【转载】 TensorFlow - 框架实现中的三种 Graph图结构
原文地址:
https://zhuanlan.zhihu.com/p/31308381
-------------------------------------------------------------------------------------
图(graph)是 tensorflow 用于表达计算任务的一个核心概念。从前端(python)描述神经网络的结构,到后端在多机和分布式系统上部署,到底层 Device(CPU、GPU、TPU)上运行,都是基于图来完成。然而我在实际使用过程中遇到了三对API,
- tf.train.Saver() / saver.restore()
- tf.train.export_meta_graph / tf.train.Import_meta_graph
- tf.train.write_graph() / tf.Import_graph_def()
他们都是用于对图的保存和恢复。同一个计算框架,为什么需要三对不同的API呢?他们保存/恢复的图在使用时又有什么区别呢?初学的时候,常常闹不清楚他们的区别,以至常常写出了错误的程序,经过一番研究,在本文中对Tensorflow中围绕Graph的核心概念进行了总结。
Graph
首先介绍一下关于 Tensorflow 中 Graph 和它的序列化表示 Graph_def。在Tensorflow的官方文档中,Graph 被定义为“一些 Operation 和 Tensor 的集合”。例如我们表达如下的一个计算的 python代码,
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
c = tf.placeholder(tf.float32)
d = a*b+c
e = d*2
就会生成相应的一张图,在Tensorboard中看到的图大概如下这样。其中每一个圆圈表示一个Operation(输入处为Placeholder),椭圆到椭圆的边为Tensor,箭头的指向表示了这张图
Operation 输入输出 Tensor 的传递关系。
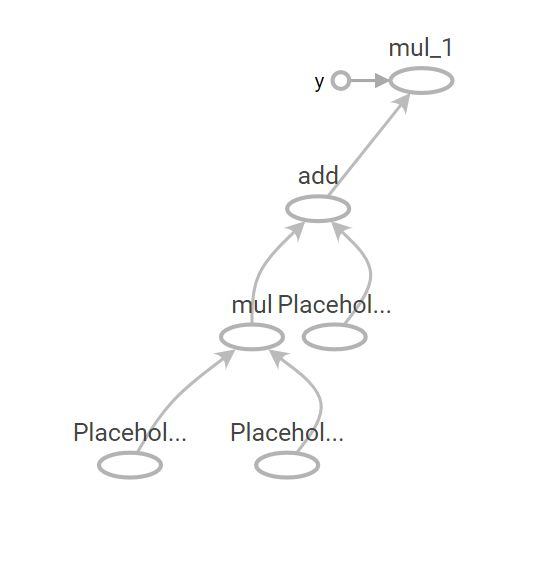
这张图所表达的数据流 与 python 代码中所表达的计算是对应的关系(为了称呼方便,我们下面将这张由Python表达式所描述的数据流动关系叫做 Python Graph)。然而在真实的 Tensorflow 运行中,Python 构建的“图”并不是启动一个Session之后始终不变的东西。因为Tensorflow在运行时,真实的计算会被下放到多CPU上,或者 GPU 等异构设备,或者ARM等上进行高性能/能效的计算。单纯使用 Python 肯定是无法有效完成的。实际上,Tensorflow而是首先将 python 代码所描绘的图转换(即“序列化”)成 Protocol Buffer,再通过 C/C++/CUDA 运行 Protocol Buffer 所定义的图。(Protocol Buffer的介绍可以参考这篇文章学习:https://www.ibm.com/developerworks/cn/linux/l-cn-gpb/)
GraphDef
从 python Graph中序列化出来的图就叫做 GraphDef(这是一种不严格的说法,先这样进行理解)。而 GraphDef 又是由许多叫做 NodeDef 的 Protocol Buffer 组成。在概念上 NodeDef 与 (Python Graph 中的)Operation 相对应。如下就是 GraphDef 的 ProtoBuf,由许多node组成的图表示。这是与上文 Python 图对应的 GraphDef:
node {
name: "Placeholder" # 注释:这是一个叫做 "Placeholder" 的node
op: "Placeholder"
attr {
key: "dtype"
value {
type: DT_FLOAT
}
}
attr {
key: "shape"
value {
shape {
unknown_rank: true
}
}
}
}
node {
name: "Placeholder_1" # 注释:这是一个叫做 "Placeholder_1" 的node
op: "Placeholder"
attr {
key: "dtype"
value {
type: DT_FLOAT
}
}
attr {
key: "shape"
value {
shape {
unknown_rank: true
}
}
}
}
node {
name: "mul" # 注释:一个 Mul(乘法)操作
op: "Mul"
input: "Placeholder" # 使用上面的node(即Placeholder和Placeholder_1)
input: "Placeholder_1" # 作为这个Node的输入
attr {
key: "T"
value {
type: DT_FLOAT
}
}
}以上三个 NodeDef 定义了两个Placeholder和一个Multiply。Placeholder 通过 attr(attribute的缩写)来定义数据类型和 Tensor 的形状。Multiply通过 input 属性定义了两个placeholder作为其输入。无论是 Placeholder 还是 Multiply 都没有关于输出(output)的信息。其实 Tensorflow 中都是通过 Input 来定义 Node 之间的连接信息。
那么既然 tf.Operation 的序列化 ProtoBuf 是 NodeDef,那么 tf.Variable 呢?在这个 GraphDef 中只有网络的连接信息,却没有任何 Variables呀?没错,Graphdef
中不保存任何 Variable 的信息,所以如果我们从 graph_def 来构建图并恢复训练的话,是不能成功的。比如以下代码,
with tf.Graph().as_default() as graph:
