baselines算法库logger.py模块分析
baselines根目录下logger.py模块代码:


import os
import sys
import shutil
import os.path as osp
import json
import time
import datetime
import tempfile
from collections import defaultdict
from contextlib import contextmanager DEBUG = 10
INFO = 20
WARN = 30
ERROR = 40 DISABLED = 50 class KVWriter(object):
def writekvs(self, kvs):
raise NotImplementedError class SeqWriter(object):
def writeseq(self, seq):
raise NotImplementedError class HumanOutputFormat(KVWriter, SeqWriter):
def __init__(self, filename_or_file):
if isinstance(filename_or_file, str):
self.file = open(filename_or_file, 'wt')
self.own_file = True
else:
assert hasattr(filename_or_file, 'read'), 'expected file or str, got %s'%filename_or_file
self.file = filename_or_file
self.own_file = False def writekvs(self, kvs):
# Create strings for printing
key2str = {}
for (key, val) in sorted(kvs.items()):
if hasattr(val, '__float__'):
valstr = '%-8.3g' % val
else:
valstr = str(val)
key2str[self._truncate(key)] = self._truncate(valstr) # Find max widths
if len(key2str) == 0:
print('WARNING: tried to write empty key-value dict')
return
else:
keywidth = max(map(len, key2str.keys()))
valwidth = max(map(len, key2str.values())) # Write out the data
dashes = '-' * (keywidth + valwidth + 7)
lines = [dashes]
for (key, val) in sorted(key2str.items(), key=lambda kv: kv[0].lower()):
lines.append('| %s%s | %s%s |' % (
key,
' ' * (keywidth - len(key)),
val,
' ' * (valwidth - len(val)),
))
lines.append(dashes)
self.file.write('\n'.join(lines) + '\n') # Flush the output to the file
self.file.flush() def _truncate(self, s):
maxlen = 30
return s[:maxlen-3] + '...' if len(s) > maxlen else s def writeseq(self, seq):
seq = list(seq)
for (i, elem) in enumerate(seq):
self.file.write(elem)
if i < len(seq) - 1: # add space unless this is the last one
self.file.write(' ')
self.file.write('\n')
self.file.flush() def close(self):
if self.own_file:
self.file.close() class JSONOutputFormat(KVWriter):
def __init__(self, filename):
self.file = open(filename, 'wt') def writekvs(self, kvs):
for k, v in sorted(kvs.items()):
if hasattr(v, 'dtype'):
kvs[k] = float(v)
self.file.write(json.dumps(kvs) + '\n')
self.file.flush() def close(self):
self.file.close() class CSVOutputFormat(KVWriter):
def __init__(self, filename):
self.file = open(filename, 'w+t')
self.keys = []
self.sep = ',' def writekvs(self, kvs):
# Add our current row to the history
extra_keys = list(kvs.keys() - self.keys)
extra_keys.sort()
if extra_keys:
self.keys.extend(extra_keys)
self.file.seek(0)
lines = self.file.readlines()
self.file.seek(0)
for (i, k) in enumerate(self.keys):
if i > 0:
self.file.write(',')
self.file.write(k)
self.file.write('\n')
for line in lines[1:]:
self.file.write(line[:-1])
self.file.write(self.sep * len(extra_keys))
self.file.write('\n')
for (i, k) in enumerate(self.keys):
if i > 0:
self.file.write(',')
v = kvs.get(k)
if v is not None:
self.file.write(str(v))
self.file.write('\n')
self.file.flush() def close(self):
self.file.close() class TensorBoardOutputFormat(KVWriter):
"""
Dumps key/value pairs into TensorBoard's numeric format.
