spark on yarn模式下配置spark-sql访问hive元数据
spark on yarn模式下配置spark-sql访问hive元数据
目的:在spark on yarn模式下,执行spark-sql访问hive的元数据。并对比一下spark-sql 和hive的效率。
软件环境:
- hadoop2.7.3
- apache-hive-2.1.1-bin
- spark-2.1.0-bin-hadoop2.7
- jd1.8
hadoop是伪分布式安装的,1个节点,2core,4G内存。
hive是远程模式。
spark的下载地址:
http://spark.apache.org/downloads.html
解压安装spark
tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz.tar
cd spark-2.1.0-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
cp log4j.properties.template log4j.properties
cp spark-defaults.conf.template spark-defaults.conf修改spark的配置文件
cd $SPARK_HOME/conf
vi spark-env.shexport JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/home/fuxin.zhao/soft/hadoop-2.7.3
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
vi spark-defaults.conf
spark.master spark://ubuntuServer01:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://ubuntuServer01:9000/tmp/spark
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512m
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
#spark.yarn.jars hdfs://ubuntuServer01:9000/tmp/spark/lib_jars/*.jar
vi slaves
ubuntuServer01
** 配置spark-sql读取hive的元数据**
##将hive-site.xml 软连接到spark的conf配置目录中:
cd $SPARK_HOME/conf
ln -s /home/fuxin.zhao/soft/apache-hive-2.1.1-bin/conf/hive-site.xml hive-site.xml
##将连接 mysql-connector-java-5.1.35-bin.jar拷贝到spark的jars目录下
cp $HIVE_HOME/lib/mysql-connector-java-5.1.35-bin.jar $SPARK_HOME/jars
测试spark-sql:
先使用hive创建几个数据库和数据表,测试spark-sql是否可以访问
我向 temp.s4_order表导入了6万行,9M大小的数据。#先使用hive创建一下数据库和数据表,测试spark-sql是否可以访问
hive -e "
create database temp;
create database test;
use temp;
CREATE EXTERNAL TABLE t_source(
`sid` string,
`uid` string
); load data local inpath '/home/fuxin.zhao/t_data' into table t_source;
CREATE EXTERNAL TABLE s4_order(
`orderid` int ,
`retailercode` string ,
`orderstatus` int,
`paystatus` int,
`payid` string,
`paytime` timestamp,
`payendtime` timestamp,
`salesamount` int,
`description` string,
`usertoken` string,
`username` string,
`mobile` string,
`createtime` timestamp,
`refundstatus` int,
`subordercount` int,
`subordersuccesscount` int,
`subordercreatesuccesscount` int,
`businesstype` int,
`deductedamount` int,
`refundorderstatus` int,
`platform` string,
`subplatform` string,
`refundnumber` string,
`refundpaytime` timestamp,
`refundordertime` timestamp,
`primarysubordercount` int,
`primarysubordersuccesscount` int,
`suborderprocesscount` int,
`isshoworder` int,
`updateshowordertime` timestamp,
`devicetoken` string,
`lastmodifytime` timestamp,
`refundreasontype` int )
PARTITIONED BY (
`dt` string);
load data local inpath '/home/fuxin.zhao/20170214003514' OVERWRITE into table s4_order partition(dt='2017-02-13');
load data local inpath '/home/fuxin.zhao/20170215000514' OVERWRITE into table s4_order partition(dt='2017-02-14');
"
输入spark-sql命令,在终端中执行如下一些sql命令:
启动spark-sql客户端:
spark-sql --master yarn
在启动的命令行中执行如下sql:
