ZooKeeper论文阅读笔记
介绍
ZooKeeper 是一个开源的分布式协调服务,它提供了高可用性和一致性的数据管理和协调功能。它被设计用于构建可靠的分布式系统,并提供了一组简单而强大的 wait-free 原语,使开发人员能够处理分布式应用中的共享配置、命名服务、分布式锁、分布式队列等问题。
在论文中,客户端表示使用 Zookeeper 服务的应用,服务端表示一个运行 Zookeeper 程序的程序,znode 表示内存中的数据节点(Zookeeper 使用树形结构作为存储结构,整体就像一个文件系统)。
Zookeeper服务概述
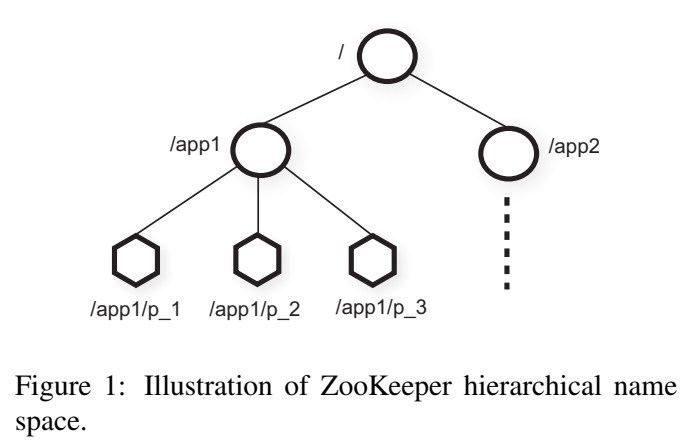
znode 有两种类型:
- 常规:数据对象正常创建和删除
- 临时:创建对象的 session 终止之后,对象会被删除
znode 默认最大存储 1MB 数据,这是可配置的。
在创建文件的时候设置 SEQUENTIAL 标志,那么会在文件名后增加一个自动增加的计数器。比如上图创建 /app1 节点时设置了 SEQUENTIAL 标志,那么连续创建三个 /app1/p_ 节点时结果如上图所示。ZooKeeper 实现了观测(watch)机制,能够在数据对象更新后通知客户端(由与客户端连接的服务端通知),观测只会触发一次,如果想继续监测需要重新设置 watch。
ZooKeeper 以库的形式向客户端提供 API,类似于 RPC 中的 client stub,库也负责客户端到 ZooKeeper 服务器的连接,每个连接即是一个 session,它有一个超时时间 s,如果在超时时间内没有收到客户端请求,那么服务器认为客户端出故障,客户端即便没有读写请求也要发送心跳避免超时。为了防止会话超时,ZooKeeper 客户端库在会话空闲 \(\frac{s}{3}\) 后发送心跳,如果在 \(\frac{2s}{3}\) 内没有收到服务器的消息,则切换到新服务器,
其中 s 是以毫秒为单位的会话超时
客户端API
create(path, data, flags):创建一个路径为path的 znode,将data[]保存到其中,返回新 znode 的名称,flags用来设置 znode 类型:普通或者临时,以及设置SEQUENTIAL标志。delete(path, version):如果版本匹配,删除path对应的 znode。exists(path, watch):如果path对应的 znode 存在,那么返回真,否则返回假。watch标志让客户端观测这个 znode。getData(path, watch):返回 znode 对应的数据和元数据,watch功能类似。setData(path, data, version):如果版本匹配,将data[]写入到path对应的 znode 中。getChildren(path, watch):返回 znode 的子节点集合。sync(path):等待目前所有未决的更新,path没什么用。
以上全部的方法提供了阻塞版本和非阻塞版本,如果传入版本号为-1,那么不进行版本检查。
Zookeeper保证
Zookeeper 给出了两个保证:
- 线性写入:所有改变 ZooKeeper 状态的更新都是串行的
- 客户端先进先出:所有来自客户端的请求按照先进先出顺序执行
Zookeeper 并不完全满足线性一致性,它只支持写请求的线性一致性,以及保证一个客户端的读操作一定可以读取到该客户端最后一个写操作的数据或者在这个写操作之后的其它客户端的写入数据,这是通过为每个写操作分配一个 zxid 来实现,zxid 是单调递增的,写请求的响应包含该写请求对应的 zxid,服务器将该写请求修改的 znode 的最近修改信息更新为该zxid(这句话是我的猜测),之后客户端发出读请求要求服务器读取的 znode 的 zxid 不小于客户端最近一次读/写请求返回的 zxid,如果该服务器在一定时间内还不能满足该要求,那么客户端会连接其它的服务器获取数据。
