C语言的简单学习
C语言是编译型语言,先编译再运行,通常用gcc进行编译,于是安装了Ubuntu操作系统。至于编辑器,VS Code也能用,先sudo apt install build-essential gdb,再在VS Code安装C/C++ extension,就可以进行开发了。

C语言程序都是 .c文件结尾,新建一个hello_world.c 文件
#include <stdio.h>
int main(void) {
printf("Hello World \n");
return 0;
}
#include<stdio.h>,#表示指令,include 包含,stdio.h 是一个以.h结尾的文件,连起来就是把stdio.h文件包含进来,把stdio.h文件内容复制粘贴到 #include <stdio.h>这一行代码所在的地方。int main(void) 定义main函数,函数中调用printf, 然后返回0。C程序都是从main函数开始执行,所以必须有main函数。main函数调用哪个C函数,就要include这个函数所在的头文件。所以一个C语言程序要包含main函数,调用系统函数,还要include头文件。打开VS Code命令行,gcc hello_world.c进行编译,生成了a.out,再./a.out,输出Hello World。
变量声明
使用变量之前,要先声明变量,就是先在内存中开辟一块空间,再使用。C语言是强类型语言,声明变量的时候要指定变量类型。基本数据类型有整数,字符,小数
整数有int, short,long类型,主要是所占的内存空间不同,能存储的数值范围不同。C语言的整数还分有符号(signed)和无符号(unsigned)。有符号就是它可以存储正数,负数和0。无符号则只能存储0和正数。默认情况下,所有整数类型都是singed的。如果要用无符号整型,用unsiged int, unsiged short, unsigned long,在类型前面加unsigned。浮点数(小数)就是float,double,long double,浮点数全是有符号的。C语言没有规定每一个类型的所占内存空间是多大,也就是说,在不同的机器上,int可能占2个字节,也可能占4个字节,它只保证了大的类型要大于等于小的类型所占的空间,为此,提供了sizeof操作符, 获取每一个类型所占的字节。后面出现了int8_t,int16_t, int32_t, int64_t类型, 在每一个机器上都占8,16,32,64个字节。
char类型,用来存储字符(字母或标点符号),比如 'A',所以它只占1个字节。但实际上,char类型存储的是数字,存储字符的时候,根据字符编码表,把字符转化成数字,因此char类型也可以用来表示小的整数,不过,有些编译器把char实现为有符号类型,而有些编译器把它实现为无符号的类型,所以如果要表示数字,最好使用singed char 或unsigned char。转义序列(字符),就是代码中不能或者很难用键盘输入的字符,比如,换行符,如果按enter, 编辑器会解析成下一行,不会在代码中保留下来,还有空格。 The space, tab and the newline are often referred to collectively as white space character, because they cause space to appear rather than making marks on the page when they are printed.
C语言没有布尔类型,使用数字来表示布尔类型,0表示false,1表示true。但后来, 增加了_Bool 类型和<stdbool.h>,可以使用bool声明变量,也可以使用true 和false, 但本质上还是0和1,它们只是对0 和1 进行重定义。
变量名的长度:编译器只识别变量名的前63个字符,后面的字符会忽略,所以变量名最好不要超过63个字符。声明了变量,就要给它赋值,声明变量的同时进行赋值称为初始化。需要注意的是,字面量也是有类型。3就是int类型,整数默认是int类型,如果字面量特别大,int放不下,那该数就成了long。3.0是double类型,浮点数字面量默认是double类型。后面加f表示float类型,3.0f是float类型。字面量有类型,赋值时不要类型不匹配,因为赋值时,类型不匹配也不会报错。int a = 33.33; 会把double类型的33.33 转化成给int,a的值就是33,C竟然不报错。
#include <stdio.h>
#include <stdbool.h> int main(void) {
int num = 5;
char grade = 'a'; // char类型用单引号
signed char char_num= 3; float f = 4.0f;
double d = 3.0; bool isTrue = false;
// 当使用printf输出int时,用%d.使用%c 来打印字符。 浮点型用%f进行输出。
printf("num: %d, grade: %c, char_num: %d, float: %f, double: %f, bool_num: %d \n",
num, grade, char_num, f, d, isTrue);
// 可以使用sizeof() 查看类型占多少个字节,比如sizeof(int). 在printf 中使用%zd进行输出
printf("size of int: %zd \n", sizeof(num));
}
操作符、表达式和语句
算术运算符(+, -, *, /, %, ++, --) 、比较操作符(>, <, ==, >=, <=) 、逻辑运算符(, &&, || , !) ,所有语言都差不多。操作符加上它的操作数就是表达式,3+4就是表达式,表达式后面加;号就成了语句,C语句以分号结尾,3+4;就是语句,单个分号;也是一个语句,表示空语句,什么都不做。语句就是对计算机下达的指令,C程序由一条条语句组成。条件语句(if else),循环语句(while, for) 也是和其他语言一样,几个细节需要注意
两个整数相除,结果为整数,舍去小数(truncate toward zero)。取模运算,不能用于小数。a÷b=c…d,c是商,d是余数. c的数值是|a|/|b|, 正负号由a和b的负号数量决定;d的正负号和a相同,数值为 a-(a/b)*b.

-11 %5的运算
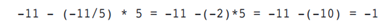
浮点数的计算是不精确的,因为浮点数并不能准确地表示小数,为什么呢?先看一下,在0和1之间有多少个整数?只有2个,0和1。但有多少个小数呢?0.1, 0.01, 0.001, 0.0.......01, 无穷多个,由于计算机内存有限,所以无法表示所有的小数,只能表示某些特定小数,其它无法表示的小数用近似数表示,这就会产生误差。小数点位数越多,越能表示的精确, 如果一个小数是0.123456798345, float 就会 取前7-8位,double 类型会取前15-16 位小数(四舍五入),会更精确一点。由于计算机是二进制,它也不能很好的表示十进制小数,比如,0.1, 如果把0.1 赋值给一个浮点数变量,变量实际存储的值可能是 0.0999999999999987,同样存在四舍五入的原因,所以浮点数比较大小,可以使用> 或 <,最好不要比较相等,因为稍微四舍五入,就会导致两数不相等,尽管逻辑上,它们应该相等。可以使用近似比较,只要两数相减,大于我们认为的最小值,就认为它们相等。(fabs(response - ANSWER) > 0.0001。
自动类型转换。计算机在做算术运算时,操作数必须大小相同且存储方式一致。大小指的是操作数在内存中占用的空间。比如int是4个字节,char是1个字节,它们的大小就不同。计算机会把两个16-bit的整数直接相加,但它不会把一个16-bit的整数和一个32-bit的整数直接相加,也不会把32-bit的整数和32-bit的小数直接相加。如果表达式中,操作数类型不一致,就会自动类型提升(小类型转换成大类型),char 和short, 不管是有符号,还是无符号,都会提升成int 或unsigned int。3+4.5,3会提升double类型,整个表达式的结果是double类型的7.5。表达式也有类型,赋值的时候要注意,因为赋值时类型不匹配,也不会报错。int a = 3 + 4.5; 7.5 会自动转化成int,a的值为7。如果必须这样操作,最好使用强制类型转化,把想要转化成的类型用()括起来,然后放到要转化值前,int a = (int ) (3 + 4.5);
由于使用0和1,而不是true 和false 关键字,表达式4 > 5结果是0 ,4 < 5的结果是1,在if,while等条件表达式中,非0数字也被认为是true。
赋值操作也是一个表达式,会得到一个值。v = e的值是赋值过后的v。如果i是int类型,i=72.99的值是72,而不是72.99,1 + (i = 72.99) 的值为73。程序就是求值,如果求值的过程中改变了其它东西,就是产生了副作用。(i=72.99)求值是72,但同时,它也改变了变量i的值,这就是副作用。如果一个表达式中有多个副作用? 怎么执行,需要序列点。序列点(sequence point)是程序执行过程中的一个点,在该点上,所有的副作用都必须执行完,才能进入下一步。语句结尾的分号是序列点,每一行语句中的所有副作用都执行完,才能执行下一行语句。if和while的测试条件也是序列点,只有测试条件中的所有副作用都执行完毕,才能执行if 和while语句块。逗号也是序列点,ounces++, cost = ounces * 2 ,ounces++完成后,再执行ounces * 2。逻辑表达式也是从左到右执行,&& 和 || 也是序列点,它们前面的表达式中的所有副作用,都执行完,才执行后面的表达式。子表达式不是序列点,完整表达式才是。y = (4 + x++) + (6 + x++); 4 + x++ 是子表达式,所以C不保证执行完它之后,x会加1,后面6+x++中x的值不确定,C也不保证,先执行哪一个子表达式,表达式(a+b) * (c -d )中,不知道(a+b)先计算,还是(c -d )先计算,所以不要写这样的表达式,但整个赋值表达式是完整表达式,且后面有;,都是序列点,C保证,执行下一句的时候,x会被加两次。
求值时,先看优先级,再看结合律(从左到右还是从右到左执行),最终有4个操作符(逗号,&&,||, ?: )对整个表达式的顺序施加一定的控制,要么一个表达式执行完,再执行另外一个表达式,要么一个表达式,完全不执行。除此之外,编译器按照自己的顺序来求值表达式。