"""
def __init__(self, dir):
os.makedirs(dir, exist_ok=True)
self.dir = dir
self.step = 1
prefix = 'events'
path = osp.join(osp.abspath(dir), prefix)
import tensorflow as tf
from tensorflow.python import pywrap_tensorflow
from tensorflow.core.util import event_pb2
from tensorflow.python.util import compat
self.tf = tf
self.event_pb2 = event_pb2
self.pywrap_tensorflow = pywrap_tensorflow
self.writer = pywrap_tensorflow.EventsWriter(compat.as_bytes(path)) def writekvs(self, kvs):
def summary_val(k, v):
kwargs = {'tag': k, 'simple_value': float(v)}
return self.tf.Summary.Value(**kwargs)
summary = self.tf.Summary(value=[summary_val(k, v) for k, v in kvs.items()])
event = self.event_pb2.Event(wall_time=time.time(), summary=summary)
event.step = self.step # is there any reason why you'd want to specify the step?
self.writer.WriteEvent(event)
self.writer.Flush()
self.step += 1 def close(self):
if self.writer:
self.writer.Close()
self.writer = None def make_output_format(format, ev_dir, log_suffix=''):
os.makedirs(ev_dir, exist_ok=True)
if format == 'stdout':
return HumanOutputFormat(sys.stdout)
elif format == 'log':
return HumanOutputFormat(osp.join(ev_dir, 'log%s.txt' % log_suffix))
elif format == 'json':
return JSONOutputFormat(osp.join(ev_dir, 'progress%s.json' % log_suffix))
elif format == 'csv':
return CSVOutputFormat(osp.join(ev_dir, 'progress%s.csv' % log_suffix))
elif format == 'tensorboard':
return TensorBoardOutputFormat(osp.join(ev_dir, 'tb%s' % log_suffix))
else:
raise ValueError('Unknown format specified: %s' % (format,)) # ================================================================
# API
# ================================================================ def logkv(key, val):
"""
Log a value of some diagnostic
Call this once for each diagnostic quantity, each iteration
If called many times, last value will be used.
"""
get_current().logkv(key, val) def logkv_mean(key, val):
"""
The same as logkv(), but if called many times, values averaged.
"""
get_current().logkv_mean(key, val) def logkvs(d):
"""
Log a dictionary of key-value pairs
"""
for (k, v) in d.items():
logkv(k, v) def dumpkvs():
"""
Write all of the diagnostics from the current iteration
"""
return get_current().dumpkvs() def getkvs():
return get_current().name2val def log(*args, level=INFO):
"""
Write the sequence of args, with no separators, to the console and output files (if you've configured an output file).
"""
get_current().log(*args, level=level) def debug(*args):
log(*args, level=DEBUG) def info(*args):
log(*args, level=INFO) def warn(*args):
log(*args, level=WARN) def error(*args):
log(*args, level=ERROR) def set_level(level):
"""
Set logging threshold on current logger.
"""
get_current().set_level(level) def set_comm(comm):
get_current().set_comm(comm) def get_dir():
"""
Get directory that log files are being written to.
will be None if there is no output directory (i.e., if you didn't call start)
"""
return get_current().get_dir() record_tabular = logkv
dump_tabular = dumpkvs @contextmanager
def profile_kv(scopename):
logkey = 'wait_' + scopename
tstart = time.time()
try:
yield
finally:
get_current().name2val[logkey] += time.time() - tstart def profile(n):
