笔记本电脑上的聊天机器人: 在英特尔 Meteor Lake 上运行 Phi-2

对应于其强大的能力,大语言模型 (LLM) 需要强大的算力支撑,而个人计算机上很难满足这一需求。因此,我们别无选择,只能将它们部署至由本地或云端托管的性能强大的定制 AI 服务器上。
为何需要将 LLM 推理本地化
如果我们可以在典配个人计算机上运行最先进的开源 LLM 会如何?好处简直太多了:
- 增强隐私保护: 私有数据不需要发送至外部 API 进行推理。
- 降低延迟: 节省网络往返的次数。
- 支持离线工作: 用户可以在没有网络连接的情况下使用 LLM (常旅客的梦想!)。
- 降低成本: 无需在 API 调用或模型托管上花一分钱。
- 可定制: 每个用户都可以找到最适合他们日常工作任务的模型,甚至可以对其进行微调或使用本地检索增强生成 (RAG) 来提高适配度。
这一切的一切都太诱人了!那么,为什么我们没有这样做呢?回到我们的开场白,一般典配笔记本电脑没有足够的计算能力来运行具有可接受性能的 LLM。它们既没有数千核的 GPU,也没有快如闪电的高内存带宽。
接受失败,就此放弃?当然不!
为何现在 LLM 推理本地化有戏了
聪明的人类总能想到法子把一切东西变得更小、更快、更优雅、更具性价比。近几个月来,AI 社区一直在努力在不影响其预测质量的前提下缩小模型。其中,有三个领域的进展最振奋人心:
硬件加速: 现代 CPU 架构内置了专门用于加速最常见的深度学习算子 (如矩阵乘或卷积) 的硬件,这使得在 AI PC 上使能新的生成式 AI 应用并显著提高其速度和效率成为可能。
小语言模型 (Small Language Models,SLMs): 得益于在模型架构和训练技术上的创新,这些小模型的生成质量与大模型相当甚至更好。同时,由于它们的参数较少,推理所需的计算和内存也较少,因此非常适合资源受限的设备。
量化: 量化技术通过减少模型权重和激活的位宽来降低内存和计算要求,如将权重和激活从 16 位浮点 (
fp16) 降至 8 位整型 (int8)。减少位宽意味着模型推理时的内存需求更少,因而能加速内存受限步骤 (如文本生成的解码阶段) 的延迟。此外,权重和激活量化后,能充分利用 AI 加速器的整型运算加速模块,因而可以加速矩阵乘等运算。
本文,我们将综合利用以上三种技术对微软 Phi-2 模型进行 4 比特权重量化,随后在搭载英特尔 Meteor Lake CPU 的中端笔记本电脑上进行推理。在此过程中,我们主要使用集成了英特尔 OpenVINO 的 Hugging Face Optimum Intel 库。
注意: 如果你想同时量化权重和激活的话,可参阅 该文档。
我们开始吧。
英特尔 Meteor Lake
英特尔 Meteor Lake 于 2023 年 12 月推出,现已更名为 Core Ultra,其是一个专为高性能笔记本电脑优化的全新 架构。
Meteor Lake 是首款使用 chiplet 架构的英特尔客户端处理器,其包含:
高至 16 核的 高能效 CPU,
集成显卡 (iGPU): 高至 8 个 Xe 核心,每个核心含 16 个 Xe 矢量引擎 (Xe Vector Engines,XVE)。顾名思义,XVE 可以对 256 比特的向量执行向量运算。它还支持 DP4a 指令,该指令可用于计算两个宽度为 4 字节的向量的点积,将结果存储成一个 32 位整数,并将其与另一个 32 位整数相加。
神经处理单元 (Neural Processing Unit,NPU),是英特尔架构的首创。NPU 是专为客户端 AI 打造的、高效专用的 AI 引擎。它经过优化,可有效处理高计算需求的 AI 计算,从而释放主 CPU 和显卡的压力,使其可处理其他任务。与利用 CPU 或 iGPU 运行 AI 任务相比,NPU 的设计更加节能。
为了运行下面的演示,我们选择了一台搭载了 Core Ultra 7 155H CPU 的 中端笔记本电脑。现在,我们选一个可爱的小语言模型到这台笔记本电脑上跑跑看吧!
