Python 之lxml解析库
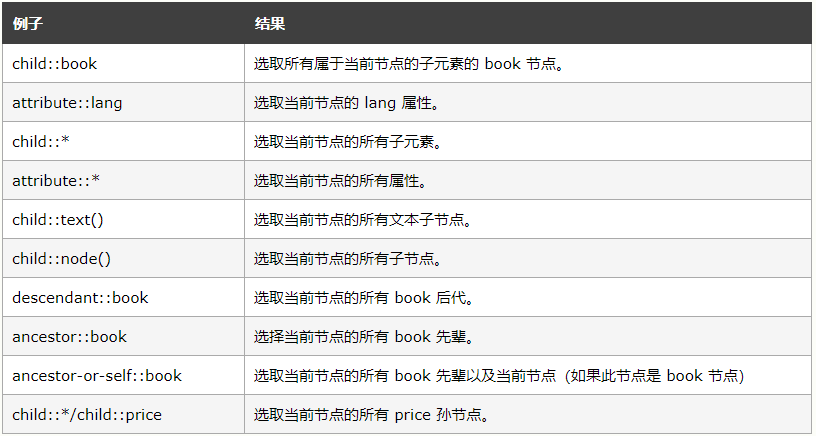
一、XPath常用规则




二、解析html文件
from lxml import etree # 读取HTML文件进行解析
def parse_html_file():
html = etree.parse("./test.html", parser=etree.HTMLParser())
print(etree.tostring(html).decode("utf-8"))
'''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
<body>
<h1>yangs</h1>
</body>
</html>
''' # 读取文本解析节点
def get_text_node(text):
html = etree.HTML(text, parser=etree.HTMLParser())
print(html.xpath("//ul/li[position()=2]/text()")) # ['你好!!!']
print(html.xpath("//ul/li[2]/text()")) # ['你好!!!'] # 获取所有节点
def get_all_node(text):
html = etree.HTML(text, parser=etree.HTMLParser())
print(html.xpath(
"//*")) # [<Element html at 0x20be0903f48>, <Element body at 0x20be0910048>, <Element div at 0x20be0910088>, <Element ul at 0x20be09100c8>, <Element li at 0x20be0910108>, <Element a at 0x20be0910188>, <Element li at 0x20be09101c8>, <Element li at 0x20be0910208>, <Element span at 0x20be0910248>] # 获取子节点
def get_children_node(text):
html = etree.HTML(text, parser=etree.HTMLParser())
print(html.xpath("//div/ul/li/a")) # [<Element a at 0x1e15740e108>] # 获取父节点
def get_parent_node(text):
html = etree.HTML(text, parser=etree.HTMLParser())
print(html.xpath("//a/..")) # [<Element li at 0x28a7d2ae108>, <Element li at 0x28a7d2ae208>] # 属性匹配
def math_attr(text):
html = etree.HTML(text, parser=etree.HTMLParser())
print(html.xpath("//a[@href='2.html']/text()")) # ['hello world'] # 属性获取
def get_attr(text):
html = etree.HTML(text, parser=etree.HTMLParser())
print(html.xpath("//a/@href")) # ['1.html', '2.html'] # 属性多值匹配
def match_more_attr(text):
html = etree.HTML(text, parser=etree.HTMLParser())
print(html.xpath("//li[contains(@class, 'aaa')]/a/text()")) # ['yangs'] if __name__ == '__main__':
text = '''
<div>
<ul>
<li class="aaa last-li"><a href="1.html">yangs</a></li>
<li>你好!!!</li>
<li class="last-li"><a href="2.html">hello world</a></li>
</ul>
</div>
'''
三、去哪儿网html抓取案例
import requests
from lxml import etree def go_where(keyword):
url = "https://piao.qunar.com/ticket/list.htm?keyword=" + keyword
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
try:
html = requests.get(url, headers=headers).content.decode("utf-8")
except RuntimeError as e:
print(e)
try:
html_object = etree.HTML(html, parser=etree.HTMLParser())
# 获取总共多少条数据
count = len(html_object.xpath("//div[@class='sight_item']"))
return_data = []
for i in range(count):
name = html_object.xpath("//div[@class='sight_item']/@data-sight-name")
districts = html_object.xpath("//div[@class='sight_item']/@data-districts")
point = html_object.xpath("//div[@class='sight_item']/@data-point")
img_url = html_object.xpath("//div[@class='sight_item']/@data-sight-img-u-r-l")
address = html_object.xpath("//div[@class='sight_item']/@data-address")
return_data.append({
"name": name[i],