"""
Usage:
@profile("my_func")
def my_func(): code
"""
def decorator_with_name(func):
def func_wrapper(*args, **kwargs):
with profile_kv(n):
return func(*args, **kwargs)
return func_wrapper
return decorator_with_name # ================================================================
# Backend
# ================================================================ def get_current():
if Logger.CURRENT is None:
_configure_default_logger() return Logger.CURRENT class Logger(object):
DEFAULT = None # A logger with no output files. (See right below class definition)
# So that you can still log to the terminal without setting up any output files
CURRENT = None # Current logger being used by the free functions above def __init__(self, dir, output_formats, comm=None):
self.name2val = defaultdict(float) # values this iteration
self.name2cnt = defaultdict(int)
self.level = INFO
self.dir = dir
self.output_formats = output_formats
self.comm = comm # Logging API, forwarded
# ----------------------------------------
def logkv(self, key, val):
self.name2val[key] = val def logkv_mean(self, key, val):
oldval, cnt = self.name2val[key], self.name2cnt[key]
self.name2val[key] = oldval*cnt/(cnt+1) + val/(cnt+1)
self.name2cnt[key] = cnt + 1 def dumpkvs(self):
if self.comm is None:
d = self.name2val
else:
from baselines.common import mpi_util
d = mpi_util.mpi_weighted_mean(self.comm,
{name : (val, self.name2cnt.get(name, 1))
for (name, val) in self.name2val.items()})
if self.comm.rank != 0:
d['dummy'] = 1 # so we don't get a warning about empty dict
out = d.copy() # Return the dict for unit testing purposes
for fmt in self.output_formats:
if isinstance(fmt, KVWriter):
fmt.writekvs(d)
self.name2val.clear()
self.name2cnt.clear()
return out def log(self, *args, level=INFO):
if self.level <= level:
self._do_log(args) # Configuration
# ----------------------------------------
def set_level(self, level):
self.level = level def set_comm(self, comm):
self.comm = comm def get_dir(self):
return self.dir def close(self):
for fmt in self.output_formats:
fmt.close() # Misc
# ----------------------------------------
def _do_log(self, args):
for fmt in self.output_formats:
if isinstance(fmt, SeqWriter):
fmt.writeseq(map(str, args)) def get_rank_without_mpi_import():
# check environment variables here instead of importing mpi4py
# to avoid calling MPI_Init() when this module is imported
for varname in ['PMI_RANK', 'OMPI_COMM_WORLD_RANK']:
if varname in os.environ:
return int(os.environ[varname])
return 0 def configure(dir=None, format_strs=None, comm=None, log_suffix=''):
"""
If comm is provided, average all numerical stats across that comm
"""
if dir is None:
dir = os.getenv('OPENAI_LOGDIR')
if dir is None:
dir = osp.join(tempfile.gettempdir(),
datetime.datetime.now().strftime("openai-%Y-%m-%d-%H-%M-%S-%f"))
assert isinstance(dir, str)
dir = os.path.expanduser(dir)
os.makedirs(os.path.expanduser(dir), exist_ok=True) rank = get_rank_without_mpi_import()
if rank > 0:
log_suffix = log_suffix + "-rank%03i" % rank if format_strs is None:
if rank == 0:
format_strs = os.getenv('OPENAI_LOG_FORMAT', 'stdout,log,csv').split(',')
