Flink 自定义 ClickHouse Table Connector 的简单实现
本次实现基于 Flink 1.18 版本,具体的对象之间的关系可以先参考官网的图:
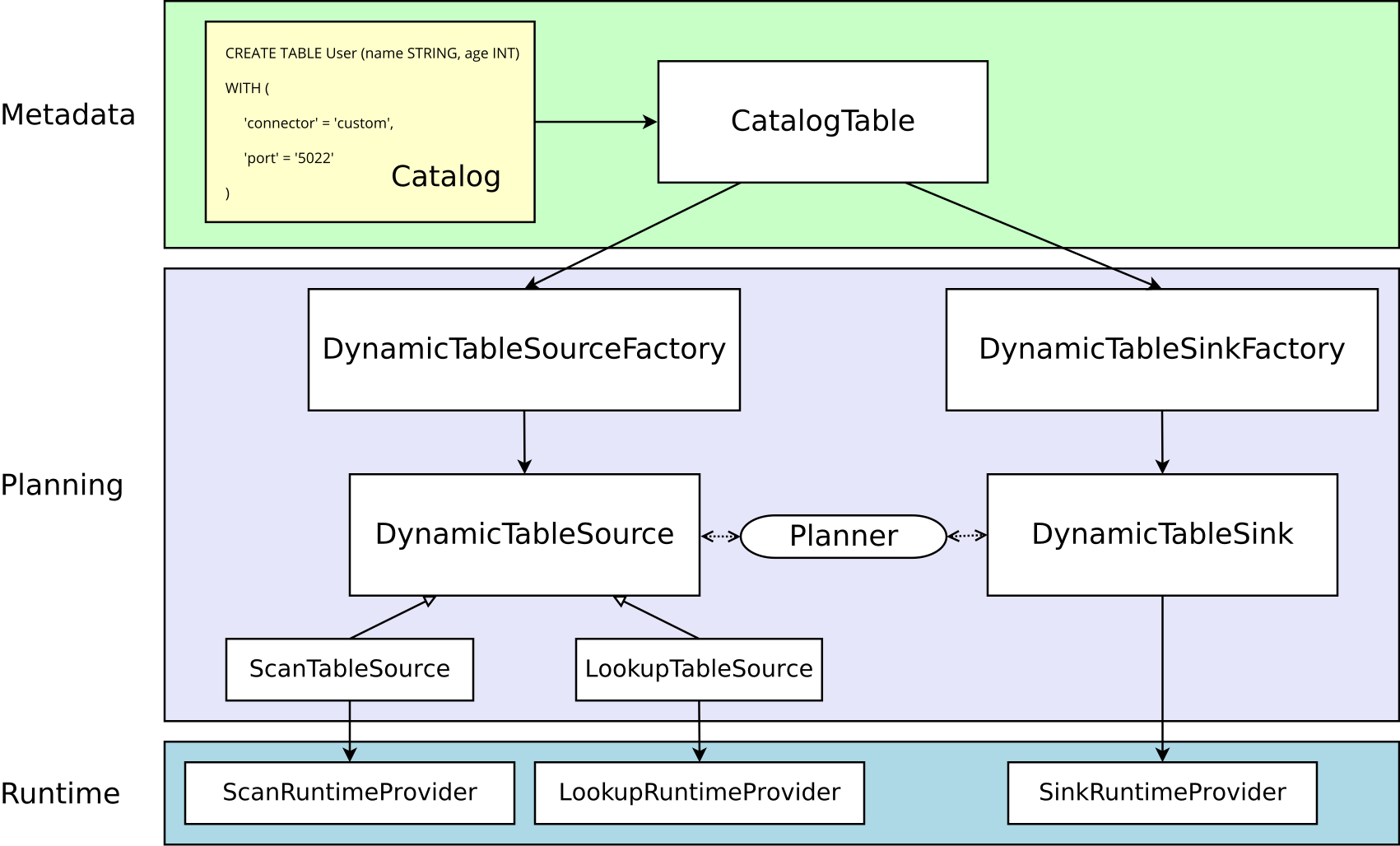
先拿官网上的 Socket 示例来说一下实现过程:
- 首先编写
SocketDynamicTableFactory实现DynamicTableSourceFactory接口。 - 在
SocketDynamicTableFactory中会返回SocketDynamicTableSource,同时返回实现了ScanTableSource接口。 - 在
SockeDynamicTableSource中返回了SocketSourceFunction,而具体的逻辑就是写在SocketSourceFunction中的。 SocketSourceFunction需要继承RichSourceFunction<RowData>类同时实现ResultTypeQueryable<RowData>接口,在其中的run方法中实现主要的逻辑,将结果发送至下游。- 另外关于序列化部分,需要编写
ChangelogCsvFormatFactory实现DeserializationFormatFactory接口,在其中会返回ChangelogCsvFormat。 - 而
ChangelogCsvFormat会实现DecodingFormat<DeserializationSchema<RowData>>接口,并在其中返回ChangelogCsvDeserializer。 - 同时
ChangelogCsvDeserializer又实现了DeserializationSchema<RowData>接口,并在其主要的方法deserialize中实现二进制反序列化的过程,也就是转换为RowData的过程。
官网的示例链接为:https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/dev/table/sourcessinks/
下面我们基于这个原理来实现一个简单的 ClickHouse Table Source,我们不做复杂的字段映射,仅完成指定表数据的读取,简单的将这个过程过一遍。
需要说明的是 Connector 项目和客户端的项目必须拆分为两个项目,因为 Connector 项目需要通过 Flink 的 ClassLoader 进行加载,也就是需要放到 Flink 的 lib 目录下然后再重启才可以,所以如果是一个整体的项目,那么 Flink 将会报错找不到具体的 Connector。
我们首先来创建 Connector 的项目,使用 Maven 来管理,pom.xml 文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>flink-1.18-table-source-example</artifactId>
<version>1.0.0-SNAPSHOT</version>
<name>Flink Table Source Example</name>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.18.0</flink.version>
<log4j.version>2.17.1</log4j.version>
</properties>
<repositories>
<repository>
<id>aliyun-maven</id>
<name>阿里云 central仓和jcenter仓的聚合仓</name>
<url>https://maven.aliyun.com/repository/public</url>
</repository>
</repositories>
<dependencies>
<!-- Table API 开发 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.18.0</version>
<scope>provided</scope>
</dependency>
<!-- ClickHouse Client -->
<dependency>
<groupId>com.clickhouse</groupId>
<!-- or clickhouse-grpc-client if you prefer gRPC -->
<artifactId>clickhouse-http-client</artifactId>
<version>0.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents.client5</groupId>
<artifactId>httpclient5</artifactId>
<version>5.2.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id> <!-- this is used for inheritance merges -->
<phase>package</phase> <!-- bind to the packaging phase -->
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
这里引入的 Flink Table API 开发相关的包都标记为 provided ,因为 Flink 本身已经存在这个包了,然后 ClickHouse 相关包需要作为依赖打进去,如果不打进去的话需要把独立的包放到 Flink 的 lib 目录下,因为 Connector 依赖 ClickHouse Client,所以这俩依赖必须同时加载,在提交任务时包含依赖是无效的,如果依赖不存在那么在提交任务时会报 NoClassDefFoundError 的错误。这里为了将依赖打进去,所以下面使用了 Maven 的插件。
我们在 ClickHouse 中有下面这么一张表:
CREATE TABLE user_score
(
`name` String,
`score` Int32,
`user_id` FixedString(16)
)
ENGINE = MergeTree
ORDER BY user_id
我们计划要在 Flink 中定义的 ClickHouse Table 如下:
CREATE TABLE user_score (name STRING, score INT, user_id BYTES)
WITH (
'connector' = 'clickhouse',
'hostname' = 'localhost',
