用 nebula_dart_gdbc 在移动设备玩图数据库,泰酷辣!

nebula_dart_gdbc,是访问 NebulaGraph 的 Dart 语言客户端,在 dart_gdbc 的规范下进行开发。
dart_gdbc 是一套使用 Dart 语言定义的图数据库标准数据接口,整体思路参考了 JDBC 的规范。目前已经实现了对 NebulaGraph 的支持。
在先前写 GraphDesk 的过程中,曾使用过 nebula-java(Socket)+ Spring Boot(HTTP)的方式实现了 Flutter 应用对 NebulaGraph 的访问。这无异于一辆可以高速行驶的汽车(Socket),进出家门的时候非要用人推(HTTP)的方式,这一点很难让人接受。而使用 Dart Socket 访问图数据库无疑是 Flutter 应用一个不错的选择。不过,因为 Dart 相比其他编程语言来说,目前相对小众,需求量小,并且是个偏前端的语言,纵观现有的图数据库生态,它们都不支持 Dart。
于是,dart_gdbc 与 nebula_dart_gdbc 应运而生。
随着 Dart 客户端的打通,对于拥有图数据库的朋友来说,通过 Dart 在手机上,甚至嵌入式平台上进行 NebulaGraph 的图探索,已经成为可能。而对于 Flutter 开发者来说,可以试试创建自己的图数据库,使用 nebula_dart_gdbc 直连数据库来实现自己的应用,也是一种奇妙体验。虽然,数据库的常规操作还是经过服务端做数据转发合理一点,但不影响大家尝试这种新玩法。
如果一切顺利的话,Dart 这一环节补上之后,之前我做的 GraphDesk,将会有以下变化:
- 从程序启动来看,将挣脱 Java 环境的束缚,不再需要等待本地 Java 服务的启动过程,运行体验上会有一个质的变化;
- 从查询性能的角度上来看,也会更加流畅;
- 条件允许的情况下,未来将推出 App 版本。
意义层面的内容就说到这,接下来聊聊 nebula_dart_gdbc 的诞生历程,下文带有很强的技术色彩,非业内人士可以选择性跳过。
nebula_dart_gdbc 的设计实现
nebula_dart_gdbc 的大概实现思路同其他语言的客户端一致,按照了下面这个步骤:
- 通过 thrift 文件,生成 NebulaGraph 数据访问接口;
- 将生成的数据访问接口与 Thrift 结合,完成对 NebulaGraph 的访问;
- 封装数据库连接。
显然,真正的开发并没有这么简单。在实际的过程中,我遇到了很多问题,也做了很多尝试,最终才有了现在的 nebula_dart_gdbc。下面来记录下开发一个 Dart 客户端,有哪些操作步骤以及相关问题的解决方案。
生成 NebulaGraph 数据访问接口
第一步,先下载数据接口的 thrift 文件,这是 NebulaGraph 给出的链接:https://github.com/vesoft-inc/nebula/tree/master/src/interface,包含下面这些文件:
- common.thrift
- graph.thrift
- meta.thrift
- storage.thrift
注意:下载完之后,需要往文件添加对应的包名,如:namespace dart nebula.graph
第二步,下载完接口所需的 NebulaGraph thrift 文件之后,我们再来下载 Thrift,这是 Thrift 的官方下载地址:https://thrift.apache.org/download,这里使用的是最新版本 0.18.1(如果你阅读本文的时候,0.18.1 不是最新版本,下载最新版本即可)。
第三步,逐个文件生成 Dart 代码。使用下面的命令就行:
thrift --gen dart common.thrift
thrift --gen dart graph.thrift
thrift --gen dart meta.thrift
thrift --gen dart storage.thrift
这个过程中,我们会遇到一些问题,这里记录了它们的解决方法。
- 问题 1:文件会遇到“非语言中立性的标记编译”问题;
- 解决方案:按报错将文件中的语言标记删除即可。
- 问题 2:这里使用的 Dart 版本是 2.19.0,由 thrift-0.18.1 生成的 Dart 代码与现今的版本语法并不兼容,而且版本差异很大。报错如下图所示,当然这只是当中的一部分,实际报错的文件有 300 个左右。
- (这是一张散户欢呼,码农落泪的图)
- 解决方案:根据编辑器的报错,逐个文件改。可能是最笨的办法,花了好几个小时。更好的方式,应该是让 thrift 的 compiler 支持最新的 Dart 版本,但这个办法可能需要花费更多的时间,而且不一定能成功。(退堂鼓震天响,退散...)