else:
format_strs = os.getenv('OPENAI_LOG_FORMAT_MPI', 'log').split(',')
format_strs = filter(None, format_strs)
output_formats = [make_output_format(f, dir, log_suffix) for f in format_strs] Logger.CURRENT = Logger(dir=dir, output_formats=output_formats, comm=comm)
if output_formats:
log('Logging to %s'%dir) def _configure_default_logger():
configure()
Logger.DEFAULT = Logger.CURRENT def reset():
if Logger.CURRENT is not Logger.DEFAULT:
Logger.CURRENT.close()
Logger.CURRENT = Logger.DEFAULT
log('Reset logger') @contextmanager
def scoped_configure(dir=None, format_strs=None, comm=None):
prevlogger = Logger.CURRENT
configure(dir=dir, format_strs=format_strs, comm=comm)
try:
yield
finally:
Logger.CURRENT.close()
Logger.CURRENT = prevlogger # ================================================================ def _demo():
info("hi")
debug("shouldn't appear")
set_level(DEBUG)
debug("should appear")
dir = "/tmp/testlogging"
if os.path.exists(dir):
shutil.rmtree(dir)
configure(dir=dir)
logkv("a", 3)
logkv("b", 2.5)
dumpkvs()
logkv("b", -2.5)
logkv("a", 5.5)
dumpkvs()
info("^^^ should see a = 5.5")
logkv_mean("b", -22.5)
logkv_mean("b", -44.4)
logkv("a", 5.5)
dumpkvs()
info("^^^ should see b = -33.3") logkv("b", -2.5)
dumpkvs() logkv("a", "longasslongasslongasslongasslongasslongassvalue")
dumpkvs() # ================================================================
# Readers
# ================================================================ def read_json(fname):
import pandas
ds = []
with open(fname, 'rt') as fh:
for line in fh:
ds.append(json.loads(line))
return pandas.DataFrame(ds) def read_csv(fname):
import pandas
return pandas.read_csv(fname, index_col=None, comment='#') def read_tb(path):
"""
path : a tensorboard file OR a directory, where we will find all TB files
of the form events.*
"""
import pandas
import numpy as np
from glob import glob
import tensorflow as tf
if osp.isdir(path):
fnames = glob(osp.join(path, "events.*"))
elif osp.basename(path).startswith("events."):
fnames = [path]
else:
raise NotImplementedError("Expected tensorboard file or directory containing them. Got %s"%path)
tag2pairs = defaultdict(list)
maxstep = 0
for fname in fnames:
for summary in tf.train.summary_iterator(fname):
if summary.step > 0:
for v in summary.summary.value:
pair = (summary.step, v.simple_value)
tag2pairs[v.tag].append(pair)
maxstep = max(summary.step, maxstep)
data = np.empty((maxstep, len(tag2pairs)))
data[:] = np.nan
tags = sorted(tag2pairs.keys())
for (colidx,tag) in enumerate(tags):
pairs = tag2pairs[tag]
for (step, value) in pairs:
data[step-1, colidx] = value
return pandas.DataFrame(data, columns=tags) if __name__ == "__main__":
_demo()
这个模块代码较多,逻辑比较复杂,其实实现的功能还是比较简单的,就是把python中的字典类型数据格式化后打印到屏幕和文件中。
由于这个模块写了主函数:
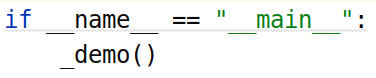
所以可以直接以模块化的方式进行运行:
python -m baselines.logger
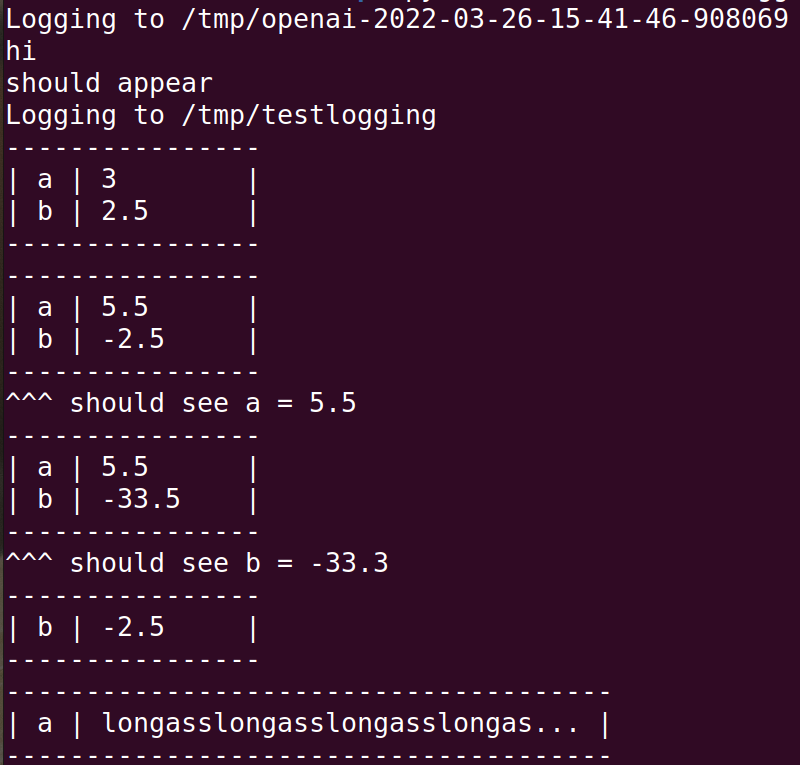
可以在/tmp路径下面看到保存的字典数据:



这个日志模块感觉设计的过于复杂而且使用性较差,属于自己造轮子的做法,意义价值不到,不细分析了。
==============================================
baselines算法库logger.py模块分析的更多相关文章
- 爆料喽!!!开源日志库Logger的剖析分析
导读 Logger类提供了多种方法来处理日志活动.上一篇介绍了开源日志库Logger的使用,今天我主要来分析Logger实现的原理. 库的整体架构图 详细剖析 我们从使用的角度来对Logger库抽茧剥 ...