'port' = '8123',
'username' = 'default',
'password' = '',
'database' = 'default',
'table' = 'user_score',
'format' = 'clickhouse-row'
);
首先我们创建 ClickHouse 连接所需配置的容器类:
package org.example.source.clickhouse;
import java.io.Serializable;
public class ClickHouseConnection implements Serializable {
private final String hostname;
private final int port;
private final String username;
private final String password;
private final String database;
private final String table;
public ClickHouseConnection(String hostname, int port, String username, String password, String database, String table) {
this.hostname = hostname;
this.port = port;
this.username = username;
this.password = password;
this.database = database;
this.table = table;
}
public String getEndpoint() {
StringBuilder builder = new StringBuilder();
builder.append("http://")
.append(this.hostname)
.append(":")
.append(this.port)
.append("/")
.append(this.database)
.append("?user=")
.append(username);
if(!"".equals(password)) {
builder.append("&password=")
.append(password);
}
return builder.toString();
}
public String getTable() {
return table;
}
}
这个类必须要实现 Serializable 接口,否则 Flink 会报错无法序列化。
然后我们创建 ClickHouseDynamicTableFactory 内容如下:
package org.example.source.clickhouse;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ConfigOptions;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.factories.DeserializationFormatFactory;
import org.apache.flink.table.factories.DynamicTableSourceFactory;
import org.apache.flink.table.factories.FactoryUtil;
import org.apache.flink.table.types.DataType;
import java.util.HashSet;
import java.util.Set;
public class ClickHouseDynamicTableFactory implements DynamicTableSourceFactory {
public static final ConfigOption<String> HOSTNAME = ConfigOptions.key("hostname")
.stringType()
.noDefaultValue();
public static final ConfigOption<Integer> PORT = ConfigOptions.key("port")
.intType()
.defaultValue(8123);
public static final ConfigOption<String> USERNAME = ConfigOptions.key("username")
.stringType()
.defaultValue("default");
public static final ConfigOption<String> PASSWORD = ConfigOptions.key("password")
.stringType()
.defaultValue("");
public static final ConfigOption<String> DATABASE = ConfigOptions.key("database")
.stringType()
.defaultValue("default");
public static final ConfigOption<String> TABLE = ConfigOptions.key("table")
.stringType()
.noDefaultValue();
@Override
public DynamicTableSource createDynamicTableSource(Context context) {
// 内置验证工具
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
final DecodingFormat<DeserializationSchema<RowData>> decodingFormat = helper.discoverDecodingFormat(
DeserializationFormatFactory.class,
FactoryUtil.FORMAT);
helper.validate();
// 获取已经验证的参数
final ReadableConfig options = helper.getOptions();
final String hostname = options.get(HOSTNAME);
final int port = options.get(PORT);
final String username = options.get(USERNAME);