第四步,将生成的 Dart 代码,放到项目中。
至此,完成“通过 thrift 文件,生成 NebulaGraph 数据访问接口”。
数据访问接口与 Thrift 结合
这里,先插播一条广告(请耐心读下去)。
给大家介绍一家的烧烤摊。这家店的特点是,一个服务员有一个托盘,并且这个服务员只服务一桌。服务员很庄重地用托盘,端着一张空白的纸来到顾客面前,由顾客们轮流写上自己喜欢的牛肉串、烤面筋、烤花菜...,再选择调料黑胡椒、孜然...等信息。将纸放到托盘中后,由服务员送到烧烤师傅手中,烧烤师傅按照纸上的要求,烤好后将菜品装到碟子里,放在原来的托盘上。由服务员再端到顾客面前,顾客们分别拿走自己点的菜品。
这家烧烤摊名字叫:Thrift。
这可能是一段迄今为止对 Thrift 最奇怪的比喻。Thrift 是一个 RPC 框架,可将接口的参数转换成二进制数据。下面,介绍 Thrift 两个重要的接口:TProtocol 跟 TTransport。以刚刚烧烤摊为例子,大致可以有以下对应关系(可能有些许不恰当):
TProtocol:可以有很多不同的顾客,负责写内容TTransport:托盘 + 服务员,负责传递内容- TSocketTransport:服务员
- THeaderTransport:托盘
- Socket 连接的 IP 跟端口:桌号
- 传递给服务器的输出流:纸
- 调用接口的入参:纸上的内容
- 传递给客户端的输入流:碟子
- 调用接口的返回值:牛肉串、烤面筋、烤花菜...黑胡椒、孜然...
- 服务器:烧烤师傅
好了,广告结束。相信机智的你看到这里,对 Thrift 有了一定的了解。下面继续我们的 Dart 之旅:
首先要参考 nebula-java 源码,对 GraphServiceClient 进行调用。
这个环节我遇到了两个问题:
- 问题 1:nebula-java 使用的是 fbthrift,而 fbthrift 并没有 Dart 的实现。
- 解决方案:使用 Apache Thrift 的 Dart 实现。
- 问题 2:两个实现方案有着比较大的差异,比如说 Apache Thrift 没有 THeaderTransport,共同之处是,都有 Socket 的方式。
- 解决方案:这里先埋个雷,建立用 Socket 连接再说。
搞定上面两个问题后,我们可以通过 Dart Socket 连接,实现对 NebulaGraph 的访问。
这个步骤怎么说呢?就好像又来了一桌,现在两桌,一桌顾客和服务员都只会闽南语,一桌顾客和服务员都只会普通话。而烧烤师傅啥也不管,只看菜单。新来的这桌只有一个要求,跟隔壁桌点的要一模一样...在两桌语言不通的情况下,没有意外的话,这里要出意外。
好的,我们现在遇到了几个问题:
- 问题 1:返回了空数据,报错信息无从得知
- 解决思路:先使用 nebula-java,并对 Socket 发送数据的位置进行断点,将数据拷贝下来,通过 Dart Socket 直接发送,卒。到这个地方,我意识到不得不建立一个可以调试的环境。根据我朴素的直觉,客户端跟服务端应该是一个类似湖面倒影的结构。于是,参考过 nebula-java 客户端的代码后,我决定开了个小灶,建立了一个服务端 Mock,并使用返回伪造数据的方式,实现了 GraphService 接口。此时,服务端就具备了调试的条件。
- 问题 2:怎么确定 Mock 的结构是正确的?
