【转载】 一块GPU顶数千个CPU内核,英伟达的这个强化学习利器技术细节终于公开了
原文地址:
https://mp.weixin.qq.com/s/FmFqmIqmknkpBQbNb2ioDA
======================================================
很多机器人强化学习任务都面临计算需求和仿真速度的瓶颈,而英伟达这个仿真环境可以将过去需要数千个 CPU 核参与训练的任务移植到单个 GPU 上完成训练。
强化学习已经成为机器学习中最有前途的研究领域之一,在解决复杂问题方面展现出了巨大的潜力。基于强化学习的系统在很多具有挑战性的任务中展现出了超越人类的性能,比如围棋、国际象棋、「星际争霸」、DOTA 等等。
此外,基于强化学习的方法也为机器人应用带来了希望,比如解魔方、通过模仿动物来学习运动等。
但直到现在,多数强化学习机器人研究者都不得不使用 CPU 和 GPU 的组合来运行强化学习系统。二者各司其职:CPU 用于模拟环境物理、计算奖励和运行环境,而 GPU 用于在训练和推理期间加速神经网络模型,以及在需要时进行渲染。
然而,在为序列任务优化的 CPU 内核和提供大规模并行运算的 GPU 之间来回切换本质上是低效的,需要于训练过程中在系统的不同部分之间进行多点数据传输。因此,机器人深度强化学习的可扩展性面临两个关键瓶颈:1)庞大的计算需求;2)有限的仿真速度。在拥有多个自由度的机器人学习长视野行为时,这个问题尤其具有挑战性。
流行的物理引擎,如 MuJoCo、PyBullet、DART、Drake、V-Rep 等,需要大型 CPU 集群来解决具有挑战性的强化学习任务,自然会面临这些瓶颈。例如,OpenAI 2019 年推出了一个会玩魔方的机械手,为了训练这个机械手,OpenAI 动用了大约 30,000 个 CPU 内核(920 台 32 核计算机)。

在一个类似的手持立方体定位任务中,OpenAI 也用到了 6144 个 CPU 内核组成的 384 个系统集群,再加上 8 个 Volta V100 GPU,而且需要近 30 个小时的训练才能达到最佳效果。这种手持立方体定位任务非常复杂,背后有着复杂的物理学、动力学原理和高维连续控制空间。

加速模拟和训练的一种方法是使用硬件加速器。GPU 已经在计算机图形学中取得了巨大的成功,自然也适用于高度并行的模拟。之前已经有研究采用了这种方法,并在 GPU 上运行仿真显示了非常有前景的结果,证明使用 RL 可以极大地减少训练时间,并解决庞大的计算资源需求。然而,一些瓶颈仍然没有解决,即模拟是在 GPU 上,但物理状态被复制回 CPU。在这种模式中,观察和奖励使用优化的 c++ 代码计算,然后复制回 GPU。此外,只有简化的基于物理的场景得到了训练,而不是典型的机器人环境。