final String password = options.get(PASSWORD);
final String database = options.get(DATABASE);
final String table = options.get(TABLE);
ClickHouseConnection clickHouseConnection = new ClickHouseConnection(hostname, port, username, password, database, table);
final DataType producedDataType =
context.getCatalogTable().getResolvedSchema().toPhysicalRowDataType();
// 返回 DynamicTableSource
return new ClickHouseDynamicTableSource(clickHouseConnection, decodingFormat, producedDataType);
}
@Override
public String factoryIdentifier() {
return "clickhouse";
}
@Override
public Set<ConfigOption<?>> requiredOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
options.add(HOSTNAME);
options.add(TABLE);
options.add(FactoryUtil.FORMAT); // use pre-defined option for format
return options;
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
options.add(PORT);
options.add(USERNAME);
options.add(PASSWORD);
options.add(DATABASE);
options.add(TABLE);
return options;
}
}
其中定义了各类参数,也就是 Flink SQL 中传入的参数,主要是进行了初步的参数校验等,其中 factoryIdentifier 返回的就是 connector 中的定义标识。
然后返回了 ClickHouseDynamicTableSource ,其中就包括传入的连接参数等信息,然后我们继续创建 ClickHouseDynamicTableSource 类:
package org.example.source.clickhouse;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.table.connector.ChangelogMode;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.connector.source.ScanTableSource;
import org.apache.flink.table.connector.source.SourceFunctionProvider;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.DataType;
public class ClickHouseDynamicTableSource implements ScanTableSource {
private final ClickHouseConnection clickHouseConnection;
private final DecodingFormat<DeserializationSchema<RowData>> decodingFormat;
private final DataType producedDataType;
public ClickHouseDynamicTableSource(
ClickHouseConnection clickHouseConnection,
DecodingFormat<DeserializationSchema<RowData>> decodingFormat,
DataType producedDataType) {
this.clickHouseConnection = clickHouseConnection;
this.decodingFormat = decodingFormat;
this.producedDataType = producedDataType;
}
@Override
public ChangelogMode getChangelogMode() {
return decodingFormat.getChangelogMode();
}
@Override
public ScanRuntimeProvider getScanRuntimeProvider(ScanContext runtimeProviderContext) {
// 发送到集群的运行时上下文
final DeserializationSchema<RowData> deserializer = decodingFormat.createRuntimeDecoder(
runtimeProviderContext,
producedDataType);
DataStructureConverter converter = runtimeProviderContext.createDataStructureConverter(producedDataType);
// 创建 SourceFunction<RowData>
final SourceFunction<RowData> sourceFunction = new ClickHouseSourceFunction(
clickHouseConnection,
deserializer,
converter);
// 第二个参数设置是否是有界流
return SourceFunctionProvider.of(sourceFunction, true);
}
@Override
public DynamicTableSource copy() {
// 实现拷贝
return new ClickHouseDynamicTableSource(clickHouseConnection, decodingFormat, producedDataType);
}
@Override
public String asSummaryString() {
