scrapy 资料整合
先看看scrapy的框架流程,
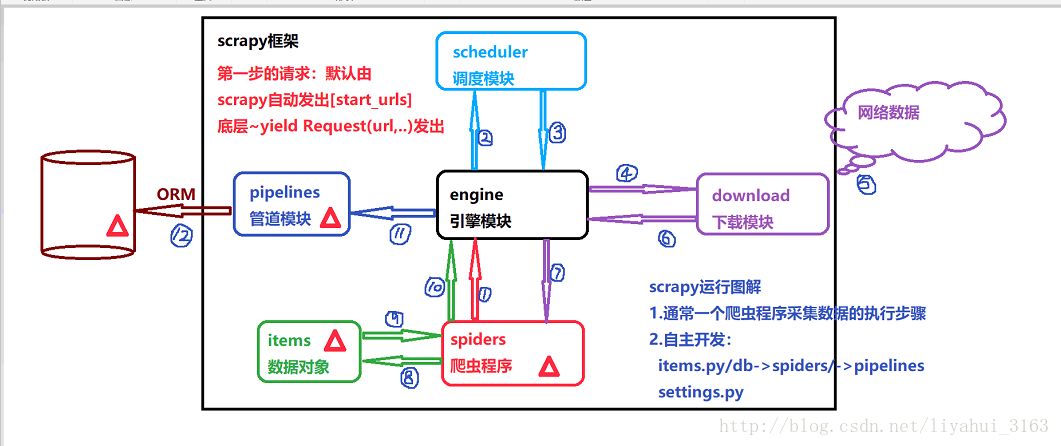
1,安装 scrapy 链接 查看即可。
2,新建scrapy项目
scrapy startproject 项目名
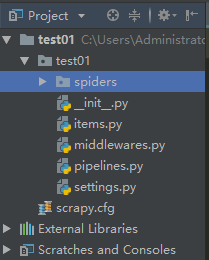 目录结构图
目录结构图
3,cd到项目名下,创建任务。
scrapy genspider 爬虫名 www.baidu.com(网站网址)
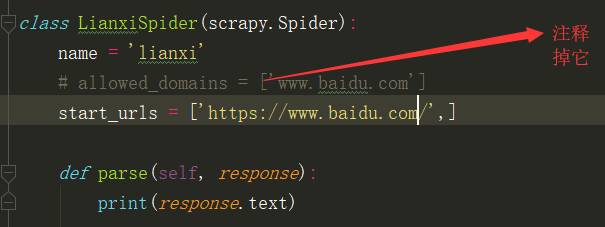
参数解析:
name,
定义spider的名字的字符串,必须是唯一的,name是spider的最重要的属性,而且是必须的
allowed_domains
可选,包含spider允许爬取的域名的列表,当offsiterMiddleware启用时,域名不在列表的url不会被跟进
start_urls
url列表,spider从该列表中开始进行爬取。 (列表生成式也可以实现分页抓取)
start_requests
该方必须返回一个可迭代的对象,对象中包含了spider用于爬取的第一个request.(加for循环,实现翻页抓取)
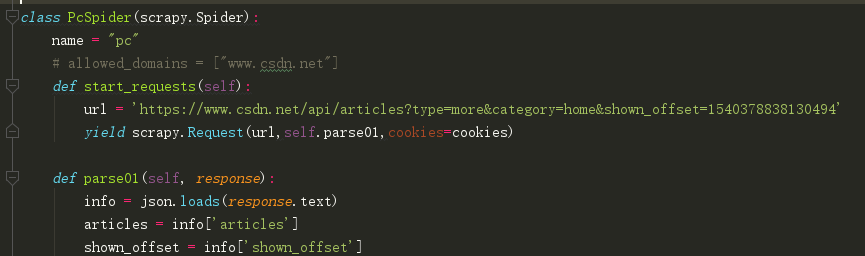
注:然后去setting里将 ROBOTSTXT_OBEY = False (不遵循网站的robots协议)
4,在项目的根目录下新建run.py 运行脚本,注意是根目录
from scrapy.cmdline import execute
execute(['scrapy','crawl','lianxi'])
我们的爬虫项目到此也就配置完毕,下面我来说一下setting里的配置说明
DOWNLOAD_DELAY = 2-----------设置爬取间隔
DEFAULT_REQUEST_HEADERS-----------设置头信息
ROBOTSTXT_OBEY = True-----------如果启用,Scrapy将会采用 robots.txt策略
AUTOTHROTTLE_START_DELAY = 5----------开始下载时限速并延迟时间
AUTOTHROTTLE_MAX_DELAY = 60------------高并发请求时最大延迟时间
CONCURRENT_REQUESTS = 16-----------开启线程数量,默认16
setting中可以设置全局请求头信息,

当然在我们的爬虫程序中也可以,不过需要注意cookies的格式,
cookies = {'Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac': '1788*1*PC_VC',...... } 注意是键值对的形式
cookies 字符串转换为字典,
keys = [i.split('=',1)[0] for i in cookie.split('; ')]
values = [i.split('=',1)[1] for i in cookie.split('; ')]
res = dict(zip(keys,values))
print(res)
我们再来看看response的几个方法
url (string) – 这个响应的URL
headers (dict) – 这个响应的标题。字典值可以是字符串(对于单值标题)或列表(对于多值标题)。
status (integer) – 响应的HTTP状态。默认为200。
body (str) – 响应身体。它必须是str,而不是unicode,除非你使用了一个编码感知的Response子类,比如 TextResponse。
text 返回响应str
5,解析工具
1)然后我们再来看一下scrapy为我们封装的 css解析工具。
response.css('.text::text').extract()
这里为提取所有带有class=’text’ 这个属性的元素里面的text返回的是一个列表
response.css('.text::text').extract_first()
这是取第一条,返回的是str
print(response.css("div span::attr(class)").extract())
这是取元素属性
举例:

我来解析一下,在浏览器中我们获取到需要的标签,然后 遍历取到我们需要的标签内容以及它的href属性,注意写法。

css 查询集
2)xpath方法,这种解析方法我们会常用的,我们接着看
url = response.url+response.xpath('/html/body/div/div[2]/div[1]/div[1]/div/a[1]/@href').extract_first()
和原来用法基本一样,这里是获取一个url 然后跟网站的主url拼接了
print(response.xpath("//a[@class='tag']/text()").extract())
https://blog.csdn.net/gongbing798930123/article/details/78955597 这个网址上是xpath语法大全,我这里就不在多说。
3)当然,scrapy还为我们封装了re模块
>>> response.xpath("//span[contains(@class, 'bookmark-btn')]/text()").re('.*?(\d+).*')
['']