函数
C语言的函数比较特殊,函数的声明和函数的定义是分开的。函数声明就是函数接收什么参数,返回什么类型的值,也称为函数原型(签名),函数原型以;结尾,所以函数声明的格式为 返回值类型 函数名(参数列表); 函数使用之前,要先声明它。
// 不要忘记后面的;分号,它表示是声明函数,而不是定义函数
void starbar(void); // void作为参数,表示函数不接受参数,void作为返回值,表示函数没有返回值
int square(int number); // 函数接受一个int类型的参数,返回一个int类型的值。
函数定义就是实现函数的功能。函数返回值 函数名(参数类型 参数名,.....) {},函数定义的中函数头必须和函数原型保持一致
void starbar(void) { // 函数头
for (size_t count = 0; count < 10; count++){
putchar('*');
}
printf("\n");
}
int square(int number){ // 函数头
return number * number;
}
调用函数,就是函数名后面加(),如果函数接受参数,就在括号中提供参数,提供的参数的类型和个数(实参)要与函数声明中定义的参数类型和个数(形参)保持一致。如果参数需要计算,C语言并不保证,哪一个参数先计算,有可能第二个参数,比第一个参数先进行计算。
int main(void) {
int num = square(2);
printf("2的平方 %d \n", num);
starbar();
return 0;
}
函数的调用都是按值传递,实参的值(如果实参是表达式,先求值)会被复制给形参。需要注意的是,函数的调用如果形参和实参类型不匹配,C不会报错,而是隐式地把实参转化成形参的类型,比如square('!'), '!' 会转化成int类型的33。返回值也是一样,如果返回值和函数定义的返回值类型不一样,先把返回值转换成定义的类型再返回,假设 square() 中number * number 的结果就5.23,由于返回int,函数实际的返回值是5,虽然return 5.23。不建议使用隐式的类型转化。
数组
数组就是数据类型相同的一组元素,所以声明数组时,要声明数组中元素的个数(数组长度)以及元素的类型,格式为:元素类型 数组名[数组长度],比如 int num[5]。数组长度一旦确定,就不能改了。声明的时候可以初始化,使用{} 把初始值包括起来,初始值之间用,隔开。初始化的方式也有很多
int n[5] = {32, 27, 64, 18, 95}; // 显示初始化数组中的每一个值
int n[5] = {3}; // 初始值列表{}中的值比数组的长度小,没有被显示初始化的元素,值为0。n[0]是3, n[1]到n[4]都是0
int n[] = {1, 2, 3, 4, 5}; // 声明数组并初始化,可以不用声明数组的长度,编译器会自己计算
int arr[6] = {[5] = 212}; // 指定初始化,arr[5]是212, 数组其它元素全初始化为0
//下面也是指定初始化,只不过指定初始化后面还有值,[4] = 31,30,31,后面的值被用来初始化后面的值,就是[5] =30, [6]=31
// 如果对同一个元素初始化2次,最后面的会覆盖前面的。[1]=29 会覆盖前面的28。没有被初始化到的元素取值还是0
int days[] = {31,28, [4] = 31,30,31, [1] = 29};
C语言并没有提供操作数组的方法,length要用sizeof来计算,sizeof(数组名)/sizeof(数组第一个元素)。其他操作基本靠for循环来完成。sizeof运算符很特殊,“sizeof表达式”中的子表达式并不求值,它只根据子表达式得到它的类型,然后把这种类型所占的字节数返回。由于sizeof 表达式中的子表达式不需要求值,所以在编译时就能知道它的大小,比如sizeof n的值是20 ,sizeof n[0] 的值是4,就可以把sizeof n/sizeof n[0] 替换成常量5,这是一个常量表达式。
int main(void){
int n[5] = {32, 27, 64, 18, 95};
for (size_t i = 0; i < sizeof(n) / sizeof(n[0]); i++){
printf("element %d \n", n[i]);
}
return 0;
}
二维数组是数组的数组,首先是个一维数组,一维数组每一个元素又都是一维数组。一维数组有3个元素,每一个元素又都是长度为5的数组,int arr[3][5]。取二维数组中的元素就要指定第几个数组和数组中第几个元素,arr[1][2]就是第二个数组第三个元素。对二维数组数组的操作通常 是嵌套for循环
int main(void) {
int arr[3][5];
for (size_t i = 0; i < 3; i++) {
for (size_t j = 0; j < 5; j++) {
arr[i][j] = 1; // 二维数组所有元素赋值为1
}
}
printf("Element %d \n", arr[1][2]);
return 0;
}
指针
在内存中存放东西,都是有地址的,指针就是内存地址,指针变量就是存放内存地址的变量(变量的值是内存地址)。声明指针变量的方式是 (存放谁的地址)谁的类型 * 变量名。int *yPtr,yPtr就可以存储int类型变量的地址。&操作符能取到变量的内存地址(变量在内存中的位置),比如 int y = 5; &y就可以取到变量y的地址,也就可以把它赋值给一个指针变量。int *yPtr = &y;