"districts": districts[i],
"point": point[i],
"address": address[i],
"img_url": img_url[i]
})
return return_data
except RuntimeError as e:
print(e) if __name__ == '__main__':
data = go_where("温州")
print(data) # [{'name': '雁荡山', 'districts': '浙江·温州·乐清市', 'point': '121.095868,28.352028', 'address': '浙江省温州乐清市雁荡镇雁山路88号', 'img_url': 'https://imgs.qunarzz.com/sight/p0/1604/70/7094d064511234be90.img.jpg_280x200_03cb9d77.jpg'}, {'name': '江心屿', 'districts': '浙江·温州·鹿城区', 'point': '120.645422,28.032889', 'address': '浙江省温州市鹿城区望江东路119号', 'img_url': 'https://imgs.qunarzz.com/sight/p0/201402/24/0b725e8cd5bb14af0a634e7dc7057e15.jpg_280x200_6042c3f2.jpg'}, {'name': '楠溪江', 'districts': '浙江·温州·永嘉县', 'point': '120.696651,28.063045', 'address': '浙江省温州市永嘉县楠溪江风景区', 'img_url': 'https://imgs.qunarzz.com/sight/p0/1603/20/20e0961e888e8db790.water.jpg_280x200_373cc32f.jpg'}, {'name': '石桅岩', 'districts': '浙江·温州·楠溪江', 'point': '120.906672,28.38873', 'address': '浙江省温州市永嘉县鹤盛乡', 'img_url': 'https://imgs.qunarzz.com/sight/p0/201301/16/18efacf1a049d44793835fbb.jpg_280x200_ded84edf.jpg'}, {'name': '龙湾潭国家森林公园', 'districts': '浙江·温州·楠溪江', 'point': '120.881758,28.343969', 'address': '浙江省温州市永嘉县鹤盛乡季家岙', 'img_url': 'https://imgs.qunarzz.com/sight/p0/201301/15/3a5b3d27b59a888393835fbb.jpg_280x200_fb391fc7.jpg'}, {'name': '大龙湫', 'districts': '浙江·温州·雁荡山', 'point': '121.060234,28.354889', 'address': '浙江省温州乐清市雁荡山雁山路88号', 'img_url': 'https://imgs.qunarzz.com/sight/p0/201405/20/2d7f19b34f7a6064e9bb8dc0d531e4b1.jpg_280x200_cc049369.jpg'}, {'name': '仙叠岩', 'districts': '浙江·温州·洞头县', 'point': '121.171743,27.82429', 'address': '浙江省温州市洞头县', 'img_url': 'https://imgs.qunarzz.com/sight/p73/201211/03/b3a8633322999c0d93835fbb.jpg_280x200_8d32214b.jpg'}, {'name': '灵峰', 'districts': '浙江·温州·雁荡山', 'point': '121.122449,28.38293', 'address': '浙江省温州乐清市中雁荡山的东大门', 'img_url': 'https://imgs.qunarzz.com/sight/p0/1410/14/72a3cf0e134514459208762c339ea137.jpg_280x200_a9c29a7f.jpg'}, {'name': '雁荡山净名谷', 'districts': '浙江·温州·雁荡山', 'point': '121.106647,28.37454', 'address': '浙江省温州乐清市雁荡镇响岭头村净名路16-1号', 'img_url': 'https://imgs.qunarzz.com/sight/p0/201301/16/32144da037b4f5bd93835fbb.jpg_280x200_9d664b50.jpg'}, {'name': '小龙湫', 'districts': '浙江·温州·灵岩', 'point': '121.09865,28.365099', 'address': '浙江省温州市乐清市雁荡山白芙线旁', 'img_url': 'https://imgs.qunarzz.com/sight/p47/201211/02/bf0df4ce367cf77893835fbb.jpg_280x200_7db1df9d.jpg'}, {'name': '雁荡山飞拉达攀岩景区', 'districts': '浙江·温州·雁荡山', 'point': '121.059208,28.399697', 'address': '浙江省温州市乐清市仙溪镇龙西乡庄屋村', 'img_url': 'https://imgs.qunarzz.com/sight/p0/1802/48/488f3680d455fc9da3.img.jpg_280x200_62d7e7f7.jpg'}]
有我案例代码优化的,可以发给我。。。
Python 之lxml解析库的更多相关文章
- 网络爬虫之Selenium模块和Xpath表达式+Lxml解析库的使用
实际生产环境下,我们一般使用lxml的xpath来解析出我们想要的数据,本篇博客将重点整理Selenium和Xpath表达式,关于CSS选择器,将另外再整理一篇! 一.介绍: selenium最初是一 ...