ZooKeeper 服务包含一组使用复制来实现高可用性和性能的服务器。ZooKeeper 使用简单的流水线架构实现,该架构允许 ZooKeeper 处理成百上千个未完成的请求,同时仍能实现低延迟。 这样的管道自然能够以 FIFO 顺序从单个客户端执行操作。 保证 FIFO 客户端顺序使客户端能够异步提交操作。 通过异步操作,客户端可以同时进行多个未完成的操作。
为了满足线性写入,Zookeeper 实现了一个 leader-based 的原子广播协议 ZAB,该协议改良自 Paxos 协议。
对于写入请求,如果与客户端连接的服务器是 Follower 节点,那么它会把请求转发给 Leader 服务器,如果是同步写,那么当写请求应用到超过半数服务器时返回响应给客户端,如果是异步写,那么立即返回成功响应给客户端。
对于读操作,不用转发给 Leader,直接返回服务器本地存储的数据即可。这样可能造成返回的数据不是最新的,但这是 ZooKeeper 可以容忍的。如果客户端想要最新的数据,那么它可以先发送一个 Sync 请求,该请求可以看作是一个空的写请求,由于 Zookeeper 的两个保证,在执行完 Sync 后再执行读操作就可以读取到所有在 Sync 之前执行的写请求数据了。
现在举个例子演示这两个保证如何保障系统运行。假设一个系统选举主节点管理其他节点,主节点随后需要更新一些配置,然后通知其他节点,要求:
- 主节点在修改配置过程,不希望其他节点访问正在被修改的配置
- 主节点在更新完成前崩溃,不希望其他节点访问这些破碎的配置
可以设置一个readyznode解决,主节点可以在配置前删除,完成后重新建立。当其他节点看到ready不存在时就不读取配置。
但是还会存在问题:如果其他节点看到ready后读取配置,但是主节点随即删除ready节点并开始修改配置,那么其他节点将得到过时的配置。这个问题可以采用 watch 机制来解决,ready删除后会及时通知其他节点,这样客户端就会放弃读取的数据,然后重新设置 watch,当配置文件更新完毕后通知客户端发送读取请求。
原语示例:
配置管理:只需要将配置保存在一个 znode 中,各个进程可以通过 watch 机制来获取配置更新通知。
组成员关系:组成员进程上线之后可以在组对应的 znode 之下创建对应的临时子 znode,成员进程退出之后临时znode也被删除,因此可以通过组 znode 的子znode获取组成员状态。
简单锁:应用试图创建同一个文件,如果 znode 创建成功,那么获取锁。如果 znode 已经存在,那么需要等待锁被释放(znode被删除)后才能继续尝试获取锁(创建znode)。
无惊群效应的简单锁:简单锁会出现大量进程竞争的情况,因为每次锁被释放后所有等待的进程都会被通知唤醒,但最终只有一个进程可以获取锁,可以将锁请求排序后,按次序分配锁,实现公平锁,如下面的算法所示:
Lock (l是 znode 路径)
1 n = create(l + “/lock-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if n is lowest znode in C, exit
4 p = znode in C ordered just before n
5 if exists(p, true) wait for watch event
6 goto 2
Unlock
1 delete(n)
读写锁:写锁和普通锁类似,和其他的锁互斥。读锁之间可以互相兼容,和写锁互斥。
Write Lock
1 n = create(l + “/write-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if n is lowest znode in C, exit
4 p = znode in C ordered just before n
5 if exists(p, true) wait for event
6 goto 2
Read Lock
1 n = create(l + “/read-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if no write znodes lower than n in C, exit