yPtr中保存的是变量y所在的内存地址(yPtr指向y),通过yPtr也可以找到变量y,这要用到 *操作符(指针操作符),也称为解引用。当*用到一个指针变量名前面,它是解引用,找到指针指向的变量或找到变量中保存的内存地址。*yPtr 就找到了y。*yPtr就等价y。对y进行什么操作,就可以*yPtr 进行什么操作。一个变量在内存中占多个字节,第一个字节的地址就是变量的地址。如果一个变量num的占据4个字节,2000, 2001, 2002, 2003, 那么变量num的地址是2000。指针可以被初始化为NULL, 0, 表示不指向任何内容。
一维数组和指针
当数组名在一个表达式中时,它会转换成地址,数组首元素的地址。如果a是个数组,在表达式中,a和 &a[0]等价,都是地址常量,因为在程序执行的过程中,数组一旦在内存中开辟了空间,就不会变了。所以不能把数组作为一个整体,赋值给另外一个数组
int oxen[SIZE] = {5, 3, 2, 8};
int yaks[SIZE];
yaks = oxen; /* 不允许 数组名是一个常量 */
由于数组名会转化成地址,所以当把它传递给一个函数时,函数接收到的是数组首元素的地址,因此也就不能知道数组的长度了。在C中,操作数组的函数有两个参数,一个是地址,一个是数组的长度。地址的表示方式有两种,int sum(int *ar, int n);,一种是int sum(int arr[], int n);, 通常使用第二种,更清晰表明参数是数组
int sum(int arr[], int n) {
int total = 0;
for (int i = 0; i < n; i++)
total += ar[i]; // 用数组的方式来操作指针, ar[i] 相当于 *(ar + i). 数组名虽然是一个指针,但也能通过下标的方式来操作指针
return total;
}
当指针指向数组元素时,指针可以做算术运算(+, -) 和比较(<, >, <=, >=, ==, !=)运算。假设a是一个数组,p是一个指针,指向arr[i],p + j, 就是指向数组a[i + j],指针+1 加的是一个存储单元,比如double占8个字节,它就加8个字节,正好是double数组的下一个元素,这也是声明指针变量的时候,指定指针类型,要加多少个字节,获取指针变量指指向的变量的值时,要读多少个字节。
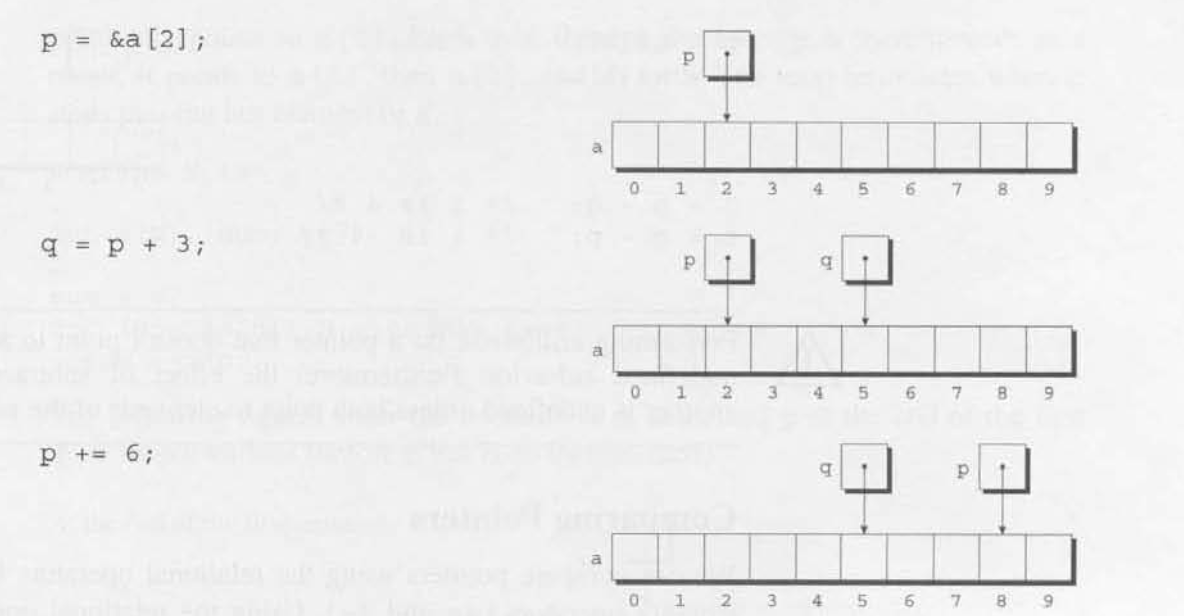
p -j 则指向 a[p - j ]
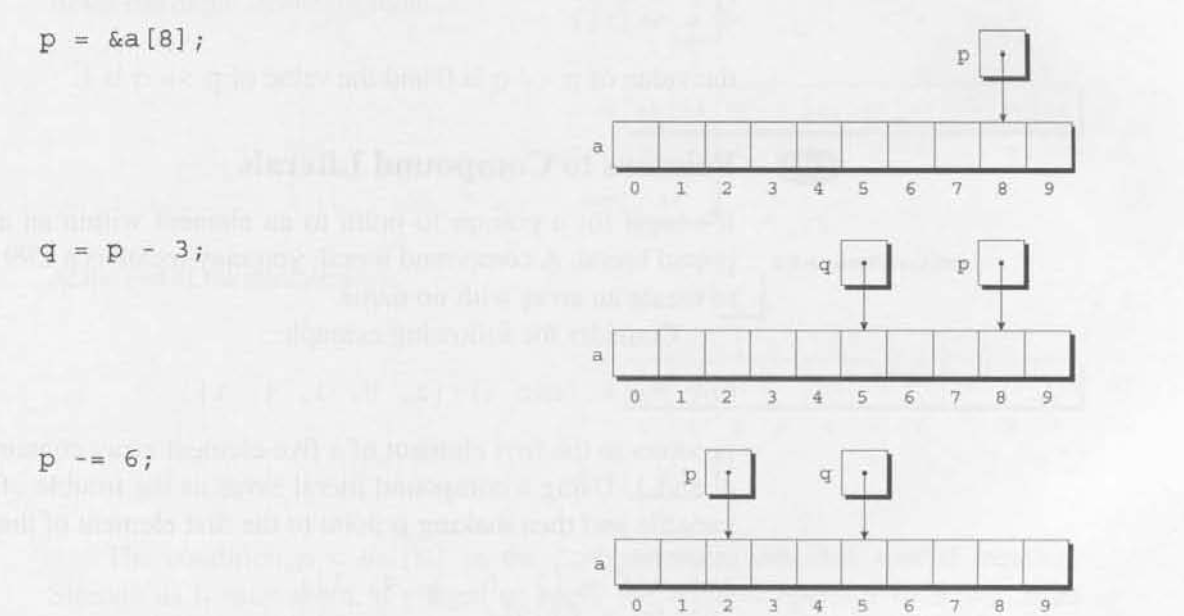
两个指针相减,则产生两个指针之间的distance,
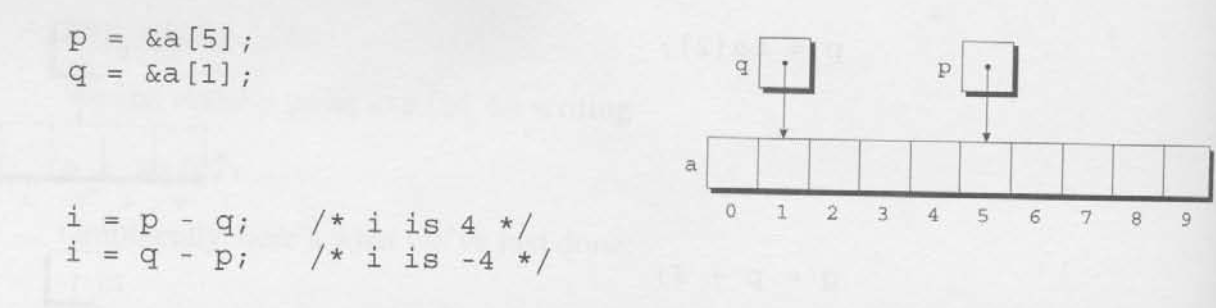
另外一种用纯指针的方式来操作数组,
#include <stdio.h>
#define SIZE 5
int sum(int *start, int *end) {
int total = 0;
while (start < end) {
total += *start;
start++; // 指针变量的值,是可以变化的, 进行算术运算。
}
return total;
} int main(void) {
int arr[SIZE] = {20, 40, 50, 30, 10}; int *start = arr; // 由于是地址, 可以赋值给指针变量
int *end = arr + SIZE; printf("total: %d \n", sum(start, end));
return 0;
}
start是数组首元素地址,相当于数组0的位置,start + 1是第一个元素,start + 2 是第二个元素,数组大小是SIZE,start + SIZE - 1就是数组最后一个元素的地址,但C保证start + SIZE 也是有效地址,可以用于比较大小,但不保证该地址内的元素是有效无素,所以不要取这个地址内存的值。
函数接受到的是数组的地址,所以函数中对数组的改变,也会改变函数外面的数组。如果不想改变原数组,函数参数加const修饰,const int arr[]。
指针和二维数组
二维数组,尽管在视觉上,可以看作一个行列矩阵,如下二维数组
int arr[3][4] = {
{11,22,33,44},
{55,66,77,88},
{11,66,77,44}
};
可以看做

但是在内存中,它们实际上是按行存储的(row-major order)

