hdfs深入:05、hdfs中的fsimage和edits的合并过程
6.4、secondarynameNode如何辅助管理FSImage与Edits文件
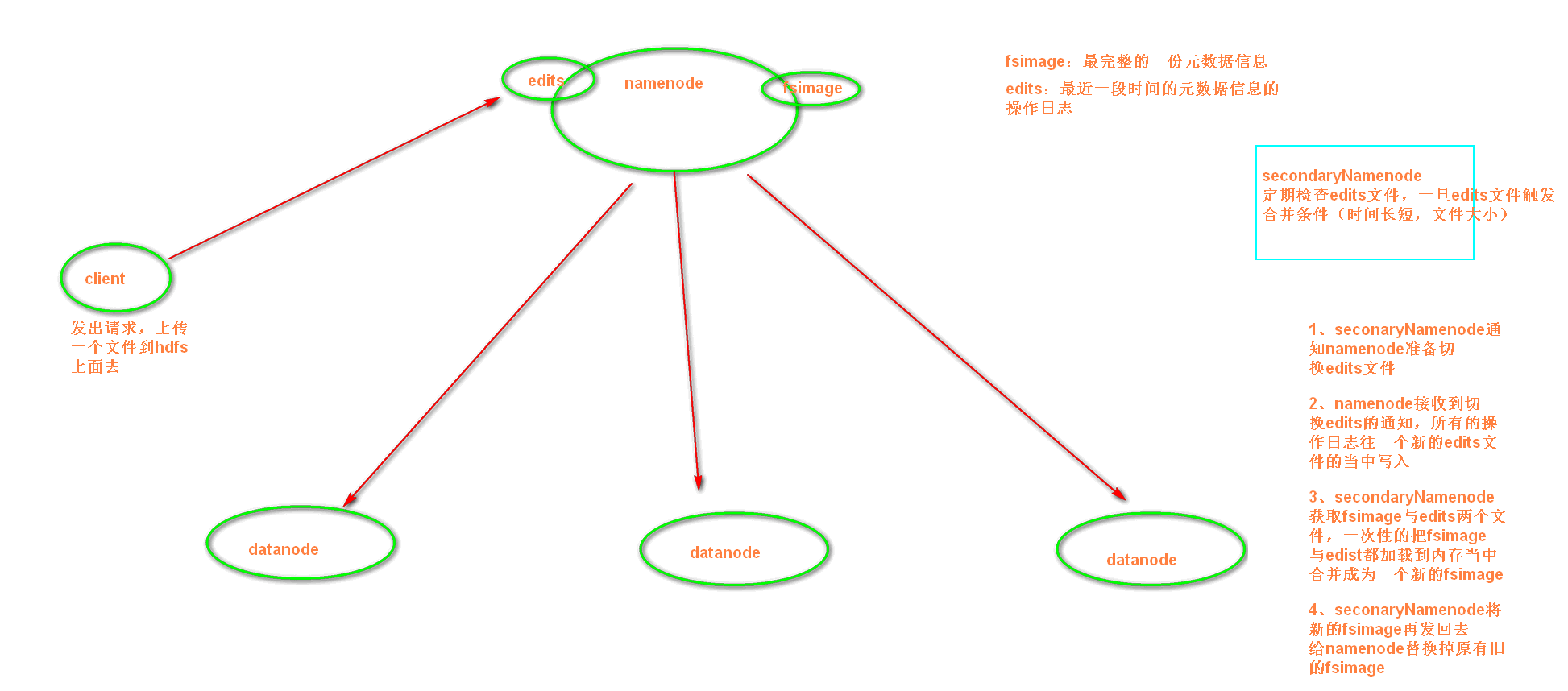
①:secnonaryNN通知NameNode切换editlog
②:secondaryNN从NameNode中获得FSImage和editlog(通过http方式)
③:secondaryNN将FSImage载入内存,然后开始合并editlog,合并之后成为新的fsimage
④:secondaryNN将新的fsimage发回给NameNode
⑤:NameNode用新的fsimage替换旧的fsimage
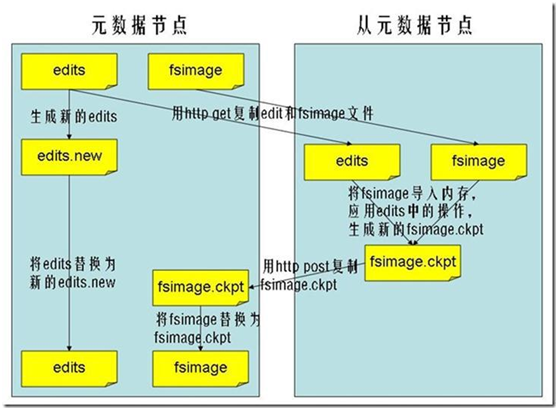

完成合并的是secondarynamenode,会请求namenode停止使用edits,暂时将新写操作放入一个新的文件中(edits.new)。secondarynamenode从namenode中通过http get获得edits,因为要和fsimage合并,所以也是通过http get 的方式把fsimage加载到内存,然后逐一执行具体对文件系统的操作,与fsimage合并,生成新的fsimage,然后把fsimage发送给namenode,通过http post的方式。namenode从secondarynamenode获得了fsimage后会把原有的fsimage替换为新的fsimage,把edits.new变成edits。同时会更新fstime。
hadoop进入安全模式时需要管理员使用dfsadmin的save namespace来创建新的检查点。
secondarynamenode在合并edits和fsimage时需要消耗的内存和namenode差不多,所以一般把namenode和secondarynamenode放在不同的机器上。
fs.checkpoint.period: 默认是一个小时(3600s)
fs.checkpoint.size: edits达到一定大小时也会触发合并(默认64M)
hdfs深入:05、hdfs中的fsimage和edits的合并过程的更多相关文章
- HDFS之四:HDFS原理解析(总体架构,读写操作流程)
前言 HDFS 是一个能够面向大规模数据使用的,可进行扩展的文件存储与传递系统.是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和 存储空间.让实际上是通过网络来访问文件 ...