tf.import_graph_def("graph_def_path")
saver= tf.train.Saver()
with tf.Session() as sess:
tf.trainable_variables()
其中 tf.trainable_variables() 只会返回一个空的list。Tf.train.Saver() 也会报告 no variables to save。
然而,在实际线上 inference 中,通常就是使用 GraphDef。然而,GraphDef中连Variable都没有,怎么存储weight呢?原来GraphDef 虽然不能保存 Variable,但可以保存 Constant 。通过 tf.constant 将 weight 直接存储在 NodeDef 里,tensorflow 1.3.0 版本也提供了一套叫做 freeze_graph 的工具来自动的将图中的 Variable 替换成 constant 存储在 GraphDef 里面,并将该图导出为 Proto。可以查看以下链接获取更多信息,
tensorflow.org/extend/tool_developers/
https://www.tensorflow.org/mobile/prepare_models
tf.train.write_graph() 与 tf.Import_graph_def() 就是用来进行 GraphDef 读写的API。那么,我们怎么才能从序列化的图中,得到 Variables呢?这就要学习下一个重要概念,MetaGraph。
MetaGraph
Meta graph 的官方解释是:一个Meta Graph 由一个计算图和其相关的元数据构成。其包含了用于继续训练,实施评估和(在已训练好的的图上)做前向推断的信息。(A MetaGraph consists of both a computational graph and its associated metadata. A MetaGraph contains the information required to continue training, perform evaluation, or run inference on a previously trained graph. From <https://www.tensorflow.org/versions/r1.1/programmers_guide/> )
这一段看的云里雾里,不过这篇文章(https://www.tensorflow.org/versions/r1.1/programmers_guide/meta_graph)进一步解释说,Meta Graph在具体实现上就是一个 MetaGraphDef (同样是由 Protocol Buffer来定义的)。其包含了四种主要的信息,根据Tensorflow官网,这四种 Protobuf 分别是
- MetaInfoDef,存一些元信息(比如版本和其他用户信息)
- GraphDef, MetaGraph的核心内容之一,我们刚刚介绍过
- SaverDef,图的Saver信息(比如最多同时保存的check-point数量,需保存的Tensor名字等,但并不保存Tensor中的实际内容)
- CollectionDef 任何需要特殊注意的 Python 对象,需要特殊的标注以方便import_meta_graph 后取回。(比如“train_op”,"prediction"
等等)
在以上四种 ProtoBuf 里面,1 和 3 都比较容易理解,2 刚刚总结过。这里特别要讲一下 Collection(CollectionDef是对应的ProtoBuf)。
Tensorflow中并没有一个官方的定义说 collection 是什么。简单的理解,它就是为了方便用户对图中的操作和变量进行管理,而创建的一个概念。它可以说是一种“集合”,通过一个 key(string类型)来对一组 Python 对象进行命名的集合。这个key既可以是tensorflow在内部定义的一些key,也可以是用户自己定义的名字(string)。
Tensorflow 内部定义了许多标准 Key,全部定义在了 tf.GraphKeys 这个类中。其中有一些常用的,tf.GraphKeys.TRAINABLE_VARIABLES, tf.GraphKeys.GLOBAL_VARIABLES 等等。tf.trainable_variables() 与 tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES) 是等价的;tf.global_variables() 与 tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES) 是等价的。
对于用户定义的 key,我们举一个例子。例如:
pred = model_network(X)
loss=tf.reduce_mean(…, pred, …)
train_op=tf.train.AdamOptimizer(lr).minimize(loss)
这样一段 Tensorflow程序,用户希望特别关注 pred, loss, train_op 这几个操作,那么就可以使用如下代码,将这几个变量加入到 collection 中去。(假设我们将其命名为 “training_collection”)
tf.add_to_collection("training_collection", pred)
tf.add_to_collection("training_collection", loss)
tf.add_to_collection("training_collection", train_op)
并且可以通过 Train_collect = tf.get_collection(“training_collection”) 得到一个python list,其中的内容就是 pred, loss, train_op的 Tensor。这通常是为了在一个新的 session 中打开这张图时,方便我们获取想要的操作。比如我们可以直接工通过get_collection() 得到 train_op,然后通过 sess.run(train_op)来开启一段训练,而无需重新构建 loss 和optimizer。
