[转帖]内存随机访问也比顺序慢,带你深入理解内存IO过程
https://zhuanlan.zhihu.com/p/86513504
平时大家都知道内存访问很快,今天来让我们来思考两个问题:
问题1: 内存访问一次延时到底是多少?你是否会进行大概的估算?
例如笔者的内存条的Speed显示是1066MHz,那是否可以推算出内存IO延时是1s/1066MHz=0.93ns? 这种算法大错特错。
问题2: 内存存在随机IO比顺序IO慢的问题吗? 我们都知道磁盘的随机IO要比顺序IO慢的多(操作系统底层还专门实现了电梯调度算法来缓解这个问题),那么内存的随机IO会比顺序IO慢吗?
要想彻底弄明白以上两个问题,我想我们得从内存IO的物理过程中来寻找答案。
先给你讲个图书管理员的故事
在开始介绍枯燥的内存工作原理之前。我想先给你讲一个故事,并带你去认识一个人,图书馆的管理员。
在我们的这个故事中,你是故事的主角。你有一所房子,房子里有一个仆人,他每天帮你处理各种各样的图书数据。但是北京房价太贵,所以你的这个房子很小,只能放的下64本书。你家的马路对面,就是北京图书馆(你家房子虽然小但是地段还不错),你所需要的所有的图书在那里都可以找到。图书馆有个管理员,他负责帮你把你想要的书找出来。

图1 图书管理员的故事
好接下来,故事开始进行!
场景1:
你发现你需要编号为0的书的计算结果,你的仆人穿过马路告诉了图书管理员,告诉他请帮我把第0-63本书取出来。图书管理员帮你在电脑前查得该书在二楼。 于是他,花了点时间坐电梯到了二楼。等到了二楼,他又花了点时间帮你找了出来。然后你的仆人抱着64本书放到了客厅,拿起第0本书帮你处理了起来。
场景2:
你发现你需要编号为1的书的计算结果,告诉你的仆人。你的仆人直接从客厅拿出来就可以处理了,这次你等的时间最短。
场景3:
你发现需要编号为65的书,你又告诉你的仆人。你的仆人穿过马路又去找了图书管理员。图书管理员还在二楼呢,听说这次需要65-127,这次他不用再花时间找楼层了。只是花时间找书就可以了。你的仆人把65-127的书放到了客厅(以前的0-63就都扔了),并帮你开始处理起65号书来。
场景4:
你发现你需要编号为10000的书,你告诉了你的仆人。你的仆人穿过马路去图书馆,找到了管理员。这次管理员查得你需要的书是在10楼,他得花点时间坐电梯过去。去了之后,他又得花点时间帮你找出来。
这四个场景里,我觉得你一定发现了不同情形下耗时的差异。
- 场景1和场景4花费的时间最多。因为图书管理员需要花时间坐电梯找楼层,需要花时间在楼内找书。
- 场景3次之,因为图书管理员直接就在楼层内,只需要花时间在楼内找书既可
- 场景2最快,因为只需要仆人帮你从客厅拿过来就好,连马路都不需要过。
之所以编造这么一个例子,是因为内存的工作方式和它太像了。 接下来我们进入内存的实际分析。
内存的物理结构
在《带你理解内存对齐最底层原理!》中我们了解了内存颗粒的物理构造以及IO过程,今天我们再来复习一下。
内存是由chip构成。每个chip内部,是由8个bank组成的。其构造如下图:

图2 内存颗粒chip内部结构
而每一个bank是一个二维平面上的矩阵,前面文章中我们说到过。矩阵中每一个元素中都是保存了1个字节,也就是8个bit。

图3 bank内部物理结构
每当CPU向内存请求数据的时候,内存芯片总是8个bank并行一起工作。每个bank在定位到行地址后,把对应的行copy到row buffer。 再根据列地址把对应的元素中的数据取出来,8个bank把数据拼接一下,一个64位宽的数据就可以返回给CPU了。
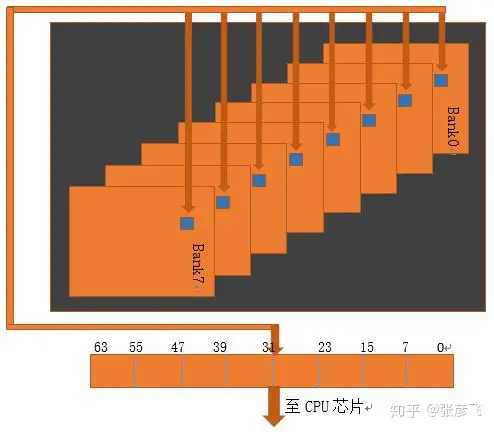
图4 一次内存IO的过程示意
根据上面几张图我们可以大致了解内存的IO过程,在这个过程中每一步操作之间都有一些延迟,让我们来继续了解这些延迟。
内存IO延迟
在《从DDR发展到DDR4,内存核心频率指标其实基本上就没太大的进步》里我们提到内存的延迟很大程度是受核心频率制约的,你也应该记得我们提到了内存延迟一般是通过CL-tRCD-tRP-tRAS四个参数来标识的。 我们今天来详细理解一下这四个参数的含义:
- CL(Column Address Latency):发送一个列地址到内存与数据开始响应之间的周期数
- tRCD(Row Address to Column Address Delay):打开一行内存并访问其中的列所需的最小时钟周期数
- tRP(Row Precharge Time):发出预充电命令与打开下一行之间所需的最小时钟周期数。
- tRAS(Row Active Time):行活动命令与发出预充电命令之间所需的最小时钟周期数。也就是对下一次预充电时间进行限制。
要注意除了CL是固定周期数以外,其它的三个都是最小周期。另外上面的参数都是以时钟周期为单位的。因为现代的内存都是一个时钟周期上下沿分别各传输一次数据,所以用Speed/2就可以得出,例如笔者的机器的Speed是1066MHz,则时钟周期为533MHz。你自己的机器可以通过dmidecode命令查看:
# dmidecode | grep -P -A16 "Memory Device"
Memory Device
......