注意: 要在 Linux 上运行此代码,请先遵照 此说明 安装 GPU 驱动。
微软 Phi-2 模型
微软于 2023 年 12 月 发布 了 Phi-2 模型,它是一个 27 亿参数的文本生成模型。
微软给出的基准测试结果表明,Phi-2 并未因其较小的尺寸而影响生成质量,其表现优于某些最先进的 70 亿参数和 130 亿参数的 LLM,甚至与更大的 Llama-2 70B 模型相比也仅有一步之遥。
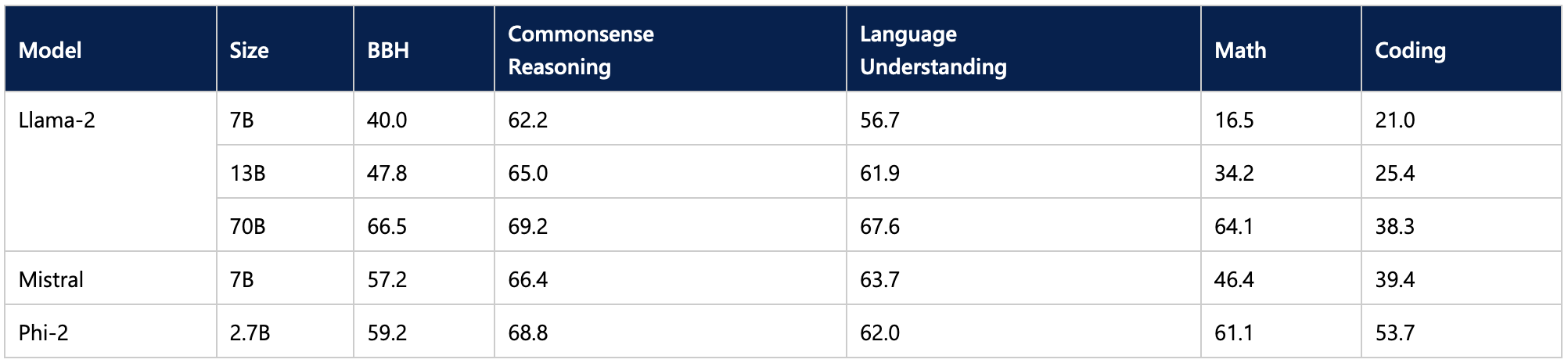
这使其成为可用于笔记本电脑推理的有利候选。另一个候选是 11 亿参数的 TinyLlama 模型。
现在,让我们看看如何缩小模型以使其更小、更快。
使用英特尔 OpenVINO 和 Optimum Intel 进行量化
英特尔 OpenVINO 是一个开源工具包,其针对许多英特尔硬件平台对 AI 推理工作负载进行优化 (Github、文档),模型量化是其重要特性之一。
我们与英特尔合作,将 OpenVINO 集成至 Optimum Intel 中,以加速 Hugging Face 模型在英特尔平台上的性能 (Github,文档)。
首先,请确保你安装了最新版本的 optimum-intel 及其依赖库:
pip install --upgrade-strategy eager optimum[openvino,nncf]
optimum-intel 支持用户很容易地把 Phi-2 量化至 4 比特。我们定义量化配置,设置优化参数,并从 Hub 上加载模型。一旦量化和优化完成,我们可将模型存储至本地。
from transformers import AutoTokenizer, pipeline
from optimum.intel import OVModelForCausalLM, OVWeightQuantizationConfig
model_id = "microsoft/phi-2"
device = "gpu"
# Create the quantization configuration with desired quantization parameters
q_config = OVWeightQuantizationConfig(bits=4, group_size=128, ratio=0.8)
# Create OpenVINO configuration with optimal settings for this model
ov_config = {"PERFORMANCE_HINT": "LATENCY", "CACHE_DIR": "model_cache", "INFERENCE_PRECISION_HINT": "f32"}