通过export_meta_graph保存图,并且通过 add_to_collection 将 train_op 加入到 collection中:
with tf.Session() as sess:
pred = model_network(X)
loss=tf.reduce_mean(…,pred, …)
train_op=tf.train.AdamOptimizer(lr).minimize(loss)
tf.add_to_collection("training_collection", train_op)
Meta_graph_def =
tf.train.export_meta_graph(tf.get_default_graph(), 'my_graph.meta')
通过 import_meta_graph将图恢复(同时初始化为本 Session的 default 图),并且通过 get_collection 重新获得 train_op,以及通过 train_op 来开始一段训练( sess.run() )。
with tf.Session() as new_sess:
tf.train.import_meta_graph('my_graph.meta')
train_op = tf.get_collection("training_collection")[0]
new_sess.run(train_op)
更多的代码例子可以在这篇文档(https://www.tensorflow.org/api_guides/python/meta_graph)中的 Import a MetaGraph 章节中看到。
那么,从 Meta Graph 中恢复构建的图可以被训练吗?是可以的。Tensorflow的官方文档 https://www.tensorflow.org/api_guides/python/meta_graph 说明了使用方法。这里要特殊的说明一下,Meta Graph中虽然包含Variable的信息,却没有 Variable 的实际值。所以从Meta Graph中恢复的图,其训练是从随机初始化的值开始的。训练中Variable的实际值都保存在check-point中,如果要从之前训练的状态继续恢复训练,就要从check-point中restore。进一步读一下Export Meta Graph的代码,可以看到,事实上variables并没有被export到meta_graph 中
github.com/tensorflow/tensorflow/blob/r1.4/tensorflow/python/training/saver.py (1872行)
github.com/tensorflow/tensorflow/blob/r1.4/tensorflow/python/framework/meta_graph.py (829,845行)

export_meta_graph/Import_meta_graph 就是用来进行 Meta Graph 读写的API。
tf.train.saver.save() 在保存check-point的同时也会保存Meta Graph。但是在恢复图时,tf.train.saver.restore() 只恢复 Variable,如果要从MetaGraph恢复图,需要使用 import_meta_graph。这是其实为了方便用户,有时我们不需要从MetaGraph恢复的图,而是需要在 python 中构建神经网络图,并恢复对应的 Variable。
Check-point
Check-point 里全面保存了训练某时间截面的信息,包括参数,超参数,梯度等等。tf.train.Saver()/saver.restore() 则能够完完整整保存和恢复神经网络的训练。Check-point分为两个文件保存Variable的二进制信息。ckpt文件保存了Variable的二进制信息,index
文件用于保存 ckpt 文件中对应 Variable 的偏移量信息。
总结
Tensorflow 三种 API 所保存和恢复的图是不一样的。这三种图是从Tensorflow框架设计的角度出发而定义的。但是从用户的角度来看,TF文档的写作难免有些云里雾里,弄不清他们的区别。需要读一读Tensorflow的代码,做一些实验来对他们进行辨析。
简而言之,Tensorflow 在前端 Python 中构建图,并且通过将该图序列化到 ProtoBuf GraphDef,以方便在后端运行。在这个过程中,图的保存、恢复和运行都通过 ProtoBuf 来实现。GraphDef,MetaGraph,以及Variable,Collection 和 Saver 等都有对应的 ProtoBuf 定义。ProtoBuf 的定义也决定了用户能对图进行的操作。例如用户只能找到Node的前一个Node,却无法得知自己的输出会由哪个Node接收。
【转载】 TensorFlow - 框架实现中的三种 Graph图结构的更多相关文章
- TensorFlow - 框架实现中的三种 Graph
文章目录 TensorFlow - 框架实现中的三种 Graph 1. Graph 2. GraphDef 3. MetaGraph 4. Checkpoint 5. 总结 TensorFlow - ...
- Tensorflow框架实现中的“三”种图
https://zhuanlan.zhihu.com/p/31308381 图(graph)是 tensorflow 用于表达计算任务的一个核心概念.从前端(python)描述神经网络的结构,到后端在 ...
- Java三大框架之——Hibernate中的三种数据持久状态和缓存机制
Hibernate中的三种状态 瞬时状态:刚创建的对象还没有被Session持久化.缓存中不存在这个对象的数据并且数据库中没有这个对象对应的数据为瞬时状态这个时候是没有OID. 持久状态:对象经过 ...