return "ClickHouse Table Source";
}
}
然后这里主要设置了一些集群上下文信息,包括反序列化器、数据的转换器等,然后将通过 SourceFunctionProvider 返回 SourceFunction 实例,第二个参数就表示是否是有界流,如果是无界流要设置为 false 。
最后再来创建 ClickHouseSourceFunction :
package org.example.source.clickhouse;
import com.clickhouse.client.ClickHouseClient;
import com.clickhouse.client.ClickHouseNode;
import com.clickhouse.client.ClickHouseResponse;
import com.clickhouse.data.ClickHouseFormat;
import com.clickhouse.data.ClickHouseRecord;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.typeutils.ResultTypeQueryable;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.data.RowData;
import org.apache.flink.types.Row;
import org.apache.flink.types.RowKind;
public class ClickHouseSourceFunction extends RichSourceFunction<RowData> implements ResultTypeQueryable<RowData> {
private final ClickHouseConnection clickHouseConnection;
private final DeserializationSchema<RowData> deserializer;
private final DynamicTableSource.DataStructureConverter converter;
private volatile boolean isRunning = true;
public ClickHouseSourceFunction(ClickHouseConnection clickHouseConnection, DeserializationSchema<RowData> deserializer, DynamicTableSource.DataStructureConverter converter) {
this.clickHouseConnection = clickHouseConnection;
this.deserializer = deserializer;
this.converter = converter;
}
@Override
public TypeInformation<RowData> getProducedType() {
return deserializer.getProducedType();
}
@Override
public void run(SourceContext<RowData> ctx) throws Exception {
String endpoint = clickHouseConnection.getEndpoint();
String table = clickHouseConnection.getTable();
ClickHouseNode clickHouseNode = ClickHouseNode.of(endpoint);
while (isRunning) {
try (ClickHouseClient client = ClickHouseClient.newInstance(clickHouseNode.getProtocol())) {
ClickHouseResponse response = client.read(endpoint)
.format(ClickHouseFormat.RowBinaryWithNamesAndTypes)
.query("select name, score, user_id from " + table)
.executeAndWait();
for(ClickHouseRecord record : response.records()) {
Row row = new Row(RowKind.INSERT, record.size());
row.setField(0, record.getValue("name").asString());
row.setField(1, record.getValue("score").asInteger());
row.setField(2, record.getValue("user_id").asBinary());
ctx.collect((RowData) converter.toInternal(row));
}
response.close();
cancel();
} catch (Throwable t) {
t.printStackTrace(); // print and continue
}
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
主要的业务代码在 run 方法中,这里会读取数据并发送至下游,下游以批的方式进行计算,其实原始数据还是流。我们这里查询完一波数据之后直接接将循环退出,下游会将这批数据作为整体进行计算。
由于我们直接就查询出了结果,所以这里直接可以在这里创建 Row 并转换为 RowData 发送到下游,不需要再经过反序列化处理了,因为反序列化只能传入 byte[] 类型的参数,一来一回比较麻烦,这里直接就处理了。但是我们还必须定义一套反序列化的类,因为在 Flink SQL 中 format 参数是必传的,我们可以随便传入一个,比如常用的 csv 也可以,但是这样会造成困扰,所以我们专门定义一个为我们 Connector 使用的 format 即可,仅仅让参数校验通过。好像没找到其他方法可以使得 format 参数不传,这里先暂且这样实现。
另外调用 row.setField 的时候,第一个参数一定是位置参数,不能是字符串,否则会报错:
Accessing a field by name is not supported in position-based field mode.