为了克服这些瓶颈,去年,英伟达发布了用于强化学习的物理模拟环境 Isaac Gym 预览版。它可以借助 GPU 的并行计算能力,将过去需要数千个 CPU 核参与训练的任务移植到单个 GPU 上完成训练。
为什么 Isaac Gym 可以如此高效?昨天,英伟达机器人研究科学家(前 OpenAI 研究科学家)Ankur Handa 在推特上公布,他们已经发布了 Isaac Gym 的技术报告,里面详细解释了 Isaac Gym 的构建细节。
论文链接:https://arxiv.org/pdf/2108.10470.pdf
Isaac Gym 是一个端到端的高性能机器人仿真平台,它运行一个端到端的 GPU 加速训练 pipeline,使研究人员能够克服上述限制,在连续控制任务中实现 2-3 个数量级的训练加速。
具体来说,Isaac Gym 利用 NVIDIA PhysX 提供了一个 GPU 加速的模拟后端,允许它以只有使用高度并行才能达到的速度收集机器人 RL 所需的经验数据。它提供了一个基于 PyTorch 张量的 API,可以在 GPU 上本地访问物理模拟的结果。观测张量可以作为策略网络的输入,而产生的动作张量可以直接反馈到物理系统中。
借助端到端的方法,观察、奖励和动作的缓冲可以在整个学习过程中保留在 GPU 上,因此不需要从 CPU 读取数据。这种设置使得一个 GPU 上可以同时处理数以万计的环境,研究者可以轻松地在本地运行实验。
基于这一平台,研究者复现了 OpenAI 的手持立方体定位任务。实验表明,在 A100 上,Isaac Gym 可以实现与 OpenAI 相似的性能结果,即使用前馈连续成功 20 次,使用 LSTM 网络连续成功 37 次,但分别只用了 1 小时和 6 小时左右。相比之下,之前 OpenAI 的研究分别需要 30 个小时和 17 个小时。

此外,研究者还在其他多个机器人任务上进行了实验,Isaac Gym 都实现了明显的加速。

以下是报告细节节选。
端到端 GPU 强化学习
Isaac Gym 通过利用英伟达的 PhysX GPU 加速模拟引擎实现了这些结果,使其能够收集机器人 RL 所需的经验数据。除了快速物理模拟以外,Isaac Gym 还支持在 GPU 上进行观察和奖励计算,从而避免严重的性能瓶颈,特别是消除了 GPU 与 CPU 之间昂贵的数据传输。通过这种方式实施,Isaac Gym 实现了完整的端到端 GPU 强化学习 pipeline。
Isaac Gym 提供了一个简单的 API,用于创建包括机器人和物体场景,支持从常见的 URDF(Unified Robot Description Format)和 MJCF 文件格式加载数据。每个环境都可以根据需要进行多次复制,同时保留复制之间的变化能力(例如通过域随机化)。该环境可以同时并行模拟,而不需要与其他环境交互。
