Mysql查询语句的 where子句、group by子句、having子句、order by子句、limit子句
Mysql的各个查询语句
一、where子句
语法:select *|字段列表 from 表名 where 表达式。where子句后面往往配合MySQL运算符一起使用(做条件判断)
作用:通过限定的表达式的条件对数据进行过滤,得到我们想要的结果。
1.MYSQL运算符:
MySQL支持以下的运算符:
关系运算符
< >
<= >=
= !=(<>)
注意:这里的等于是一个等号
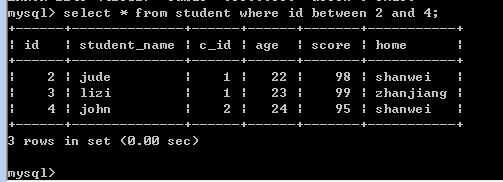
between and
做数值范围限定,相当于数学上的闭区间!
比如:
between A and B相当于 [A,B]

in和not in
语法形式:in|not in(集合)
表示某个值出现或没出现在一个集合之中!

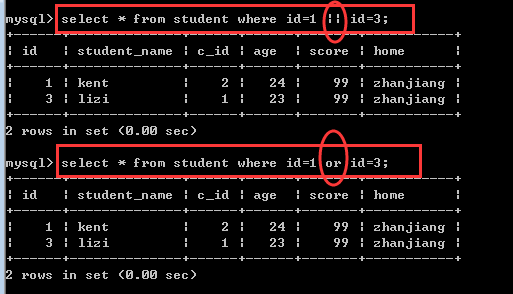
逻辑运算符
&& and
|| or
! not
where子句的其他形式
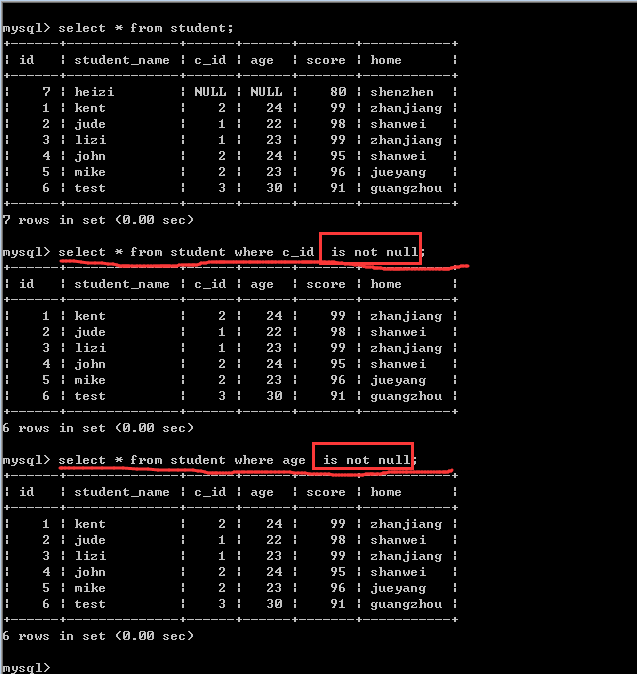
空值查询
select *|字段列表 from 表名 where 字段名 is [not] null
模糊查询
也就是带有like关键字的查询,常见的语法形式是:
select *|字段列表from 表名 where 字段名 [not] like ‘通配符字符串’;
所谓的通配符字符串,就是含有通配符的字符串!
MySQL中的通配符有两个:
_ :代表任意的单个字符
% :代表任意的字符
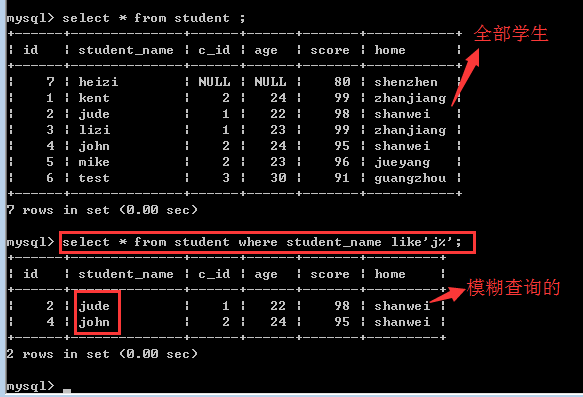
案例一:
查找student表中student_name字段以“j”开头的学生信息!
案例二:
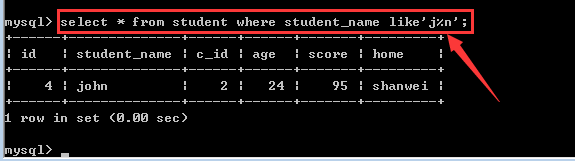
查找student表中student_name字段以“j”开头以“n”结尾的学生信息!
案例三:
查找student表中student_name字段含有“n”字的学生信息