然后我们来创建反序列化相关的类,首先是 ClickHouseFormatFactory :
package org.example.source.clickhouse;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.factories.DeserializationFormatFactory;
import org.apache.flink.table.factories.DynamicTableFactory;
import java.util.Collections;
import java.util.Set;
public class ClickHouseFormatFactory implements DeserializationFormatFactory {
@Override
public DecodingFormat<DeserializationSchema<RowData>> createDecodingFormat(DynamicTableFactory.Context context, ReadableConfig formatOptions) {
// 返回 DecodingFormat<DeserializationSchema<RowData>> 的实现
return new ClickHouseFormat();
}
@Override
public String factoryIdentifier() {
return "clickhouse-row";
}
@Override
public Set<ConfigOption<?>> requiredOptions() {
return Collections.emptySet();
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
return Collections.emptySet();
}
}
这里返回的标识就是 clickhouse-row 我们在所有不同的 ClickHouse Connector 中都可以引用这一个,然后返回了 ClickHouseFormat 我们继续来创建:
package org.example.source.clickhouse;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.table.connector.ChangelogMode;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.DataType;
import org.apache.flink.types.RowKind;
public class ClickHouseFormat implements DecodingFormat<DeserializationSchema<RowData>> {
public ClickHouseFormat() {
}
@Override
public DeserializationSchema<RowData> createRuntimeDecoder(DynamicTableSource.Context context, DataType producedDataType) {
final TypeInformation<RowData> producedTypeInfo = context.createTypeInformation(
producedDataType);
final DynamicTableSource.DataStructureConverter converter = context.createDataStructureConverter(producedDataType);
// 返回 DeserializationSchema<RowData> 的实现
return new ClickHouseDeserializer(converter, producedTypeInfo);
}
@Override
public ChangelogMode getChangelogMode() {
return ChangelogMode.newBuilder()
.addContainedKind(RowKind.INSERT)
// 批处理不能添加除 INSERT 之外的其他操作
// .addContainedKind(RowKind.DELETE)
.build();
}
}
这里需要注意的一点就是,getChangelogMode 方法中定义了支持的操作,如果是批处理模式那么只支持 INSERT 操作,其余的都不支持,否则将会报错:
Querying a table in batch mode is currently only possible for INSERT-only table sources. But the source for table 'default_catalog.default_database.user_score' produces other changelog messages than just INSERT.
因为批处理就是一批数据,相当于只有插入操作,而流处理可以支持各类操作。
这里返回了 ClickHouseDeserializer 然后我们来实现它:
package org.example.source.clickhouse;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.table.connector.RuntimeConverter;
import org.apache.flink.table.connector.source.DynamicTableSource.DataStructureConverter;
import org.apache.flink.table.data.RowData;
import java.io.IOException;
public class ClickHouseDeserializer implements DeserializationSchema<RowData> {
private final DataStructureConverter converter;
private final TypeInformation<RowData> producedTypeInfo;
public ClickHouseDeserializer(
DataStructureConverter converter,
TypeInformation<RowData> producedTypeInfo) {
this.converter = converter;
this.producedTypeInfo = producedTypeInfo;
}
@Override
public void open(InitializationContext context) throws Exception {
converter.open(RuntimeConverter.Context.create(ClickHouseDeserializer.class.getClassLoader()));
}
@Override
public RowData deserialize(byte[] message) throws IOException {
return null;
}
@Override
public boolean isEndOfStream(RowData nextElement) {
return false;
}
@Override
public TypeInformation<RowData> getProducedType() {
return producedTypeInfo;
}
}
这个写法也非常简单,因为我们在 SourceFunction 中直接进行了数据处理,所以这里 deserialize 直接返回空即可,我们也不会调用它。
以上这样,ClickHouse 的 Connector 就定义好了,然后我们安装到本地 Maven 仓库,以便于开发时可以引用它:
mvn install
安装成功后即可创建一个项目来使用它。