4 p = write znode in C ordered just before n
5 if exists(p, true) wait for event
6 goto 3
双栅栏:双栅栏用来保证多个客户端的计算同时开始和同时结束。客户端开始计算之前添加 znode 到栅栏对应的 znode 之下,结束计算之后删除 znode。客户端需要等待栅栏 znode 的子 znode 数量到达一定阈值后才能开始计算,客户端可以等待一个特殊的
ready的 znode 的创建,当数量到达阈值后创建。客户端退出的时候需要等待子 znode 全部被删除,同样可以通过删除ready删除。
Zookeeper实现
ZooKeeper 的组件如下图所示,ZooKeeper 的数据副本保存在每一个服务器的内存中,写操作需要通过一致性协议提交到数据库,而读取请求可以直接访问服务器本地数据库获得。ZooKeeper 在写请求修改到数据库之前会先将其写入日志(WAL)中,并在适当的时机持久化当前数据块的快照,故障后采用快照加日志的方式进行恢复。根据一致协议,写入请求会转发到领导(leader)节点。
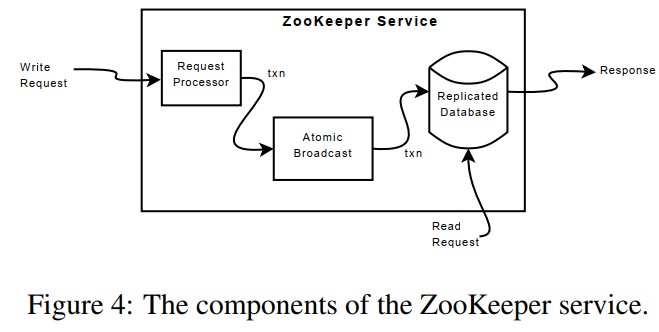
请求处理器
请求处理器收到写入请求之后,会将其转换为事务,与客户端发送的请求不同,事务是幂等的。 当领导者收到写入请求时,它会计算应用写入时系统的状态,并将其转换为捕获此新状态的事务。 必须计算未来状态,因为可能有尚未应用到数据库的未完成事务。 例如,如果客户端执行条件 setData 并且请求中的版本号与正在更新的 znode 的未来版本号相匹配,则该服务会生成一个包含新数据、新版本号和更新时间戳的 setDataTXN。 如果发生错误,例如版本号不匹配或要更新的 znode 不存在,则会生成 errorTXN。
原子广播(Atomic Broadcast)
所有更新 ZooKeeper 状态的请求都被转发给领导者。 领导者执行请求并通过原子广播协议 Zab 广播 ZooKeeper 的状态变化。 接收到客户端请求的服务器在接收到相应的状态变化时响应客户端。 Zab 默认使用 majority quorums 来决定提案,因此 Zab 和 ZooKeeper 只能在大多数服务器正确的情况下工作。Zab 保证领导者广播的更改按照发送的顺序进行交付,并且在广播自己的更改之前,先前领导者的所有更改都已交付给现在的领导者
ZAB 使用 TCP 协议传输数据,而 TCP 协议可以保证传输的数据按照发送顺序到达。
在正常操作期间,Zab 确实按顺序传递所有消息,并且只传递一次,但由于 Zab 不会持久记录传递的每条消息的 ID,因此 Zab 可能会在恢复期间重新传递消息。 因为使用的是幂等事务,多次投递是可以接受的,只要按顺序投递即可。 事实上,ZooKeeper 要求 Zab 至少重新投递上次快照开始后投递的所有消息
多副本数据库
当服务器故障后,使用周期性的快照和快照之后的日志恢复。创建快照的时候并不需要锁定数据库,相反,Zookeeper 通过优先深度搜索遍历 data-tree 中znode 里的数据并持久化到磁盘中,由于生成的快照可能应用了快照生成期间交付的状态更改的某些子集,因此结果可能与 ZooKeeper 在任何时间点的状态都不对应。 但是,由于状态更改是幂等的,只要我们按顺序应用状态更改,我们就可以应用它们两次。
例如,假设现在有两个 znode 节点分别为 /foo 和 /goo,这两个节点分别存储了数据 f1 和 g1,且版本号都为 1。此时开始生成快照,然后按序执行以下三个操作,操作序列含义为<transactionType,path,value,new-version>,此时快照检测点的位置不包含下面的操作序列。
- <SetFDataTrx,/foo,f2,2>
- <SetFDataTrx,/goo,g2,2>
- <SetFDataTrx,/foo,f3,3>
