HDFS03
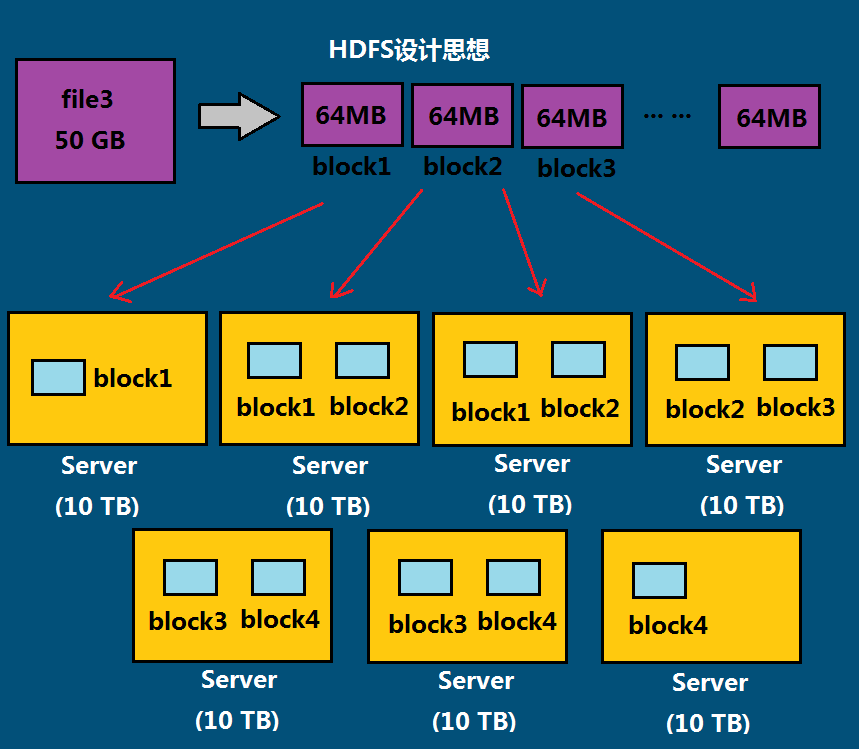
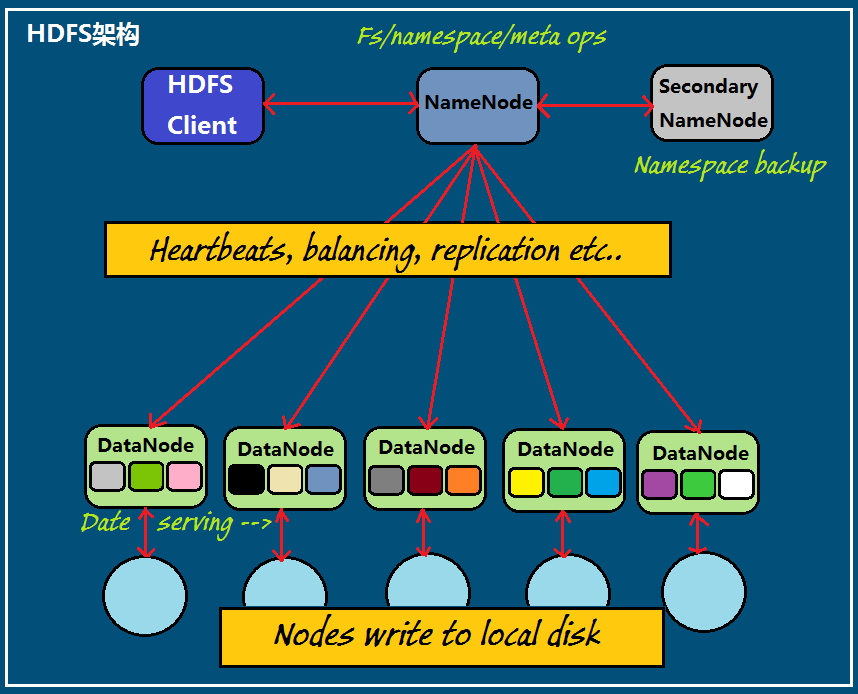
=====================HDFS数据块(block)=====================
文件被切分成固定大小的数据块 ------------->
√默认数据块大小为64MB,可配
√若文件大小不到64MB,则单存成一个block
为何数据块如此之大 ------------->
√数据传输时间超过寻道时间(高吞吐率)
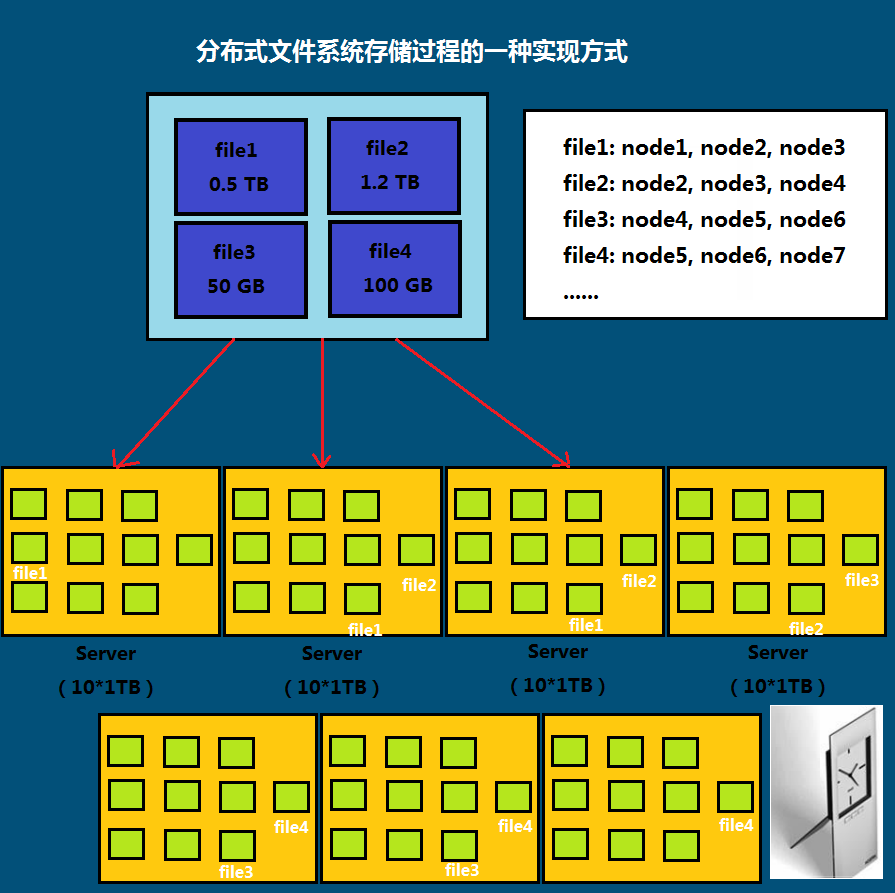
一个文件存储方式 ------------->
√按大小被切分成若干个block,存储到不同的节点上
√默认情况下每个block有三个备份
HDFS03的更多相关文章
- HDFS03 HDFS的API操作
HDFS的API操作 目录 HDFS的API操作 客户端环境准备 1.下载windows支持的hadoop 2.配置环境变量 3 在IDEA中创建一个Maven工程 HDFS的API实例 用客户端远程 ...
- HDFS基本操作的API
一.从hdfs下载文件到windows本地: package com.css.hdfs01; import java.io.IOException; import java.net.URI; impo ...
- Hortonwork Ambari配置Hive集成Hbase的java开发maven配置
集群环境 ambari 2.7.3 hdp/hortonwork 2.6.0.3 maven <dependency> <groupId>org.apache.hive< ...
随机推荐
- CLISTCTRL2
回顾: 刚刚写完,因为是分期写的,所以最初想好好做一下的文章格式半途而废了~说的也许会有点啰嗦,但是所有的基础用到的技术细节应该都用到了. 如果还有什么疑问,请回复留言,我会尽力解答. 如果有错误,请 ...
- 梦想CAD控件打印相关
一.打印设置 在顶部快速访问工具栏单击打印按钮或者直接输入PLOT命令或者点击打印控制的打印设置按钮打开打印对话框.c#代码实现如下: //打印设置 private void Print1() { ...
- php中 如何找到session 的保存位置
