[转帖]《AWK程序设计语言》笔记(1)—— AWK入门与简单案例
原文为 《The AWK Programming Language》,GitHub上有中译版,不过有些内容翻译的比较奇怪,建议跟原版对照着看 https://github.com/wuzhouhui/awk
本篇的小案例基本均基于文件 emp.data,三个字段分别为:员工名、每小时工资、工作时长,每一行代表一个雇员的记录
一、 AWK入门
1. 入门小案例
打印每位雇员的名字以及他们的报酬 (每小时工资*工作时长),雇员的工作时长必须大于0。

被单引号包围的部分是一个完整的 awk 程序,一般由 模式–动作 (pattern-action) 组成,当然模式可以没有。模式 $3 > 0 扫描每一个输入行, 如果该行的第三列大于0,则执行动作,为每一个匹配行打印第一个字段以及第二与第三个字段的乘积。
想知道哪些员工在偷懒(工作时长为0)
awk '$3 == 0 { print $1 }' emp.data

2. 运行 AWK 程序
awk 程序有多种运行方式:
- 读取输入文件 awk 'program' input files。输入文件可以有多个,例如

- 读取终端输入内容 awk 'program',awk 会将 program 应用到你在终端输入的内容,直到你输入文件结束标志 (ctrl+d)
awk '$3 == 0 { print $1 }'

橙色部分为输出,其余为输入,不符合条件则无返回结果
- 将awk程序放入文件,并用-f参数指定 awk -f progfile optional list of files,注意progfile中程序不用加''

二、 AWK输出
awk 的数据只有两种类型:数值与字符串。emp.data 是很典型的待处理数据,它既有单词也包括数值,且字段之间通过制表符或空格分隔。
1. 打印每一行
{ print }或者{ print $0 },即:

2. NF,字段的数量
{ print NF, $1, $NF },打印每行字段数、第一个字段、最后一个字段。
awk ' { print NF, $1, $NF } ' emp.data

3. NR,打印行号
可以使用 NR 和 $0 为 emp.data 的每一行加上行号。
awk ' { print NR, $0 } ' emp.data

4. 列计算
可以用字段的值进行计算,并将计算得到的结果放在输出语句中,{ print $1, $2 * $3 } 就是最开始的例子。
5. 拼文本
可以把单词放在字段与算术表达式之间,例如 { print "total pay for", $1, "is", $2 * $3 }
awk '{ print "total pay for", $1, "is", $2*$3 }' emp.data

三、 更精美的输出
格式化输出需要使用 printf 语句,printf 几乎可以产生任何种类的输出
printf(format, value1, value2, ... , valuen)
format 是一个字符串,它包含按字面打印的文本,中间为格式说明符,格式说明符是%加上后面几个字符,这些字符控制 value 的输出格式。每个格式说明符对应一个value值,因此,格式说明符的数量应该和被打印的 value 一样多。
1. 打印每位雇员的报酬
awk ' { printf("total pay for %s is %.2f\n", $1, $2 * $3) } ' emp.data
这个 printf 语句包含两个格式说明符:%s 将第一个值 $1 以字符串的形式打印;%.2f 将第二个值 $2*$3 按照浮点数格式打印且保留两位小数。其他内容按照字面值打印,\n 表示换行符。printf 不会自动产生空格符或换行符,用户必须自己创建。

来看另一个打印每位雇员的名字与报酬程序:{ printf("%-8s %6.2f\n", $1, $2 * $3) }
%-8s -代表左对齐输出,8占用 8 个字符的宽度,s代表字符串;6.2f,6代表至少占用 6 个字符的宽度,.2f跟前例相同。
awk '{ printf ("%-8s %6.2f\n",$1,$2*$3) }' emp.data

为每一位雇员打印所有的数据,包括报酬,报酬按照升序排列。最简单的办法是使用awk 在每一位雇员的记录前加上报酬,然后将 awk 的输出通过管道传递给 sort 命令。
awk '{ printf("%6.2f %s\n",$2 * $3, $0) }' emp.data | sort -n

