【python爬虫案例】用python爬豆瓣电影TOP250排行榜!
一、爬虫对象-豆瓣电影TOP250
前几天,我分享了一个python爬虫案例,爬取豆瓣读书TOP250数据:【python爬虫案例】用python爬豆瓣读书TOP250排行榜!
今天,我再分享一期,python爬取豆瓣电影TOP250数据!
爬虫大体流程和豆瓣读书TOP250类似,细节之处见逻辑。
首先,打开豆瓣电影TOP250的页面:https://movie.douban.com/top250
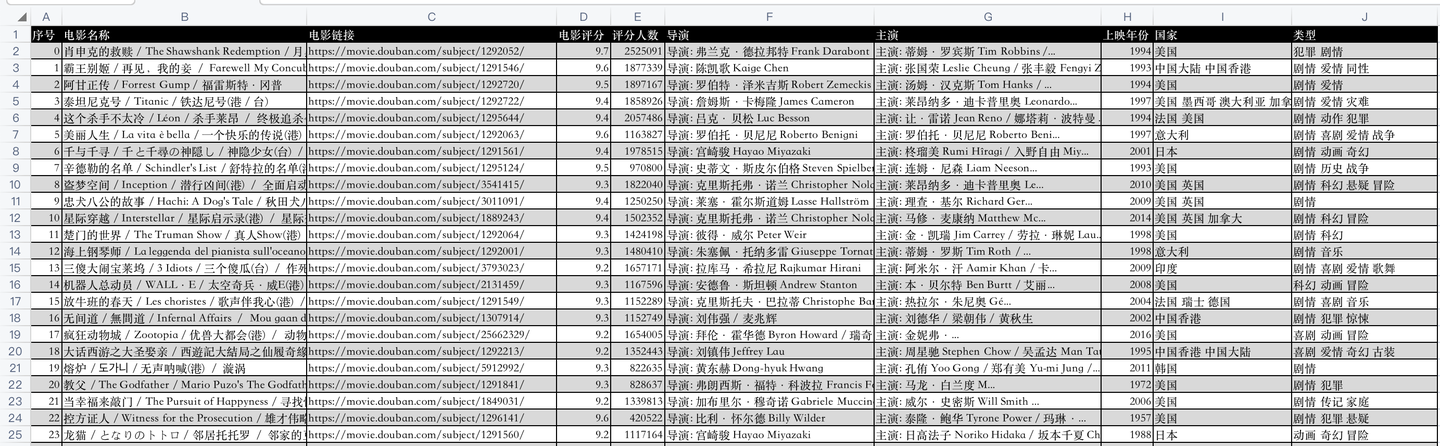
开发好python爬虫代码后,爬取成功后的csv数据,如下:
代码是怎样实现的爬取呢?下面逐一讲解python核心代码。
二、python爬虫代码讲解
首先,导入需要用到的库:
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间
然后,向豆瓣电影网页发送请求:
res = requests.get(url, headers=headers)
利用BeautifulSoup库解析响应页面:
soup = BeautifulSoup(res.text, 'html.parser')
用BeautifulSoup的select函数,(css解析的方法)编写代码逻辑,部分核心代码:
for movie in soup.select('.item'):
name = movie.select('.hd a')[0].text.replace('\n', '') # 电影名称
movie_name.append(name)
url = movie.select('.hd a')[0]['href'] # 电影链接
movie_url.append(url)
star = movie.select('.rating_num')[0].text # 电影评分
movie_star.append(star)
star_people = movie.select('.star span')[3].text # 评分人数
star_people = star_people.strip().replace('人评价', '')
movie_star_people.append(star_people)
其中,需要说明的是,《大闹天宫》这部电影和其他电影页面排版不同:

它的上映年份有3个(其他电影只有1个上映年份),并且以"/"分隔,正好和国家、电影类型的分割线冲突,
所以,这里特殊处理一下:
if name == '大闹天宫 / 大闹天宫 上下集 / The Monkey King': # 大闹天宫,特殊处理
year0 = movie_infos.split('\n')[1].split('/')[0].strip()
year1 = movie_infos.split('\n')[1].split('/')[1].strip()
year2 = movie_infos.split('\n')[1].split('/')[2].strip()
year = year0 + '/' + year1 + '/' + year2
movie_year.append(year)
country = movie_infos.split('\n')[1].split('/')[3].strip()
movie_country.append(country)
type = movie_infos.split('\n')[1].split('/')[4].strip()
movie_type.append(type)
最后,将爬取到的数据保存到csv文件中:
def save_to_csv(csv_name):
"""
数据保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['电影名称'] = movie_name
df['电影链接'] = movie_url
df['电影评分'] = movie_star
df['评分人数'] = movie_star_people
df['导演'] = movie_director
df['主演'] = movie_actor
df['上映年份'] = movie_year
df['国家'] = movie_country
df['类型'] = movie_type
df.to_csv(csv_name, encoding='utf_8_sig') # 将数据保存到csv文件
其中,把各个list赋值为DataFrame的各个列,就把list数据转换为了DataFrame数据,然后直接to_csv保存。
这样,爬取的数据就持久化保存下来了。
三、同步视频
同步讲解视频:【python爬虫】利用python爬虫爬取豆瓣电影TOP250的数据!