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OVModelForCausalLM.from_pretrained(
model_id,
export=True, # export model to OpenVINO format: should be False if model already exported
quantization_config=q_config,
device=device,
ov_config=ov_config,
)
# Compilation step : if not explicitly called, compilation will happen before the first inference
model.compile()
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
results = pipe("He's a dreadful magician and")
save_directory = "phi-2-openvino"
model.save_pretrained(save_directory)
tokenizer.save_pretrained(save_directory)
ratio 参数用于控制将多少权重量化为 4 比特 (此处为 80%),其余会量化至 8 比特。 group_size 参数定义了权重量化组的大小 (此处为 128),每个组都具有独立的缩放因子。减小这两个值通常会提高准确度,但同时会牺牲模型尺寸和推理延迟。
你可以从我们的 文档 中获取更多有关权重量化的信息。
注意: 你可在 Github 上 找到完整的文本生成示例 notebook。
那么,在我们的笔记本电脑上运行量化模型究竟有多快?请观看以下视频亲自体验一下!播放时,请选择 1080p 分辨率以获得最大清晰度。
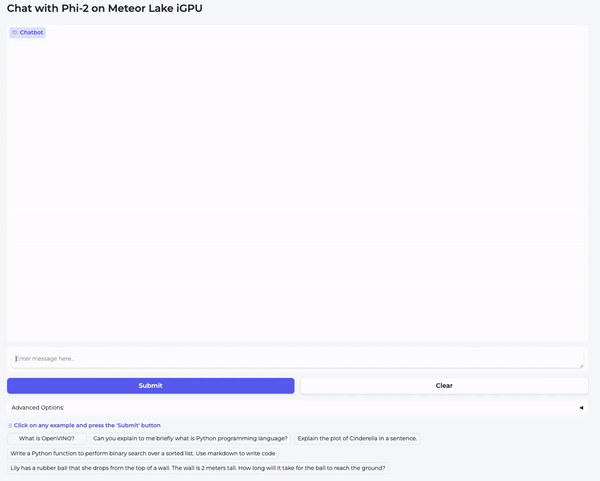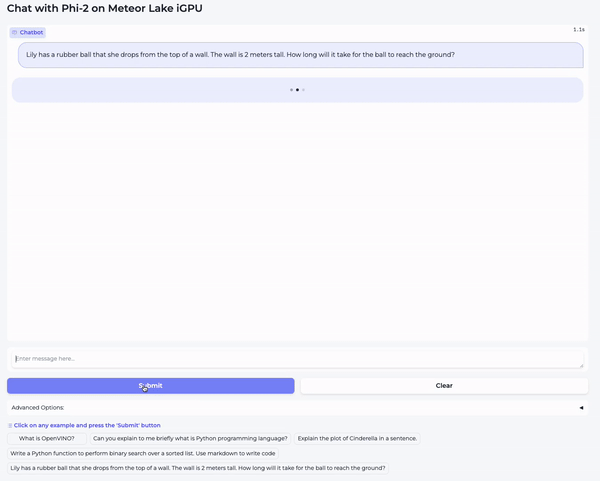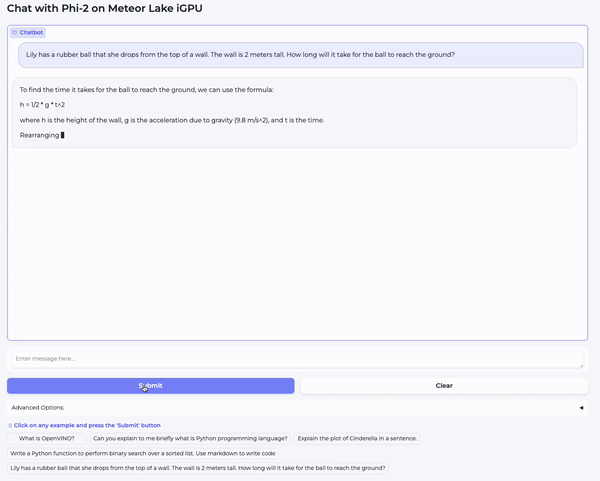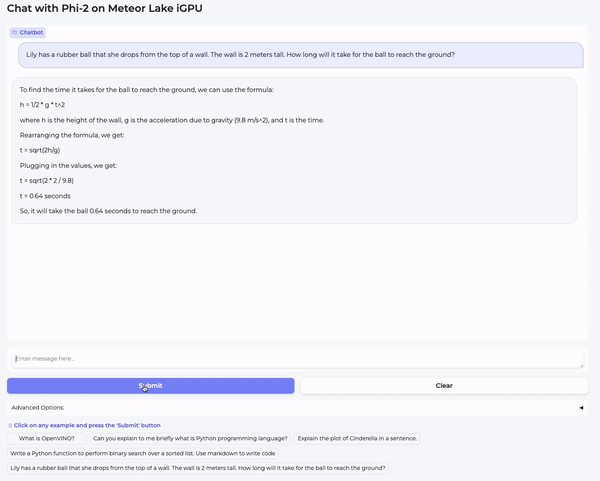
在第一个视频中,我们向模型提了一个高中物理问题: “Lily has a rubber ball that she drops from the top of a wall. The wall is 2 meters tall. How long will it take for the ball to reach the ground?”
