spark与Scala安装过程和步骤及sparkshell命令的使用

Spark与Scala版本兼容问题:
Spark运行在Java 8 +,Python 2.7 + / 3.4 +和R 3.1+上。对于Scala API,Spark 2.4.2使用Scala 2.12。您需要使用兼容的Scala版本(2.12.x)。
请注意,自Spark 2.2.0起,对2.6.5之前的Java 7,Python 2.6和旧Hadoop版本的支持已被删除。自2.3.0起,对Scala 2.10的支持被删除。自Spark 2.4.1起,对Scala 2.11的支持已被弃用,将在Spark 3.0中删除。
https://spark.apache.org/docs/latest/index.html
1.官网下载安装Scala:scala-2.12.8.tgz
https://www.scala-lang.org/download/
2.将Scala解压到/opt/module目录下
tar -zxvf scala-2.12.8.tgz -C /opt/module
3.将scala-2.12.8改成Scala
mv scala-2.12.8 scala
4.测试scala是否安装成功
测试:scala -version
5.启动Scala命令:scala

1.官网下载安装Spark:spark-2.4.2-bin-hadoop2.7.tgz
https://www.apache.org/dyn/closer.lua/spark/spark-2.4.2/spark-2.4.2-bin-hadoop2.7.tgz
2.解压、重命名
ar -zxvf spark-2.4.2-bin-hadoop2.7.tgz -C /opt/module
