solr学习之一 搜索基本知识
学习了一段时间的solr了,用自己的方式总结下目前学到的内容,这是个系列文章,这里面的有些说法可能不准确,也可能有问题
欢迎大家指正。
一、搜索引擎目的
搜索引擎在我们的生活中,已经无处不在,除了我们常用的baidu、Google等,还有一些电商的搜索 比如亚马逊搜书等。除了网页搜索外,企业内部可能涉及到知识库搜索,一般称为企业搜索。现在搜索要主要的目的是,在海量信息中,从非结构化数据中快速找到符合我们含义的信息。注意这里的几个关键词语。
"海量信息" :搜索引擎一般处理的数据量很大,普通数据库在搜索的数据量非常大的时候,比如上亿条数据的时候,就算建立索引,查询速度也不是很快,不能满足现实的需求。
“符合我们的含义”:我觉得这可以称为语意搜索(还没有看到过这个叫法:),第一条也许数据库还可以勉强达到,但是数据库搜索难以达到符合含义这个目的,这在搜索过程中要涉及到同义词的转换。比如你在亚马逊中搜索solr,可以找到Lucene、搜索引擎相关的书籍,这里面就涉及到同义词的转换;我觉得这是搜索引擎最重要的特征。
一般的搜索引擎都会根据相关性对我们搜索的内容和现存的文档进行匹配,对相似度进行打分,并且按照相似度的进行排序,相似的排在前面。
"非结构化数据": 这个是指没有固定格式和固定长度的数据,比如一篇文章,这种数据也称为全文数据。
二、搜索引擎原理
2.1 常用的非结构化数据检索方法
按照上节所说,搜索引擎主要处理的是非结构化数据,故名思议,非结构化数据的特点就是没有固定的结构,这也正是处理比较困难的原因;结构化数据可以通过数据库等方式处理。非结构化数据如何处理,据说有两种方法:
一种是顺序搜索,比如在linux下用grep方式来搜索包含特定字符串的文档,这在文档数量少的时候比较有效。
二种是全文检索,它是通过对非结构化数据进行结构化转化,对非结构化数据进行抽取(从文档中抽取词),然后重新组合,再利用它进行搜索。
这个被抽取出来重新组织的信息称为索引。
第二种方法是搜索引擎中用的主要方法了。
2.2 全文检索的三大问题
这就涉及到三个问题:1、索引里面保存什么信息?2、索引如何建立? 3、如何利用索引进行搜索?
索引保存的是什么
让我们思考下,既然全文搜索是通过建立索引的方式进行搜索的,那么我们的索引内容必然是为了方便查找到我们要的信息的。
以搜索文章为例,假如我们需要海量的文章,为了方便管理我们给这些文章进行编号,
搜索就是要找到搜索关键词和文章编号的对应关系,然后通过编号再找到对应的文档。那么很自然的存储的索引的内容必然有和关键字匹配的部分,还有文章编号的部分。
实际情况也是如此,全文搜索建立的索引简单来说就是词和文章编号的对应关系,由于一个词可以放在多个文章中,所以这种索引一般就是一个个词后面对应一串文章编号(文档编号链表)。
从文章对应词比较自然,所以从词对应文档是文档对应词的反过程,保存这种信息的索引称为反向索引(倒排索引)。
盗用一张网上说明Lucene的倒排索引原理图,solr是基于Lucene的,所以solr的索引也是倒排索引。
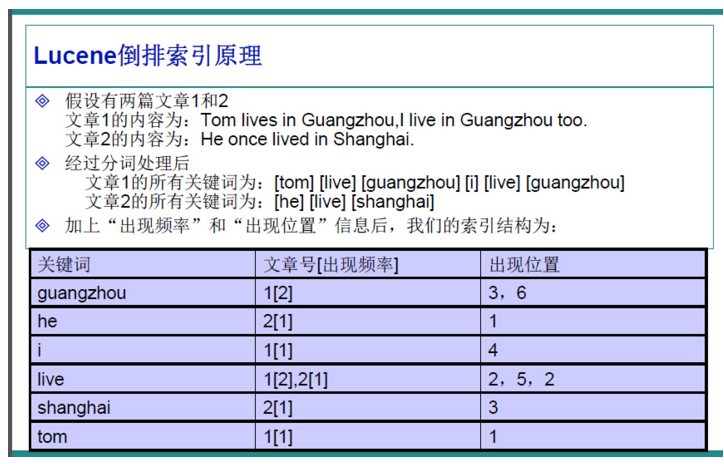
这里面,关键词一般叫词典,后面对应的一串文档号文章号叫做倒排表。
索引如何建立
创建索引的过程盗用个网上图,索引过程如下:

我们来思考下,我们要建立的索引为倒排索引即是词典和倒排表。