Speed: 1067 MHz
......和“图书管理员”类似,内存芯片也有类似的工作场景:
场景1:
你的进程需要内存地址0x0000为的一个字节的数据,CPU这时候向内存控制器发出请求,内存控制器进行行地址的预充电,需要等待tRP个时钟周期。再发出打开一行内存的命令,又需要等待tRCD个时钟周期。接着发送列地址,再等待CL个周期。最终将0x0000-0x0007的数据全部返回给了CPU。 CPU把这些数据放入到了自己的cache里,并帮你开始对0x0000的数据进行运算。
场景2:
你的进程需要内存地址0x0003的一个字节数据,CPU发现发现它在自己的cache里存在,直接使用就好了。这个场景里其实根本就没有内存IO发生。
场景3:
你的进程需要内存地址0x0008的一个字节数据,CPU的cache并没有命中,于是向内存控制器请求。内存控制器发现行地址和上一次工作的行地址一致,这次只需要发送列地址后等待CL个周期,就可以拿到0x0008-0x0015的数据并返回给CPU了。
场景4:
你的进程需要内存地址0xf000的一个字节数据,同样CPU的cache并不命中,向内存控制器请求。内存控制器一看(内心有些许的郁闷),这次行地址又变了,得,和场景1一样。继续等待tRP+tRCD+CL个周期后,才能够取到数据并返回。
实际的计算机的内存IO过程中还需要进行逻辑地址和物理地址的转换,这里忽略不表。
结论
其中场景1和场景4是随机IO的情况,场景2无内存IO发生,场景3是顺序IO。通过上面的过程描述我们可以得到结论。内存也存在和磁盘一样,随机IO比顺序IO要慢的问题。如果行地址同上一次访问的不一致,则需要重新拷贝row buffer,延迟周期需要tRP+tRCD+CL。而如果是顺序IO的话(行地址不变),只需要CL个周期既可完成。
我们接着估算下内存的延时,笔者的机器上的内存参数Speed为1066MHz(通过dmidecode查得),该值除以2就是时钟周期的频率=1066/2=533Mhz。其延迟周期为7-7-7-24。
- 随机IO:这种状况下需要tRP+tRCD+CL个时钟周期,7+7+7=21个周期。但是还有个tRAS的限制,两次行地址预充电不得小于24。所以我们得按24来计算,24*(1s/533Mhz) = 45ns
- 顺序IO:这种状况下只需要CL个时钟周期 7*(1s/533Mhz)=13ns
扩展:回顾CPU的Cache Line
因为对于内存来说,随机IO一次开销比顺序IO高好几倍。所以操作系统在工作的时候,会尽量让内存通过顺序IO的方式来进行。做法关键就是Cache Line。当CPU发现缓存不命中的时候,实际上从来不会向内存去请求1个字节,8个字节这种。而是一次性就要64字节,然后放到自己的Cache中存起来。
用上面的例子来看,
- 如果随机请求8字节:耗时是45ns
- 如果随机请求64字节:耗时是45+7*13 = 136ns
开销也没贵多少,因为只有第一个字节可能是随机IO,后面的7个字节都是顺序IO。数据是8倍,但是IO耗时只有3倍,而且取出来的数据后面大概率要用,所以计算机内部就这么搞了,通过这种方式帮你避免一些随机IO!
另外,内存也支持burst(突发传输)模式,在这种模式下可以只传入一次行列地址,就命令内存返回该内存开头的连续字节数据,比如64字节。这种模式下,只有第一次的8字节需要真正的行列访问延迟,后面的7个字节可以直接按内存的数据频率给吐出来。接下来我们进行实践测试,请转移到《实际测试内存在顺序IO和随机IO时的访问延时差异》。
[转帖]内存随机访问也比顺序慢,带你深入理解内存IO过程的更多相关文章
- 关于顺序磁盘IO比内存随机IO快的讨论
这个问题来源于我书中引用的一幅图: 我们从图中明显可以看某性能测试的结果表明普通机械磁盘的顺序I/O性能指标是53.2M values/s,SSD的顺序I/O性能指标是42.2M values/s,而 ...
