。 它封装了一个节点上的 CPU,内存,磁盘,网络等信息, MapReduce 程序的所有 task 都是在一个容器里执行完成的,容器的大小是可以 动态调整的
(5)ASM
应用程序管理器 ASM 负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协 商资源以启动 ApplicationMaster、监控 ApplicationMaster 运行状态并在失败时重新启动它等
(6)Scheduler
调度器根据应用程序的资源需求进行资源分配,不参与应用程序具体的执行和监控等工作 资源分配的单位就是 Container,调度器是一个可插拔的组件, 用户可以根据自己的需求实 现自己的调度器。 YARN 本身为我们提供了多种直接可用的调度器,比如 FIFO, Fair Scheduler
和 Capacity Scheduler 等
3、yarn的架构

4、 yarn作业执行流程
YARN 作业执行流程:
(1)用户向 YARN 中提交应用程序,其中包括 ApplicationMaster 程序,启动 ApplicationMaster 的命令,用户程序等。
(2) ResourceManager 为该程序分配第一个 Container,并与对应的 NodeManager 通讯,要求 它在这个 Container 中启动应用程序 ApplicationMaster。
(3)ApplicationMaster 首先向 ResourceManager 注册,这样用户可以直接通过 ResourceManager 查看应用程序的运行状态,然后将为各个任务申请资源,并监控它的运行状态,直到运行结 束,重复 4 到 7 的步骤。
(4) ApplicationMaster 采用轮询的方式通过 RPC 协议向 ResourceManager 申请和领取资源。
(5)一旦 ApplicationMaster 申请到资源后,便与对应的 NodeManager 通讯,要求它启动任务。
(6)NodeManager 为任务设置好运行环境(包括环境变量、 JAR 包、二进制程序等)后,将 任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
(7)各个任务通过某个 RPC 协议向 ApplicationMaster 汇报自己的状态和进度,以让 ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务败的时候重新启动任务。
(8)应用程序运行完成后, AM 向 RM 注销并关闭自己。
MapReduce(五) mapreduce的shuffle机制 与 Yarn的更多相关文章
- mapreduce (五) MapReduce实现倒排索引 修改版 combiner是把同一个机器上的多个map的结果先聚合一次
(总感觉上一篇的实现有问题)http://www.cnblogs.com/i80386/p/3444726.html combiner是把同一个机器上的多个map的结果先聚合一次现重新实现一个: 思路 ...
- MapReduce框架中的Shuffle机制
Shuffle是map和reduce中间的数据调度过程,包括:缓存.分区.排序等. Shuffle数据调度过程: map task处理hdfs文件,调用map()方法,map task的collect ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- MapReduce框架原理--Shuffle机制
Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的.系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle. partition分区 ...
- MapReduce实例2(自定义compare、partition)& shuffle机制
MapReduce实例2(自定义compare.partition)& shuffle机制 实例:统计流量 有一份流量数据,结构是:时间戳.手机号.....上行流量.下行流量,需求是统计每个用 ...
- mapreduce.shuffle set in yarn.nodemanager.aux-services is invalid
15/07/01 20:14:41 FATAL containermanager.AuxServices: Failed to initialize mapreduce.shuffle java.la ...
- MapReduce详解及shuffle阶段
hadoop1.x和hadoop2.x的区别: Hadoop1.x版本: 内核主要由Hdfs和Mapreduce两个系统组成,其中Mapreduce是一个离线分布式计算框架,由一个JobTracker ...
- MapReduce工作流程及Shuffle原理概述
引言: 虽然MapReduce计算框架简化了分布式程序设计,将所有的并行程序均需要关注的设计细节抽象成公共模块并交由系统实现,用户只需关注自己的应用程序的逻辑实现,提高了开发效率,但是开发如果对Map ...
- hadoop的mapReduce和Spark的shuffle过程的详解与对比及优化
https://blog.csdn.net/u010697988/article/details/70173104 大数据的分布式计算框架目前使用的最多的就是hadoop的mapReduce和Spar ...
随机推荐
- sql server 批量备份数据库
很多时候,我们都需要将数据库进行备份,当服务器上数据库较多时,不可能一个数据库创建一个定时任务进行备份,这时,就需要进行批量的数据库备份操作,好了,废话不多说,具体实现语句如下: --开启文件夹权限 ...
- TPO 03 - Architecture
TPO 03 - Architecture Architecture is the art and science of designing structures that[主语是Architectu ...
- Unity标准材质官方教程合集
- centos7.2部署docker-17.06.0-ce的bug:Error response from daemon: oci runtime error: container_linux.go:262: starting container process caused "process_linux.go:339: container init caused \"\"".
现象: 操作系统:centos 7.2 kernel 3.10.0-327.el7.x86_64 mesos:1.3.0 docker:docker-17.06.0-ce 在做mesos验证时,通过m ...
- [题解] 洛谷 P3603 雪辉
模拟赛中遇到了这个题,当时我这个沙雕因为把一个\(y\)打成了\(x\)而爆零.回来重新写这道题,莫名其妙的拿了rank1... 我的解法与其他几位的题解有些不同我太蒻了.并没有选取所谓的关键点,而是 ...
- 亮眼的购物季数据,高涨的 Amazon Prime
依照往年的惯例,亚马逊公布了 2013 购物季的销售数据.据 The Verge 的报道,今年,仅仅网购星期一(Cyber Monday)一天就在全球范围内销售出 3680 万件商品,而去年这一数字为 ...
- 20162328蔡文琛 week06 大二
20162328 2017-2018-1 <程序设计与数据结构>第6周学习总结 教材学习内容总结 队列元素按FIFO的方式处理----最先进入的元素最先离开. 队列是保存重复编码k值得一种 ...
- 扩展欧几里德 SGU 106
题目链接:http://acm.sgu.ru/problem.php?contest=0&problem=106 题意:求ax + by + c = 0在[x1, x2], [y1, y2 ...
- maven 添加tomcat依赖
https://my.oschina.net/angel243/blog/178554
- c 读取文本
#include <stdio.h> #include <stdlib.h> #include <string.h> #define max 10 #define ...