我们首先要从文档中得到词,所以我们首要工作是分词,这里面用到的就是分词组件(Tokenizer)本次得到的结果是词元(Token)。
其次从词元(Token)经过语言处理组件(Linguistic Processor)的处理,输出为词(Term)。这一部分主要完成的是词义转化等
词边变的更纯碎些。最后一步就是将词传递给相关的索引组件,建立索引。
1、分词做的主要工作
1)切词,英语比较好拆分就是按照空格分隔,汉字要涉及到利用词典进行切词或单独按照字来进行切词。
2)去掉标点符号。
3)去掉停词,停词是指语言中没有特殊含义的副词,比如英语中的this、is、a、汉语中的“的”等。
在solr中有专门的配置文件配置停词,stopwords_开头的配置文件。
使得到的词更有意义,减少索引的长度,因为停词在很多文档中都有,如果加到索引里面,后面的文档号要排很长,专业名词叫拉链过长。
不光占用过多的空间,而且还会导致搜索变慢。
中文由于没有明显的词语直接的间隔,所以中文分词要复杂的多。solr中默认StandardTokenizerFactory是按照字来分隔,好处是实现字级匹配,坏处索引变大。
也可以利用网上开源的分词组件,比如:庖丁分词、IK分词等。
效率solr默认的分词的建索引效率大概是IK分词的1倍,但是查询效率却慢4倍原因,是按字分词拉链过长原因。
2、语言处理主要工作
1)对英语来说是大小写转换。
2)将词缩减或简化为词根。(比如cars转成car、running转成run)
语言处理组件得到的结果是为Term(词)。
3、将此传递给索引组件
1)利用词创建词典和文档ID的对应关系表。
2)按照字典顺序对词典进行排序。
3)合并相同的词典,文档ID变成文档ID链表。
实际建立的倒排索引,还包含词在文档中的位置、出现的频次等信息。
搜索过程
1)我们利用搜索引擎的语法输入查询的语句。我们常用的搜索引擎百度
常用语法举例子如下:
1. 如果你想让百度作为整体搜索而不进行分词,用双引号包括。
2. 如果你不想要一些信息可以用-号,比如手机-推广,将不会显示百度的推广广告。
3. 比如搜索关键词之间是或者关系,可以通过搜索xxx|yyy方式搜索。
2) 对查询的语句进行词法分析、语法分析和语义处理。
类似建索引的过程,需要进行分词、转化后,还有多一个内容要区分关键字和搜索词、
关键字代表搜索词之间的逻辑关系,在solr搜索中是op标示,比如AND标示逻辑与、
OR标示或关系,经过这种语法分析后形成一个语法树。
3)搜索
在solr中大概分为三步完成:
1、在反向索引表中查找符合要求的文档ID。第一次查询返回的是文档ID和匹配度得分。
2、根据语法树进行逻辑与或或等操作,得到最终符合要求的文档ID列表。
3、通过这些文档ID列表,结合要求查询的内容去查询具体到具体的内容信息返回。
4)排序返回
文档列表查到之后,把查询的语句当做一个文档,来计算被查询的文档和查询到的文档之间的相关度,并进行打分,
相关度高的排在前面。
相关度得分的计算比较复杂,主要涉及有:
词频TF: 即词在文档中出现的次数。
DF: 即这个词在多少个文档中出现。
词的权重:词在文档中的重要性。
solr学习之一 搜索基本知识的更多相关文章
- Solr学习之二-Solr基础知识
一 基本说明 简单来说Solr是基于Lucene的高性能的,开源的Java企业搜索服务器.Solr可以看作一个Web app,运行在tomcat或Jetty这类HTTP服务器上, 底层是一个基于Luc ...
