Spark的基本原理
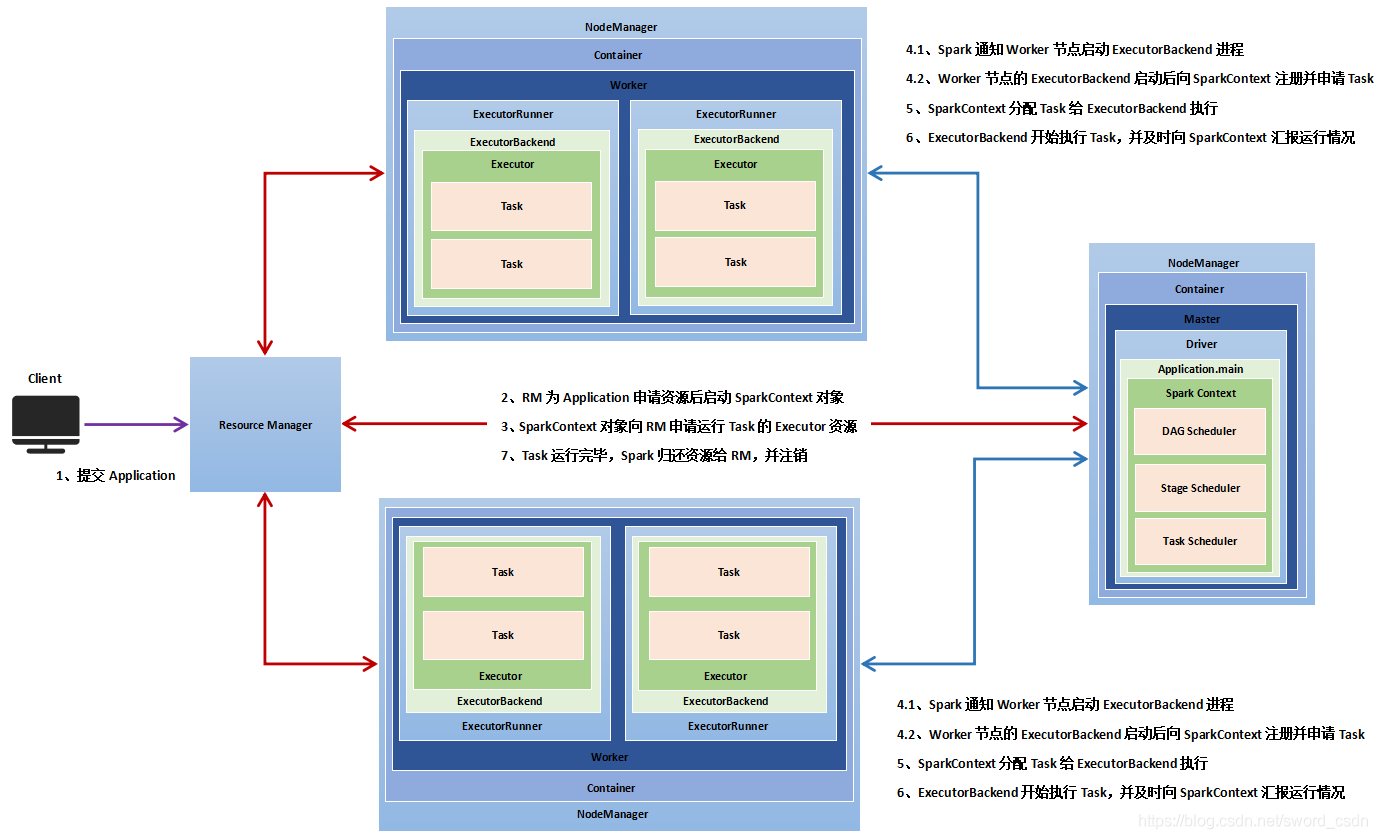
Application
Application是在使用spark-submit 提交的打包程序,也就是需要写的代码。
完整的Application一般包含以下步骤:
(1)获取数据
(2)计算逻辑
(3)输出结果(可以是存入HDFS,或者是其他存储介质)
Executor
Executor是一个Application运行在Worker节点上的一种进程,一个worker可以有多个Executor,一个Executor进程有且仅有一个executor对象。executor对象负责将Task包装成taskRunner,并从线程池抽取出一个空闲线程运行Task。每个进程能并行运行Task的个数就取决于分配给它的CPU core的数量。
Worker
Spark集群中可以用来运行Application的节点,在standalone模式下指的是slaves文件配置的worker节点,在spark on yarn模式下是NodeManager节点。
Task
在Excutor进程中执行任务的单元,执行相同代码段的多个Task组成一个Stage。
Job
由一个Action算子触发的一个调度。
Stage
Spark根据提交的作业代码划分出多个Stages,每个Stage有多个Tasks,这些Tasks负责并行处理他们所属的stage里面的代码。
DAGScheduler
根据Stage划分原则构建的DAG(有向无环图,理解为执行流程还行),并将Stage提交给Taskscheduler。
TaskScheduler
TaskScheduler将TaskSet提交给Worker运行。
RDD
弹性分布式数据集。
Resilient Distributed Dataset,是Spark中最基本的数据抽象,它代表一个不可变、可分区、元素可并行计算的集合。简单点说,从数据文件中获取到的数据会被放到RDD中。
它具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。它允许在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD的属性
(1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
(2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
(3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
(4)一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
(5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
————————————————
原文链接:https://blog.csdn.net/sword_csdn/article/details/103101878
Spark的基本原理的更多相关文章
- Spark SQL概念学习系列之Spark SQL基本原理
Spark SQL基本原理 1.Spark SQL模块划分 2.Spark SQL架构--catalyst设计图 3.Spark SQL运行架构 4.Hive兼容性 1.Spark SQL模块划分 S ...
