如何用Python实现常见机器学习算法-1
最近在GitHub上学习了有关python实现常见机器学习算法
目录
- 一、线性回归
1、代价函数
2、梯度下降算法
3、均值归一化
4、最终运行结果
5、使用scikit-learn库中的线性模型实现
- 二、逻辑回归
1、代价函数
2、梯度
3、正则化
4、S型函数
5、映射为多项式
6、使用的优化方法
7、运行结果
8、使用scikit-learn库中的逻辑回归模型实现
- 逻辑回归_手写数字识别_OneVsAll
1、随机显示100个数字
2、OneVsAll
3、手写数字识别
4、预测
5、运行结果
6、使用scikit-learn库中的逻辑回归模型实现
- 三、BP神经网络
1、神经网络model
2、代价函数
3、正则化
4、反向传播BP
5、BP可以求梯度的原因
6、梯度检查
7、权重的随机初始化
8、预测
9、输出结果
- 四、SVM支持向量机
1、代价函数
2、Large Margin
3、SVM Kernel
4、使用中的模型代码
5、运行结果
- 五、K-Mearns聚类算法
1、聚类过程
2、目标函数
3、聚类中心的选择
4、聚类个数K的选择
5、应用——图片压缩
6、使用scikit-learn库中的线性模型实现聚类
7、运行结果
- 六、PCA主成分分析(降维)
1、用处
2、2D-->1D,nD-->kD
3、主成分分析PCA与线性回归的区别
4、PCA降维过程
5、数据恢复
6、主成分个数的选择(即要降的维度)
7、使用建议
8、运行结果
9、使用scikit-learn库中的PCA实现降维
- 七、异常检测Anomaly Detection
1、高斯分布(正态分布)
2、异常检测算法
3、评价的好坏,以及 的选取
的选取
4、选择使用什么样的feature(单位高斯分布)
5、多元高斯分布
6、单元和多元高斯分布特点
7、程序运行结果
一、线性回归
1、代价函数

其中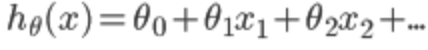 。
。
下面就是求出theta,使代价最小,即代表我们拟合出来的方程距离真实值最近共有m条数据,其中 代表我们拟合出来的方程到真实值距离的平方,平方的原因是因为可能有负值,系数2的原因是下面求梯度是对每个变量求偏导,2可以消去。
代表我们拟合出来的方程到真实值距离的平方,平方的原因是因为可能有负值,系数2的原因是下面求梯度是对每个变量求偏导,2可以消去。
代码实现:
# 计算代价函数
def computerCost(X,y,theta):
m = len(y)
J = 0
J = (np.transpose(X*theta-y))*(X*theta-y)/(2*m) #计算代价J
return J
注意这里的X是真实数据前加了一列1,因为有theta(0)
2、梯度下降算法
代价函数对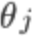 求偏导得到:
求偏导得到:

所以对theta的更新可以写成:
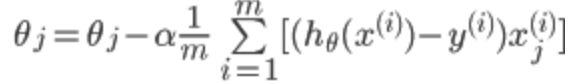
其中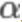 为学习速率,控制梯度下降的速度,一般取0.01,0.03,0.1,0.3......
为学习速率,控制梯度下降的速度,一般取0.01,0.03,0.1,0.3......
为什么梯度下降可以逐步减小代价函数?