- 解决思路:使用 nebula-java 客户端,连接 Mock 服务端,看看是否能够正常返回数据。如果能够正常返回数据,Mock 的结构上的准确性也就可以确定。这边调试使用的是不需要太多条件的 verifyClientVersion 接口。
至此,建立如图所示的结构:
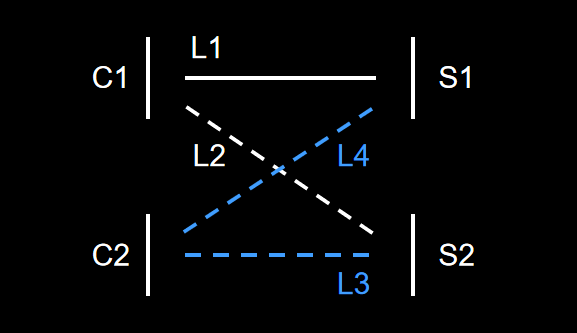
- 对应关系如下:
- C1:nebula-java
- S1:NebulaGraph 数据库
- C2:nebula_dart_gdbc
- S2:Mock 测试
- 整体思路如下:
- L1 是可靠的,可以发送准确数据,也能接收准确数据;
- L2 可以发送准确数据,用 L2 的连通性来确保 S2 的准确性;
- 通过 L3 对 C2 进行调试,当 L2 跟 L3 返回的数据一样时,说明此时的 C2 发送的数据是正确;
- 执行 L4,当 L4 跟 L1 返回的数据一样时,说明 C2 通过 Socket,连接到了数据库。
基本思路确定之后,开始了漫长的翻译(Java 代码变 Dart 代码)、调试,再翻译、再调试...,在 L2 跟 L3 中反复横跳。每个环节的数据表现形式都是纯数字数组,数组长度、下标对应的值错一个都可能功亏一篑。这里需要细心跟耐心。特别是数字操作上涉及到反码、补码、移位的操作,不同的参数有不同的字节长度,按位读写。以下,再列几个 L2、L3 反复横跳的过程中几个让人比较头大的问题:
- 问题 1:Apache 的 Thrift 版本,相比 fbthrift 版本缺了很多类,这里就不一一列举。
- 解决方案:将缺失的类,从 nebula-java 中的 fbthrift 中翻译,连同所依赖的第三方类也要跟着翻译(所幸依赖的并不多,只有 IO 相关的几个类。所幸做数据压缩的 zip 包有依赖,但实际没用到)。
- 问题 2:结构一样了,但发送的数据还是不一样,Apache 版本中,包括 Socket,用来写数据的容器是 Uint8List,所有放进去的数字都会被强行转成正数,但 fbthrift 中的数据是带正负号的。
- 解决方案:对所有类型进行修改,全部使用 Int8List 声明跟传输,包括 thrift 生成的类。
- 问题 3:在 Dart 中并没有 byte、short、int、long 的区分,所有的整型都是 int。
- 解决方案:同样是整数型,需要特别注意,根据实际的情况手动降低整型精度,从而达到与 Java 中声明类型后赋值时自动舍弃精度的效果。
到这里,L3 已经走通,C1 跟 C2 访问 S2,返回的数据一致,拿下模拟考!继续迎接挑战:
- 问题 4:调用 L4,通过 C2 连接到 S1,返回的数据还是空数据,明明 L2 跟 L3 从 S2 拿到的数据都是一样的,这让人很费解。
- 解决方法 1:改写 Apache 版本下 Socket 的机制,放弃使用创建时就指定消息回调,直接使用 async/await 的方式,使得调试更符合顺序思维。然后,对返回结果进行等待读取。虽然读到的数据依然是空的,不过在 Socket 使用方式上还是保留了这个写法。
- 解决方法 2:后来,我发现这个问题的原因是,Java Socket 跟 Dart Socket 之间写入的方式不同。在 nebula-java 中,接口间的数据传输使用了 THeaderTransport,数据会分为两段发送的,不确定是不是断点的位置不对,服务端拿到的都是一份两段合并后的数据。而 Dart 中的做法是将两个
List<int>拼接成一段合并发送,在 S2 的表现完全一致,这个问题就很隐蔽,过了相当长一段一行代码不写还不得不保持干活状态的时间。到最后改成在 Dart Socket 的一次传输中,强行将两个List<int>剥离,使用两个 Stream 进行传输。至此,L4 成功,连通性问题解决,说实话,最后这点带有一丝运气成分。
封装数据库连接
在这个环节,实现思路中断的情况比较少碰到,整体算流畅,比较花时间的是结果集的处理。
nebula_dart_gdbc,并没有沿用 NebulaGraph 其他客户端的写法。而是整体上参考了 JDBC 的思路,将数据库连接、执行、结果集等进行了封装,形成 dart_gdbc。在这套接口标准下,对 nebula_dart_gdbc 进行实现。
熟悉 JDBC 的朋友,对以下流程就不陌生了,dart_gdbc 的调用流程如下:
- 注册驱动
- 获取连接
- 创建语句
- 执行语句
- 处理结果集
- 关闭连接
以下是 nebula_dart_gdbc 在 dart_gdbc 的规范下的代码示例:
import 'package:nebula_dart_gdbc/nebula_dart_gdbc.dart';
void main() async {
// 注册驱动
DriverManager.registerDriver(NgDriver());
