HBase架构和技术原理介绍
一、HBase数据模型(☆)
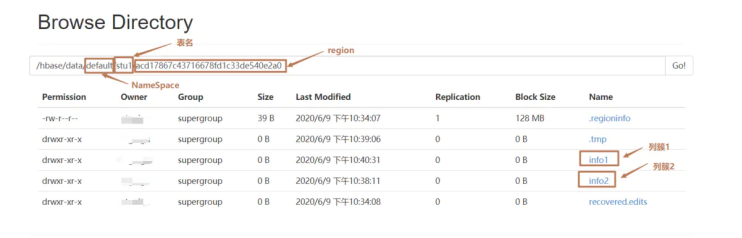
1.NameSpace
命名空间,类似于关系型数据库的 DataBase 概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,default 表是用户默认使用的命名空间。
2.Region
类似于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往 HBase 写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase 能够轻松应对字段变更的场景。
3.Row
HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
4.Column
HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
5.TimeStamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入 HBase 的时间。
6.Cell
由{rowkey, column Family:column Qualifier, timeStamp} 唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存贮。
二、HBase架构(☆)

从上面的架构图可以看出HBase是建立在hadoop之上的,HBase底层依赖于HDFS。
HBase有3个重要的组件:Zookeeper、HMaster、HRegionServer。
Zookeeper为整个HBase集群提供协助的服务,HMaster主要用于监控和操作集群的所有RegionServer。RegionServer主要用于服务和管理分区(Regions)。
1.RegionServer
Region Server 为 Region 的管理者,其实现类为HRegionServer,主要作用如下:
对于数据的操作:get, put, delete;
对于 Region 的操作:splitRegion、compactRegion。
2.Master
Master 是所有 Region Server 的管理者,其实现类为 HMaster,主要作用如下:
(1)对于表的操作:create, delete, alter;
(2)对于 RegionServer的操作:分配 regions到每个RegionServer,监控每个 RegionServer的状态,负载均衡和故障转移。
3.Zookeeper
HBase 通过 Zookeeper 来做 Master 的高可用、RegionServer 的监控、元数据的入口以及集群配置的维护等工作。
4.HDFS
HDFS 为 HBase 提供最终的底层数据存储服务,同时为 HBase 提供高可用的支持。
5.StoreFile
保存实际数据的物理文件,StoreFile 以 HFile 的形式存储在 HDFS 上。每个 Store 会有一个或多个 StoreFile(HFile),数据在每个 StoreFile 中都是有序的。
6.MemStore
写缓存,由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的 HFile。
7.WAL
由于数据要经 MemStore 排序后才能刷写到 HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile 的文件中,然后再写入 MemStore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
三、Region/Store/StoreFile/Hfile之间的关系
1.Region
table在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。
Region按大小分隔,表中每一行只能属于一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
2.Store
每一个region有一个或多个store组成,至少是一个store,hbase会把一起访问的数据放在一个store里面,即为每个ColumnFamily建一个store(即有几个ColumnFamily,也就有几个Store)。一个Store由一个memStore和0或多个StoreFile组成。
HBase以store的大小来判断是否需要切分region。
store的数据存储在两个地方MemStore和StoreFile
3.MemStore
写缓存,memStore 是放在内存里的。由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好序后,等到达刷写时机才会刷写到 HFile(当memStore的大小达到一个阀值【默认64MB】时,memStore会被flush到文件),每次刷写都会形成一个新的 HFile。
4.StoreFile
memStore内存中的数据写到文件后就是StoreFile(即memstore的每次flush操作都会生成一个新的StoreFile),StoreFile底层是以HFile的格式保存。
5.HFile
HFile是HBase中KeyValue数据的存储格式,是hadoop的二进制格式文件。一个StoreFile对应着一个HFile。而HFile是存储在HDFS之上的。
四、HBase读写流程(☆)
1.写流程