[前言] 刚刚想测试FQ操作,需要删除session,这里记录分享下 [主体] (1)想要查看session保存的目录,需要先找到 php.ini配置文件 (2)在php.ini文件中查找 sessi ...
- 04Oracle Database 登陆
Oracle Database 登陆 EM Express Login https://localhost:5500/em/login cmd sqlplus SQL/PLUS system/code ...
- 实战:tcp链接rst场景tcpdump分析
RST为重置报文段,它会导致TCP连接的快速拆迁,且不需要ack进行确认. 1.针对不存在的端口的连请求 客户端: #include <unistd.h> #include <sys ...
- org.springframework.data.repository.config.RepositoryConfigurationSource.getAttribute(Ljava/lang/String;)Ljava/util/Optional;
升级springboot到2.0时,碰到了一大堆问题,上面异常原因是jar版本冲突了,有的模块忘记更新版本了,统一一下版本就可以了
- POJ P2096 Collecting Bugs
思路 分类讨论,不妨先设$DP[i][j]$表示已经发现$i$种子系统中有$n$种$bug$无非只有四种情况 发现的$bug$在旧的系统旧的分类,概率$p1$是$(i/s)*(j/n)$. 发现的$b ...
- sscanf 与 sscanf_s
sscanf 与 sscanf_s 之间的Details sscanf sscanf函数想必大家用的很熟练吧 sscanf函数原型: sscanf(const char* src,format,... ...
- [Algorithm] 10. Reverse Integer
Description Given a 32-bit signed integer, reverse digits of an integer. Example Example 1: Input: 1 ...
- Gym - 101670H Dark Ride with Monsters(CTU Open Contest 2017 贪心)
题目: A narrow gauge train drives the visitors through the sequence of chambers in the Dark Ride attra ...