在第二个视频中,我们向模型提了一个编码问题: “Write a class which implements a fully connected layer with forward and backward functions using numpy. Use markdown markers for code.”
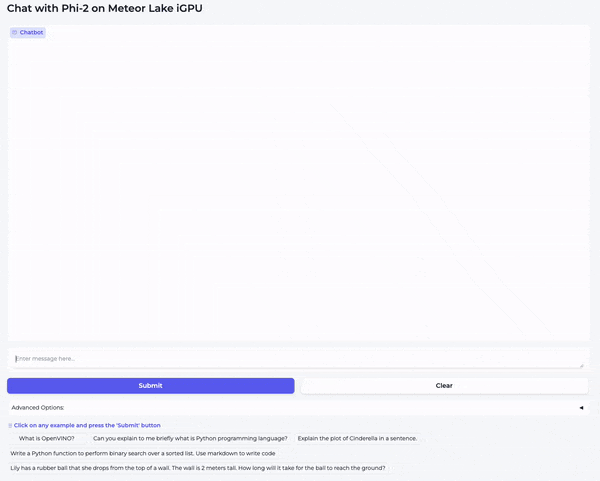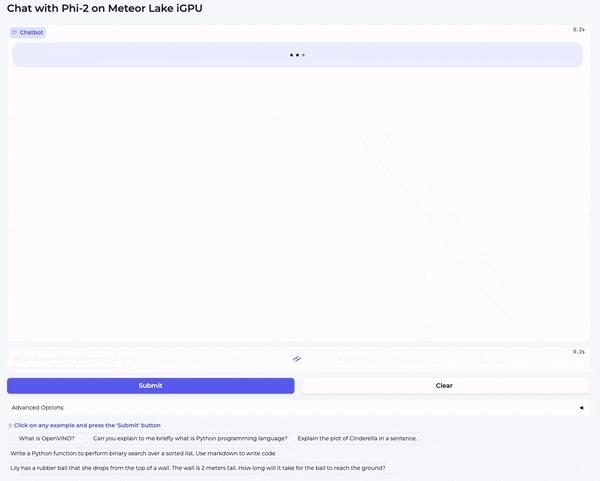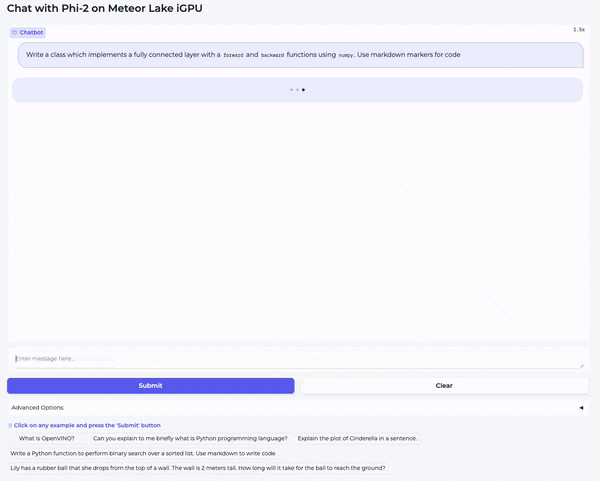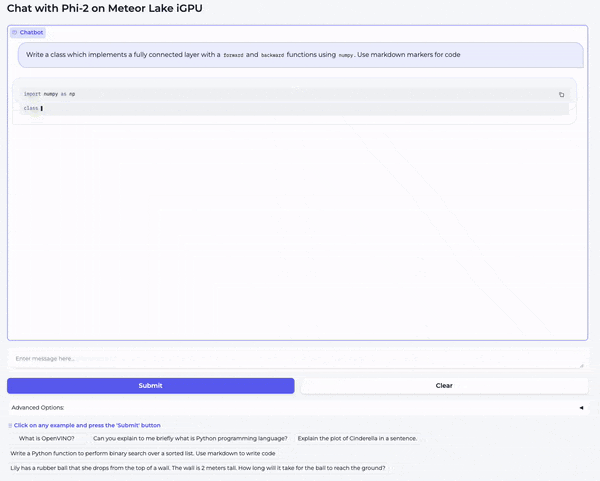
如你所见,模型对这两个问题生成的答案质量都非常高。量化加快了生成速度,但并没有降低 Phi-2 的质量。我本人很愿意在我的笔记本电脑上每天使用这个模型。
总结
借助 Hugging Face 和英特尔的工作,现在你可以在笔记本电脑上运行 LLM,并享受本地推理带来的诸多优势,如隐私、低延迟和低成本。我们希望看到更多好模型能够针对 Meteor Lake 平台及其下一代平台 Lunar Lake 进行优化。Optimum Intel 库使得在英特尔平台上对量化模型变得非常容易,所以,何不试一下并在 Hugging Face Hub 上分享你生成的优秀模型呢?多多益善!
下面列出了一些可帮助大家入门的资源:
如若你有任何问题或反馈,我们很乐意在 Hugging Face 论坛 上解答。
感谢垂阅!
英文原文: https://hf.co/blog/phi2-intel-meteor-lake
原文作者: Julien Simon,Ella Charlaix,Ofir Zafrir,Igor Margulis,Guy Boudoukh,Moshe Wasserblat