四、 选择(过滤)
1. 数值选择
比如过滤报酬大于50的员工信息,模式部分应该是 $2 * $3 > 50,结合前面的格式化:
awk ' $2 * $3 > 50 { printf("%.2f for %s\n"),$2*$3,$1 }' emp.data

2. 通过文本内容选择
也可以选择那些包含特定单词或短语的输入行,下面程序打印所有第一个字段是Susie 的行:
awk ' $1 == "Susie" { printf("%.2f for %s\n"),$2*$3,$1 }' emp.data

也可以通过正则表达式完成,下面程序打印所有包含 Susie 的行:
awk ' /Susie/ { printf("%.2f for %s\n"),$2*$3,$1 }' emp.data

3. 模式的组合
模式可以使用逻辑运算符(&&, ||, 和 !,)进行组合,例如 $2 >= 4 || $3 >= 20
这两个程序是逻辑上是等价的,但第二个可读性比较差

五、 BEGIN 与 END
有两个特殊的模式 BEGIN 和 END。BEGIN 在第一个输入文件的第一行之前被匹配,END 在最后一个输入文件的最后一行被处理之后匹配。下面程序使用 BEGIN 打印一个标题:
awk 'BEGIN { print"NAME RATE HOURS"; print "" } { print } ' emp.data

BEGIN {}构造标题,{ print }输出文件内容,相当于
awk 'BEGIN { print"NAME RATE HOURS"; print "" } ' emp.data; cat emp.data

BEGIN 与END 分别提供了一种控制初始化与扫尾的方式,BEGIN 与 END 不能与其他模式作组合。如果有多个 BEGIN,会按照它们在程序中出现的顺序执行,多个 END 同样适用。
BEGIN 的一个常见用途是更改输入行的分隔符,分隔符由内建变量FS 控制,默认由空格分割(FS=' ')。将 FS设置为什么值,就会使其成为字段分隔符。
下面程序在 BEGIN 里将字段分隔符设置为 \t,并在输出之前打印标题。第二个 printf 语句将输出格式化成一张表格,使得每一列都刚好与标题的列表头对齐,END 打印总和。

六、 用 AWK 计算
1. count
下面程序计算工作时长超过 15 个小时的员工人数
在 awk 中,用户变量不需要事先声明,数值默认初始化为0。对每个第三列>15的行,对emp加1,统计结束后利用END最后输出结果。

2. 求总和与平均数
为了计算雇员的人数,可以使用内建变量 NR(当前行数),当所有输入都处理完毕时,它的值就是读取到的行数。
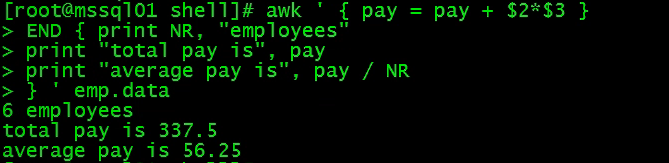
显然如果NR 的值为0,程序会报错,后面再看如何处理。
七、 操作文本
Awk 的长处之一是它可以非常方便地操作字符串。
1. 搜索每小时工资最高的雇员

在这个程序里,变量 maxrate 保存的是数值,maxemp 保存的是字符串,如果有多个雇员都拥有相同的最高每小时工资,这个程序只会打印第一个人的名字。
2. 字符串拼接
将所有雇员名存储到一个单独的字符串中,每一次拼接都是把名字与一个空格符添加到变量 name 的值的末尾,最后在 END 动作中被打印出来。存储字符串的变量的初始值默认为空字符串,因此 name 不需要显式地初始化。

3. 打印最后一行
在 END 里 NR 的值会被保留下来,但是 $0 不会,需要通过用户变量存储。
如果在END前面执行,print $0会打印每行的值,如果放在END里,由于已经遍历完了,就只打印最后一行。

4. 内建函数
awk 提供一些内建函数,例如求平方根、取对数、随机数,还有用来操作文本的函数,比如 length 用来计算字符串中字符的个数。下面程序计算每个名字的长度:
awk ' { print $1, length($1) } ' emp.data

八、 流程控制语句
Awk 提供了 if-else 语句以及循环语句 while和for,这些都来源于 C 语言,只能用在Action部分。
1. if-else 语句
下面程序计算每小时工资>6 的雇员的总报酬与平均报酬。在计算平均数时,它用到了 if 语句,避免用 0 作除数。