项目的 pom.xml 定义如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>flink-1.18-example</artifactId>
<version>1.0-SNAPSHOT</version>
<name>Flink Table Example</name>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.18.0</flink.version>
<log4j.version>2.17.1</log4j.version>
</properties>
<repositories>
<repository>
<id>aliyun-maven</id>
<name>阿里云 central仓和jcenter仓的聚合仓</name>
<url>https://maven.aliyun.com/repository/public</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.example</groupId>
<artifactId>flink-1.18-table-source-example</artifactId>
<version>1.0.0-SNAPSHOT</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>jar-with-dependencies</shadedClassifierName>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
这里我们引入了 Flink 的相关依赖,但是都标记为 provided ,然后我们也引入了我们自己的 Connector 但是也标记为 provided ,因为我们之后运行时要放到 Flink 的 lib 下,所以不需要带上。另外我们也不需要引入 ClickHouse 的依赖,因为我们的 Connector 中已经包含了。
这里我们使用了 maven-shade-plugin 进行打包,主要是为了合并 resources 下面的 services 中的内容,这个等下我们会说,然后我们创建一个测试代码,内容如下:
package org.example;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class ClickHouseTableExample {
public static void main(String[] args) {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
tableEnv.executeSql("CREATE TABLE user_score (\n" +
" `name` STRING,\n" +
" `score` INTEGER,\n" +
" `user_id` BYTES\n" +
") WITH (\n" +
" 'connector' = 'clickhouse',\n" +
" 'hostname' = 'localhost',\n" +
" 'port' = '8123',\n" +
" 'username' = 'default',\n" +
" 'password' = 'wSqDxDAt',\n" +
" 'database' = 'default',\n" +
" 'table' = 'user_score',\n" +
" 'format' = 'clickhouse-row'\n" +
");\n").print();
tableEnv.executeSql("SELECT sum(score), name from user_score group by name;").print();
}
}
这是一段很简单的代码,主要就是做了一点统计,其中的模式设置为了 BATCH ,其实如果 Source Connector 定义为批,那么运行模式既可以设置为流也可以设置为批,如果是设置为流在聚合时,所有的计算过程都会更新出来,而如果设置为批,则只有一个最终的结果,结果是在 SourceFunction 退出后才会最终输出。如果 SourceFunction 是无限循环,那么永远也得不到最终的结果,但是流运行模式可以不断地得到当前的结果。如果 Source Connector 定义为流,那么当前的运行模式只能设置为流,所有的聚合结果都会根据流的到来实时输出。
现在程序还无法运行,这时候会报错:
Could not find any factory for identifier 'clickhouse' that implements 'org.apache.flink.table.factories.Factory' in the classpath.
这是因为具体的 DynamicTableSource 和 DynamicTableSink 是通过 Java 的 SPI 提供发现的,简单来说定义方法如下,我们在项目的 resources 目录下,对于 Maven 详细的目录就是 src/main/resources 下创建子目录 META-INF/services ,然后创建文件 org.apache.flink.table.factories.Factory ,内容如下:
org.example.source.clickhouse.ClickHouseDynamicTableFactory
org.example.source.clickhouse.ClickHouseFormatFactory
这样程序在运行时就会找到对应 Class 的位置从而加载它。
在本地运行时,需要将相关的 provided 注释掉并运行即可,然后如果是打包提交集群时,默认如果其他依赖包也有 SPI 相关的文件,那么会把当前项目的覆盖掉,所以上面在 Maven 中配置了下面的内容:
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
这个表示将当前项目的 ServicesResource 和打包中已经存在的进行合并,这样我们上面写的文件就会带到发布的包中了。
最后上面 pom.xml 中的 filters 也必须配置,否则一些多余的文件不过滤掉在运行时会报错:
Invalid signature file digest for Manifest main
表示签名无效,去掉后才可以正常运行。
这样我们先将 Connector 放到 Flink 集群中所有的 lib 目录下,然后重启 Flink 集群,最后再将当前项目通过 mvn package 打成的包提交到集群运行就可以了。
Reference:
- https://developer.aliyun.com/article/1045096
- https://www.modb.pro/db/634537
- https://juejin.cn/post/7212901628769189947
Flink 自定义 ClickHouse Table Connector 的简单实现的更多相关文章
- 自定义 Azure Table storage 查询过滤条件
本文是在Azure Table storage 基本用法一文的基础上,介绍如何自定义 Azure Table storage 的查询过滤条件.如果您还不太清楚 Azure Table storage ...
- Flink自定义Sink
Flink自定义Sink Flink 自定义Sink,把socket数据流数据转换成对象写入到mysql存储. #创建Student类 public class Student { private i ...
- IOS自定义日历控件的简单实现(附思想及过程)
因为程序要求要插入一个日历控件,该空间的要求是从当天开始及以后的六个月内的日历,上网查资料基本上都说只要获取两个条件(当月第一天周几和本月一共有多少天)就可以实现一个简单的日历,剩下的靠自己的简单逻辑 ...
- Flink系统之Table API 和 SQL
Flink提供了像表一样处理的API和像执行SQL语句一样把结果集进行执行.这样很方便的让大家进行数据处理了.比如执行一些查询,在无界数据和批处理的任务上,然后将这些按一定的格式进行输出,很方便的让大 ...