>>> response.xpath("//span[contains(@class, 'bookmark-btn')]/text()").re('.*?(\d+).*')[0]
''
不过,我更习惯用原生的re。
extract()解析:
1)extract()方法会把原数据的selector类型转变为列表类型
2)extract()会得到多个值,extract()[1]取第2个值
3)extract_first()得到第一个值,类型为字符串。extract_first(default='')如果没取到返回默认值
6,给Scrapy添加代理
给请求添加代理有2种方式,第一种重写start_request方法,第二种是添加download中间件。
第一种:
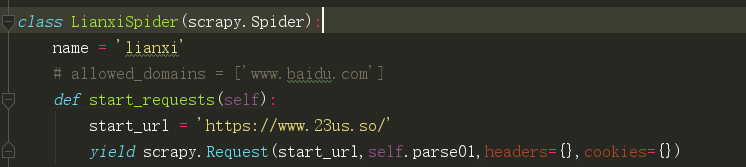
def start_requests(self):
start_url = 'http://httpbin.org/get'
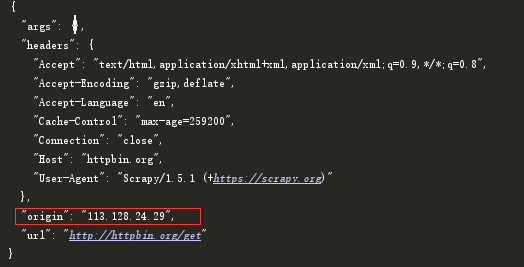
yield scrapy.Request(start_url,self.parse01,meta={'proxy': 'http://113.128.24.29:22121'})
只是在meta中加了一个proxy代理。然后可以测试了,我们通过抓取这个网站就可以返回我们的请求的信息,如:
第二种:
1.在middlewares.py中增加一个类,取名:ProxyMiddleware即代理中间件:
class ProxyMiddleware():
def process_request(self, request, spider):
request.meta['proxy'] = 'http://114.230.126.173:41472'
当然这里还可以设置请求头:
class AgantMiddleware(object):
def __init__(self):
self.user_agent = ['Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0',、、、、、、]
def process_request(self,request,spider):
request.headers['User-Agent'] = random.choice(self.user_agent)
然后在 setting中开启中间件:
DOWNLOADER_MIDDLEWARES = {
# 'test01.middlewares.Test01DownloaderMiddleware': 543,
'test01.middlewares.ProxyMiddleware': 543,
}
优先级随意,只要不重复即可,这是设置全局代理ip
7,POST请求
from scrapy import FormRequest ##Scrapy中用作登录使用的一个包
formdata = {
'username': 'wangshang',
'password': 'a706486'
}
yield scrapy.FormRequest(
url='http://172.16.10.119:8080/bwie/login.do',
formdata=formdata,
callback=self.after_login,
)
8,meta()传参用法,
假如需要从上一个函数传入下一个参数,我们需要。
上个函数中:
yield scrapy.Request(url,self.detail,meta={'title':title,'summary':summary,'views'})
下一个函数中:
response.meta['title']
接收就可以、
9,爬取信息储存
在item.py里定义需要储存字段。
class CsdnItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
summary = scrapy.Field()
views = scrapy.Field()
commits = scrapy.Field()
在爬虫程序中,
from ..items import CsdnItem def detail(self,response):
item = CsdnItem()
item['title'] = response.meta['title']
item['summary'] = re.sub(r'\s+','',response.meta['summary'])
item['views'] = response.meta['views'] return item
在piplines里,
class Test01Pipeline(object):
def process_item(self, item, spider): title = item['title']
summary = item['summary']
views = item['views']
return item
注:注释需打开
ITEM_PIPELINES = {
'csdn.pipelines.CsdnPipeline': 300,
}
scrapy 资料整合的更多相关文章
- mina学习资料整合
最好的资料当然是官方文档:https://mina.apache.org/mina-project/userguide/user-guide-toc.html 官方文档,配合源码中的example例子 ...