假设函数f(x)的泰勒展开:f(x+△x)=f(x)+f'(x)*△x+o(△x),令:△x=-α*f'(x),即负梯度方向乘以一个很小的步长α,将△x带入泰勒展开式中:
f(x+x)=f(x)-α*[f'(x)]²+o(△x)
可以看出,α是取得很小的正数,[f'(x)]²也是正数,所以可以得出f(x+△x)<=f(x),所以沿着负梯度放下,函数在减小,多维情况一样。
# 梯度下降算法
def gradientDescent(X,y,theta,alpha,num_iters):
m = len(y)
n = len(theta)
temp = np.matrix(np.zeros((n,num_iters))) # 暂存每次迭代计算的theta,转化为矩阵形式
J_history = np.zeros((num_iters,1)) #记录每次迭代计算的代价值 for i in range(num_iters): # 遍历迭代次数
h = np.dot(X,theta) # 计算内积,matrix可以直接乘
temp[:,i] = theta - ((alpha/m)*(np.dot(np.transpose(X),h-y))) #梯度的计算
theta = temp[:,i]
J_history[i] = computerCost(X,y,theta) #调用计算代价函数
print '.',
return theta,J_history
3、均值归一化
均值归一化的目的是使数据都缩放到一个范围内,便于使用梯度下降算法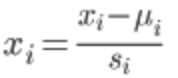
其中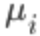 为所有此feature数据的平均值,
为所有此feature数据的平均值, 可以为此feature的最大值减去最小值,也可以为这个feature对应的数据的标准差。
可以为此feature的最大值减去最小值,也可以为这个feature对应的数据的标准差。
代码实现:
# 归一化feature
def featureNormaliza(X):
X_norm = np.array(X) #将X转化为numpy数组对象,才可以进行矩阵的运算
#定义所需变量
mu = np.zeros((1,X.shape[1]))
sigma = np.zeros((1,X.shape[1])) mu = np.mean(X_norm,0) # 求每一列的平均值(0指定为列,1代表行)
sigma = np.std(X_norm,0) # 求每一列的标准差
for i in range(X.shape[1]): # 遍历列
X_norm[:,i] = (X_norm[:,i]-mu[i])/sigma[i] # 归一化 return X_norm,mu,sigma
注意预测的时候也需要均值归一化数据
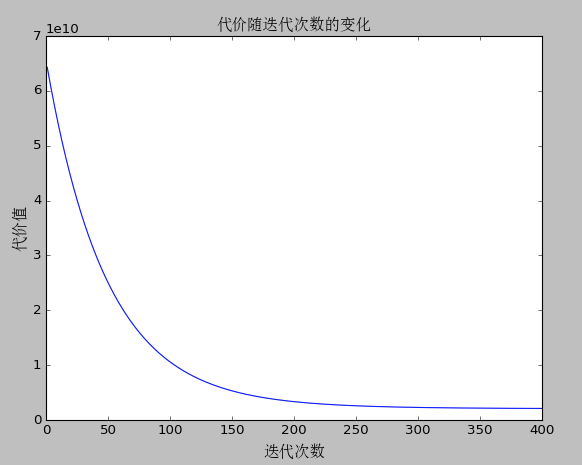
4、最终运行结果
代价随迭代次数的变化
5、使用scikit-learn库中的线性模型实现
#-*- coding: utf-8 -*-
import numpy as np
from sklearn import linear_model
from sklearn.preprocessing import StandardScaler #引入归一化的包 def linearRegression():
print u"加载数据...\n"
data = loadtxtAndcsv_data("data.txt",",",np.float64) #读取数据
X = np.array(data[:,0:-1],dtype=np.float64) # X对应0到倒数第2列
y = np.array(data[:,-1],dtype=np.float64) # y对应最后一列 # 归一化操作
scaler = StandardScaler()
scaler.fit(X)
x_train = scaler.transform(X)
x_test = scaler.transform(np.array([1650,3])) # 线性模型拟合
model = linear_model.LinearRegression()
model.fit(x_train, y) #预测结果
result = model.predict(x_test)
print model.coef_ # Coefficient of the features 决策函数中的特征系数
print model.intercept_ # 又名bias偏置,若设置为False,则为0
print result # 预测结果 # 加载txt和csv文件
def loadtxtAndcsv_data(fileName,split,dataType):
return np.loadtxt(fileName,delimiter=split,dtype=dataType) # 加载npy文件
def loadnpy_data(fileName):
return np.load(fileName) if __name__ == "__main__":
linearRegression()
如何用Python实现常见机器学习算法-1的更多相关文章
- 如何用Python实现常见机器学习算法-2
二.逻辑回归 1.代价函数 可以将上式综合起来为: 其中: 为什么不用线性回归的代价函数表示呢?因为线性回归的代价函数可能是非凸的,对于分类问题,使用梯度下降很难得到最小值,上面的代价函数是凸函数的图 ...
- 如何用Python实现常见机器学习算法-4
四.SVM支持向量机 1.代价函数 在逻辑回归中,我们的代价为: 其中: 如图所示,如果y=1,cost代价函数如图所示 我们想让,即z>>0,这样的话cost代价函数才会趋于最小(这正是 ...
