MySQL专题3 SQL 优化
这两天去京东面试,面试官问了我一个问题,如何优化SQL
我上网查了一下资料,找到了不少方法,做一下记录
(一)、 首先使用慢查询分析 通过Mysql 的Slow Query log 可以找到哪些SQL运行很慢。耗时间
在my.ini中:
long_query_time=1
log-slow-queries=d:\mysql5\logs\mysqlslow.log
把超过1秒的记录在慢查询日志中
可以用mysqlsla来分析之。也可以在mysqlreport中,有如
DMS分别分析了select ,update,insert,delete,replace等所占的百份比
慢查询日志是将mysql服务器中影响数据库性能的相关SQL语句记录到日志文件,通过对这些特殊的SQL语句分析,改进以达到提高数据库性能的目的。
通过使用--slow_query_log[={0|1}]选项来启用慢查询日志。所有执行时间超过long_query_time秒的SQL语句都会被记录到慢查询日志。
缺省情况下hostname-slow.log为慢查询日志文件安名,存放到数据目录,同时缺省情况下未开启慢查询日志。
缺省情况下数据库相关管理型SQL(比如OPTIMIZE TABLE、ANALYZE TABLE和ALTER TABLE)不会被记录到日志。
对于管理型SQL可以通过--log-slow-admin-statements开启记录管理型慢SQL。
mysqld在语句执行完并且所有锁释放后记入慢查询日志。记录顺序可以与执行顺序不相同。获得初使表锁定的时间不算作执行时间。
参考:MySQL 慢查询日志(Slow Query Log)
(二)、找到了SQL之后 ,通过Mysql 的查询分析器进行分析;
可以通过explain 方法 即在执行的sql前面加上explain,
MySQL性能分析及explain用法的知识是本文我们主要要介绍的内容,接下来就让我们通过一些实际的例子来介绍这一过程,希望能够对您有所帮助。
使用explain语句去查看分析结果
如explain select * from test1 where id=1;会出现:id selecttype table type possible_keys key key_len ref rows extra各列。
其中,
type=const表示通过索引一次就找到了;
key=primary的话,表示使用了主键;
type=all,表示为全表扫描;
key=null表示没用到索引。type=ref,因为这时认为是多个匹配行,在联合查询中,一般为REF。
参考: 查看SQL语句执行效率
(三)、使用 show profiles 分析查询时间,
Show profiles是5.0.37之后添加的,要想使用此功能,要确保版本在5.0.37之后。
Query Profiler是MYSQL自带的一种query诊断分析工具,通过它可以分析出一条SQL语句的性能瓶颈在什么地方。通常我们是使用的explain,以及slow query log都无法做到精确分析,
但是Query Profiler却可以定位出一条SQL语句执行的各种资源消耗情况,比如CPU,IO等,以及该SQL执行所耗费的时间等。
查看数据库版本方法:show variables like "%version%"; 或者 select version();

2.确定支持show profile 后,查看profile是否开启,数据库默认是不开启的。变量profiling是用户变量,每次都得重新启用。
查看方法: show variables like "%pro%";
设置开启方法: set profiling = 1;
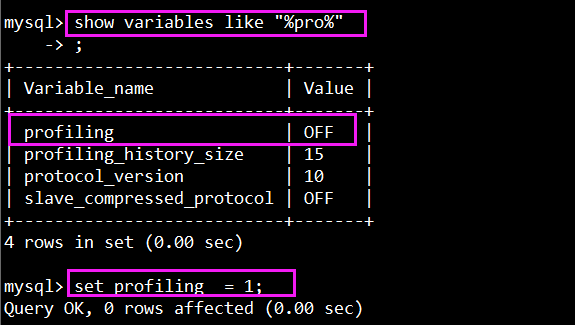
再次查看show variables like "%pro%"; 已经是开启的状态了。
3.可以开始执行一些想要分析的sql语句了,执行完后,show profiles;即可查看所有sql的总的执行时间。

show profile for query 1 即可查看第1个sql语句的执行的各个操作的耗时详情。
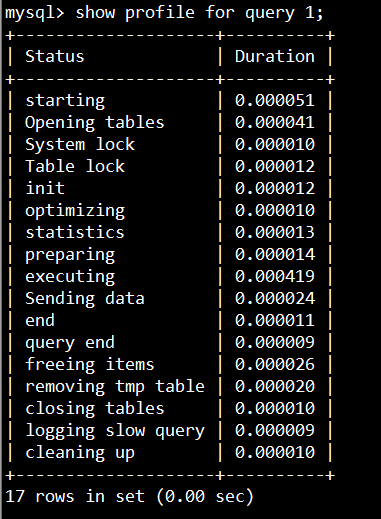
show profile cpu, block io, memory,swaps,context switches,source for query 6;可以查看出一条SQL语句执行的各种资源消耗情况,比如CPU,IO等
show profile all for query 6 查看第6条语句的所有的执行信息。
测试完毕后,关闭参数:
mysql> set profiling=0
(四)以上是总体而言如何对SQL进行优化,具体的对于某一个sql还有如下具体的方法:
1.查询的模糊匹配
尽量避免在一个复杂查询里面使用 LIKE '%parm1%'—— 红色标识位置的百分号会导致相关列的索引无法使用,最好不要用.