1)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 RegionServer 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3)与目标 Region Server 进行通讯;
4)将数据顺序写入(追加)到 WAL;
5)将数据写入对应的 MemStore,数据会在 MemStore 进行排序;
6)向客户端发送 ack;
7)等达到 MemStore 的刷写时机后,将数据刷写到 HFile。

2.MemStore 刷写时机

(1)当某个 memstroe 的大小达到了 hbase.hregion.memstore.flush.size(默认值 128M),其所在 region 的所有 memstore 都会刷写。当 memstore 的大小达到了hbase.hregion.memstore.flush.size(默认值128M) * hbase.hregion.memstore.block.multiplier(默认值 4)时,会阻止继续往该 memstore 写数据。
(2)当 region server 中 memstore 的总大小达到java_heapsize * hbase.regionserver.global.memstore.size(默认值 0.4)* hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95),region 会按照其所有 memstore 的大小顺序(由大到小)依次进行刷写。直到region server中所有 memstore 的总大小减小到上述值以下。当 region server 中 memstore 的总大小达到java_heapsize*hbase.regionserver.global.memstore.size(默认值 0.4)时,会阻止继续往所有的 memstore 写数据。
(3)到达自动刷写的时间,也会触发 memstore flush。自动刷新的时间间隔由该属性进行配置 hbase.regionserver.optionalcacheflushinterval(默认 1 小时)。
(4)当 WAL 文件的数量超过 hbase.regionserver.max.logs,region 会按照时间顺序依次进行刷写,直到 WAL 文件数量减小到 hbase.regionserver.max.log以下(该属性名已经废弃,现无需手动设置,最大值为32)。
3.读流程
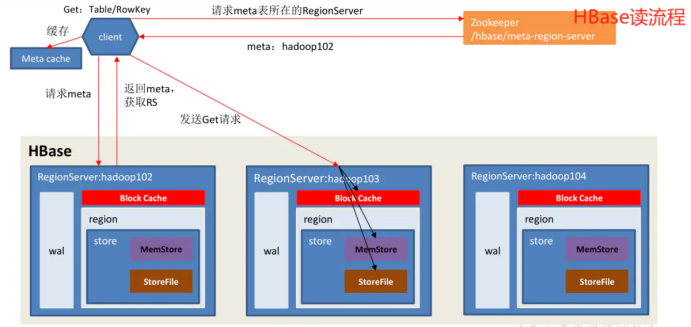
查找顺序:先到MemStore查,查不到去BlockCache,再查不到StoreFile。
1)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个 RegionServer 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3)与目标 Region Server 进行通讯;
4)分别在 Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
5) 将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓存到Block Cache。
6)将合并后的最终结果返回给客户端。
五、StoreFile Compaction相关
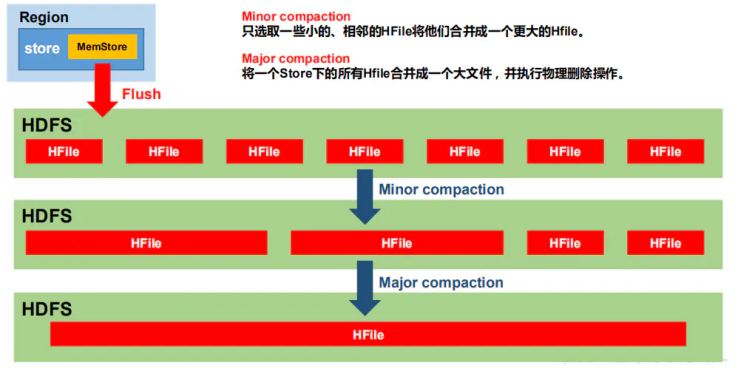
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的 HFile 中,因此查询时需要遍历所有的 HFile。为了减少 HFile 的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。
Compaction 分为两种,分别是 Minor Compaction 和 Major Compaction。
(1)Minor Compaction会将临近的若干个较小的 HFile 合并成一个较大的 HFile,但不会清理过期和删除的数据。
(2)Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并且会清理掉过期和删除的数据。
六、Region Split相关

默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入,Region 会自动进行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考虑,HMaster 有可能会将某个 Region 转移给其他的 Region Server。
Region Split 时机:
(1).当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize,该 Region 就会进行拆分(0.94 版本之前)。
(2).当 1 个 region 中 的 某 个 Store 下所有 StoreFile 的 总 大 小 超 过 Min(R^2*"hbase.hregion.memstore.flush.size",hbase.hregion.max.filesize"),该 Region 就会进行拆分,其中 R 为当前 Region Server 中属于该 Table 的个数(0.94 版本之后)。
七、HBase和Hive比较(☆)
1.Hive
(1) 数据仓库
Hive 的本质其实就相当于将 HDFS中已经存储的文件在 Mysql 中做了一个双射关系,以方便使用 HQL 去管理查询。