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
笔记本电脑上的聊天机器人: 在英特尔 Meteor Lake 上运行 Phi-2的更多相关文章
- 优化 VR 动作类游戏《Space Pirate Trainer*》以便在英特尔® 集成显卡上实现卓越的表现
Space Pirate Trainer* 是一款面向 HTC Vive*.Oculus Touch* 和 Windows Mixed Reality* 的原创发行游戏.版本 1.0 于 2017 年 ...
- 增加游戏受众:在英特尔核显上运行MR游戏
为了获得良好的用户体验,通常VR游戏需要稳定在每秒90帧,这意味着整个场景只有11.1毫秒的时间来进行左右眼渲染,这就是为何VR游戏需要配备高端的独立显卡.现在来看看我们如何使用最新版英特尔图形性能分 ...
- 在配有英特尔® Iris™ 显卡的系统上通过优化对 Just Cause 3 进行增强
高端 PC 继续通过高性能显卡驱动桌面游戏. 一流的"梦想机器"基于第六代智能 英特尔® 酷睿™ 处理器i7-6700K等 CPU,通常与高端独立显卡配合使用以运行要求最严苛的游戏 ...
- QQ聊天机器人 Delphi代码
QQ聊天机器人 前几日,看到杂志上有一篇关于开发QQ聊天机器人的文章.谈到了对QQ循环发送消息内容,感觉倒也很好玩,于是拿起Delphi开始了我的QQ聊天机器人之路. 首先要明白自己要做什么, ...
- 0基础搭建基于OpenAI的ChatGPT钉钉聊天机器人
前言:以下文章来源于我去年写的个人公众号.最近chatgpt又开始流行,顺便把原文内容发到博客园上遛一遛. 注意事项和指引: 注册openai账号,需要有梯子进行访问,最好是欧美国家的IP,亚洲国家容 ...