- 如何用Python实现常见机器学习算法-3
三.BP神经网络 1.神经网络模型 首先介绍三层神经网络,如下图 输入层(input layer)有三个units(为补上的bias,通常设为1) 表示第j层的第i个激励,也称为单元unit 为第j层 ...
- python 的常见排序算法实现
python 的常见排序算法实现 参考以下链接:https://www.cnblogs.com/shiluoliming/p/6740585.html 算法(Algorithm)是指解题方案的准确而完 ...
- 用Python实现常见排序算法
最简单的排序有三种:插入排序,选择排序和冒泡排序.这三种排序比较简单,它们的平均时间复杂度均为O(n^2),在这里对原理就不加赘述了.贴出来源代码. 插入排序: def insertion_sort( ...
- python实现常见排序算法
#coding=utf-8from collections import deque #冒泡排序def bubblesort(l):#复杂度平均O(n*2) 最优O(n) 最坏O(n*2) for i ...
- 建模分析之机器学习算法(附python&R代码)
0序 随着移动互联和大数据的拓展越发觉得算法以及模型在设计和开发中的重要性.不管是现在接触比较多的安全产品还是大互联网公司经常提到的人工智能产品(甚至人类2045的的智能拐点时代).都基于算法及建模来 ...
- 10 种机器学习算法的要点(附 Python 和 R 代码)
本文由 伯乐在线 - Agatha 翻译,唐尤华 校稿.未经许可,禁止转载!英文出处:SUNIL RAY.欢迎加入翻译组. 前言 谷歌董事长施密特曾说过:虽然谷歌的无人驾驶汽车和机器人受到了许多媒体关 ...
- 10 种机器学习算法的要点(附 Python)(转载)
一.前言 谷歌董事长施密特曾说过:虽然谷歌的无人驾驶汽车和机器人受到了许多媒体关注,但是这家公司真正的未来在于机器学习,一种让计算机更聪明.更个性化的技术 也许我们生活在人类历史上最关键的时期:从使用 ...
随机推荐
- 【转】linux tail命令使用方法详解
原文网址:http://www.111cn.net/sys/linux/46902.htm linux tail命令用途是按照要求将指定的文件的最后部分输出到标准设备,一般是终端,通俗讲来,就是把某个 ...
- application项目获取bean
对于web项目,编程方式获取bean如下: WebApplicationContext wac = ContextLoader.getCurrentWebApplicationContext(); C ...
- java用double和float进行小数计算精度不准确
java用double和float进行小数计算精度不准确 大多数情况下,使用double和float计算的结果是准确的,但是在一些精度要求很高的系统中或者已知的小数计算得到的结果会不准确,这种问题是非 ...
- 设置cassandra用户名和密码
参考http://zhaoyanblog.com/archives/307.html 修改cassandra.yaml配置文件 把默认的 authenticator: AllowAllAuthenti ...
- spring RestTemplate用法详解
spring RestTemplate用法详解 spring 3.2.3 框架参考有说明 21.9 Accessing RESTful services on the Client
- SQL 基础命令和函数
[数据操作] SELECT --从数据库表中检索数据行和列 INSERT --向数据库表添加新数据行 DELETE --从数据库表中删除数据行 UPDATE --更新数据库表中的数据 [数据定义] C ...
- 让别人能登陆你的mysql
线上的数据库肯定是不能轻易在开发新功能的时候动的,如果你的数据库跟线上不一样了又没有新数据库的备份,就很麻烦. 当然去动线上数据库,出了什么问题我是不想背锅的. 最稳健的办法!让管理线上数据库的同学, ...
- leetcode9
public class Solution { public bool IsPalindrome(int x) { ) { return false; } var str = x.ToString() ...
- excel拼接数据宏
将sheet2的A2 和 G2 加上 sheet5的A2和B2合一起生成新的sheet--就是将两个sheet的指定列前后拼接一起作为一个新的sheet Sub addwork() Sheets ...
- 开源地理空间基金会OSGeo简介
开源地理空间基金会 OSGeo 相关站点: OSGeo官方站点:http://www.osgeo.org/home OSGeo中国中心:http://www.osgeo.cn/ OSGeo GitHu ...