- Machine Learning & Data Mining 资料整合
机器学习常见算法分类汇总 | 码农网 数据挖掘十大经典算法 | CSDN博客 (内含十个算法具体介绍) 支持向量机通俗导论(理解 SVM 的三层境界)| CSDN博客 (强烈推荐关注博主) 教你如何迅 ...
- Weex学习资料整合
1.weex weex文档:http://weex.apache.org/cn/guide/index.html Weex Ui awesome-weex WEEX免费视频教程-从入门到放肆 (共17 ...
- Android + Eclipse + PhoneGap 2.9.0 安卓最新环境配置,部分资料整合网上资料,已成功安装.
前言:最近心血来潮做了一个以品牌为中心的网站,打算推出本地服务o2o应用.快速开发手机应用,最后选择了phonegap,这里我只是讲述我安装的过程,仅供大家参考. 我开发的一个模型http://www ...
- Android + Eclipse + PhoneGap 3.4 安卓最新环境配置,部分资料整合网上资料,已成功安装.
前言:广州花都论坛,打算推出本地服务o2o应用.快速开发手机应用,phonegap 我的小站,http://www.w30.cn/ 如果有什么问题也可以到小组留言,可以的话,贡献一个ip:) phon ...
- eigenface资料整合
把图片映射到能最好区分的空间(pca),在这个空间同类是聚集的,而不同类之间间隔大.这相当于一个模型,把验证集也映射到此空间,然后利用knn对验证集分类. pca:https://wenku.baid ...
- cors跨域的前端实现---根据资料整合的
1.服务端 搁response中增加Access-Control-Allow-Origin:‘*’ eg: context.Response.AddHeader("Access-Contr ...
- Scrapy开发指南
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. Scrapy基于事件驱动网络框架 Twis ...
- Dedecmsv5.7整合ueditor 图片上传添加水印
最近的项目是做dedecmsv5.7的二次开发,被要求上传的图片要加水印,百度ueditor编辑器不支持自动加水印,所以,找了很多资料整合记录一下,具体效果图 这里不仔细写dedecmsv5.7 整合 ...
随机推荐
- hive中分组取前N个值的实现
背景 假设有一个学生各门课的成绩的表单,应用hive取出每科成绩前100名的学生成绩. 这个就是典型在分组取Top N的需求. 解决思路 对于取出每科成绩前100名的学生成绩,针对学生成绩表,根据学科 ...
- MVC-READ3(视图引擎主要类关系图)
- MyBatis 查询缓存
增删改操作对一级缓存的影响:增删改操作都会清空一级缓存,无论是否提交
- spring集成mybatis配置多个数据源,通过aop自动切换
spring集成mybatis,配置多个数据源并自动切换. spring-mybatis.xml如下: <?xml version="1.0" encoding=" ...
- 01b-1: 性能测度
- 流形学习 (Manifold Learning)
流形学习 (manifold learning) zz from prfans............................... dodo:流形学习 (manifold learning) ...
- 查看binlog的简单方法!
今天学到一个牛逼的东西,不用打开binlog文件就可以查看binlog里的event事件. 命令为:show binlog events in 'mysql-bin.000001' from 4 li ...
- 不要怂,就是GAN (生成式对抗网络) (五):无约束条件的 GAN 代码与网络的 Graph
GAN 这个领域发展太快,日新月异,各种 GAN 层出不穷,前几天看到一篇关于 Wasserstein GAN 的文章,讲的很好,在此把它分享出来一起学习:https://zhuanlan.zhihu ...
- mysql的.sql文件头部 /*!32312 IF NOT EXISTS*/;
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RE ...
- BZOJ 4326 NOIP2015 运输计划 (二分+树上差分)
4326: NOIP2015 运输计划 Time Limit: 30 Sec Memory Limit: 128 MBSubmit: 1930 Solved: 1231[Submit][Statu ...