四、获取完整源码
附完整源码:【python爬虫案例】利用python爬虫爬取豆瓣电影TOP250的数据!
我是 @马哥python说 ,持续分享python源码干货中!
【python爬虫案例】用python爬豆瓣电影TOP250排行榜!的更多相关文章
- Python 爬取豆瓣电影Top250排行榜,爬虫初试
from bs4 import BeautifulSoup import openpyxl import re import urllib.request import urllib.error # ...
- python爬虫1——获取网站源代码(豆瓣图书top250信息)
# -*- coding: utf-8 -*- import requests import re import sys reload(sys) sys.setdefaultencoding('utf ...
- Scrapy爬豆瓣电影Top250并存入MySQL数据库
d:进入D盘 scrapy startproject douban创建豆瓣项目 cd douban进入项目 scrapy genspider douban_spider movie.douban.co ...
- [151116 记录] 使用Python3.5爬取豆瓣电影Top250
这一段时间,一直在折腾Python爬虫.已有的文件记录显示,折腾爬虫大概个把月了吧.但是断断续续,一会儿鼓捣python.一会学习sql儿.一会调试OpenCV,结果什么都没学好.前几天,终于耐下心来 ...
- 练习:一只豆瓣电影TOP250的爬虫
练习:一只豆瓣电影TOP250爬虫 练习:一只豆瓣电影TOP250爬虫 ①创建project ②编辑items.py import scrapyclass DoubanmovieItem(scrapy ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- 【Python爬虫】:使用高性能异步多进程爬虫获取豆瓣电影Top250
在本篇博文当中,将会教会大家如何使用高性能爬虫,快速爬取并解析页面当中的信息.一般情况下,如果我们请求网页的次数太多,每次都要发出一次请求,进行串行执行的话,那么请求将会占用我们大量的时间,这样得不偿 ...
随机推荐
- KingbaseES V8R6 数据库运维案例之 -- root用户securecmd连接'Permission denied'错误
案例分析: 在KingbaseES V8R6数据库在不支持ssh连接的系统环境,可以通过securecmdd服务建立主机之间的通讯,默认securecmdd服务建立用户之间的互信,通过publicke ...
- #轻重链剖分,交互#LOJ 6669 Nauuo and Binary Tree
题目 有一棵大小为\(n\)只知道根节点为1的二叉树, 可以不超过\(3*10^4\)询问两点之间距离, 最后输出除了点1以外其余点的祖先 \(n\leq 3000\) 分析 \(O(n^2)\)的时 ...
- #K-D Tree#洛谷 4357 [CQOI2016]K 远点对
题目 已知平面内 \(n\) 个点的坐标,求欧氏距离下的第 \(k\) 远点对. 分析 先将\(k\)乘2转换为第\(k\)远有序点对. 由于\(O(n^2)\)即枚举一个点再枚举另一个点会超出时限, ...
- 面试必备HashMap源码解析
Map的实现有很多种,而HashMap算是最经典的实现之一了吧,在平时的使用中,绝大部分的使用也都是HashMap,我记得刚入行那会,脑子里对Map的使用就是Map map = new HashMap ...
- 一图读懂DCI版权服务
访问华为开发者联盟官网 获取开发指导文档 华为移动服务开源仓库地址:GitHub.Gitee 关注我们,第一时间了解 HMS Core 最新技术资讯~
- 标签栏切换效果 JS
标签栏切换效果 JS 要求:class为tab-box的元素用于实现标签栏的外边框,,分别实现标签栏的标签部分和内容部分. html <div class="tab-box" ...
- 阿里开源的32B大模型到底强在哪里?
阿里巴巴最近开源了一个320亿参数的大语言模型Qwen1.5-32B,网上都说很强很强,那么它到底强在哪里呢? 更高的性价比 Qwen1.5-32B中的B是billion的意思,也就是10亿,32B就 ...
- 京东一面:如何在SpringBoot启动时执行特定代码?有哪些方式?
引言 Spring Boot 提供了许多便捷的功能和特性,使得开发者可以更加轻松地构建强大.高效的应用程序.然而,在应用程序启动时执行一些初始化操作是至关重要的,它可以确保应用程序在启动后处于预期的状 ...
- HarmonyOS 电话服务开发指导
电话服务开发概述 HarmonyOS 电话服务系统提供了一系列的 API 用于拨打电话.获取无线蜂窝网络和 SIM 卡相关信息. 应用可以通过调用 API 来获取当前注册网络名称.网络服务状态.信号强 ...
- 【资料包】HDC.Together 2023精选Codelabs指南现已上线(内有活动)
今年HDC.Together 2023的Codelabs挑战系列活动如期而至,众多开发者齐聚一堂,积极参与.本次赛题中部分Codelabs已在官网上线详细操作指南,让我们与众多coders一起探索代 ...