postgres SQL编译过程
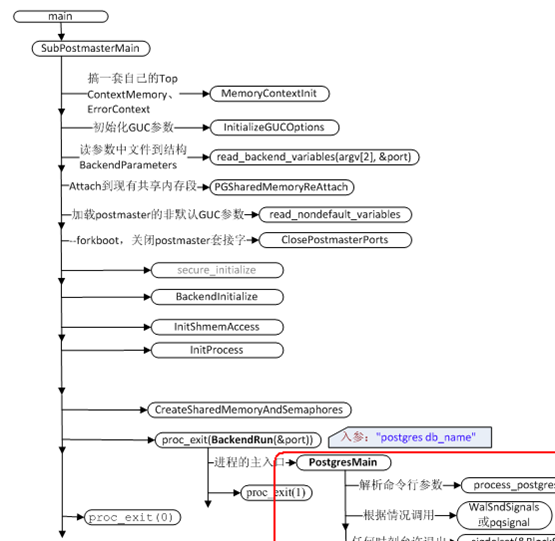

PG启动首先完成主进程和后台进程的启动,启动时完成数据库文件的打开,共享内存的建立等。接着,所有SQL都会启动1个单独的进程处理SQL的执行过程。
新的进程首先是进行自身的初始化,最主要的是初始化内存上下文,准备好SQL处理过程。
进入PostgresMain后,解析客户端命令行参数dbname;做文件、存储、缓存的初始化;设置合适的信号处理句柄;调用InitPostgres方法给portgres服务进程做相关初始化,这个方法里初始化了relcache和catcache,初始化了执行查询计划的portal的管理器,填充本进程PGPROC结构相关部分成员等。进入无限循环,检查并处理任何请求或者最近收到的信号。然后再接着循环。
循环一直在ReadCommand。 进入无限循环后,切换到内存上下文"MessageContext"并清理干净该内存上下文;读取客户端命令;根据客户端各种命令分别进行处理。

客户端发起请求,pg服务器为该请求启动一个postgres访问进程为该客户端通过访问,建立了连接。这个postgres访问进程进入无限循环,等待客户端请求并为其通过服务,直到进程终止,连接断口。
当客户端给服务器端发出查询SQL后,建立连接时已经启动且进入无限循环的服务器端的postgres服务进程处理步骤如下:
(1)调用MemoryContextSwitchTo切换内存上下文到"MessageContext"。
(2)调用MemoryContextResetAndDeleteChildren清理上次为相同连接服务时"MessageContext"内存上下文里遗留的对象。
(3)调用ReadCommand读取客户端的请求。
(4)根据客户端请求判断要提供何种服务,进入相应分支。
从源码的角度分析sql编译过程:
对于一个简单SQL查询,主要的处理过程是先调用start_xact_command方法开启一个事务,再用pg_parse_query方法用词法语法解析工具把查询命令解析为解析树parsetree,根据需要调用PushActiveSnapshot方法搞一个快照,调用pg_analyze_and_rewrite方法分析、根据规则重写解析树为查询树querytree,调用pg_plan_queries方法把查询树转换到执行计划树plantree,在调用相应方法创建portal和在postal中执行执行计划树并给客户端发回结果。然后退出当前事务,清理内存。
src/backend/parser下,scan.l为词法定义,gram.y为语法定义。
postgres SQL编译过程的更多相关文章
- Hive SQL 编译过程
转自:http://www.open-open.com/lib/view/open1400644430159.html Hive跟Impala貌似都是公司或者研究所常用的系统,前者更稳定点,实现方式是 ...
- Hive SQL编译过程(转)
转自:https://www.cnblogs.com/zhzhang/p/5691997.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive ...
- 【转】Hive SQL的编译过程
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- Hive SQL的编译过程
文章转自:http://tech.meituan.com/hive-sql-to-mapreduce.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是 ...
- 转:Hive SQL的编译过程
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- Hive SQL的编译过程[转载自https://tech.meituan.com/hive-sql-to-mapreduce.html]
https://tech.meituan.com/hive-sql-to-mapreduce.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hi ...
- Hive SQL的底层编译过程详解
本文结构采用宏观着眼,微观入手,从整体到细节的方式剖析 Hive SQL 底层原理.第一节先介绍 Hive 底层的整体执行流程,然后第二节介绍执行流程中的 SQL 编译成 MapReduce 的过程, ...
- 对MySql查询缓存及SQL Server过程缓存的理解及总结
一.MySql的Query Cache 1.Query Cache MySQL Query Cache是用来缓存我们所执行的SELECT语句以及该语句的结果集.MySql在实现Query Cache的 ...
- Spark源码的编译过程详细解读(各版本)
说在前面的话 重新试多几次.编译过程中会出现下载某个包的时间太久,这是由于连接网站的过程中会出现假死,按ctrl+c,重新运行编译命令. 如果出现缺少了某个文件的情况,则要先清理maven(使用命 ...
随机推荐
- Lambert (兰伯特)光照模型
Lambert (兰伯特)光照模型 是光源照射到物体表面后,向四面八方反射,产生的漫反射效果.这是一种理想的漫反射光照模型.如下图:这个是顶点函数处理后的该光照模型,因此看起来像素不够平滑. 漫反射 ...
- Mysql 使用命令及 sql 语句示例
Mysql 是数据库开发使用的主要平台之一.sql 的学习掌握与使用是数据库开发的基础,此处展示详细sql 语句的写法,及各种功能下的 sql 语句. 在此处有 sql 语句使用示例:在这里 此处插入 ...
- PYDay6- 内置函数、验证码、文件操作、发送邮件函数
1.内置函数 1.1Python的内置函数 abs() dict() help() min() setattr() all() dir() hex() next() slice() any() div ...
- Cookie测试的测试点
1.禁止使用Cookie:设置浏览器禁止使用Cookie,访问网页后,检查存放Cookie文件中未生成相关文件: 2.Cookie寻出路径:按照操作系统和浏览器对Cookie存放路径的设置,检查存放路 ...
- C# 字符串型转数字型
// 当需要将字符串格式的数字转为数字时候,我们会用到的函数为Convert.ToDouble(),// 然而当你的字符串为49,9时,由于包含了逗号,函数会将逗号忽略,直接转为499,// 所以我们 ...
- Cocos2d-JS 实现将TiledMap中的每个 tile 变成物理精灵的方法
How to generate a physics body from a tiledmap 鄙人在网上找了许久都未找到方法,说句实在话,Cocos2d官方给出的与物理引擎相关的内容真的不是很多, ...
- tomcat的安装和优化
tomcat的安装 jdk版本安装 #!/bin/bash # desc: jdk安装脚本1. 1.7 1.8 download_url='http://**************' jdk_env ...
- 【bzoj4804】欧拉心算 欧拉函数
题目描述 给出一个数字N 输入 第一行为一个正整数T,表示数据组数. 接下来T行为询问,每行包含一个正整数N. T<=5000,N<=10^7 输出 按读入顺序输出答案. 样例输入 1 1 ...
- [SCOI2005]最大子矩阵 (动态规划)
题目描述 这里有一个n*m的矩阵,请你选出其中k个子矩阵,使得这个k个子矩阵分值之和最大.注意:选出的k个子矩阵不能相互重叠. 输入输出格式 输入格式: 第一行为n,m,k(1≤n≤100,1≤m≤2 ...
- 【NOI2012】骑行川藏
获得成就:第一次在信竞做神仙数学题 先放个前言,$OI$ 出大型数学题还是比较麻烦的,因为主要是考你数学推导 / 手算式子,你算出来之后把公式套个板子,就得到结论——$OI$ 的大型数学题的代码都是板 ...