- Solr学习总结(六)SolrNet的高级用法(复杂查询,分页,高亮,Facet查询)
上一篇,讲到了SolrNet的基本用法及CURD,这个算是SolrNet 的入门知识介绍吧,昨天写完之后,有朋友评论说,这些感觉都被写烂了.没错,这些基本的用法,在网上百度,资料肯定一大堆,有一些写的 ...
- Solr学习总结(四)Solr查询参数
今天还是不会涉及到.Net和数据库操作,主要还是总结Solr 的查询参数,还是那句话,只有先明白了solr的基础内容和查询语法,后续学习solr 的C#和数据库操作,都是水到渠成的事.这里先列出sol ...
- Solr学习笔记之1、环境搭建
Solr学习笔记之1.环境搭建 一.下载相关安装包 1.JDK 2.Tomcat 3.Solr 此文所用软件包版本如下: 操作系统:Win7 64位 JDK:jdk-7u25-windows-i586 ...
- Solr学习笔记之5、Component(组件)与Handler(处理器)学习
Solr学习笔记之5.Component(组件)与Handler(处理器)学习 一.搜索篇 拼写检查(spellCheck) 作用:用来检查用户输入的检索内容是否存在,如果不存在则给它提示出相近或相似 ...
- Solr学习笔记之4、Solr配置文件简介
Solr学习笔记之4.Solr配置文件简介 摘自<Solr in Action>. 1. solr.xml – Defines one or more cores per Solr ser ...
- Solr学习之四-Solr配置说明之二
上一篇的配置说明主要是说明solrconfig.xml配置中的查询部分配置,在solr的功能中另外一个重要的功能是建索引,这是提供快速查询的核心. 按照Solr学习之一所述关于搜索引擎的原理中说明了建 ...
- Solr学习记录:Getting started
目录 Solr学习记录:Getting started 1.Solr Tutorial 2. A Quick Overview Solr学习记录:Getting started 本教程使用环境:jav ...
- solr学习笔记-入门
solr学习笔记 1.安装前准备 solr依赖java 8 运行环境,所以我们先安装java.如果没有java环境无法启动solr服务,并且会看到如下提示: [root@localhost solr- ...
随机推荐
- POSIX 线程详解
一种支持内存共享的简捷工具 POSIX(可移植操作系统接口)线程是提高代码响应和性能的有力手段.在本系列中,Daniel Robbins 向您精确地展示在编程中如何使用线程.其中还涉及大量幕后细节,读 ...
- MySQL双主如何解决主键冲突问题
搭建了个双主,突然想到如果表设置了自增主键的话,当业务同时向双库中插入一条数据,这时候情况是什么样子的呢? 比如:主库A和主库B上的一个表数据为: 12 'ninhao' .当业务同时写入数据后主库A ...
- linux RAID10测试
mdadm命令用于管理系统软件RAID硬盘阵列,格式为:"mdadm [模式] <RAID设备名称> [选项] [成员设备名称]". mdadm命令能够在Linux系统 ...
- 如何解决普通用户使用sudo找不到命令
一.在linux的普通用户下,要使用root权限的命令需要使用sudo [dev@dev1 client_api]# sudo git pull origin develop sudo: git: c ...
- HDUOJ-----(1072)Nightmare(bfs)
Nightmare Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total ...
- HDUOJ---Hamming Distance(4712)
Hamming Distance Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 65535/65535 K (Java/Others) ...
- eclipse容易卡死或者较慢的解决方案
http://blog.sina.com.cn/s/blog_5c6c4dc90100lg8n.html 问题: Eclipse经常卡住或Building workspace等待,感觉很不爽,很多朋友 ...
- jsp里面实现asp.net的Global文件内容。
Global.java文件: import javax.servlet.ServletContext; import javax.servlet.ServletContextEvent; import ...
- Python练习笔记——对输入的数字进行加和
请您输入数字,每个数字采用回车结束,当您输入型号*时,则结束数字输入,输出所有数字的总和 def num_sum(): i = 0 while True: get_num = input(" ...
- SqlServer 获取汉字的拼音首字母
一.该函数传入字符串,返回数据为:如果为汉字字符,返回该字符的首字母,如果为非汉字字符,则返回本身.二.用到的知识点:汉字对应的UNICODE值,汉字的排序规则.三.数据库函数: CREATE FUN ...