改为判断每小时工资>2 的雇员

2. while 语句
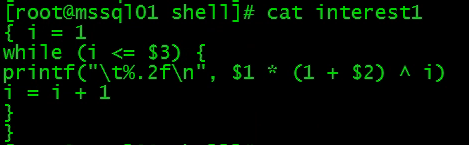
while 含有一个条件判断与一个循环体。当条件为真时,执行循环体。
下面程序展示了一笔钱在特定的利率下如何随着投资时间的增长而增加,假设计算的公式是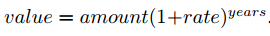

3. for 语句
大多数循环都包括初始化、判断、递增值,for 语句将这三者压缩成一行。
这里是前一个计算投资回报的程序, 不过这次用 for 循环:

九、 数组
awk 提供数组用来存储一组相关的值,数组功能强大,,但是我们在这里只展示一个简单的例子。
下面程序按行逆序显示输入数据

用 for 循环实现的等价的程序

十、 实用 “一行” 手册
虽然 awk 可以写出非常复杂的程序,,但是许多实用的程序并不比我们目前为止看到的复杂多少。这里有一些小程序集合,对读者应该会有一些参考价值,大多数是我们已经讨论过的程序的变形。
1. 输入行的总行数
END { print NR }
2. 打印第 10 行
NR == 10
3. 打印每一个输入行的最后一个字段
{ print $NF }
4. 打印最后一行的最后一个字段
5. 打印字段数多于 4 个的输入行
NF > 4
6. 打印最后一个字段值大于 4 的输入行
$NF > 4
7. 打印所有输入行的字段数的总和
8. 打印包含 Beth 的行的数量
9. 打印具有最大值的第一个字段, 以及包含它的行 (假设 $1 总是 正的) 18
10. 打印至少包含一个字段的行
NF > 0
11. 打印长度超过 80 个字符的行
length($0) > 80
12. 在每一行的前面加上它的字段数
{ print NF, $0 }
13. 打印每一行的第 1 与第 2 个字段, 但顺序相反
{ print $2, $1 }
14. 交换每一行的第 1 与第 2 个字段, 并打印该行
{ temp = $1; $1 = $2; $2 = temp; print }
15. 将每一行的第一个字段用行号代替
{ $1 = NR; print }
16. 打印删除了第 2 个字段后的行
{ $2 = ""; print }
17. 将每一行的字段按逆序打印
18. 打印每一行的所有字段值之和
19. 将所有行的所有字段值累加起来
20. 将每一行的每一个字段用它的绝对值替换
[转帖]《AWK程序设计语言》笔记(1)—— AWK入门与简单案例的更多相关文章
- awk程序设计语言之-awk基础
awk程序设计语言之-awk基础 http://man.linuxde.net/ 常用工具命令之awk命令 awk是一种编程语言,用于在Linux/Unix下对文本和数据处理.数据可以来自标准输入(s ...
- AWK程序设计语言
一. AWK入门指南 Awk是一种便于使用且表达能力强的程序设计语言,可应用于各种计算和数据处理任务.本章是个入门指南,让你能够尽快地开始编写你自己的程序.第二章将描述整个语言,而剩下的章节将向你展示 ...
- python程序设计语言笔记 第一部分 程序设计基础
1.1.1中央处理器(CPU) cpu是计算机的大脑,它从内存中获取指令然后执行这些指令,CPU通常由控制单元和逻辑单元组成. 控制单元用来控制和协调除cpu之外的其他组件的动作. 算数单元用来完成数 ...
- C程序设计语言笔记-第一章
The C Programming language notes 一 基础变量类型.运算符和判断循环 char 字符型 character ...
- R语言笔记:快速入门
1.简单会话 > x<-c(1,2,4) > x [1] 1 2 4 R语言的标准赋值运算符是<-.也可以用=,不过不建议用它,有些情况会失灵.其中c表示连接(concaten ...
- 《linux程序设计》笔记 第一章 入门
linux程序存放位置linux主要有一下几个存放程序的目录: /bin 系统启动程序目录 /usr/bin 用户使用的标准程序 /usr/local/bin 用于存放软件安装目录 /usr ...
- Sed&awk笔记之awk篇