(2) 用于数据分析、清洗
Hive 适用于离线的数据分析和清洗,延迟较高。
(3) 基于 HDFS、MapReduce
Hive 存储的数据依旧在 DataNode上,编写的 HQL 语句终将是转换为 MapReduce代码执行。
2.HBase
(1) 数据库
是一种面向列族存储的非关系型数据库。
(2) 用于存储结构化和非结构化的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN 等操作。
(3) 基于 HDFS
数据持久化存储的体现形式是 HFile,存放于 DataNode 中,被 ResionServer 以 region 的形式进行管理。
(4) 延迟较低,接入在线业务使用
面对大量的企业数据,HBase 可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
八、HBase优化(☆)
1.高可用
在 HBase 中 HMaster 负责监控 HRegionServer 的生命周期,均衡 RegionServer 的负载,如果HMaster 挂掉了,那么整个 HBase 集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase 支持对 HMaster 的高可用配置。
2.预分区
每一个 region 维护着 StartRow 与 EndRow,如果加入的数据符合某个 Region 维护的RowKey 范围,则该数据交给这个 Region 维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase 性能。
3.RowKey 设计
一条数据的唯一标识就是 RowKey,那么这条数据存储于哪个分区,取决于RowKey 处于哪个一个预分区的区间内,设计 RowKey的主要目的 ,就是让数据均匀的分布于所有的region 中,在一定程度上防止数据倾斜。接下来我们就谈一谈RowKey 常用的设计方案。
(1)生成随机数、hash、散列值
(2)字符串反转
(3)字符串拼接
4.内存优化
HBase 操作过程中需要大量的内存开销,毕竟 Table 是可以缓存在内存中的,一般会分配整个可用内存的70%给 HBase 的 Java 堆。但是不建议分配非常大的堆内存,因为 GC 过程持续太久会导致 RegionServer 处于长期不可用状态,一般 16~48G 内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。
5.基础优化
(1)允许在 HDFS 的文件中追加内容
(2)优化 DataNode 允许的最大文件打开数
(3)优化延迟高的数据操作的等待时间
(4)优化数据的写入效率
(5)设置 RPC 监听数量
(6)优化 HStore 文件大小
(7)优化 HBase 客户端缓存
(8)指定 scan.next 扫描 HBase 所获取的行数
(9)flush、compact、split 机制
当 MemStore 达到阈值,将 Memstore 中的数据 Flush 进 Storefile;compact 机制则是把 flush出来的小文件合并成大的 Storefile 文件。split 则是当 Region 达到阈值,会把过大的 Region一分为二。
九、RowKey的三个原则(☆)
1.唯一原则
必须在设计上保证其唯一性。由于在HBase中数据存储是Key-Value形式,若HBase中同一表插入相同Rowkey,则原先的数据会被覆盖掉(如果表的version设置为1的话),所以务必保证Rowkey的唯一性。
2.排序原则
HBase的Rowkey是按照ASCII有序设计的,我们在设计Rowkey时要充分利用这点。比如视频网站上对影片《泰坦尼克号》的弹幕信息,这个弹幕是按照时间倒排序展示视频里,这个时候我们设计的Rowkey要和时间顺序相关。可以使用"Long.MAX_VALUE - 弹幕发表时间"的 long 值作为 Rowkey 的前缀。
3.散列原则
我们设计的Rowkey应均匀的分布在各个HBase节点上。拿常见的时间戳举例,假如Rowkey是按系统时间戳的方式递增,Rowkey的第一部分如果是时间戳信息的话将造成所有新数据都在一个RegionServer上堆积的热点现象,也就是通常说的Region热点问题, 热点发生在大量的client直接访问集中在个别RegionServer上(访问可能是读,写或者其他操作),导致单个RegionServer机器自身负载过高,引起性能下降甚至Region不可用,常见的是发生jvm full gc或者显示region too busy异常情况,当然这也会影响同一个RegionServer上的其他Region。
HBase架构和技术原理介绍的更多相关文章
- 液晶常用接口“LVDS、TTL、RSDS、TMDS”技术原理介绍
液晶常用接口“LVDS.TTL.RSDS.TMDS”技术原理介绍 1:Lvds Low-Voltage Differential Signaling 低压差分信号 1994年由美国国家半导体公司提出之 ...
- HBase存储及读写原理介绍
一.HBase介绍及其特点 HBase是一个开源的非关系型分布式数据库,它参考了谷歌的BigTable建模,实现的编程语言为Java.它是Apache软件基金会的Hadoop项目的一部分,运行于HDF ...
- HBase(三)HBase架构与工作原理
一.系统架构 注意:应该是每一个 RegionServer 就只有一个 HLog,而不是一个 Region 有一个 HLog. 从HBase的架构图上可以看出,HBase中的组件包括Client.Zo ...