show database;
use temp;
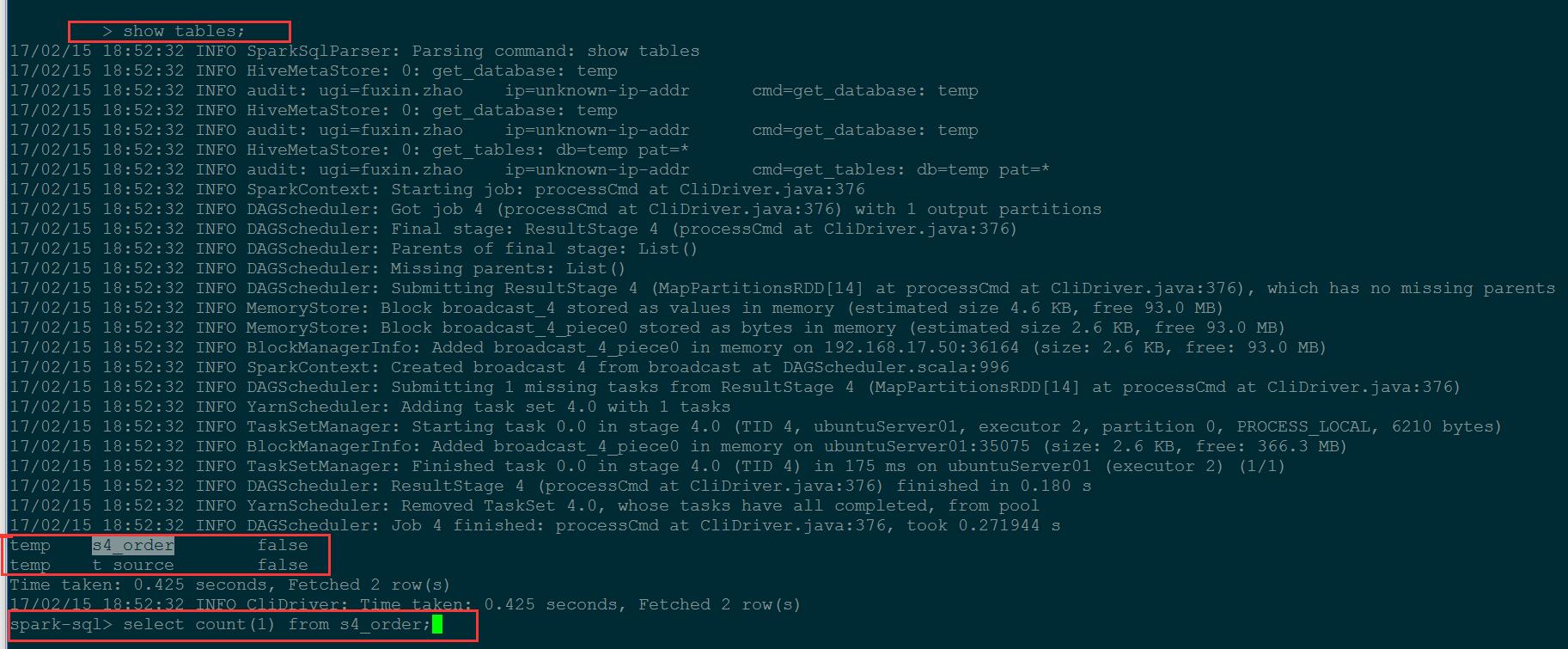
show tables;
select * from s4_order limit 100;
select count(*) ,dt from s4_order group dt;
select count(*) from s4_order ;
insert overwrite table t_source select orderid,createtime from s4_order;
select count() ,dt from s4_order group dt; // spark-sql耗时 11s; hive执行耗时30秒
select count() from s4_order ; // spark-sql耗时2s;hive执行耗时25秒。
直观的感受是spark-sql 的效率大概是hive的 3到10倍,由于我的测试是本地的虚拟机单机环境,hadoop也是伪分布式环境,资源较匮乏,在生产环境中随着集群规模,数据量,执行逻辑的变化,执行效率应该不是这个比例。
spark on yarn模式下配置spark-sql访问hive元数据的更多相关文章
- spark 在yarn模式下提交作业
1.spark在yarn模式下提交作业需要启动hdfs集群和yarn,具体操作参照:hadoop 完全分布式集群搭建 2.spark需要配置yarn和hadoop的参数目录 将spark/conf/目 ...
- spark on yarn模式下内存资源管理(笔记2)
1.spark 2.2内存占用计算公式 https://blog.csdn.net/lingbo229/article/details/80914283 2.spark on yarn内存分配** 本 ...
- spark on yarn模式下内存资源管理(笔记1)
问题:1. spark中yarn集群资源管理器,container资源容器与集群各节点node,spark应用(application),spark作业(job),阶段(stage),任务(task) ...
- Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
说白了 Spark on YARN模式的安装,它是非常的简单,只需要下载编译好Spark安装包,在一台带有Hadoop YARN客户端的的机器上运行即可. Spark on YARN简介与运行wor ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)(转)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- spark on yarn模式里需要有时手工释放linux内存
为什么要提出这个问题? spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED) 然后执行 [spark@master spark--bin- ...
- Spark- Spark Yarn模式下跑yarn-client无法初始化SparkConext,Over usage of virtual memory
在spark yarn模式下跑yarn-client时出现无法初始化SparkContext错误. // :: INFO mapreduce.Job: Task Id : attempt_142829 ...
- flink on yarn模式下两种提交job方式
yarn集群搭建,参见hadoop 完全分布式集群搭建 通过yarn进行资源管理,flink的任务直接提交到hadoop集群 1.hadoop集群启动,yarn需要运行起来.确保配置HADOOP_HO ...
随机推荐
- Spring batch学习 (1)
Spring Batch 批处理框架 埃森哲和Spring Source研发 主要解决批处理数据的问题,包含并行处理,事务处理机制等.具有健壮性 可扩展,和自带的监控功能,并且支持断点和重发.让程序员 ...
- django-model的元类Meta
Meta类存在model类里面 模型元选项 文档有更多Meta类的配置属性: English:https://docs.djangoproject.com/en/1.11/ref/models/opt ...
- PHP 成长规划
PHP程序员的技术成长规划 作者:黑夜路人(2014/10/15) 转:http://blog.csdn.net/heiyeshuwu/article/details/40098043 按照了解的很多 ...
- ADO 缓存更新
if (ADOQuery1->UpdateStatus() == usUnmodified) return; ADOQuery1->UpdateBatch(arAll); Update ...
- VS2013默认打开HTML文件没有设计视图
打开VS菜单->工具->选项->文本编辑器->文件扩展名,右侧输入html,再下拉列表选HTML(Web窗体)编辑器,点添加,确定. 第二条是彻底解决VS2013不能编辑HTM ...
- Lrc歌词-开发标准
LRC歌词是在其程序当中实现的专门用于MP3等歌词同步显示的标签式的纯文本文件,如今已经得到了广泛的运用.现就LRC歌词文件的格式规定详细说明,已供程序开发人员参考. LRC文件是纯文本文件,可以用记 ...
- UVALive-7297-Hounded by Indecision
OK, maybe stealing the Duchess’s favorite ruby necklace was not such a good idea. You were makingyou ...
- centos7虚拟机安装elasticsearch6.4.x-遇到的坑
OS:Centos7x虚拟机 1H2Gjdk:1.8elasticsearch:5.6.0 1.下载“elasticsearch-5.6.0.tar.gz”解压到/usr/local/elastics ...
- 基础知识 一个工具给win7 win10的同学 或者MAC 可以跳过
- 44. Wildcard Matching (String; DP, Back-Track)
Implement wildcard pattern matching with support for '?' and '*'. '?' Matches any single character. ...