- Intel 英特尔
英特尔 英特尔 基本资料 公司名称:英特尔(集成电路公司) 外文名称:Intel Corporation(Integrated Electronics Corporation) 总部地 ...
- 英特尔关闭PC计算卡项目—插个卡片就能升级个人电脑
在 2017 年的美国国际消费电子展上,电脑芯片巨头英特尔公司曾经推出一个名为“计算卡”的新产品,相当于把个人电脑的重要零部件整合到了一张信用卡大小的卡片设备中,未来用户升级个人电脑,只需要拔下旧卡片 ...
- [转帖]高通推出八核笔电处理器骁龙8cx 能超英特尔吗?
高通推出八核笔电处理器骁龙8cx 能超英特尔吗? https://baijiahao.baidu.com/s?id=1619154699684981202&wfr=spider&for ...
- [转帖]抢先AMD一步,英特尔推出新处理器,支持LPDDR5!
抢先AMD一步,英特尔推出新处理器,支持LPDDR5! http://www.eetop.cn/cpu_soc/6946240.html 2019.10 intel的最新技术发展. 近日,知名硬件爆料 ...
- [转帖]英特尔首次使用其3D堆叠架构演示Lakefield芯片设计
英特尔首次使用其3D堆叠架构演示Lakefield芯片设计 http://www.chinapeace.org.cn/keji/201904/2812749.html 这段时间学习最大的收获: . 发 ...
随机推荐
- Java中枚举配合switch语句用法-2022新项目
一.业务场景 项目开发中经常会遇到多条件判断的情况,如果判断条件少的话使用if/elseif/else还比较好处理,如果判断条件多的话,则在使用这种语句就不太合适. 如果是自定义的一些内容,比如不同的 ...
- MinGW编译Python至pyd踩坑整理
不需要安装VS工具,pyd使用说明. 用scoop自动安装配置MinGw 需要魔法,用包管理scoop安装不需要手动配置.这一步可以自行下载mingw64然后手动配置. scoop install m ...
- class cl表示 汇聚 集合 ss表示 阴性 这里表示抽象
class cl表示 汇聚 集合 ss表示 阴性 这里表示抽象
- Android Material组件库(日期选择和时间选择器)基本使用
原文:Android Material组件库(日期选择和时间选择器)基本使用 - Stars-One的杂货小窝 简单的封装下Material组件里的日期选择器和时间选择器的使用方法 效果 代码 需要添 ...
- day01-2-导入驱动和工具类
满汉楼01-2 4.功能实现01 4.1导入驱动和工具类 4.1.1导入驱动 首先将连接mysql的相关jar包引入项目中,分别右键,点击add as library 4.1.2导入工具类Utilit ...
- 逆向通达信Level-2 续九 (无帐号打开itrend研究版)
此itrend研究版的版本比较旧. 本篇演示三图,用例进程同为0x4970. 1. itrend不支持脱机,游客登陆.没有帐号不能打开.现在以无帐号打开. 2. itrend支持高清,当打开主界面就会 ...
- 公开的Webservice集锦
备注:以下所有的来自 互联网,版权归原作者所有 股票行情数据 WEB 服务(支持香港.深圳.上海基金.债券和股票:支持多股票同时查询) Endpoint: http://webservice.webx ...
- 单体JOB向分布式JOB迁移案例
一.背景 1.1前言 相信大家在工作中多多少少都离不开定时任务吧,每个公司对定时任务的具体实现都不同.在一些体量小的公司或者一些个人独立项目,服务可能还是单体的,并且在服务器上只有一台实例部署,大多数 ...
- 【leetcode 952. 按公因数计算最大组件大小】【欧拉筛+并查集】
import java.util.ArrayList; import java.util.Arrays; import java.util.List; class Solution { List< ...
- 如何在uniapp中优雅地使用WebView
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 从webview页面传值到uniapp中 官方文档已经很详细了,这里给大家上我的实战代码,首先在webview页面中引入相关依赖: < ...