- HBase 架构与工作原理2 - HBase 组件
本文系转载,如有侵权,请联系我:likui0913@gmail.com 一.HBase 组件概览 Master-Slave 模式: HBase 体系结构遵循传统的 master-slave 模式,由一 ...
- HBase 架构与工作原理3 - HBase 读写与删除原理
本文系转载,如有侵权,请联系我:likui0913@gmail.com 一.前言 在 HBase 中,Region 是有效性和分布的基本单位,这通常也是我们在维护时能直接操作的最小单位.比如当一个集群 ...
- HBase 架构与工作原理1 - HBase 的数据模型
本文系转载,如有侵权,请联系我:likui0913@gmail.com 一.应用场景 HBase 与 Google 的 BigTable 极为相似,可以说 HBase 就是根据 BigTable 设计 ...
- HBase 架构与工作原理5 - Region 的部分特性
本文系转载,如有侵权,请联系我:likui0913@gmail.com Region Region 是表格可用性和分布的基本元素,由列族(Column Family)构成的 Store 组成.对象的层 ...
- HBase 架构与工作原理4 - 压缩、分裂与故障恢复
本文系转载,如有侵权,请联系我:likui0913@gmail.com Compacation HBase 在读写的过程中,难免会产生无效的数据以及过小的文件,比如:MemStore 在未达到指定大小 ...
- 大数据相关技术原理资料整理(hdfs, spark, hbase, kafka, zookeeper, redis, hive, flink, k8s, OpenTSDB, InfluxDB, yarn)
hdfs: hdfs官方文档 深入理解HDFS的架构和原理 https://blog.csdn.net/kezhong_wxl/article/details/76573901 HDFS原理解析(总体 ...
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
随机推荐
- C#写一套最全的MySQL帮助类(包括增删改查)
介绍说明:这个帮助类包含了六个主要的方法:ExecuteNonQuery.ExecuteScalar.ExecuteQuery.ExecuteQuery(泛型).Insert.Update和Delet ...
- 多维评测指标解读2022MSU世界编码器大赛结果
是极致性能,更是最佳商用. 19项第一之上,是63%的极致带宽降低 近日,2022 MSU世界视频编码器大赛成绩正式揭晓.报告显示,阿里媒体处理服务MPS(Alibaba Media Processi ...
- WPF Button MouseDown事件
Button的MouseDown事件 WPF的Button控件,鼠标点击时,MouseDown事件没有触发. 经确认,Button的MouseDown被内部处理了.下面是基类ButtonBase的部分 ...
- 快速傅里叶变换FFT学习笔记
点值表示法 我们正常表示一个多项式的方式,形如 \(A(x)=a_0+a_1x+a_2x^2+...+a_nx^n\),这是正常人容易看懂的,但是,我们还有一种表示法. 我们知道,\(n+1\)个点可 ...
- Stream方法的介绍
文章目录 前言 Lambda表达式 格式 函数式接口 Stream的方法介绍 forEach filter collect count sum limit 和skip groupingBy reduc ...
- 【Azure 应用服务】Azure JS Function 异步方法中日志无法输出问题引发的(await\async)关键字问题
问题描述 开发 Azure JS Function(NodeJS),使用 mssql 组件操作数据库.当SQL语句执行完成后,在Callback函数中执行日志输出 context.log(" ...
- rnacos——用rust重新实现的nacos开源配置、注册中心服务
1. 简介 rnacos 是一个用rust实现的nacos服务. rnacos是一个轻量.快速.稳定的服务,包含注册中心.配置中心.web管理控制台功能. rnacos兼容nacos client s ...
- 2023-02-20:小A认为如果在数组中有一个数出现了至少k次, 且这个数是该数组的众数,即出现次数最多的数之一, 那么这个数组被该数所支配, 显然当k比较大的时候,有些数组不被任何数所支配。 现在
2023-02-20:小A认为如果在数组中有一个数出现了至少k次, 且这个数是该数组的众数,即出现次数最多的数之一, 那么这个数组被该数所支配, 显然当k比较大的时候,有些数组不被任何数所支配. 现在 ...
- 2020-10-21:go中channel的send流程是什么?
福哥答案2020-10-21: ***[评论](https://user.qzone.qq.com/3182319461/blog/1603234689)
- Redis数据结构二之SDS和双向链表
本文首发于公众号:Hunter后端 原文链接:Redis数据结构二之SDS和双向链表 这一篇笔记介绍一下 SDS(simple dynamic string)和双向链表. 以下是本篇笔记目录: SDS ...