数组名arr是数组首元素的地址,对于二维数组来说,数组首元素也是一个数组(4个int的数组),所以数组名arr是4个int元素数组的地址。arr+1 直接越过4个int,指向二维数组的第二个元素。arr[0], arr[1], arr[2] 也是一维数组,相当于一个普通的一维数组名,arr[0], arr[1], arr[2] 是对应在一维数组的首元素的地址。arr[0]+1只是指向一维数组的第二个元素。*arr相当于来到第一个数组元素(一维数组 arr[0]),*(arr+1)相当于来到数组的第二个元素(一维数组arr[1])。arr[0], arr[1] 也是一维数组,对它进行解引用,就相当于数组的第一个元素了,int类型了。变量保存的是地址,变量的值是地址,才能解引用。假设二维数组 int zippo[4][2]
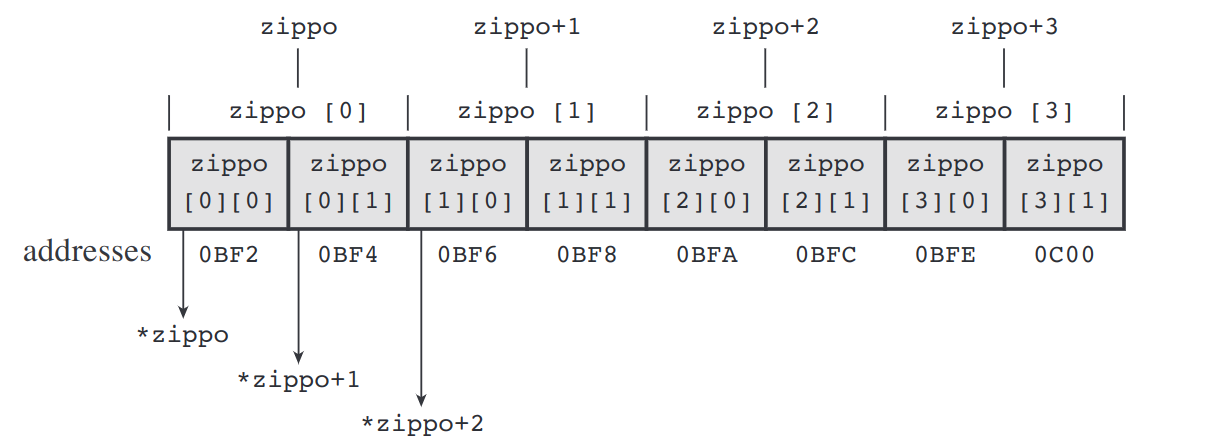
如果把二维数组作为参数传递函数,怎么表示参数?如果用指针表示,int (*pt)[4], p指针变量指向了一个数组,这个数组有4个元素,每一个元素的类型是int,整个函数原型是int sum2d(int (*pt)[4], int rows); 就像一维数组一样,参数通常用数组表示法,int sum2d(int ar[][4], int rows); rows 表示数组的长度,4表示二维数组中每一个一维数组的长度,因为操作二维数组是两个for循环,它们都需要怎么终止循环。但这种做法不够通用,C99 有了变量长度数组(VLA: variable-length array)的概念,就是声明数组的时候,数组长度可以是一个变量, 因为在以前,数组的长度必须是常量。
int quarters = 4;
int regions = 5;
double sales[regions][quarters];
声明之后,数组的长度就不会变化了。再强调一下,VLA是声明的时候,长度是变量,而不是,数组长度是可变的,在C中,数组的长度一旦确定,就不会再变化了。可以用VLA来处理二位数组,int sum2d(int rows, int cols, int ar[rows][cols]);
// ar是 VLA,数组的长度是由前面的参数n决定的,因此参数的顺序非常重要
int sum2d(int rows, int cols, int ar[rows][cols]){
int tot = 0; for (int r = 0; r < rows; r++) {
for (int c = 0; c < cols; c++)
tot += ar[r][c];
}
return tot;
}
数组传参时,还有一个数组字面量(复合变量)的概念,复合变量,不提前声明,使用时,直接创建,没有名字,比如声明数组复合变量
total = sum2d(2, 3, (int []){3, 0, 3, 4, 1})
函数名也是地址,一个函数声明一个指针形参,就可以接受函数。char (*p)(void),就是声明一个p指针变量,可以接受一个函数。通过指针变量来调用函数, (*p)() , 其实直接调用 pf()也可以
C语言函数调用最大的特点是,它能接受指针,所以获取函数的执行结果,并不一定非要从函数的返回值获得,而是可以使用参数获得。定义一个变量,把变量的地址做为参数传递给函数,函数内的操作改变了外部变量,可以通过函数外的变量获取函数操作的结果,函数的调用都是同步的。
字符串
C语言中没有字符串类型,用char类型的数组来表示字符串。都是char类型的数组,C是怎么知道它是字符串的?看一下字符串的存储,虽然没有字符串类型,但有字符串字面量,"Zing went the strings of my heart!" 就是字符串字面量。