- Spark SQL 基本原理
Spark SQL 模块划分 Spark SQL架构--catalyst设计图 Spark SQL 运行架构 Hive的兼容性
- Spark学习资料共享
链接相关 课件代码:http://pan.baidu.com/s/1nvbkRSt 教学视频:http://pan.baidu.com/s/1c12XsIG 这是最近买的付费教程,对资料感兴趣的可以在 ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- 小白学习Spark系列三:RDD常用方法总结
上一节简单介绍了Spark的基本原理以及如何调用spark进行打包一个独立应用,那么这节我们来学习下在spark中如何编程,同样先抛出以下几个问题. Spark支持的数据集,如何理解? Spark编程 ...
- Spark SQL概念学习系列之Spark SQL概述
很多人一个误区,Spark SQL重点不是在SQL啊,而是在结构化数据处理! Spark SQL结构化数据处理 概要: 01 Spark SQL概述 02 Spark SQL基本原理 03 Spark ...
- 成功入职ByteDance,分享我的八面面经心得!
今天正式入职了字节跳动.办公环境也很好,这边一栋楼都是办公区域.公司内部配备各种小零食.饮料,还有免费的咖啡.15楼还有健身房.而且公司包三餐来着.下午三点半左右还会有阿姨推着小车给大家送下午茶.听说 ...
- spark第一篇--简介,应用场景和基本原理
摘要: spark的优势:(1)图计算,迭代计算(2)交互式查询计算 spark特点:(1)分布式并行计算框架(2)内存计算,不仅数据加载到内存,中间结果也存储内存 为了满足挖掘分析与交互式实时查询的 ...
- spark第二篇--基本原理
==是什么 == 目标Scope(解决什么问题) 在大规模的特定数据集上的迭代运算或重复查询检索 官方定义 aMapReduce-like cluster computing framework de ...
- Spark 准备篇-基本原理
本章内容: 待整理 参考文献: <深入理解SPARK:核心思想与源码分析>(第2章) Spark的作业提交及运行流程的异同
随机推荐
- C++ 多线程的错误和如何避免(6)
加锁的临界区要尽可能的紧凑和小型 问题分析: 当一个线程在临界区内执行时,所有其他试图进入临界区的线程都会被阻止,所以我们应该保证临界区尽可能的小.比如, void CallHome(string m ...
- 如何处理Long类型精度丢失问题?
一.现象与分析: 1.1. 现象 前后端交互,当后端传一些值给前端的时候,如果是long类型,有可能会出现数字太大而前端接收不了(java中的long大于js的number)而导致数据不一致,精度会丢 ...
- 麒麟系统开发笔记(十二):在国产麒麟系统上编译GDAL库、搭建基础开发环境和基础Demo
前言 麒麟系统上做全球北斗定位终端开发,北斗GPS发过来的是大地坐标,应用需要的是经纬度坐标,所以需要转换,可以使用公式转换,但是之前涉及到了山He智能一个项目使用WG. 大地坐标简介 概述 ...
- 多态,__new__魔术方法,单态模式---day22
1.多态 # ### 多态:不同的子类对象,调用相同的父类方法,产生了不同的执行效果 ''' 关键字:继承 改写 ''' class Soldier(): #攻击 def attack(): pass ...
- Spingboot替换掉jar包里面的@Bean
问题 如下图,我们需要替换掉JsoncCfg配置类里面的YCloudObjectMapper这个Bean. 这个Bean是在依赖的第三方jar包中的,因为用了@Bean而不是像@Component这种 ...
- 【Azure Redis 缓存】遇见Azure Redis不能创建成功的问题:至少一个资源部署操作失败,因为 Microsoft.Cache 资源提供程序未注册。
问题描述 在中国区微软云上创建Redis失败.收到的错误消息为: { "code": "DeploymentFailed", "message&quo ...
- Jmeter 之 forEach控制器
1 添加方法: 线程组右键-> 添加 -> 逻辑控制器 ->ForEach控制器 2 作用: 可以更方便JMeter后置处理器提取出来的多组数据,也可以定义具有特定规则的数据,用 ...
- C++ 错误 具有类型“const sort”的表达式会丢失一些 const-volatile 限定符以调用“bool sort::operator ()(int,int)” 如下:环境 vs2019 内容:set内置函数排序
C++ 错误 具有类型"const sort"的表达式会丢失一些 const-volatile 限定符以调用"bool sort::operator ()(int,int ...
- [学习笔记] Rocket.Chat 安装与设置启动项
这篇文章主要介绍手动安装的方式来安装Rocket.Chat,在Rocket.Chat官方有三种安装方式, 面向开发人员的直接使用meteor部署 传统的源码编译安装 Docker方式部署 接下来分别介 ...
- 一款开源、免费、跨平台的Redis可视化管理工具
前言 经常有小伙伴在技术群里问:有什么好用的Redis可视化管理工具推荐的吗?, 今天大姚给大家分享一款我一直在用的开源.免费(MIT License).跨平台的Redis可视化管理工具:Anothe ...