使用一个完全由 GPU 加速的仿真和训练 pipeline 可以帮助降低研究阻碍,使得以前只能在大型 CPU 集群完成的任务,现在仅用一个 GPU 即可解决。Isaac Gym 还包括一个基本的近似策略优化 (PPO) 实现和一个简单的 RL 任务系统,用户可以根据需要替换为其他任务系统或 RL 算法。当示例使用的是 PyTorch 时,用户也能够通过定制与 TensorFlow 训练库集成。
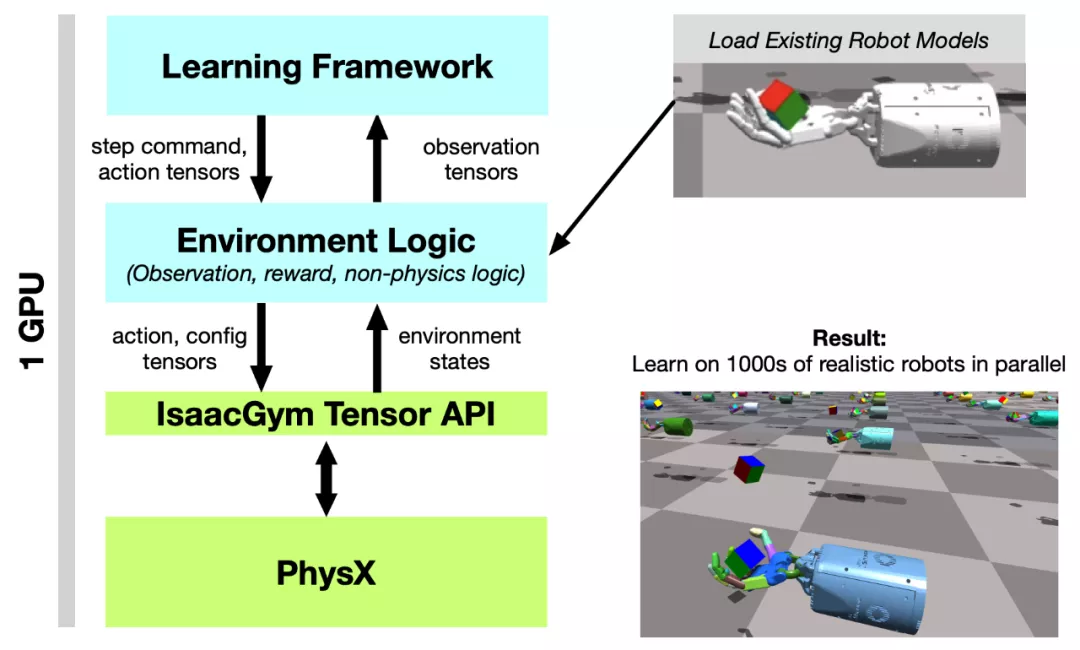
图 2:系统概述。Tensor API 提供了一个 Python 代码接口,可以直接在 GPU 上实现 PhysX 后端以及 get 和 set 模拟器状态,在整个 RL 训练 pipeline 中能实现 100 倍到 1000 倍的速度提升,同时提供高保真度的仿真,并且能够与现有机器人模型连接。
这项研究的主要贡献包括:
开发了用于机器人学习任务的高保真 GPU 加速的机器人模拟器;
Python 中的 Tensor API 将物理缓冲区封装到 PyTorch 张量中,从而提供对物理缓冲区的直接访问,而无需受到任何 CPU 限制;
实施多个高度复杂的机器人操作环境,这些环境可以在一个 GPU 上以每秒数十万 step 的速度模拟;
在充满挑战的机器人环境中,使用 Isaac Gym 和 深度强化学习进行高性能训练的结果。
实验结果
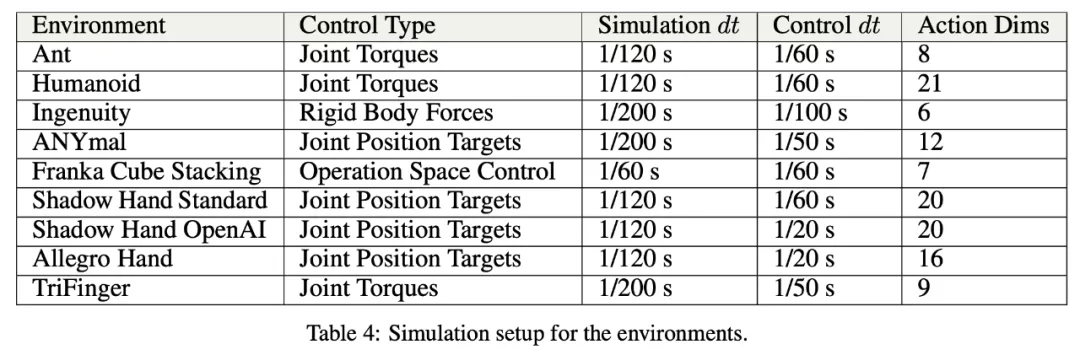
该研究在多种模拟环境中实现了显著的训练加速:在单个 NVIDIA A100 GPU 上,Ant 和 Humanoid 环境可以分别在 20 秒和 4 分钟内实现高性能运动,而 ANYmal 的训练也只需要不到 2 分钟的时间,使用 AMP 的 Humanoid 角色动画训练需要 6 分钟,使用 Shadow Hand 旋转立方体需 35 分钟。
研究者首先进行了「Ant 实验」,在这个环境中,智能体被训练在平坦的地面上运行。实验发现,随着智能体数量的增加,训练时间如预期中一样在减少。也就是说,环境数量由 256 个改变为 8192 个,增加了 5 个数量级,达到 7000 个奖励数量级的训练时间从 1000 秒 (约 16.6 分钟) 减少到了 100 秒(约 1.6 分钟)。但 Ant 在单个 GPU 上仅用 20 秒就可以达到 3000 次运动效果。
「Ant」是模拟最简单的环境之一,每秒并行环境步骤的数量可能高达 700K。当环境数量从 8192 增加到 16384 时,由于水平长度减少,研究者没能再观测到增益。

研究者还为 ANYmal 开发了一个粗糙地面的运动任务,并通过将训练好的策略转移到实体机器人上来验证了该方法的有效性。机器人学习在不平坦的地面、斜坡、楼梯和障碍物上行走,除了对平坦地形环境的观察外,它还需要接收机器人周围地形高度的测量数据。