mv spark-2.4.2-bin-hadoop2.7.tgz spark
3.配置环境变量
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin #
使环境变量生效 :source /etc/profile
4.启动spark
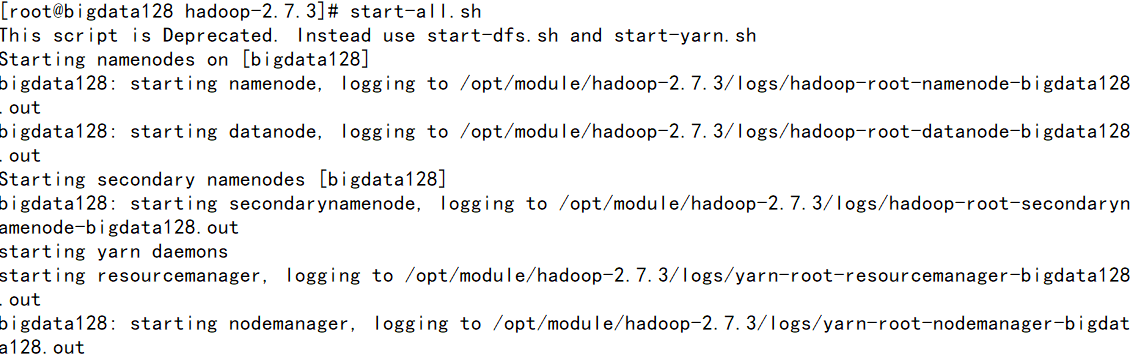
①先启动hadoop 环境
start-all.sh
②启动spark环境
进入到SPARK_HOME/sbin下运行start-all.sh
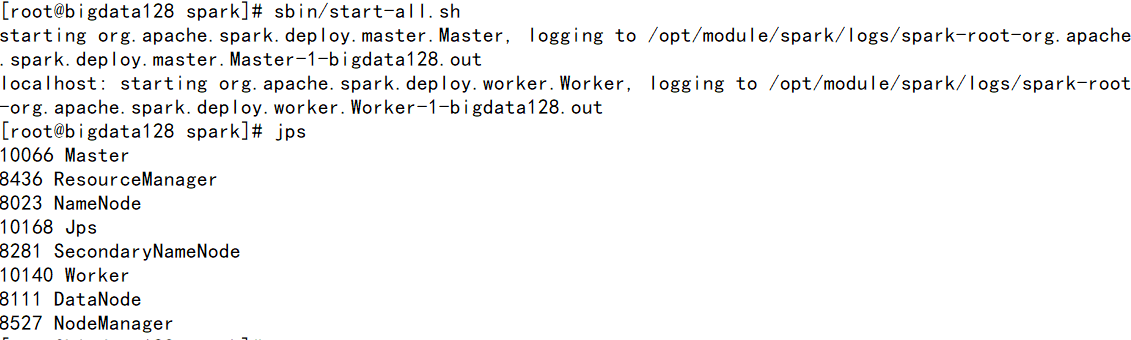
[注] 如果使用start-all.sh时候会重复启动hadoop配置,需要./在当前工作目录下执行命令
jps 观察进程 多出 worker 和 mater 两个进程。
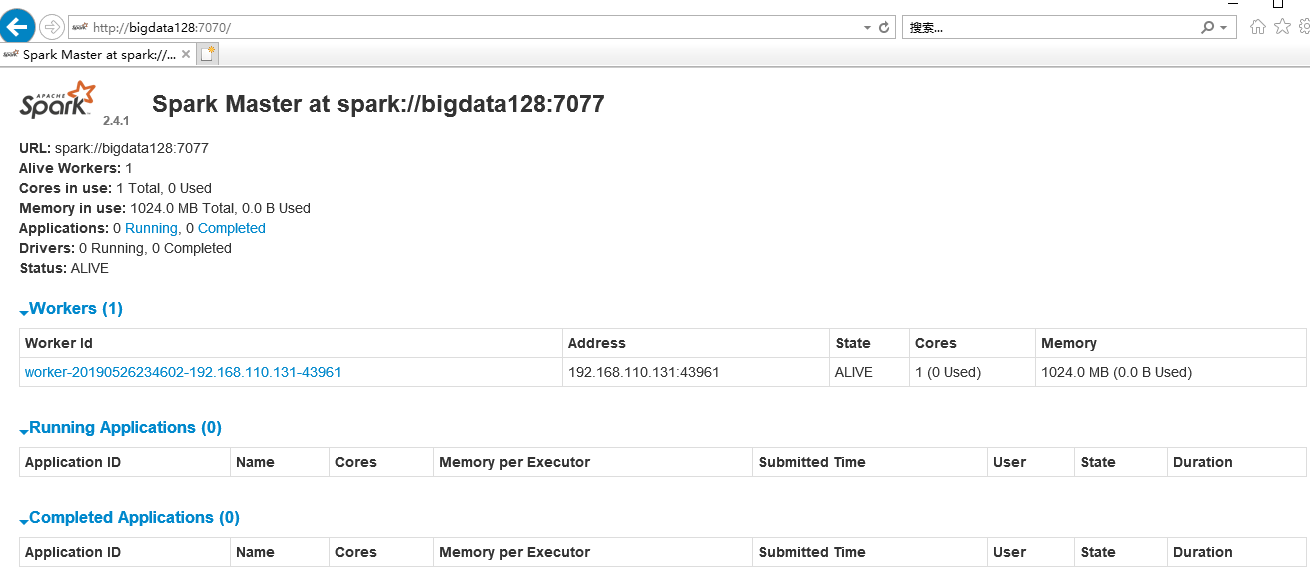
5.查看spark的web控制页面:http://bigdata128:7077/
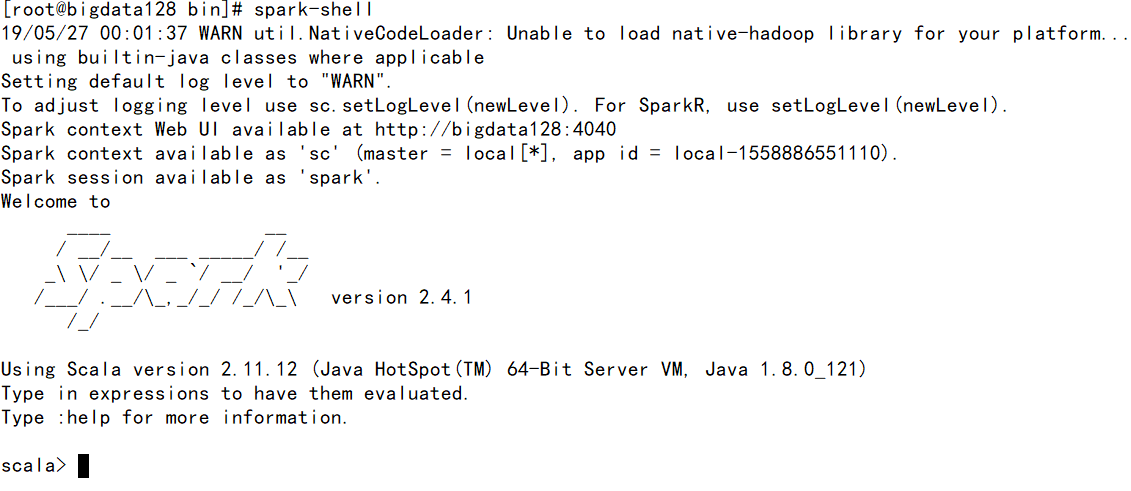
使用Spark-shell命令
此模式用于interactive programming,先进入bin文件夹后运行:spark-shell

spark与Scala安装过程和步骤及sparkshell命令的使用的更多相关文章
- Bigbluebutton安装过程
BigBlueButton安装过程(翻译) 欢迎来到BigBlueButton 1.0-beta安装指南(以下简称BigBlueButton 1.0).BigBlueButton是一个开放源代码的网络 ...