解决办法:
其实只需要对该脚本略做改进,查询速度便会提高近百倍。改进方法如下:
a、修改前台程序——把查询条件的供应商名称一栏由原来的文本输入改为下拉列表,用户模糊输入供应商名称时,直接在前台就帮忙定位到具体的供应商,这样在调用后台程序时,这列就可以直接用等于来关联了。
b、直接修改后台——根据输入条件,先查出符合条件的供应商,并把相关记录保存在一个临时表里头,然后再用临时表去做复杂关联
2.索引问题
在做性能跟踪分析过程中,经常发现有不少后台程序的性能问题是因为缺少合适索引造成的,有些表甚至一个索引都没有。这种情况往往都是因为在设计表时,没去定义索引,而开发初期,由于表记录很少,索引创建与否,可能对性能没啥影响,开发人员因此也未多加重视。然一旦程序发布到生产环境,随着时间的推移,表记录越来越多
这时缺少索引,对性能的影响便会越来越大了。
这个问题需要数据库设计人员和开发人员共同关注
法则:不要在建立的索引的数据列上进行下列操作:
◆避免对索引字段进行计算操作
◆避免在索引字段上使用not,<>,!=
◆避免在索引列上使用IS NULL和IS NOT NULL
◆避免在索引列上出现数据类型转换
◆避免在索引字段上使用函数
◆避免建立索引的列中使用空值。
3.复杂操作
部分UPDATE、SELECT 语句 写得很复杂(经常嵌套多级子查询)——可以考虑适当拆成几步,先生成一些临时数据表,再进行关联操作
4.update
(a)UPDATE操作不要拆成DELETE操作+INSERT操作的形式,虽然功能相同,但是性能差别是很大的。
(b)同一个表的修改在一个过程里出现好几十次,如:
update table1
set col1=...
where col2=...;
update table1
set col1=...
where col2=...
......
象这类脚本其实可以很简单就整合在一个UPDATE语句来完成(前些时候在协助xxx项目做性能问题分析时就发现存在这种情况)
5.在可以使用UNION ALL的语句里,使用了UNION
UNION 因为会将各查询子集的记录做比较,故比起UNION ALL ,通常速度都会慢上许多。一般来说,如果使用UNION ALL能满足要求的话,务必使用UNION ALL。还有一种情况大家可能会忽略掉,就是虽然要求几个子集的并集需要过滤掉重复记录,但由于脚本的特殊性,不可能存在重复记录,这时便应该使用UNION ALL,如xx模块的某个查询程序就曾经存在这种情况,见,由于语句的特殊性,在这个脚本中几个子集的记录绝对不可能重复,故可以改用UNION ALL)
6.在WHERE 语句中,尽量避免对索引字段进行计算操作
这个常识相信绝大部分开发人员都应该知道,但仍有不少人这么使用,我想其中一个最主要的原因可能是为了编写写简单而损害了性能,那就不可取了
9月份在对XX系统做性能分析时发现,有大量的后台程序存在类似用法,如:
......