// 获取连接
var conn = await DriverManager.getConnection(
'gdbc.nebula://127.0.0.1:9669/?space=test',
username: 'root', // username is optional
password: 'nebula', // password is optional
);
// 创建语句
var stmt = await conn.createStatement();
// 执行语句
var rs = await stmt.executeQuery(gql: 'SHOW SPACES;');
// 打印结果
print(rs);
// 关闭连接
conn.close();
}
就目前而言,拿到结果集之后,还需要自行按数组下标位进行数据组装。结果集的结构采用“头部数组”+“数据数组”的形式。在实际的开发中,处理上可能会麻烦一些。目前,我正在考虑在 dart_gdbc 未来的版本中,加入对象图映射的埋点回调。或者再开一个 OGM 的项目。关于这一点,目前只是一个还不太成熟的想法。
结尾
在文章结束部分,跟大家分享下写这个项目的心路历程。
起初,我对工作量大有一定的心理准备,铁了心想试一试。上手之后,才意识到并不仅仅是语法翻译一下这么简单,特别是不同语言的生态不同,引用的第三方也就随之不同,即使是相同的功能,运行机制也有所不同,这一部分的工作量会比想象中的要大。
再一个就是没有办法对数据库直接断点调试,算是一种黑盒调用,如同凭借着微弱的光线在黑夜中前行,对毫无头绪的问题有时候会产生一种无力感,只能凭借着经验做一些猜测,然后一点点去验证。但当连上实际的数据库,并拿到数据的那一刻,即使多年来已经习惯了被 bug 吊打再消灭 bug 的流程,但还是激动了一下。当开始着手建立 dart_gdbc 规范的时候,在《序》里写到的“责无旁贷”在脑海里回荡。直到今天发布第一个版本,这份热情算多了一份实实在在的兑现。
最后,当然是希望这个项目能够对基础软件生态有所帮助。个人也会不断修复 bug,完善功能,希望能够成为一个稳定可靠的项目。对项目感兴趣的话,欢迎参与开发。另外,dart_gdbc 与 nebula_dart_gdbc 目前收录在【图社区】(https://github.com/graph-cn),以后有新的关于图的开源项目,也会在这里发布,欢迎围观。
最后的最后,这篇文章及项目的背后有思为和想念小鱼干的清蒸两位老师的帮助,感谢。
传送门
- dart_gdbc:https://github.com/graph-cn/dart_gdbc
- nebula_dart_gdbc:https://github.com/graph-cn/nebula_dart_gdbc
- fbthrift: https://github.com/dudu-ltd/fbthrift
谢谢你读完本文 (///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(з)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呀~
2023 年 NebulaGraph 技术社区年度征文活动正在进行中,来这里领取华为 Meta 60 Pro、Switch 游戏机、小米扫地机器人等等礼品哟~ 活动链接:https://discuss.nebula-graph.com.cn/t/topic/13970

用 nebula_dart_gdbc 在移动设备玩图数据库,泰酷辣!的更多相关文章
- 从一个 issue 出发,带你玩图数据库 NebulaGraph 内核开发
如何 build NebulaGraph?如何为 NebulaGraph 内核做贡献?即便是新手也能快速上手,从本文作为切入点就够了. NebulaGraph 的架构简介 为了方便对 NebulaGr ...
- 高性能内存图数据库RedisGraph(一)
作为一种简单.通用的数据结构,图可以表示数据对象之间的复杂关系.生物信息学.计算机网络和社交媒体等领域中产生的大量数据,往往是相互连接.关系复杂且低结构化的,这类数据对传统数据库而言十分棘手,一个简单 ...
- COSCon'19 | 如何设计新一代的图数据库 Nebula
11 月 2 号 - 11 月 3 号,以"大爱无疆,开源无界"为主题的 2019 中国开源年会(COSCon'19)正式启动,大会以开源治理.国际接轨.社区发展和开源项目为切入点 ...
- Neo4j图数据库管理系统开发笔记之一:Neo4j Java 工具包
1 应用开发概述 基于数据传输效率以及接口自定义等特殊性需求,我们暂时放弃使用Neo4j服务器版本,而是在Neo4j嵌入式版本的基础上进行一些封装性的开发.封装的重点,是解决Neo4j嵌入式版本Emb ...