- mahout算法库(四)
mahout算法库 分为三大块 1.聚类算法 2.协同过滤算法(一般用于推荐) 协同过滤算法也可以称为推荐算法!!! 3.分类算法 算法类 算法名 中文名 分类算法 Log ...
- OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波
http://blog.csdn.net/chenyusiyuan/article/details/8710462 OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波 201 ...
- 【Python】【Web.py】详细解读Python的web.py框架下的application.py模块
详细解读Python的web.py框架下的application.py模块 这篇文章主要介绍了Python的web.py框架下的application.py模块,作者深入分析了web.py的源码, ...
- scikit-learn 支持向量机算法库使用小结
之前通过一个系列对支持向量机(以下简称SVM)算法的原理做了一个总结,本文从实践的角度对scikit-learn SVM算法库的使用做一个小结.scikit-learn SVM算法库封装了libsvm ...
- OpenRisc-43-or1200的IF模块分析
引言 “喂饱饥饿的CPU”,是计算机体系结构设计者时刻要考虑的问题.要解决这个问题,方法大体可分为两部分,第一就是利用principle of locality而引进的cache技术,缩短取指时间,第 ...
- 【转】python模块分析之unittest测试(五)
[转]python模块分析之unittest测试(五) 系列文章 python模块分析之random(一) python模块分析之hashlib加密(二) python模块分析之typing(三) p ...
- 【转】python模块分析之hashlib加密(二)
[转]python模块分析之hashlib加密(二) hashlib模块是用来对字符串进行hash加密的模块,明文与密文是一一对应不变的关系:用于注册.登录时用户名.密码等加密使用.一.函数分析:1. ...
- 【转】python之random模块分析(一)
[转]python之random模块分析(一) random是python产生伪随机数的模块,随机种子默认为系统时钟.下面分析模块中的方法: 1.random.randint(start,stop): ...
- 【转】python模块分析之logging日志(四)
[转]python模块分析之logging日志(四) python的logging模块是用来写日志的,是python的标准模块. 系列文章 python模块分析之random(一) python模块分 ...
随机推荐
- http请求方式-CloseableHttpClient
http请求方式-CloseableHttpClient import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObjec ...
- Python使用.NET开发的类库来提高你的程序执行效率
Python由于本身的特性原因,执行程序期间可能效率并不是很理想.在某些需要自己提高一些代码的执行效率的时候,可以考虑使用C#.C++.Rust等语言开发的库来提高python本身的执行效率.接下来, ...
- Maven配置阿里云镜像和本地仓库路径
配置阿里云镜像仓库 在settings > mirrors标签下添加以下内容 <!-- Aliyun Mirror --> <mirror> <id>alim ...
- nginx中多个server块共用upstream会相互影响吗
背景 nginx中经常有这样的场景,多个server块共用一个域名. 如:upstream有2个以上的域名,nginx配置两个server块,共用一个upstream配置. 那么,如果其中一个域名发生 ...
- Nuxt3 的生命周期和钩子函数(二)
title: Nuxt3 的生命周期和钩子函数(二) date: 2024/6/26 updated: 2024/6/26 author: cmdragon excerpt: 摘要:本文深入介绍了Nu ...
- Hbase第二课:Hbase架构与基础命令
目录 HBase架构与基础命令 一.了解HBase 1.1 HBase概述 1.2 HBase处理数据 1.3 HBase与HDFS 二.HBase相关概念 2.1 分布式数据库 2.2 列式存储 2 ...
- 【论文阅读】BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal
论文题目:BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal ...
- nodejs-mime类型
mime是一个互联网标准,通过设定它就可以设定文件在浏览器的打开方式. mime使用方法: 使用mime模块查询文件的MIME类型: mime.getType('/path/to/file.txt') ...
- springboot 整合 pagehelper
pom.xml <dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pa ...
- 【算法】用c#实现自定义字符串编码及围栏解码方法
编写一个函数/方法,它接受2个参数.一个字符串和轨道数,并返回ENCODED字符串. 编写第二个函数/方法,它接受2个参数.一个编码字符串和轨道数,并返回DECODED字符串. 然后使用围栏密码对其进 ...