where trunc(create_date)=trunc(:date1)
虽然已对create_date 字段建了索引,但由于加了TRUNC,使得索引无法用上。此处正确的写法应该是
where create_date>=trunc(:date1) and create_date<trunc(:date1)+1< pre="">
或者是
where create_date between trunc(:date1) and trunc(:date1)+1-1/(24*60*60)
注意:因between 的范围是个闭区间(greater than or equal to low value and less than or equal to high value.),
故严格意义上应该再减去一个趋于0的小数,这里暂且设置成减去1秒(1/(24*60*60)),如果不要求这么精确的话,可以略掉这步。
7.对Where 语句的法则
1)在下面两条select语句中:
select * from table1 where field1<=10000 and field1>=0;
select * from table1 where field1>=0 and field1<=10000;
如果数据表中的数据field1都>=0,则第一条select语句要比第二条select语句效率高的多,因为第二条select语句的第一个条件耗费了大量的系统资源。
第一个原则:在where子句中应把最具限制性的条件放在最前面。
2)在下面的select语句中:
select * from tab where a=… and b=… and c=…;
若有索引index(a,b,c),则where子句中字段的顺序应和索引中字段顺序一致。
关于索引可以看我的另一篇博客:数据库-索引 (聚集索引和非聚集索引)
第二个原则:where子句中字段的顺序应和索引中字段顺序一致。
(a) 减少访问数据库的次数:
程序设计中最好将一些常用的全局变量表放在内存中或者用其他的方式减少数据库的访问次数
.(b) 尽量少做重复的工作
尽量减少无效工作,但是这一点的侧重点在客户端程序,需要注意的如下:
A、 控制同一语句的多次执行,特别是一些基础数据的多次执行是很多程序员很少注意的
B、减少多次的数据转换,也许需要数据转换是设计的问题,但是减少次数是程序员可以做到的。
C、杜绝不必要的子查询和连接表,子查询在执行计划一般解释成外连接,多余的连接表带来额外的开销。
7.1 避免在WHERE子句中使用in,not in,or 或者having。
可以使用 exist 和not exist代替 in和not in。
原因:1.exist,not exist一般都是与子查询一起使用. In可以与子查询一起使用,也可以直接in (a,b.....)。
2.exist会针对子查询的表使用索引. not exist会对主子查询都会使用索引. in与子查询一起使用的时候,只能针对主查询使用索引. not in则不会使用任何索引. 注意,一直以来认为exists比in效率高的说法是不准确的。
可以使用表链接代替 exist。Having可以用where代替,如果无法代替可以分两步处理。
having 和where 都是用来筛选用的
having 是筛选组 而where是筛选记录
他们有各自的区别
1》当分组筛选的时候 用having
2》其它情况用where
用having就一定要和group by连用,
用group by不一有having (它只是一个筛选条件用的)
例子
SELECT * FROM ORDERS WHERE CUSTOMER_NAME NOT IN
(SELECT CUSTOMER_NAME FROM CUSTOMER)
优化
SELECT * FROM ORDERS WHERE CUSTOMER_NAME not exist
(SELECT CUSTOMER_NAME FROM CUSTOMER)
7.2 不要以字符格式声明数字,要以数字格式声明字符值。(日期同样)否则会使索引无效,产生全表扫描。
例子使用:
SELECT emp.ename, emp.job FROM emp WHERE emp.empno = 7369;
不要使用:SELECT emp.ename, emp.job FROM emp WHERE emp.empno = ‘7369’
8.对Select语句的法则
在应用程序、包和过程中限制使用select * from table这种方式。看下面例子
使用SELECT empno,ename,category FROM emp WHERE empno = '7369‘ (快)
而不要使用SELECT * FROM emp WHERE empno = '7369' (慢)
因为后者在索引扫描后要多一步ROWID表访问。
9. 排序
避免使用耗费资源的操作,带有DISTINCT,UNION,MINUS,INTERSECT,ORDER BY的SQL语句会启动SQL引擎 执行,耗费资源的排序(SORT)功能. DISTINCT需要一次排序操作, 而其他的至少需要执行两次排序
10.临时表
慎重使用临时表可以极大的提高系统性能
(1)除非却有需要,否则应尽量避免使用临时表,相反,可以使用表变量代替;
(2)大多数时候(99%),表变量驻扎在内存中,因此速度比临时表更快,临时表驻扎在TempDb数据库中,因此临时表上的操作需要跨数据库通信,速度自然慢。
注意SELECT INTO后的WHERE子句
因为SELECT INTO把数据插入到临时表,这个过程会锁定一些系统表,如果这个WHERE子句返回的数据过多或者速度太慢,会造成系统表长期锁定,诸塞其他进程。
对于聚合查询,可以用HAVING子句进一步限定返回的行
11不走索引的情况
(a)<>
(b)、like’%dd’百分号在前
(c)、not in ,not exist.
专门针对 like的优化
like as%, like '...%..'走索引
like %%不走索引
博客:http://blog.csdn.net/maoweiting19910402/article/details/7783084
select field3,field4 from tb where field1>='sdf' 快
select field3,field4 from tb where field1>'sdf' 慢
因为前者可以迅速定位索引。
select field3,field4 from tb where field2 like 'R%' 快
select field3,field4 from tb where field2 like '%R' 慢,
因为后者不使用索引。
12 函数
select field3,field4 from tb where upper(field2)='RMN'不使用索引。
如果一个表有两万条记录,建议不使用函数;如果一个表有五万条以上记录,严格禁止使用函数!两万条记录以下没有限制。
MySQL专题3 SQL 优化的更多相关文章
- (6)MySQL进阶篇SQL优化(MyISAM表锁)
1.MySQL锁概述 锁是计算机协调多个进程或线程并发访问某一资源的机制.在数据库中,除传统的计算资源 (如 CPU.RAM.I/O 等)的抢占以外,数据也是一种供许多用户共享的资源.如何保证数 据并 ...
- [转]Mysql中的SQL优化与执行计划
From : http://religiose.iteye.com/blog/1685537 一,如何判断SQL的执行效率? 通过explain 关键字分析效率低的SQL执行计划. 比如: expla ...