- 【转载】C#批量插入数据到Sqlserver中的三种方式
引用:https://m.jb51.net/show/99543 这篇文章主要为大家详细介绍了C#批量插入数据到Sqlserver中的三种方式,具有一定的参考价值,感兴趣的小伙伴们可以参考一下 本篇, ...
- .net core 注入中的三种模式:Singleton、Scoped 和 Transient
从上篇内容不如题的文章<.net core 并发下的线程安全问题>扩展认识.net core注入中的三种模式:Singleton.Scoped 和 Transient 我们都知道在 Sta ...
- Asp.Net中的三种分页方式
Asp.Net中的三种分页方式 通常分页有3种方法,分别是asp.net自带的数据显示空间如GridView等自带的分页,第三方分页控件如aspnetpager,存储过程分页等. 第一种:使用Grid ...
- httpClient中的三种超时设置小结
httpClient中的三种超时设置小结 本文章给大家介绍一下关于Java中httpClient中的三种超时设置小结,希望此教程能给各位朋友带来帮助. ConnectTimeoutExceptio ...
- MySQL buffer pool中的三种链
三种page.三种list.LRU控制调优 一.innodb buffer pool中的三种页 1.free page:从未用过的页 2.clean page:干净的页,数据页的数据和磁盘一致 3.d ...
- 研究分析JS中的三种逻辑语句
JS中的三种逻辑语句:顺序.分支和循环语句. 一.顺序语句 代码规范如下:1. <script type="text/javascript"> var a = 10; ...
- JavaScript中的三种弹出对话框
学习过js的小伙伴会发现,我们在一些实例中用到了alert()方法.prompt()方法.prompt()方法,他们都是在屏幕上弹出一个对话框,并且在上面显示括号内的内容,使用这种方法使得页面的交互性 ...
随机推荐
- 副本集replicaSet
mongodb高可用架构 https://www.mongodb.com/docs/manual/tutorial/deploy-replica-set/ 复制是跨多个服务器同步数据的过程. 复制提供 ...
- 从零开始写 Docker(十八)---容器网络实现(下):为容器插上”网线“
本文为从零开始写 Docker 系列第十八篇,利用 linux 下的 Veth.Bridge.iptables 等等相关技术,构建容器网络模型,为容器插上"网线". 完整代码见:h ...
- 百度地图API 循环添加信息窗口问题
百度地图API循环添加信息窗口,会出现所有消息只显示在第一个窗口的位置的问题.并且信息内容相同 解决方法1 转载自 https://blog.csdn.net/zz_mm/article/detail ...
- Flink状态(二)
Flink提供了不同的状态存储方式,并说明了状态如何存和存储在哪里. 状态可以被存储在Jvm的堆和堆外.根据状态存储方式的不同,Flink也能代替应用管理状态,意思是Flink能够进行内存管理(有必要 ...
- 关于docker-compose up -d 出现超时情况处理
由于要搭建一个ctf平台,用docker一键搭建是出现超时情况 用了很多办法,换源,等之类的一样没办法,似乎它就是只能用官方那个一样很怪. 只能用一种笨办法来处理了,一个个pull. 打个比如: 打开 ...
- 逆向通达信 x 逆向微信 x 逆向Qt
本篇在博客园地址https://www.cnblogs.com/bbqzsl/p/18252961 本篇内容包括: win32窗口嵌入Qt UI.反斗玩转signal-slot.最后 通达信 x 微信 ...
- 什么是Selenium Grid?如何搭建Selenium Grid?
标签(空格分隔): 测试架构 什么是测试基础架构? 测试基础架构指的是,执行测试的过程中用到的所有基础硬件设施以及相关的软件设施.因此,我们也把测试基础架构称之为广义的测试执行环境.通常来讲,测试基础 ...
- AOP面向切面编程@Aspect 注解用法
AOP简介 AOP为Aspect Oriented Programming 的缩写,意为"面向切面编程",通过预编译方式和运行预期动态代理实现程序功能的统一维护的一种技术.AOP是 ...
- SpringBoot 处理xss攻击
添加依赖 <!-- xss跨站脚本攻击 --> <dependency> <groupId>net.dreamlu</groupId> <arti ...
- 机器学习策略篇:详解数据分布不匹配时,偏差与方差的分析(Bias and Variance with mismatched data distributions)
详解数据分布不匹配时,偏差与方差的分析 估计学习算法的偏差和方差真的可以帮确定接下来应该优先做的方向,但是,当训练集来自和开发集.测试集不同分布时,分析偏差和方差的方式可能不一样,来看为什么. 继续用 ...