处理完这些状态更改后,/foo 和 /goo 的值分别为版本 3 和版本 2 的 f3 和 g2。 然而,快照可能记录了 /foo 和 /goo 分别具有版本 3 和 1 的值 f3 和 g1,这不是 ZooKeeper 数据树的有效状态。 但如果服务器崩溃并使用此快照恢复,然后 Zab执行检查点后的日志重新提交上面的三个操纵,则生成的状态可以正确对应崩溃前的服务状态。
参考博客:https://juejin.cn/post/6844903891146915848
ZooKeeper论文阅读笔记的更多相关文章
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
- [论文阅读笔记] GEMSEC,Graph Embedding with Self Clustering
[论文阅读笔记] GEMSEC: Graph Embedding with Self Clustering 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 已经有一些工作在使用学习 ...
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
随机推荐
- 聊聊 RocketMQ 名字服务
NameServer 是专为 RocketMQ 设计的轻量级名字服务,它的源码非常精简,八个类 ,少于1000行代码. 这篇文章, 笔者会从基础概念.Broker发送心跳包.NameServer 维护 ...
- 合宙ESP32C3使用PlatformIO开发点亮ST7735S
开发背景 模块使用的合宙的ESP32-C3(经典款) 购买连接 CORE ESP32核心板是基于乐鑫ESP32-C3进行设计的一款核心板,尺寸仅有21mm*51mm,板边采用邮票孔设计,方便开发者在不 ...
- dBeaver操作iotdb并实现导入和导出
1.windows下操作iotdb,现在官网下载相关的iotdb包 官网地址:https://archive.apache.org/dist/iotdb/ 一般建议下载 -all的 2.打开db ...
- JOIN 关联表中 ON、WHERE 后面跟条件的区别
SQL中join连接查询时条件放在on后与where后的区别 数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户. 在使用left jion时,on和wh ...
- Auto-GPT免费尝鲜之初体验-使用攻略和总结
写在前面的废话 ChatGPT 的交互模式,是和一个 "人" 对话聊天. 如果你想了解更多ChatGPT和AI绘画的相关知识,请参考:ChatGPT注册和变现思路,AI绘画教程汇总 ...
- 通过Scrum实现最大生产力的五种方法
在数字化.信息化.智能化蓬勃发展的今天,敏捷开发和Scrum已成为重塑项目管理的重要方式. 敏捷是一种体现不同方法的思维方式,包括了Scrum,看板,极限编程(XP).精益开发等众多框架. Scrum ...
- 银河麒麟使用kickstart二次打包制作安装镜像ISO
系统:银河麒麟 V10 SP2 服务器:百信恒山 TS02F-F30 安装方式:服务器挂载ISO镜像进行安装 1.安装 mkisofs 软件包: #yum install genisoimage 2. ...
- redhat7 team bonding 双网卡绑定 主备 负载均衡
team简介 team也被称为网络组,是将多个网卡聚合在一起,从而实现冗错和提高吞吐量.适用于redhat7.0以上版本,至多可支持8块网卡.team相对于之前的bonding技术,能提供更好的性能和 ...
- 小知识:将普通用户加入到docker组
新的OCI实例,OS选择的是OEL7.9,初始环境是没有安装docker的,我们可以直接使用yum安装,之后启动docker服务: [opc@oci-001 ~]$ sudo yum install ...
- $GNRMC
$GNRMC 格式: $GNRMC,<1>,<2>,<3>,<4>,<5>,<6>,<7>,<8>,&l ...