当C碰到一个长度为n的字符串时,它会在内存中开辟n + 1个空间,然后把每一个元素都放入数组中,多申请的一个的1是放\0(空字符),表示字符串的结束。char数组存储字符串时,数组的长度要比实际存储的字符串的长度大1.’ char name[40] 只能存储长度为39的字符串。当然,也可以少放一点,比如
char name[40] = "sam";
没有占用的数组元素全设置为\0(空字符)。char str[] = {'H', 'E', 'L', 'L', 'O', '\0'}; 就是个字符串,char str[] = {'H', 'E'}就是个普通char数组。字符串字面量是不可变的,由于用数组表示,字符串的值是它的第一个字符的地址。
const char *colorPtr = "blue"; // *sPtr表示它是一个指针,指向的是const char类型,也就是说不能通过指针改变它指向的变量的值。
两种形式
const char *pt1 = "Something is pointing at me.";
const char ar1[] = "Something is pointing at me.";
数组形式(ar1[])会在计算机内存中开辟29个连续的内存空间,把字符串字面量复制到数组中。通常来说,字符串字面量放到静态内存中。这时字符串字面量有两副副本,一份在静态内存中,一份在数组ar1中。指针形式*pt1,只是为指针变量pt1开辟一块内存空间,然后把静态内存的字符串字面量首字符地址赋值给它。字符串是常量,所以不能使用指针改变,但是数组形式不一样,因为数组中已经复制了一份。In short, initializing the array copies a string from static storage to the array, whereas initializ-ing the pointer merely copies the address of the string.
C语言提供了许多处理字符串的函数,函数原型都放到了string.h头文件中。stren() 返回字符串的长度,它是size_t 类型,要用%zd 打印, 碰到 \0 就停止。strcat()拼接字符串,接受两个字符串作为参数,把第二个字符串参数复制到第一个参数字符串的末尾
#include <stdio.h>
#include <string.h> int main(void) {
char flower[13] = "flower";
char addon[] = "add"; strcat(flower, addon);
puts(flower);
return 0;
}
strcat() 有一个问题,就是它不会检查第一个数组的长度是否能够放得下第二个参数,因此有了strncat(), 它能限制复制第二个字符串多少个字符。strncat(bugs, addon, 13), 它会复制addon的内容给bug时,在复制的过程中,如果达到13个字符,或遇到空字符\0,它就停止复制,然后,再在新的bug字符串的末尾添加空字符\0。也就是bug数组的长度,至少是,它本身字符串的长度 + 最大13个字符 + 结束符标志符\0
int main(void) {
const int BUGSIZE = 13;
char bug[BUGSIZE] = "flower"
char addon[] = "addddddddddddddd";
const int available = BUGSIZE - strlen(bug) - 1;
strncat(bug, addon, available);
puts(bug);
return 0;
}
strcmp() 比较两字符串的内容是否相同,如果相同返回0,如果不相同返回非0整数。strncmp()则是比较指定的前几个字符,相等返回0,不相等返回非0整数。
int main(void) {
char answer[] = "Grant";
char try[] = "GrAdd";
int no_right = strcmp(answer, try);
int right = strncmp(answer, try, 2);
printf("is right? %d \n", right);
return 0;
}
strcpy把一个字符串复制给另一个字符串,相当于赋值操作。要确保目的地有足够的空间来存储复制的字符串。
int main(void) {
char target[20];
strcpy(target, "Hi ho!"); /* assignment for strings */
target = "So long"; /* syntax error 数组名是常量 */
const char * orig = "beast";
char copy[] = "Be the best that you can be.";
strcpy(copy + 7, orig); // 需要注意的是复制的时候,原字符串(orig)的\0也会复制到新数组
return 0;
}
strncpy(),指定复制几个字符,当然如果要复制的字符串大短,碰到了\0,复制也就停止了,也就是说strncpy 复制停止的条件是,要么碰到了\0,要么达到了字数限制。如果要复制的字符大长,复制达到字数限制,那就没有字符串的\0的地方了,所以,复制的字数限制都是比目标数组小于1, 复制完成后,再手动添加\0。
int main(void) {
const int TARGSIZE = 5;
char qwords[TARGSIZE];
char temp[] = "Be the best that you can be.";
strncpy(qwords, temp, TARGSIZE - 1);
qwords[TARGSIZE - 1] = '\0';
puts(qwords);
return 0;
}
汉字如果按UTF-8编码,一个汉字占3个字节,这种字符在C语言中称为多字节字符(Multibyte Character)。printf("你好\n");相当于把一串字节(e4 bd a0 e5 a5 bd 0a 00) 写到终端,如果当前终端的驱动程序能够识别UTF-8编码就能打印出汉字,如果当前终端的驱动程序不能识别UTF-8编码(比如一般的字符终端)就打印不出汉字。也就是说,像这种程序,识别汉字的工作既不是由C编译器做的也不是由libc 做的,C编译器原封不动地把源文件中的UTF-8编码复制到目标文件中,libc 只是当作以0结尾的字符串原封不动地write 给内核,识别汉字的工作是由终端的驱动程序做的。
为了在程序中操作Unicode字符,C语言定义了宽字符(Wide Character)类型wchar_t和一些库函数。在字符常量或字符串字面值前面加一个L就表示宽字符常量或宽字符串,例如定义wchar_t c = L'你'; wcslen函数就可以取宽字符串中的字符个数. printf("%ls", L"你好\n");编译器会把它变成4个UCS编码0x00004f60 0x0000597d 0x0000000a 0x00000000 保存在目标文件中。printf的%ls 转换说明表示把后面的参数按宽字符串解释,不是见到0字节就结束,而是见到UCS编码为0的字符才结束,但是要write 到终端仍然需要以多字节编码输出,这样终端驱动程序才能识别,所以printf在内部把宽字符串转换成多字节字符串再write 出去。一般来说,程序在做内部计算时通常以宽字符编码,如果要存盘或者输出给别的程序,或者通过网络发给别的程序,则采用多字节编码。
restrict 也是是一个qualifier to a pointer type It tells the compiler that this pointer is not an alias of anything else; the memory it points at is only referenced through the pointer itself. Writing to other pointers will not change the value it points at, and writing through the pointer will not affect what other pointers read. 所谓alias, 就是同时有两个指针指向同一个内存地址,修改一个,就会引起另外一个的变化。所以当我们给一个restrict 指针赋值时,不能是一个alias的指针。
#include <stdio.h> void abc_restrict(int *a, int *b, int *restrict c)
{
*a += *c;
*b += *c;
} int main(void)
{
int x, y; x = y = 13;
abc_restrict(&x, &y, &x); //错误的。参数是的指针a和指针c 同时指向一个内存地址
printf("%d %d\n", x, y);
}
结构体
结构体是对一类实体的描述,有什么属性,类似于Java或JS中的类,但结构体只描述属性,不包含方法。结构体类型的定义,用struct,后面跟一个可选的tag名,然后{} 定义属性,最后以分号结尾
struct book {
char title[51];
char author[21];
float value;
}; // 以分号结尾
struct book library; 声明了结构体变量libaray。声明的时候可以初始化,大括号中的数据依次赋值给结构体中成员,如果Initializer中的数据比结构体的成员多,编译器会报错,如果Initializer中的数据比结构体的成员少,未指定的成员将用0来初始化,
struct book library = {"The Pious Pirate and the Devious Damsel",
"Renee Vivotte", 1.95};
c99 初始化
struct book surprise = {.value = 10.99};
struct book gift = {.value = 25.99,
.author = "James Broadfool",
.title = "Rue for the Toad"};
声明了结构体变量,怎么访问它的成员,使用点号, 比如surpise.value; 指针与结构体,struct book * plibrary; plibaray = &libray. 如果使用指针获取成员 ,一种是解引用(*library).value,一种是使用->, plibaray ->value. typedef 给一个类型定一个别名。
结构体类型和基本类型(int , double)使用方式一样,结构体可以赋值给另外一个结构体变量。struct book anotthr = library; 可以作为参数传递给函数,也可以作为函数的返回值。可以取结构体的地址,函数传参的时候,有两种方式,一种是把整个结构体,复制一份,传递过去,一个是把结构体指针传递过去,结构体也能作为函数的返回值。 结构体字面量 (struct book) {"The Idiot", "Fyodor Dostoyevsky", 6.99} , &(struct book) {"The Idiot", "Fyodor Dostoyevsky", 6.99} 则是取其地址。
内存对齐:是由于硬件方面的原因,cpu一次从内存中读取一定长度的字节,64bit操作系统,就是一次从内存中读取64bit。如果,内存放置诶只不对,一次读取不完,cpu要读取两次。通常来说,硬件更喜欢,你把元素放到 元素大小的倍数的位置上。比如一个int,4个字节,它放置到的内存位置最好是4的倍数。比如一个double 8个字节,最好把double类型的元素放置8的倍数的内存地址上。C!! 有一个alignof(), 就是告诉你类型的对齐的限制,它接受一个类型作为参数,返回地址对齐的倍数,所以对于一个struct来说,它实际占的内存大小,可能从比它本身的成员相加要大。当一个结构体数组时更是如此,数组的第一个结构体肯定是align的,那第二个怎么排列? 有可能要在第一个结构体和第二个结构体之间插入空间,也可能是第一个结构体最后一个元素后面插入空间。
union 联合类型
union hold {
int digit;
double bigfl;
char letter;
};
它所有的成员公用一块内存,它或是存一个int, 或是存一个double,或是存一个char,在同一块内存地址存储不同数据类型,同一时刻,union只存储一个值。当创建union类型的变量时,编译器会分配足够的空间,以便它能存储union类型中占用最大字节的类型。
union hold valA;
valA.letter = 'R';
union hold valB = valA; // initialize one union to another
union hold valC = {88}; // initialize digit member of union
union hold valD = {.bigfl = 118.2}; // designated initializer
枚举类型,主要是变量的取值,就只能取这么多,符号常量,主要是限定作用。
enum Jar_Type { CUP, PINT, QUART };
enum Jar_Type milk_jug; // 声明变量
实际上变量作为整数进行存储,符号常量也是作为数字进行存储,CUP是0,PINT 是1,在某些情况下,可能需要特定的数字来表示常量符号
enum Jar_Type { CUP=8, PINT=16, QUART=32};
动态分配内存(stdlib.h)
malloc()函数,在内存中分配参数指定的空间,然后返回这块内存的首字节地址,因此把它赋给一个指针变量,就可以通过指针访问这块内存。malloc()返回的是void类型(通用类型)的指针,因为它不知道要存储什么类型的数据,所以它不能返回指向普通类型指针,比如,int 或char, 而是返回 void * 类型的值。把void类型的指针赋值给任意类型的指针完全不用考虑类型匹配问题,但通常会强制类型转换一下。如果malloc()分配内存失败,则返回空指针。
double *ptd;
ptd = (double *)malloc(30 * sizeof(double));
if(ptd == NULL) {//分配失败}
// ptd[0], ptd[1],可以用数组的方式,使用内存
free(),接受malloc()返回的地址,释放malloc分配内存。手动分配的内存,需要手动释放, C没有垃圾回收机制。calloc() 也是手动分配内存,calloc(100, sizeof(int)), 只不过它会初始化为0,其他的都和malloc一样。
relloc: 增加或减少以前分配的空间,所以它的第一个参数是以前用molloc等分配的空间的地址(指针),第二个参数是大小,newp = realloc(p, ..), 如果 newp不是null,则p指针就不能再用了,以前使用p的地方都要换成newp。relloc的工作原理:调用malloc 分配内存,然后旧的内容复制到新内存中,如果分配的新内存小,新内存满了就不复制了。如果分配的新内存大,复制完旧的内容后,还有剩余,剩余的部分不会初始化。分配成功,就会调用free把旧内存释放掉,但如果分配失败,会返回null,但旧的的内存仍然存在。以下是错误的用法
int main(void)
{
int size = 10;
int *p = (int *) malloc(size * sizeof(int)); for(int i = 0; i< size; i++) {
p[i] = i;
} size += 10; // 有错误
if((p = realloc(p, size)) == NULL) {
return NULL;
} printf(" %d \n", p[5]);
return 0;
}
如果relloc 失败,p就是null,但是旧的p指向的内存并没有释放,导致内存泄漏。所以要声明两个变量,一个是保存malloc返回的指针,一个是保存realloc返回的指针, 把有错误的代码改成
// ...
void *p2;
if((p2 = realloc(p, size)) == NULL) {
free(p)
return NULL;
}
p = p2 printf("%d \n", p[5]) // ...
当有了动态分配内存,结构体有了灵活数组成员(柔性数组),声明结构体的时候,至少有两个成员,最后一个成员是数组,其它成员是什么都行,数组的并不需要数组长度。数组有个特性,它不会立即存在,只有经过适当的操作之后,这个数组才能正常使用
struct flex {
int count;
double average;
double scores[]; // 灵活数组成员
};
如果声明一个struct flex变量,你不能使用 scores, 因为并没有为它分配内存空间。事实上,也不应该这么用。我们应该声明一个struct flex指针变量(结构体指针),然后使用malloc分配足够的空间给普通的结构体成员和灵活数组,来存储 struct flex的正常类型的内容和柔性数组的内容(use malloc() to allocate enought space for the ordinary contents of struct flex plus any extra space you want for the flexiable array member),比如 想让scores 代表5个double值的数组,然后使用malloc()来分配空间
struct flex *pf;
// 分配空间给结构体和数组
pf = malloc(sizeof(struct flex) + 5 * sizeof(double));
分配了count 和average,然后5个数组,然后数组和结构体成员都可以使用了
pf->average = 12.5;
pf->scores[2] = 10.2;
当然,使用柔性数组的struct有限制,比如不能使用赋值的方式,进行copy,因为这会copy struct 普通类型,要使用memcpy(). 当然,函数传参的时候,不要使用struct 类型,要使用指针,原因和赋值一样。最后是柔性数组的struct不要做为数组元素和其它struct 类的成员
多文件程序
编写应用程序不可能只有一个文件,多个文件就涉及到共享,隐藏等问题,C语言没有模块的概念,相对应的是变量有一个链接属性,内部链接的标识符只能在本文件中使用。如果另外一个文件中有同名的变量,它们被认为是不同的变量。外部链接的定义标识符,可以在程序中的其它文件中使用,虽然标识符是在这个文件中定义的,但是它完全可以在项目中其他文件中使用。在文件作用域或全局作用域的变量和函数默认都是外部链接,在变量和函数前面加static,就变成了内部链接。只有文件作用域的定义变量和函数才有链接属性,块级作用域没有链接属性。