- Spark安装过程纪录
1 Scala安装 1.1 master 机器 修改 scala 目录所属用户和用户组. sudo chown -R hadoop:hadoop scala 修改环境变量文件 .bashrc , 添加 ...
- JProfiler远程监控Linux上Tomcat的安装过程细讲(步骤非常详细!!!)
JProfiler远程监控Linux上Tomcat的安装过程细讲(步骤非常详细!!!) 1.文件准备: 服务器:CentOS Linux release 7.3.1611 (Core) Apa ...
- Spark安装过程
Precondition:jdk.Scala安装,/etc/profile文件部分内容如下: JAVA_HOME=/home/Spark/husor/jdk CLASSPATH=.:$JAVA_HOM ...
- eclipse创建maven管理Spark的scala
说明,由于spark是用scala写的.因此,不管是在看源码还是在写spark有关的代码的时候,都最好是用scala.那么作为一个程序员首先是必须要把手中的宝剑给磨砺了.那就是创建好编写scala的代 ...
- Spark学习笔记——安装和WordCount
1.去清华的镜像站点下载文件spark-2.1.0-bin-without-hadoop.tgz,不要下spark-2.1.0-bin-hadoop2.7.tgz 2.把文件解压到/usr/local ...
- spark集群安装部署
通过Ambari(HDP)或者Cloudera Management (CDH)等集群管理服务安装和部署在此不多介绍,只需要在界面直接操作和配置即可,本文主要通过原生安装,熟悉安装配置流程. 1.选取 ...
- Win7 单机Spark和PySpark安装
欢呼一下先.软件环境菜鸟的我终于把单机Spark 和 Pyspark 安装成功了.加油加油!!! 1. 安装方法参考: 已安装Pycharm 和 Intellij IDEA. win7 PySpark ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
随机推荐
- Luogu P4231 三步必杀 (差分)
目录 题目 题解 题目 题目链接 题目背景 (三)旧都 离开狭窄的洞穴,眼前豁然开朗. 天空飘着不寻常的雪花. 一反之前的幽闭,现在面对的,是繁华的街市,可以听见酒碗碰撞的声音. 这是由被人们厌恶的鬼 ...
- 【php】运算符优先级界定
<?php $i = 1; $array[$i] = $i++; print_r($array);die; //输出 Array([2] => 1) $a = 1; echo $a + $ ...
- mysql 慢查询日志 mysqldumpslow 工具
文章来源:https://www.cnblogs.com/hello-tl/p/9229676.html 1.使用Mysql慢查询日志配置 查看慢查询日志是否开启 OFF关闭 ON开启 show va ...
- django第10天(聚合查询,常用字段)
django第10天 聚合查询 聚合函数的使用场景 单独使用:不分组,只查聚合结果 分组使用:按字段分组,可查分组字段与聚合结果 导入聚合函数 from django.db.models import ...
- "javac不是内部或外部命令"的解决办法
“javac不是内部或外部命令”,而此时的java环境是好用的: 1.先检查 JAVA_HOME = C:\Program Files\Java\jdk1.7.0_45 classpath ...
- Python第三方库之openpyxl(10)
Python第三方库之openpyxl(10) 雷达图 在工作表上的列或行中排列的数据可以在雷达图中绘制.雷达图比较多个数据系列的总值.它实际上是一个圆形x轴上的面积图的投影.有两种类型的雷达图:st ...
- swift final关键字、?、!可选与非可选符
?符号: 可选型 在初始化时可以赋值为nil !符号: 隐形可选型 类型值不能为nil,如果解包后的可选类型为nil会报运行时错误,主要用在一个变量/常量在定义瞬间完成之后值一定会存在的情况.这主要 ...
- pytorch使用过程中遇到的一些问题
问题一 ImportError: No module named torchvision torchvison:图片.视频数据和深度学习模型 解决方案 安装torchvision,参照官网 问题二 安 ...
- 也来“玩”Metro UI之磁贴(二)
继昨天的“也来“玩”Metro UI之磁贴(一)”之后,还不过瘾,今天继续“玩”吧——今天把单选的功能加进来,还有磁贴的内容,还加了发光效果(CSS3,IE9+浏览器),当然,还是纯CSS,真的要感谢 ...
- 【Luogu】P1868饥饿的奶牛(DP)
题目链接 话说我存一些只需要按照一个关键字排序的双元素结构体的时候老是喜欢使用链式前向星…… DP.f[i]表示前i个位置奶牛最多能吃到的草.转移方程如下: f[i]=f[i-]; f[i]=max( ...