- Java API —— IO流(数据操作流 & 内存操作流 & 打印流 & 标准输入输出流 & 随机访问流 & 合并流 & 序列化流 & Properties & NIO)
1.操作基本数据类型的流 1) 操作基本数据类型 · DataInputStream:数据输入流允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型.应用程序可以使用数据输出 ...
- Java内存模型深度解析:顺序一致性--转
原文地址:http://www.codeceo.com/article/java-memory-3.html 数据竞争与顺序一致性保证 当程序未正确同步时,就会存在数据竞争.java内存模型规范对数据 ...
- Java:IO流其他类(字节数组流、字符数组流、数据流、打印流、Properities、对象流、管道流、随机访问、序列流、字符串读写流)
一.字节数组流: 类 ByteArrayInputStream:在构造函数的时候,需要接受数据源,而且数据源是一个字节数组. 包含一个内部缓冲区,该缓冲区包含从流中读取的字节.内部计数器跟踪 read ...
- 深入理解Java内存模型(三)——顺序一致性
数据竞争与顺序一致性保证 当程序未正确同步时,就会存在数据竞争.java内存模型规范对数据竞争的定义如下: 在一个线程中写一个变量, 在另一个线程读同一个变量, 而且写和读没有通过同步来排序. 当代码 ...
- MappedByteBuffer高速缓存文件、RandomAccessFile随机访问
说到高速缓存存储,处理读写文件,那就不得不说MappedByteBuffer. 看了好多文章以后写一下自己的总结. 在这里先介绍一下相关的类与方法. 先说一下Buffer.ByteBuffer.Map ...
- 【转】深入理解Java内存模型(三)——顺序一致性
数据竞争与顺序一致性保证 当程序未正确同步时,就会存在数据竞争.java内存模型规范对数据竞争的定义如下: 在一个线程中写一个变量, 在另一个线程读同一个变量, 而且写和读没有通过同步来排序. 当代码 ...
- Java IO详解(六)------随机访问文件流
File 类的介绍:http://www.cnblogs.com/ysocean/p/6851878.html Java IO 流的分类介绍:http://www.cnblogs.com/ysocea ...
- Java开发笔记(八十七)随机访问文件的读写
前面介绍了字符流读写文件的两种方式,包括文件字符流和缓存字符流,但是它们的写操作都存在一个问题:不管是write方法还是append方法,都只能从文件开头写入,而不能追加到文件末尾或者在文件中间某个位 ...
- Java IO详解(七)------随机访问文件流
File 类的介绍:http://www.cnblogs.com/ysocean/p/6851878.html Java IO 流的分类介绍:http://www.cnblogs.com/ysocea ...
随机推荐
- Asp .Net Core 系列:基于 Swashbuckle.AspNetCore 包 集成 Swagger
什么是 Swagger? Swagger 是一个规范和完整的框架,用于生成.描述.调用和可视化 RESTful 风格的 Web 服务.它提供了一种规范的方式来定义.构建和文档化 RESTful Web ...
- 神经网络基础篇:史上最详细_详解计算图(Computation Graph)
计算图 可以说,一个神经网络的计算,都是按照前向或反向传播过程组织的.首先计算出一个新的网络的输出(前向过程),紧接着进行一个反向传输操作.后者用来计算出对应的梯度或导数.计算图解释了为什么用这种方式 ...
- 华为云推出全自研数据库,GaussDB(openGauss)能否撑起一片天?
摘要:GaussDB(openGauss) 基于华为云底座,能够快速全球化部署,同时支持用户的本地化部署诉求,跟云上生态工具紧密结合让用户在迁移.开发.运维上省时省心. GaussDB(openGau ...
- head/reset/revert/rebase代码回滚全解:git提交记录的背后原理
多人合作程序开发的过程中,我们有时会出现错误提交的情况,此时我们希望能撤销提交操作,让程序回到提交前的样子,操作有: 回退(reset):reset是彻底回退到指定的commit版本,该commit后 ...
- HIVE报错 need to specify partition columns because the destination table is partitioned
解决 分区需要指定分区 insert into table XXX partition(分区='')
- C# WPF 将第三方DLL嵌入 exe
没成功,只是做个记录,后面再研究 希望将第三方的 HandyControl.dll 嵌入到 exe 中,这样不用发多个文件给别人 将第三方DLL.加载到解决方案中 添加引用 将"属性页&qu ...
- display:none和overflow:hidden的区别
1.display:none 当将一个元素的display属性设置为none时,该元素将不会显示在网页中,并且不会占据任何空间.也就是说,该元素会完全隐藏,其他的元素会立即占据它原来的位置.该属性适用 ...
- SD 信用模拟检查增强
一.业务流程中需要进行信用模拟检查,但逻辑梳理较为复杂,因此借用交货单创建时信用检查逻辑.但是当交货单信用检查通过时,不创建交货单,因此需要对BAPI:BAPI_OUTB_DELIVERY_CREAT ...
- 【Debug】常用问题排查流程
常用问题排查流程 查看当前用户信息
- ACM:快读读入技巧
快速读入:当数据输入较大时,比scanf快 inline int read(){ int s=0,w=1; char ch=getchar(); while(ch<'0'||ch>'9') ...