- 【转】Hadoop 1.x中fsimage和edits合并实现
在NameNode运行期间,HDFS的所有更新操作都是直接写到edits中,久而久之edits文件将会变得很大:虽然这对NameNode运行时候是没有什么影响的,但是我们知道当NameNode重启的时 ...
- HDFS 05 - HDFS 的元数据管理(FSImage、EditLog、Checkpoint)
目录 1 - NameNode 的启动流程 2 - NameNode 的元数据 2.1 EditLog 操作日志 2.2 查看 EditLog 文件 2.3 FSImage 元数据镜像 2.4 查看 ...
- hdfs数据到hive中,以及hdfs数据隐身理解
hdfs数据到hive中: 假设hdfs中已存在好了数据,路径是hdfs:/localhost:9000/user/user_w/hive_g2park/user_center_enterprise_ ...
- HDFS追本溯源:HDFS操作的逻辑流程与源码解析
本文主要介绍5个典型的HDFS流程,这些流程充分体现了HDFS实体间IPC接口和stream接口之间的配合. 1. Client和NN Client到NN有大量的元数据操作,比如修改文件名,在给定目录 ...
- [HDFS Manual] CH3 HDFS Commands Guide
HDFS Commands Guide HDFS Commands Guide 3.1概述 3.2 用户命令 3.2.1 classpath 3.2.2 dfs 3.2.3 envvars 3.2.4 ...
- [HDFS Manual] CH2 HDFS Users Guide
2 HDFS Users Guide 2 HDFS Users Guide 2.1目的 2.2.概述 2.3.先决条件 2.4. Web Interface 2.5. Shell Command 2. ...
- [HDFS Manual] CH1 HDFS体系结构
v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VM ...
- HDFS之三:hdfs参数配置详解
1.hdfs-site.xml 参数配置 – dfs.name.dir – NameNode 元数据存放位置 – 默认值:使用core-site.xml中的hadoop.tmp.dir/dfs/nam ...
随机推荐
- python名片管理系统
1.代码: (1)主程序 #!/usr/bin/env python # -*- coding: UTF-8 -*- import cards_tools # 无限循环,由用户主动决定什么时候退出循环 ...
- 《JAVA与模式》之调停者模式
调停者模式是对象的行为模式.调停者模式包装了一系列对象相互作用的方式,使得这些对象不必相互明显引用.从而使它们可以较松散地耦合.当这些对象中的某些对象之间的相互作用发生改变时,不会立即影响到其他的一些 ...
- 【转】使用git将项目上传到github(最简单方法)
原文地址:http://www.cnblogs.com/cxk1995/p/5800196.html 首先你需要一个github账号,所有还没有的话先去注册吧! https://github.com/ ...
- logstsh | logstash-input-jdbc 启动错误收集
1: Failed to execute action {:action=>LogStash::PipelineAction::Create/pipeline_id:main, :excepti ...
- CMake学习笔记二:cmake 常用变量和常用环境变量
1 cmake 变量引用的方式 使用 ${} 进行变量的引用.在 IF 等语句中,是直接使用变量名而不通过 ${} 取值. 2 cmake 自定义变量的方式 主要有隐式定义和显式定义两种,举一个隐式定 ...
- 【LeetCode 33】Search in Rotated Sorted Array
Search in Rotated Sorted Array 分段有序的数组,二分查找返回下标,没有返回-1 数组有序之后经过 rotated, 比如:6 1 2 3 4 5 or 5 6 7 8 ...
- 446 Arithmetic Slices II - Subsequence 算数切片之二 - 子序列
详见:https://leetcode.com/problems/arithmetic-slices-ii-subsequence/description/ C++: class Solution { ...
- ambari-server启动报错500 status code received on GET method for API:/api/v1/stacks/HDP/versions/2.4/recommendations Error message : Server Error解决办法(图文详解)
问题详情 来源是,我在Ambari集群里,安装Hue. 给Ambari集群里安装可视化分析利器工具Hue步骤(图文详解 所遇到的这个问题. 然后,去ambari-server的log日志,查看,如下 ...
- 关于java的arrays数组排序示例AJPFX的分享
Java API对Arrays类的说明是:此类包含用来操作数组(比如排序和搜索)的各种方法. 1.对基本数据类型的数组的排序 说明: (1)Arrays类中的sort()使用的是“经过调优的快速排序法 ...
- 堆排序原理及其js实现
图文来源:https://www.cnblogs.com/chengxiao/p/6129630.html 堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时 ...