- Java利用自定义注解、反射实现简单BaseDao
在常见的ORM框架中,大都提供了使用注解方式来实现entity与数据库的映射,这里简单地使用自定义注解与反射来生成可执行的sql语句. 这是整体的目录结构,本来是为复习注解建立的项目^.^ 好的,首先 ...
- Flink实战(六) - Table API & SQL编程
1 意义 1.1 分层的 APIs & 抽象层次 Flink提供三层API. 每个API在简洁性和表达性之间提供不同的权衡,并针对不同的用例. 而且Flink提供不同级别的抽象来开发流/批处理 ...
- Flink源码分析 - 剖析一个简单的Flink程序
本篇文章首发于头条号Flink程序是如何执行的?通过源码来剖析一个简单的Flink程序,欢迎关注头条号和微信公众号"大数据技术和人工智能"(微信搜索bigdata_ai_tech) ...
- Flink 自定义source和sink,获取kafka的key,输出指定key
--------20190905更新------- 沙雕了,可以用 JSONKeyValueDeserializationSchema,接收ObjectNode的数据,如果有key,会放在Objec ...
- flink 自定义触发器 定时或达到数量触发
flink 触发器 触发器确定窗口(由窗口分配程序形成)何时准备由窗口函数处理.每个WindowAssigner都带有一个默认触发器. 如果默认触发器不适合需求,我们就需要自定义触发器. 主要方法 触 ...
- 【Flink】使用之前,先简单了解一下Flink吧!
目录 Flink简单介绍 概述 无边界数据流和有边界数据流 技术栈核心组成 架构体系 重要角色 Flink与Spark架构概念转换 Flink简单介绍 概述 在使用Flink之前,我们需要大概知 ...
随机推荐
- Java中使用JSON传递字符串的注意事项
一.问题由来 项目开发中,由于实际需要将某一个功能模块抽取成了一个单独的服务,其他地方需要调用的时候,通过Spring提供的RestTemplate类发送请求进行调用. 经过测试这种方法完全可行,我和 ...
- [转载]Linux根据关键词查找文件/函数/结构体命令整理
本文来自博客园,作者:Jcpeng_std,转载请注明原文链接:https://www.cnblogs.com/JCpeng/p/15077235.html 一.查找文件 使用 Linux 经常会遇到 ...
- NJUPT自控第一次积分赛的小总结(一)题目感受
快开学了事情真的好多啊 -_- 忙完积分赛就赶紧要去复习期末了...线代还是依托答辩啥都不懂 先看题目吧,RT,我们队(我)选择的是第一题(仅仅是因为很简单罢啦) 一开始看题目,心想不就调调pid吗, ...
- 记录--使用 JS 实现基本的截图功能
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 思路分析 在开始动手之前,分析一下整个功能的实现过程: 根据图片大小创建 canvas1 画布,并将原图片直接定位在 canvas1 上: ...
- Redis 中 scan 命令太坑了,千万别乱用!!
作者:铂赛东\链接:www.jianshu.com/p/8cf8aac3dc25 1 原本以为自己对redis命令还蛮熟悉的,各种数据模型各种基于redis的骚操作.但是最近在使用redis的scan ...
- QT实现参数批量配置
QT实现批量配置 需求 一些参数需要批量化配置 之前搭建的FPGA的寄存器控制模型 使用AXI-lite搭建 直接操作上位机 这里需要一个可以快速配置所有参数的上位机 需要保存文件,可以保留上一次的参 ...
- 感悟:FPGA的串行及并行设计思路
前言 FPGA设计过程中, 会遇到大量的串行转并行或者并行转串行的问题; 这些问题主要体现在FPGA对于速度和面积的均衡上; 一般而言, FPGA使用并行的设计可以提高处理的速度, 消耗更多的资源; ...
- Codeforces Round #682 (Div. 2)
CF1438A Specific Tastes of Andre 洛谷传送门 CF1438A 代码(全铺成1就可以了) #include <cstdio> #include <cct ...
- #第一类斯特林数,NTT#CF960G Bandit Blues
题目 给你三个正整数 \(n\),\(a\),\(b\),定义 \(A\) 为一个排列中是前缀最大值的数的个数, 定义 \(B\) 为一个排列中是后缀最大值的数的个数,求长度为 \(n\) 的排列中满 ...
- Jetty的server模块
启用server模块,执行如下命令: java -jar $JETTY_HOME/start.jar --add-modules=server 命令的输出,如下: INFO : server init ...