- MySQL系列(七)--SQL优化的步骤
前面讲了如何设计数据库表结构.存储引擎.索引优化等内存,这篇文章会讲述如何进行SQL优化,也是面试中关于数据库肯定会被问到的, 这些内容不仅仅是为了面试,更重要的是付诸实践,最终用到工作当中 之前的M ...
- (4)MySQL进阶篇SQL优化(常用SQL的优化)
1.概述 前面我们介绍了MySQL中怎么样通过索引来优化查询.日常开发中,除了使用查询外,我们还会使用一些其他的常用SQL,比如 INSERT.GROUP BY等.对于这些SQL语句,我们该怎么样进行 ...
- MySQL 学习四 SQL优化
MySQL逻辑架构: 第一层:客户端层,连接处理,授权认证,安全等功能. 第二层:核心层,查询解析,分析,优化,缓存,内置函数(时间,数学,加密),存储过程,触发器,视图 第三层:存储引擎.负 ...
- 基于mysql数据库 关于sql优化的一些问题
mysql数据库有一个explain关键词,可以对select语句进行分析并且输出详细的select执行过程的详细信息. 对sql explain后输出几个字段: id:SELECT查询的标识符,每个 ...
- (2)MySQL进阶篇SQL优化(show status、explain分析)
1.概述 在应用系统开发过程中,由于初期数据量小,开发人员写SQL语句时更重视功能上的实现,但是当应用系统正式上线后,随着生产数据量的急剧增长,很多SQL语句开始逐渐显露出性能问题,对生产环境的影响也 ...
- (3)MySQL进阶篇SQL优化(索引)
1.索引问题 索引是数据库优化中最常用也是最重要的手段之一,通过索引通常可以帮助用户解决大多数 的SQL性能问题.本章节将对MySQL中的索引的分类.存储.使用方法做详细的介绍. 2.索引的存储分类 ...
- MySQL 5.6 SQL 优化及 5.6手册
http://blog.chinaunix.net/uid-259788-id-4146363.html http://www.cnblogs.com/Amaranthus/p/4028687.htm ...
随机推荐
- 20155224聂小益的Linux学习
20155224聂小益的虚拟机安装 虚拟机安装 一开始,我在下载VirtulBox及Ubuntu遇到了一些困难,老实说点进去看到一大堆英文界面的时候真的是有点吓到.不过几秒钟之后就发现这并没有什么哈哈 ...
- 20155304 2016-2017-2 《Java程序设计》第十周学习总结
20155304 2016-2017-2 <Java程序设计>第十周学习总结 教材学习内容总结 网络编程 网络编程就是在两个或两个以上的设备(例如计算机)之间传输数据.程序员所作的事情就是 ...
- 2016-2017-2 20155339《 java面向对象程序设计》实验四Android程序设计
2016-2017-2 20155339< java面向对象程序设计>实验四Android程序设计 实验内容 1.Android Stuidio的安装测试: 参考<Java和Andr ...
- 解决非controller使用,@Autowired或者@Resource注解注入Mapper接口为null的问题
知识点:在service层中注入其它的service接口或者mapper接口都是可以的 但是在封装的Utils工具类中或者非controller普通类中使用@Autowired@Resource注解注 ...
- PHP 行为测试工具 Codeception (介绍)
原文地址:https://phphub.org/topics/25 Codeception 简介 Codeception 简单来说, 分为以下几种测试 Acceptance Tests 验收测试 Fu ...
- Python接口测试实战3(上)- Python操作数据库
如有任何学习问题,可以添加作者微信:lockingfree 课程目录 Python接口测试实战1(上)- 接口测试理论 Python接口测试实战1(下)- 接口测试工具的使用 Python接口测试实战 ...
- 【UGUI】 (二)--------- 小地图
在绝大多数游戏中,小地图都是极为常见的一个模块而且十分重要.在Unity里面如何制作一个地图其实也是比较简单的 一. 创建玩家与敌人 创建一个Capsule,命名为Player,代表我们的游戏玩家,创 ...
- Towards Accurate Multi-person Pose Estimation in the Wild 论文阅读
论文概况 论文名:Towards Accurate Multi-person Pose Estimation in the Wild 作者(第一作者)及单位:George Papandreou, 谷歌 ...
- Python数据可视化的10种技能
今天我来给你讲讲Python的可视化技术. 如果你想要用Python进行数据分析,就需要在项目初期开始进行探索性的数据分析,这样方便你对数据有一定的了解.其中最直观的就是采用数据可视化技术,这样,数据 ...
- Python爬虫:爬取美拍小姐姐视频
最近在写一个应用,需要收集微博上一些热门的视频,像这些小视频一般都来自秒拍,微拍,美拍和新浪视频,而且没有下载的选项,所以只能动脑想想办法了. 第一步 分析网页源码. 例如:http://video. ...