怎么在一个文件中使用另一个文件中的定义的标识符,使用变量和函数都要提前先声明的,extern来声明变量和函数。extern int i; 千万不要 extern int i = 0; 它相当于 int i = 0; extern void sum(int a, int b); 由于函数声明默认是extern 的,函数声明前可以不加extern。extern 就是告诉编译器去其他地方找标识符的定义,因此,extern 声明不占内存空间,也意味着在整个项目中,标识符只能有一个可见的定义。 函数声明只是声明了一个标识符,函数定义才是在内存中开辟空间,保存起来。变量的声明也是,它也只是声明了一个标识符号,只有赋值,才在内存中开辟空间,算是定义。但对于external的变量,只识别前31个字符。也最好不要使用以_下划线开头的变量名,以免和库文件有冲突。但这样使用有一个问题,就是如果10个文件中都用了一个函数,函数的声明就要在10个文件中都写一遍,容易出错。由于就有了头文件,把函数声明放到头文件中,然后在使用函数的文件中包含头文件。在同一个目录下,建立stack.h, stack.c, calc.c

include指令有两种形式,#include <文件名>和#include "文件名"。#include <文件名> 引用C自带的头文件,#include "文件名" 是引用自定义的文件,当然文件名中可以包含路径,最好使用相对路径,#inlucde "utils.h" 或#include "../header/untils.h". 除了调用函数的文件中引用头文件,还要在定义函数的文件包含头文件,确保原型和定义保持一致。头文件中也可以包含其它头文件
#include <stdbool.h>
void make_empty(void);
bool is_empty(void);
void push(int i);
int pop(void);
这就带来了一个问题,如果一个头文件被包含多次,并多次编译,编译器可能会报错。

需要对头文件进行保护,把头文件的内容放到#ifndef 和#endif 之间
#ifndef STACK_H
#define STACK_H #include <stdbool.h>
void make_empty(void);
bool is_empty(void);
void push(int i);
int pop(void); #endif
当这个头文件被第一次引入的时候,宏STACK_H是没有被定义的,所以预编译器会允许#ifndef 和#endif 之间 的内容存在。但是当这个文件以后再被引用时,预处理器会把#ifndef 和#endif 之间的内容删除。宏的名字最好和头文件的名字一致。
那怎么编译和运行多程序文件?如果有三个文件 justify.c包含main, line.c读取用户输入的内容,word.c 用来处理文件,line.h和word.h分别用来定义头文件。现在大部分的编译器,只用一步,就可以构建整个程序 gcc -o justify justify.c line.c word.c. 但这会有几个问题,一个是文件名大多,一个是重复编译, 为了更简单地构建大型程序,使用makefile, 一个包含构建程序必要信息的文件。makefile 不仅列出了项目中使用到的源文件,还描述它们之间的依赖关系,比如line.c 包含line.h,我们就可以说line.c依赖line.h,因为line.h发生变化,需要重新编译line.c. makefile文件的文件名就是makefile或Makefile, 在项目根目录新建makefile文件
justify: justify.o word.o line.o
gcc -o justify justify.o word.o line.o #tab键开始 justify.o: justify.c word.h line.h
gcc -c justify.c word.o: word.c word.h
gcc -c word.c line.o: line.c line.h
gcc -c line.c
有四组,每一个组称为一个规则。每一规则的第一行给了一个目标文件,后面是它的依赖。第二行是执行的命令,由于依赖文件发生变化,目标文件需要重新构建,所要执行的命令。比如第一个规则:justify是目标文件,它依赖justify.o, word.o, line.o; 如果三个文件中的任何一个发生变化,justify需要重新构建。第二行就是重新构建要执行的命令。注意命行所在行要以tab 开始,不是空格。
创建了makefile文件,使用make命令来执行构建。make 命令执行的时候,它自动在当前目录查找该文件。make target 来执行命令,target 就是在makefile文件中定义的target,比如make justify. 如果不指定target, make 命令将会构建第一行规则的target。
C语言的抽象数据类型,比如栈的实现,头文件如下
#define STACK_SIZE 100 typedef struct stack
{
int contents[STACK_SIZE];
int top;
} Stack; void push(Stack *s, int i);
void pop(Stack *s);
但Stack 并没有很好的封装性,在main 函数中 声明Stack s1, s1.top 是可行的,实际上,对于栈的操作来说,我们只想使用函数来操作栈。当然C语言本身也没有提供很好的封装,只有一个办法,不完整类型。比如struct stack;, 只告诉编译器,stack是一个结构体tag,但并没有描述结构体成员,因此结构体的定义需要在别的地方完整(stack.c 实现上), 也是因为类型是不完整的,所以不能声明变量,但可以声明指针,typedef struct stack * Stack; 但仍然不能使用 -> 获取它的成员,由不完整,就要多一个create 创建栈的方法,
#ifndef STACK_H
#define STACK_H #include <stdbool.h> typedef struct stack_type *Stack; Stack create(void);
void destroy(Stack s);
void push(Stack s, int i);
int pop(Stack s); #endif
stack,c 栈的一个简单实现
#include <stdlib.h>
#include "stack.h" #define STACK_SIZE 100 struct stack_type // 头文件中不完整类型的定义
{
int contents[STACK_SIZE];
int top;
}; Stack create(void) {
Stack s = malloc(sizeof(struct stack_type));
if (s == NULL) exit(0);
s->top = 0;
} void destroy(Stack s) {
free(s);
} void push(Stack s, int i) {
s->contents[s->top++] = i;
} int pop(Stack s) {
return s->contents[--s->top];
}
在main 函数中调用的时候
#include <stdio.h>
#include "stack.h" int main(void) {
Stack s1;
int n; s1 = create();
push(s1, 1);
n = pop(s1);
destroy(s1);
}
C语言声明
读懂C语言的声明,看的是优先级。先找到声明的变量,然后按以下优先级方式来拚读。1,如果变量在小括号内,小括号是一个整体。2, 再看变量后面的操作符,如果是小括号表示是一个函数,如果是中括号表示是一个数组,3,再看变量前面的操作符,* 表示是一个指针变量,指向什么。如果在过程中遇到了const 和 volatile限定符,它们在类型(int 等)旁边,它应用到类型上,如果不在类型前面,就就用到它左边的 *

比如:char * const * (*next)(); next 是声明的变量,它在小括里面,和* 在一起,表是它是一个指针变量,指向什么,再看next变量后面,也是一个小括号,表示函数,这个函数没有任何参数,函数要返回什么,就是next变量前面的 char * const *。也就是说,next 变量是一个指针变量,指向一个没有参数,但是返回值是char * const *的函数。char * const * 的意思是, *表示指针,指向 char * const(不变的或只读的指针 指向char) . 声明的时候,要注意,函数不能返回函数,也不能返回数组,数组中也不能函数,这些情况下,都需要指针。
文件操作:
C把每一个文件都看作是有序字节流,每一个文件都以文件结束符(end-of-file marker)作为结尾,如下图所示:

所以I/O仅仅是字节的流动,要么文件到程序,要么从程序到文件。文件到程序就是输入,程序需考虑正确地解释数据的字节。程序到文件就是输出,程序需要考虑如何创建正确的输出字节数据。无论读写,都要先打开文件。fopen()打开一个文件,打开成功,返回一个FILE 结构体地址,FILE结构体就包含程序要处理的文件的信息,所以把地址赋值给一个File类型的指针变量,操作指针变量,就是操作文件。如果打开失败,就返回空指针NUll。fopen() 第一个参数是字符串,要打开的文件名(文件路径),第二个参数是以什么方式打开,有 "r","rb","w","wb","a"
"r":以只读模式打开文件,如果文件不存在,返回NULL。"w":以写模式打开,如果文件存在,就清空文件内容,如果不存在,就创建文件。"a", 也是以写模式打开文件,不过,文件存在的时候,它会在文件末尾追加内容,而不是清空文件内容,如果文件不存在,则创建文件
"r+":如果文件存在,打开文件后,光标放到文件的起始位置,如果文件不存在,返回NULL,因此,它既不会删除文件内容,也不会创建文件。 当文件以r+打开时,文件可读,可写,但有特殊的规则,除非读到文件的末尾,否则不能从读切换到写,如果非要切换,必须调用文件位置的函数。调用写函数后,也不能从写切换到读,除非调用位置函数或fflush()函数。文件位置函烽:fseek, fsetpos, ftell, rewind. 光标在文件的什么地方。rewind() 把文件位置设置到文件起始位置
"w+", 打开文件,文件可读写,但如果文件存在,它会把文件内容清空,当文件不存在,它会创建文件,无论如何,先做读取操作是没有意义的,可以先做写操作,写完之后,再调用文件位置函数,对刚才写的内容进行读取。
"a+": 打开文件,文件可读写。如果文件存在,光标放到文件位置,按理说,此时读是没有办法读取到内容的,在Mac是确实是这样,但是Ubuntun下面,它是可以先进行读取操作的,把整个文件都读完。可以直接进行写操作,进行写操作的时候,a+只会在文件的末尾i写入内容,称动光标,对写入操作无效。写入操作完成后,再调用位置函数,设置光标,进行读取操作。
当用w+或a+来打开文件时,它可以读写。如果先写再读,写完之后,光标已到了文件末尾,这时候,再去读,读不到什么内容,所以在读之前要重置光标,rewind(fp), 将光标放到文件的起始位置。
rb, wb, a+b, 则是以二进制打开文件。C11 加了x模式,wx wbx, 如果打开存在的文件,会打开失败。
如果是以文本模式打开的文件,要用文件I/O,比如 fgets(), fgetc(), fscanf()。 如果是以二进制文件方式,打开,要要使用fread 和fwrite
打开文件后,
fgetc(File 指针)可以从文件中读取一个字符, 返回int类型(代表字符),如果读到文件末尾,就返回EOF,如果读取过程中发生错误,也会返回EOF。feof()和ferror() 函数主是用于区分这两种情况,feof()读取到文件结尾,返回非0,否则返回0。如果读和写出现错误,ferror返回非0,否则返回0。
读取字符放到哪里去呢,那就用到fputc, 它的第一个参数就是字符,第二个参数就是要放置的位置。要放置的位置,就是以写模式打开的文件,如果fputc成功,返回当前写入的字符,如要失败,返回EOF。
fclose是关闭文件(必要时,刷新缓冲区),它的参数就是打开的文件的指针。对于比较正式的程序,应该检查是否成功关闭文件,如果关闭成功,fclose返回0,否则返加EOF。
fgets(),第一个参数,就是读取字符串到哪里,第二个参数就是限制读取多少个字符,如果参数的值为n,它就会只读取n-1个字符,当然,如果不到n-1,读取到了换行符,它也会停止。也就是说,fgets() 读取停止的条件是,要么读取到最大长度,要么读取到了换行符。注意读取到换行符时,它不会舍弃,读取完成后,再在读取到的字符串后面 加'\0', 存到字符串中。加'\0',表示字符串的结束,这也是第二个参数是n,fgets()读取n-1个字符的原因。第三个参数就是从哪里去读,如果从终端中去读,就是stdin。 fgets()返回一个字符指针,值和第一个参数地址一样。如果读取失败,或读取到end-of-file,就会返回空指针NULL。fputs(),它的第一个参数是,要写的内容,第二个是写到哪里,屏幕就是stdout. 它不会换行。
①fgets:从文件中读取一行数据存入缓冲区(fgets遇到回车才会结束,不对空格和回车做任何转换就录入到缓冲区,结束后再往缓冲区写多一个\0,所以它是读一行数据) ②fscanf:从文件中读取一段数据存入缓冲区(fscanf遇到空格或回车就结束,它会把空格或回车转换为\0,所以它是读一小段数据)。假设复制 一个文件,
我爱你小白 开玩笑
哈哈
开玩笑
fgets会原样输出到目标文件

fscanf() 则会返回

fscanf() is a field oriented function and is inappropriate for use in a robust, general-purpose text file reader.
int main()
{
FILE *fp = fopen("test.txt", "r"); if (fp == NULL)
{
perror("打开文件时发生错误");
return (-1);
} const int BUFF_SIZE = 51;
char buf[BUFF_SIZE];
int line = 0;
while (1)
{
if ((fgets(buf, BUFF_SIZE -1, fp)) == NULL) {
break;
}
if(buf[strlen(buf) -1] == '\n') {
line++;
}
}
if (feof(fp))
printf("\n End of file reached. line = %d \n", line);
else
printf("\n Something went wrong."); fclose(fp);
return (0);
}
feof()函数还能判断一个二进制文件有没有到达文件末尾,比如,读一个mp3文件,fgetc, 和fputc 也能读取二进制文件
int main()
{
FILE *source;
FILE *target; // 复制source 到target
source = fopen("a.mp4", "rb");
target = fopen("b.mp4", "wb"); if (source == NULL || target == NULL)
{
perror("打开文件时发生错误");
return (-1);
} int c;
while (( c = fgetc(source)) != EOF)
{
fputc(c, target);
}
if (feof(source))
printf("\n End of file reached.");
else
printf("\n Something went wrong."); fclose(source);
fclose(target);
return (0);
}
fread() 函数用来从指定文件中读取块数据。所谓块数据,也就是若干个字节的数据。fread() 的原型为:
size_t fread ( void *ptr, size_t size, size_t count, FILE *fp );
fwrite() 函数用来向文件中写入块数据,它的原型为:
size_t fwrite ( void * ptr, size_t size, size_t count, FILE *fp );
- ptr 为内存区块的指针,它可以是数组、变量、结构体等。fread() 中的 ptr 用来存放读取到的数据,fwrite() 中的 ptr 用来存放要写入的数据。
- size:表示每个数据块的字节数。
- count:表示要读写的数据块的块数。
- fp:表示文件指针。
- 理论上,每次读写 size*count 个字节的数据。
返回值:返回成功读写的块数,也即 count。如果返回值小于 count:
- 对于 fwrite() 来说,肯定发生了写入错误,可以用 ferror() 函数检测。
- 对于 fread() 来说,可能读到了文件末尾,可能发生了错误,可以用 ferror() 或 feof() 检测。
fwrite(a, sizeof(a[0]), sizeof(a) /sizeof(a[0]), fp )
int main()
{
FILE *h = fopen("file.txt", "a");
char *line =
"bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb\n";
for (int i = 0; i < 1000; i++)
{
if (fwrite(line, 1, strlen(line), h) != strlen(line))
{
perror("Could not append line to file");
// Exception Handling
exit(1);
}
}
if (fclose(h) != 0)
{
perror("Could not close file");
exit(1);
}
return (0);
}
fread 也可以用来读文件
int main()
{
// File pointer
FILE* filePointer;
// Buffer to store the read data
char buffer[100]; // "g4g.txt" file is opened in read mode
filePointer = fopen("g4g.txt", "r"); // Data is read from the file into the buffer
// sizeof(buffer) specifies the size of each element to
// be read 1 is the number of elements to read
// filePointer is the file to read from
while (!feof(filePointer)) { fread(buffer, sizeof(buffer), 1, filePointer);
// Print the read data
printf("%s", buffer);
} fclose(filePointer);
return 0;
}
The fseek() function enables you to treat a file like an array and move directly to any partic-ular byte in a file opened by fopen(). fseek()第一个参数的fopen()打开的文件(使用rb打开), 第二个参数是从start point开始的偏移量,它是long类型,第三个参数就是标识start point。三个选项SEEK_SET(文件开始位置), SEEK_CUR(当前位置,也就是光标所在位置),SEEK_END(文件结束位置)

fseek() 近回0表示正常,fseek() 返回-1 表示不常. ftell()则表返回文件的位置,从文件开头到光标所在位置的字节数,是个long类型。
文件的读写都是缓冲区, 每个打开的文件分配一个I/O缓冲区以加速读写操作,通过文件的FILE 结构体可以找到这个缓冲
区,用户调用读写函数大多数时候都在I/O缓冲区中读写,只有少数时候需要把读写请求传给内
核。以fgetc / fputc 为例,当用户程序第一次调用fgetc 读一个字节时,fgetc 函数可能通过系统调用
进入内核读1K字节到I/O缓冲区中,然后返回I/O缓冲区中的第一个字节给用户,把读写位置指
向I/O缓冲区中的第二个字符,以后用户再调fgetc ,就直接从I/O缓冲区中读取,而不需要进内核
了,当用户把这1K字节都读完之后,再次调用fgetc 时,fgetc 函数会再次进入内核读1K字节
到I/O缓冲区中。I/O缓冲区也在用户空间,直接
从用户空间读取数据比进内核读数据要快得多。另一方面,用户程序调用fputc 通常只是写到I/O缓
冲区中,这样fputc 函数可以很快地返回,如果I/O缓冲区写满了,fputc 就通过系统调用把I/O缓冲
区中的数据传给内核,内核最终把数据写回磁盘。有时候用户程序希望把I/O缓冲区中的数据立刻
传给内核,让内核写回设备,这称为Flush操作,对应的库函数是fflush,fclose函数在关闭文件
之前也会做Flush操作