- 图数据库(graph database)资料收集和解析 - daily
Motivation 图数据库中的高科技和高安全性中引用了一个关于图数据库(graph database)的应用前景的乐观估计: 预计到2017年,图数据库产业在数据库市场的份额将从2个百分点增长到2 ...
- Neo4j图数据库管理系统开发笔记之三:构建安全的RMI Service(Server)
RMI Server(服务端)主要包括以下功能:远程用户权限验证管理.远程服务接口实现类.Neo4j实体映射转换等.项目目录结构如下图所示: 3.2.1 远程用户权限验证管理 3.2.1.1 用户权限 ...
- Neo4j图数据库管理系统开发笔记之二:管理系统Server端界面一览
最近在neo4j java api和rmi的基础上,设计了一套neo4j管理工具,分为server端和client端,中间用rmi进行通信.基本功能包括图数据库基本信息维护管理(创建.编辑.删除.统计 ...
- Neo4j图数据库简介和底层原理
现实中很多数据都是用图来表达的,比如社交网络中人与人的关系.地图数据.或是基因信息等等.RDBMS并不适合表达这类数据,而且由于海量数据的存在,让其显得捉襟见肘.NoSQL数据库的兴起,很好地解决了海 ...
- 【笨嘴拙舌WINDOWS】设备无关图(*.bmp)
设备无关图在windows上面就是一个扩展名为.bmp的文件.我们知道每一种文件都是一个二进制流,只是这个二进制流的开头几个字节是规定了文件的格式..bmp的文件格式如下 “其中信息头是windows ...
- 图数据库 Titan 高速入门
尤其在互联网世界,图计算越来越受到人们的关注,而图计算相关的软件也越来越丰富.本文将高速展示 Titan这个open source 的图数据库. 注:本文的操作主要基于Titan 官方的两篇文档: - ...
随机推荐
- MacBook m2 笔记本 + k8s容器环境开发笔记
作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢! cnblogs博客 zhihu Github 公众号:一本正经的瞎扯 为最近两周在 MacBook m2 + k8s 容器环境的 ...
- Go 匿名函数与闭包
Go 匿名函数与闭包 匿名函数和闭包是一些编程语言中的重要概念,它们在Go语言中也有重要的应用.让我们来详细介绍这两个概念,并提供示例代码来帮助理解. 目录 Go 匿名函数与闭包 一.匿名函数(Ano ...
- WebAssembly入门笔记[4]:利用Global传递全局变量
利用WebAssembly的导入导出功能可以灵活地实现宿主JavaScript程序与加载的单个wasm模块之间的交互,那么如何在宿主程序与多个wasm之间传递和共享数据呢?这就需要使用到Global这 ...
- Java连接kubernates集群最优雅的两种方式
创建maven工程,pom.xml中引入连接k8s的客户端jar包: <properties> <maven.compiler.source>8</maven.compi ...
- Nginx负载均衡、location匹配
nginx的日志 ``` #log_format main '$remote_addr - $remote_user [$time_local] "$request" ' # '$ ...
- Linux系统NTP配置同步修改硬件时钟
前言: 硬件时钟:即BIOS时间,就是CMOS设置时看到的时间,存储在主板BIOS里,关机及断电后由主板电池供电维持时间的守时. 系统时钟:linux系统Kernel时间,由CPU守时,关机及断 ...
- Docker从认识到实践再到底层原理(九)|Docker Compose 容器编排
前言 那么这里博主先安利一些干货满满的专栏了! 首先是博主的高质量博客的汇总,这个专栏里面的博客,都是博主最最用心写的一部分,干货满满,希望对大家有帮助. 高质量博客汇总 然后就是博主最近最花时间的一 ...
- Liunx知识点整理
Linux知识点整理 目录和文件 ls (list)显示当前目录下的文件或目录 a 显示所有文件及目录 (ls内定将文件名或目录名称开头为"."的视为隐藏档,不会列出) l 除文件 ...
- webrtc终极版(一)5分钟搭建多人实时会议系统webrtc
webrtc终极版(一),支持https,在线部署[不是本地demo],采用RTCMultiConnection官方demo,5分钟即可搭建成功 @ 目录 webrtc终极版(一),支持https,在 ...
- 今天才知道 Ping 命令的意义
当ping一个域名的时候 可以知道这个域名的解析情况,也可以知道 当前电脑是否联通了 域名. 可以看到 diandaxia.com 的域名解析是 112.124.182.113 ,而www.dian ...