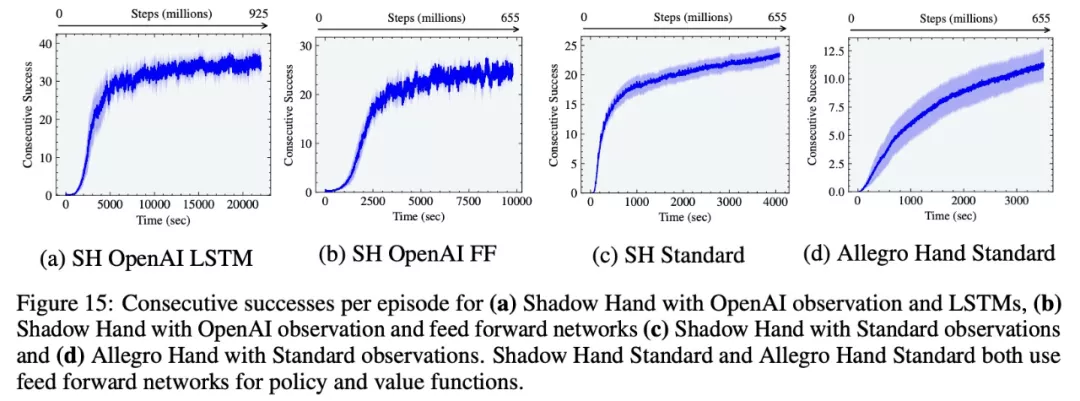
该研究使用不对称的 actor-critic 和域随机化重现 OpenAI Shadow Hand 立方体的训练设置。实验结果表明,该研究在 A100 上,前馈连续 20 次成功和 LSTM 网络连续 37 次成功,平均分别在大约 1 小时和 6 小时内获得与当时 OpenAI 实验结果相似的性能,成功容差为 0.4 rad。相比之下,使用传统 RL 训练设置,在 CPU 集群(384 个 CPU,每个 CPU 具有 16 个内核)和 8 个 NVIDIA V100 GPU、MuJoCo 的组合上,OpenAI 的工作分别需要 30 小时和 17 小时。
值得一提的是, OpenAI 仅显示 1 个随机种子的结果,相比之下,该研究中最好的种子在短短 2.5 小时内使用 LSTM 实现了 37 次连续成功。
该研究还在 ANYmal 和 TriFinger 上演示了模拟到现实的传输结果,这进一步展示了该研究的模拟器执行高保真接触丰富操作任务的能力。
【转载】 一块GPU顶数千个CPU内核,英伟达的这个强化学习利器技术细节终于公开了的更多相关文章
- 玩深度学习选哪块英伟达 GPU?有性价比排名还不够!
本文來源地址:https://www.leiphone.com/news/201705/uo3MgYrFxgdyTRGR.html 与“传统” AI 算法相比,深度学习(DL)的计算性能要求,可以说完 ...
- 基于英伟达Jetson TX1的GPU处理平台
基于英伟达Jetson TX1 GPU的HDMI图像输入的深度学习套件 [309] 本平台基于英伟达的Jetson TX1视觉计算的全功能开发板,配合本公司研发的HDMI输入图像采集板:Jetson ...
- 英伟达GPU 嵌入式开发平台
英伟达GPU 嵌入式开发平台 1. JETSON TX1 开发者组件 JETSON TX1 开发者组件是视觉计算的全功能 开发平台,旨在让您能够快速地安装和运行. 该组件带有 Lin ...
- 【转载】 DeepMind发表Nature子刊新论文:连接多巴胺与元强化学习的新方法
原文地址: baijiahao.baidu.com/s?id=1600509777750939986&wfr=spider&for=pc 机器之心 18-05-15 14:26 - ...
- 英伟达GPU虚拟化---申请英伟达测试License
此文基于全新的License 2.0系统,针对vGPU License的试用申请以及软件下载和License管理进行了详细的说明,方便今后我们申请测试License,快速验证GPU的功能. 试用步骤: ...