泛型函数操作数组:Generic functions are functions that will work on any type。 In C, generic types mean void pointers. If a function can work
on more than one type, it will take one or more void pointers as arguments.
you are always allowed to
cast data to character pointers to get the address of their first byte, so we can cast our
void pointers to char pointers and manipulate the underlying data that way. Then, if
you want to move to an address at the right distance, you must multiply the number of
elements you wish to move with the size of the objects. 当你在操作void 指针的时候,你并不知道 ,指针指向具体数据类型,指针操作无法进行,当你在调用一个void指针的函数时候,可以把要操作的数据类型的size传给它。 void reverse(void *array, int n, int size)
{
if (n <= 0) return; // avoid right underflow
char *left = array;
char *right = left + size * (n - 1);
char tmp[size];
while (left < right) {
memcpy(&tmp, left, size);
memcpy(left, right, size);
memcpy(right, &tmp, size);
left += size;
right -= size;
}
}
不能解引用一个void类型。当交换的时候,使用memory copy
编译和链接细节
对于C 语言来说,每一个C源文件都会经过编译器的单独处理,生成自己的obj文件,也就是说,有10个 .c文件,就会编译成10个.obj文件。头文件不需要单独编译,当包含头文件的文件编译时,它会自动编译头文件。然后,这些 .obj文件,再加上链接库,经过链接器链接,捆绑在一起,最终生成一个可以执行的文件或程序。编译又分为三个阶段:预处理,编译,汇编。预处理命令 gcc -E test.c -o test.i .i 文件就是预处理后生成的文件。它主要做到事情就是
#include引入的头文件中的所有内容都插入到了 test.i 文件中了。 只是把头文件中所有内容都拷贝到了.i 文件。
注释删除(使用空格替换注释)。
#define 替换,
#define 定义标识符, #define MAX 30 结尾处一定不要加分号。 预编译阶段或预处理阶段,就是纯文本替换。
编译命令 gcc -S test.i 生成test.s文件(汇编代码) 把C代码编译成汇编代码,它就是语法分析,词法分析,语义分析 符号汇总(main, printf 等函数都会保留到汇编代码中)。 汇编命令 gcc -c test.s 生成test.o, 生成 .o二进制文件,主要是形成符号表。因为每一个源文件都会生成它自己的汇编文件,每一个源文件中都有自己的函数,也就是说每一个汇编文件中都有自己定义的函数,也就是有自己的符号。这些函数或者符号,可能被另一个C文件调用,也就是说,在另一个C文件(汇编文件)中,它也有一个相同的函数名符号。比如test.c 中调用 add.c 中的add() 函数,test.c生成test.s, 它里面会用两个符号,main, add。 add.c会生成 add.s, 它里面会有 add符号。 每一个函数都会有地址,汇编阶段,就是把符号和它对应的地址放到一张表里面。add.s 生成add.0 就会生成一张符合表。

这里要注意的是add 对应的地址并不是真实的地址,因为,它是调用的外部函数,在test中,只是声明了函数。
链接: add.o 和test.o 进行链接,要合并段表。.o文件有自己的格式,文件中的内容都分段存在的(ELF 格式)。进行链接的时候,就是把每一个文件中每一段进行合并。最终生成的可执行文件也是ELF格式。还有就是符号表的合并和重定义,因为每一个文件都有自己的符号表,最主要的是联系在一起。因为有些表中的地址是无效的,要用真实的地址,进行替换,函数的调用尤其如此,最终生一张都是真实地址的表。

add是真实的地址,main 函数在调用add的时候,就会找的到。
C语言的简单学习的更多相关文章
- 表达式语言EL简单学习
Jsp2.0最重要的特性就是表达式语言EL.jsp用户可以用它来访问应用程序数据. EL表达式以${开头并以}结束. ${expresion} ${x+y} 它也常用来连接两个表达式,取值将从 ...
- 【C语言C++编程学习笔记】基础语法,第一个简单的实例编程入门教程!
C语言/C++编程学习:一个简单的实例 让我们来看一个简单的C语言程序.从下面的程序可以看出编写C语言程序的一些基本特征. 如果你能知道该程序将会在显示器上显示一些内容,那说明你还是知道一些的! ...
- R语言书籍的学习路线图
现在对R感兴趣的人越来越多,很多人都想快速的掌握R语言,然而,由于目前大部分高校都没有开设R语言课程,这就导致很多人不知道如何着手学习R语言. 对于初学R语言的人,最常见的方式是:遇到不会的地方,就跑 ...
- R语言︱H2o深度学习的一些R语言实践——H2o包
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- R语言H2o包的几个应用案例 笔者寄语:受启发 ...
- 碎片︱R语言与深度学习
笔者:受alphago影响,想看看深度学习,但是其在R语言中的应用包可谓少之又少,更多的是在matlab和python中或者是调用.整理一下目前我看到的R语言的材料: ---------------- ...
- go语言,golang学习笔记4 用beego跑一个web应用
go语言,golang学习笔记4 用beego跑一个web应用 首页 - beego: 简约 & 强大并存的 Go 应用框架https://beego.me/ 更新的命令是加个 -u 参数,g ...
- go语言,golang学习笔记2 web框架选择
go语言,golang学习笔记2 web框架选择 用什么go web框架比较好呢?能不能推荐个中文资料多的web框架呢? beego框架用的人最多,中文资料最多 首页 - beego: 简约 & ...
- C语言/C++编程学习:不做C/C++工作也要学C/C++的原因!
C语言是面向过程的,而C++是面向对象的 C和C++的区别: C是一个结构化语言,它的重点在于算法和数据结构.C程序的设计首要考虑的是如何通过一个过程,对输入(或环境条件)进行运算处理得到输出(或实现 ...
- C语言C++编程学习:排序原理分析
C语言是面向过程的,而C++是面向对象的 C和C++的区别: C是一个结构化语言,它的重点在于算法和数据结构.C程序的设计首要考虑的是如何通过一个过程,对输入(或环境条件)进行运算处理得到输出(或实现 ...
- C语言/C++编程学习:C语言环境设置
C语言是面向过程的,而C++是面向对象的 C和C++的区别: C是一个结构化语言,它的重点在于算法和数据结构.C程序的设计首要考虑的是如何通过一个过程,对输入(或环境条件)进行运算处理得到输出(或实现 ...
随机推荐
- GDB 中内存打印命令
GDB 中使用 "x" 命令来打印内存的值,格式为 "x/nfu addr".含义为以 f 格式打印从 addr 开始的 n 个长度单元为 u 的内存值.参数具 ...
- fastposter v2.9.1 程序员必备海报生成器
fastposter v2.9.1 程序员必备海报生成器 fastposter海报生成器是一款快速开发海报的工具.只需上传一张背景图,在对应的位置放上组件(文字.图片.二维.头像)即可生成海报. 点击 ...
- ASP.NET Core的全局拦截器(在页面回发时,如果判断当前请求不合法,不执行OnPost处理器)
ASP.NET Core RazorPages中,我们可以在页面模型基类中重载OnPageHandlerExecuting方法. 下面的例子中,BaseModel继承自 PageModel,是所有页面 ...
- 热更学习笔记10~11----lua调用C#中的List和Dictionary、拓展类中的方法
[10]Lua脚本调用C#中的List和Dictionary 调用还是在上文中使用的C#脚本中Student类: lua脚本: print("------------访问使用C#脚本中的Li ...
- 为什么不推荐在Spring Boot中使用@Value加载配置
@Value注解相信很多Spring Boot的开发者都已经有接触了,通过使用该注解,我们可以快速的把配置信息加载到Spring的Bean中. 比如下面这样,就可以轻松的把配置文件中key为com.d ...
- 京东面试:SpringBoot同时可以处理多少请求?
Spring Boot 作为 Java 开发中必备的框架,它为开发者提供了高效且易用的开发工具,所以和它相关的面试题自然也很重要,咱们今天就来看这道经典的面试题:SpringBoot同时可以处理多少个 ...
- 记录一次WhatTheFuck经历
起因 很早之前就一直在维护一个git仓库,平时调研什么组件就会在里面新建一个springboot的工程用来编写示例代码. 最一开始使用的是SpringInitializr,后来网站更新之后,只能生成J ...
- 揭秘华为如此多成功项目的产品关键——Charter模板
很多推行IPD(集成产品开发)体系的公司在正式研发产品前,需要开发Charter,以确保产品研发方向的正确.Charter,即项目任务书或商业计划书.Charter的呈现标志着产品规划阶段的完成,能为 ...
- Java中Calendar类与SimpleDateFormat类的介绍
目录 Calendar类(关于日期的一些方法) get(Calendar.XXX); get(Calendar.Year) get(Calendar.MONTH) get(Calendar.DAY_O ...
- 关于 cnblogs 中的神秘操作
关于 cnblogs 中的神秘操作 批量替换 利用 metaweblog 批量操作 代码参考:jeefies - jcnapi 不是很完整 其中 BLOGS_BLOGID 指的是 https://ww ...