- 第二节:web爬虫之lxml解析库
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高.
- lxml解析库的安装和使用
一.lxml的安装lxml是Python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高.本节中,我们了解一下lxml的安装方式,这主要从Windows.Linux ...
- Python爬虫【解析库之beautifulsoup】
解析库的安装 pip3 install beautifulsoup4 初始化 BeautifulSoup(str,"解析库") from bs4 import BeautifulS ...
- python爬虫中XPath和lxml解析库
什么是XML XML 指可扩展标记语言(EXtensible Markup Language) XML 是一种标记语言,很类似 HTML XML 的设计宗旨是传输数据,而非显示数据 XML 的标签需要 ...
- Python Beautiful Soup 解析库的使用
Beautiful Soup 借助网页的结构和属性等特性来解析网页,这样就可以省去复杂的正则表达式的编写. Beautiful Soup是Python的一个HTML或XML的解析库. 1.解析器 解析 ...
- python爬虫三大解析库之XPath解析库通俗易懂详讲
目录 使用XPath解析库 @(这里写自定义目录标题) 使用XPath解析库 1.简介 XPath(全称XML Path Languang),即XML路径语言,是一种在XML文档中查找信息的语言. ...
- Python的网页解析库-PyQuery
PyQuery库也是一个非常强大又灵活的网页解析库,如果你有前端开发经验的,都应该接触过jQuery,那么PyQuery就是你非常绝佳的选择,PyQuery 是 Python 仿照 jQuery 的严 ...
- Python爬虫【解析库之pyquery】
该库跟jQuery的使用方法基本一样 http://pyquery.readthedocs.io/ 官方文档 解析库的安装 pip3 install pyquery 初始化 1.字符串初始化 htm ...
随机推荐
- ms sql server 系统表详细说明
sysaltfiles 主数据库 保存数据库的文件 syscharsets 主数据库字符集与排序顺序 sysconfigures 主数据库 配置选项 syscurconfigs 主数据 ...
- Android开发:Eclipse中SqliteManager插件使用
通常开发Android的时候要使用到数据库操作,会遇到下面小问题: 数据库文件在哪?怎样訪问或操作? 能够通过:打开DDMS->File Explorer看到的sqlite数据库在eclipse ...
- C#根据规则生成6位随机码
#region 获得6位优惠码 zhy public static string CreatePromoCode(string code) { if (code == "") { ...
- LeetCode 893. Groups of Special-Equivalent Strings (特殊等价字符串组)
题目标签:String 题目可以让在 偶数位置的 chars 互换, 也可以让 在 奇数位置的 chars 互换. 所以为了 return 正确的 group 数量,需要把 那些重复的 给排除掉. 可 ...
- express 与 mvc
听人介绍,说express.js是一个for nodejs的mvc框架. 既然是MVC,那么,express里面,什么是M,什么是V,又什么是C? C,很容易看出来,就是路由.express的路由机制 ...
- NoSQL 世界交换数据的事实标准
https://www.elastic.co/guide/cn/elasticsearch/guide/current/data-in-data-out.html An object is a lan ...
- 【总结】设备树语法及常用API函数【转】
本文转载自:http://blog.csdn.net/fengyuwuzu0519/article/details/74352188 一.DTS编写语法 二.常用函数 设备树函数思路是:uboot ...
- YTU 2720: 删出多余的空格
2720: 删出多余的空格 时间限制: 1 Sec 内存限制: 128 MB 提交: 338 解决: 201 题目描述 小平在给弟弟检查英语作业时时,发现每个英语句子单词之间的空格个数不等,请你编 ...
- Istio 1.1部署实践
前提条件 正确安装配置Kubernetes集群 CentOS Linux release 7.5.1804 安装 下载istio 1.1版本 [root@vm157 ~]# wget https:// ...
- PCB genesis SET取中心点--算法实现
最新ICS工厂有一项incam脚本新需求,这里介绍5种解决方法解决 需求如下图所示:绿色所圈处是是需求出的中心点(图形间距一致归为一类并计算中心点坐标) 前题条件:1.一个SET里面可能有多个CAM, ...