http://blog.csdn.net/a81895898/article/details/8482333 Awk是什么 Awk.sed与grep,俗称Linux下的三剑客,它们之间有很多相似点,但 ...
- Sed&awk笔记之awk篇(转)
Awk是什么 Awk.sed与grep,俗称Linux下的三剑客,它们之间有很多相似点,但是同样也各有各的特色,相似的地方是它们都可以匹配文本,其中sed和awk还可以用于文本编辑,而grep则不具备 ...
- 北京大学Cousera学习笔记--6-计算导论与C语言基础--计算机的基本原理-认识程序设计语言 如何学习
1.是一门高级程序语言 低级语言-机器语言(二进制) 汇编语言-load add save mult 高级语言:有利于人们编写理解 2.C语言的规范定义非常的宽泛 1.long型数据长度不短于int型 ...
- MOOC 编译原理笔记(一):编译原理概述以及程序设计语言的定义
编译原理概述 什么是编译程序 编译程序指:把某一种高级语言程序等价地转换成另一张低级语言程序(如汇编语言或机器代码)的程序. 高级语言程序-翻译->机器语言程序-运行->结果. 其中编译程 ...
随机推荐
- Azure Data Factory(十一)Data Flow 的使用解析
一,引言 上一篇文字,我们初步对 Data Flow 有个简单的了解,也就是说可以使用 Data Flow 完成一些复杂的逻辑,如,数据计算,数据筛选,数据清洗,数据整合等操作,那我们今天就结合 Da ...
- Go语言实现GoF设计模式:备忘录模式的实践探索
本文分享自华为云社区<[Go实现]实践GoF的23种设计模式:备忘录模式>,作者:元闰子. 简介 相对于代理模式.工厂模式等设计模式,备忘录模式(Memento)在我们日常开发中出镜率并不 ...
- Serverless架构的前世今生
一.Serverless简介 云计算的不断发展,涌现出很多改变传统IT架构和运维方式的新技术,而以虚拟机.容器.微服务为代表的技术更是在各个层面不断提升云服务的技术能力,它们将应用和环境中很多通用能力 ...
- 又双叒叕种草了新家装风格?AI帮你家居换装
摘要:又双叒叕种草了家装新风格?想要尝试却又怕踩雷?如果能够轻松Get量身定制的家装风格图,那该多好啊.现在,这一切都成为了可能! 本文分享自华为云社区<又双叒叕种草了新家装风格?AI帮你家居换 ...
- 一文详解TensorFlow模型迁移及模型训练实操步骤
摘要:本文介绍将TensorFlow网络模型迁移到昇腾AI平台,并执行训练的全流程.然后以TensorFlow 1.15训练脚本为例,详细介绍了自动迁移.手工迁移以及模型训练的操作步骤. 本文分享自华 ...
- 云原生数据库风起云涌,华为云GaussDB破浪前行
摘要:云原生数据库,实现多云协同.混合云解决方案.边云协同等能力的数据库. Gartner预测,2021年云数据库在整个数据库市场中的占比将首次达到50%:2023年75%的数据库将基于云的技术来构建 ...
- java并发编程(2):Java多线程-java.util.concurrent高级工具
高级多线程控制类 Java1.5提供了一个非常高效实用的多线程包:java.util.concurrent, 提供了大量高级工具,可以帮助开发者编写高效.易维护.结构清晰的Java多线程程序. Thr ...
- Kubernetes(K8S) 常用命令
Docker 常用命令 Docker 常用命令 # 查看API版本 [root@k8smaster ~]# kubectl api-versions # 重启 K8S [root@k8smaster ...
- Mac问题记录
1. "App" can't be opened because Apple cannot check it for malicious software. 一般来说,在Syste ...
- 23年校招Java开发同花顺、滴滴等面经
前言 已经工作近半年时间了,最近突然翻到这份面经,于是想整理一下一些面试的经验,大中小公司都有 青书一面 50min 数据库.java基础. Cas机制. Tcp/udp区别 堆排序介绍,答错了,弄成 ...