- Linux查看英伟达GPU信息
命令: nvidia-smi 结果:
- 【转载】GPU深度发掘(一)::GPGPU数学基础教程
作者:Dominik Göddeke 译者:华文广 Contents 介绍 准备条件 硬件设备要求 软件设备要求 两者选择 初始化OpenGL GLUT OpenGL ...
- X86架构CPU常识(主频,外频,FSB,cpu位和字长,倍频系数,缓存,CPU扩展指令集,CPU内核和I/O工作电压,制造工艺,指令集,超流水线与超标量)
1.主频 主频也叫时钟频率,单位是MHz,用来表示CPU的运算速度. CPU的主频=外频×倍频系数.很多人认为主频就决定着CPU的运行速度,这不仅是个片面的,而且对于服务器来讲,这个认识也出现了偏差. ...
- 获取Linux进程运行在哪个CPU内核上面的方法
首先,当某些时候,在一段程序或者借助第三方软件进行程序协助的时候,在性能的优化,以及程序bug的排除上面,可能会想知道该程序执行的进程被调度到了哪一个CPU内核进行工作,从而可以推断是否是受限于硬件还 ...
- Linux 有问必答:如何知道进程运行在哪个 CPU 内核上?
问题:我有个 Linux 进程运行在多核处理器系统上.怎样才能找出哪个 CPU 内核正在运行该进程? 当你在 多核 NUMA 处理器上运 行需要较高性能的 HPC(高性能计算)程序或非常消耗网络资源的 ...
随机推荐
- Tomcat问题修复系列之后台缓存不足
系统运维时,在tomcat窗口发现一个警告 后台缓存收回进程无法释放上下文的缓存的10%-请考虑增加缓存的最大大小.在逐出之后,缓存中约保留XXX KB的数据. 无法将位于[/WEB-INF/view ...
- JavaScript中如何终止forEach循环&跳出for(双层)循环?
在JavaScript中,forEach方法是用于遍历数组的,通常没有直接终止循环的机制.然而,我们可以使用一些技巧来模拟终止forEach循环.以下是几种常见的方法 1.使用return语句:在fo ...
- Java对称加解密算法AES
Java对称加解密算法AES import org.apache.commons.codec.binary.Base64; import org.apache.commons.lang3.String ...
- Navicat 连接SQL Server LocalDB的方法
截止2021年11月,Sql Server LocalDB的资料网上并不多见,出来了其实也有一段年头了. SqlServerManagerStudio自带的工具进行查询使用体验并不好,Navicat是 ...
- Xilinux PS与PL交互:裸机程序读写FPGA-REG
背景 当时在搞ZYNQ驱动的时候,出于TDD的思想,从最简单的功能开始验证.因此就涉及到了下面的需求. PL侧会提供寄存器地址供PS端读写,这部分的寄存器在PL侧作为Avalon的IP,对PS端来说, ...
- 福利来了!MoneyPrinterPlus可以自动配置环境和自动运行了
之前开源了MoneyPrinterPlus,可以实现批量混剪视频,一键生成视频和自动发布视频的功能. 但是经常会看到小伙伴在安装过程中遇到很多问题.所以这篇文章的目的就是告诉大家怎么使用MoneyPr ...
- 【Hadoop报错】The directory item limit is exceeded: limit=1048576 items=1048576
问题描述: 调度系统执行hive任务失败,一直执行失败,报错如下: java.io.IOException: java.net.ConnectException: Call From #HostNam ...
- Qt中全局变量的定义和使用
全局变量的定义 现在需要将自定义的STRParameter变量定义为全局变量,就需要新建两个文件,分别命名为"global.h"和"global.cpp" 在g ...
- manage.py“Couldn't import Django”报错的问题解决
问题分析: 在pyharm中项目可以正常运行但是在终端 终端输入python manage.py runserver首次测试项目时,出现了无法引用Django的错误. Traceback (most ...
- 1. 简述一下你对 HTML 语义化的理解?
用正确的标签做正确的事情.1.HTML 语义化让页面的内容结构化,结构更清晰,便于对浏览器.搜索引擎解析; 2.即使在没有样式 CSS 的情况下也能以一种文档格式显示,并且是容易阅读的; 3.搜索引擎 ...