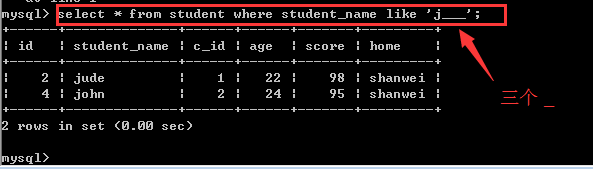
案例四:
查找student表中student_name以“j”开头含有四个字母的名字的学生信息
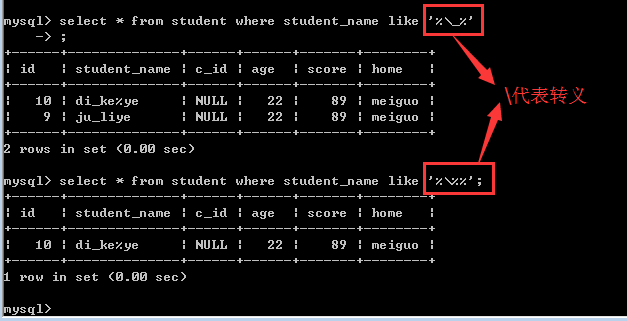
案例五:
查找student表中stu_name含有_或含有%的学生信息
由于%和_都具有特殊的含义,所以如果确实想查询某个字段中含有%或_的记录,需要对它们进行转义!
也就是查找 \_ 和 \%
二、group by子句
也叫作分组统计查询语句!
语法
group by 字段1[,字段2]……
从形式上看,就是通过表内的某个或某些字段进行分组:
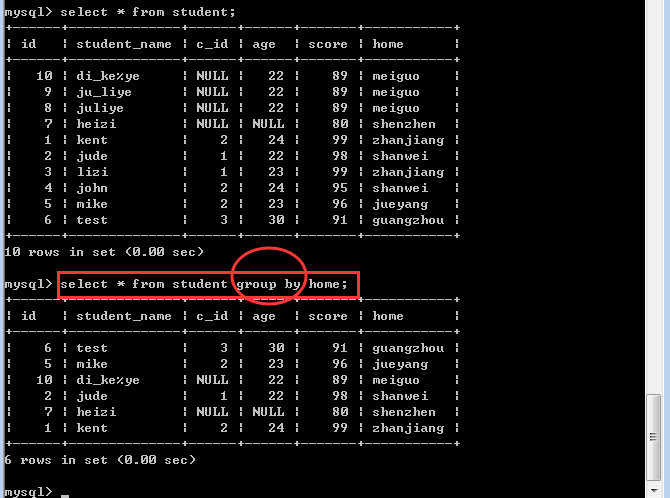
所以,分组之后,只会从每一个组内取出第一条记录,这种查询结果毫无意义!
因为分组统计查询的主要作用不是分组,而是统计!或者说分组的目的就是针对每一个分组进行相关的统计!
此时,就需要使用系统中的一些统计函数!
统计函数(聚合函数)
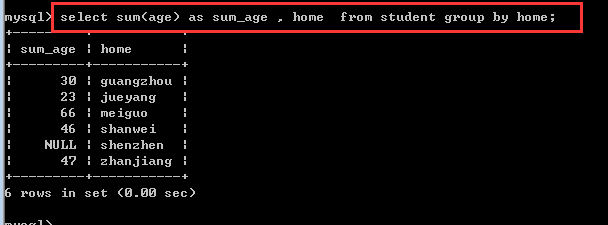
sum():求和,就是将某个分组内的某个字段的值全部相加

等于做了以前的两件事情:
1, 先按home字段对整个的表进行分组!(分成了4组)
2, 再把每一个组内的所有记录的age字段的值全部相加
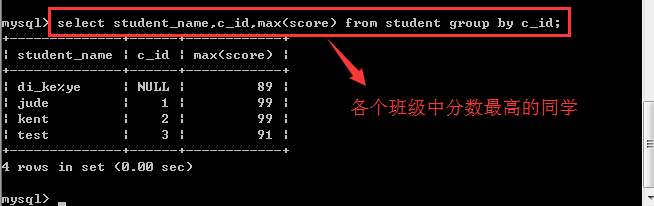
max():求某个组内某个字段的最大值
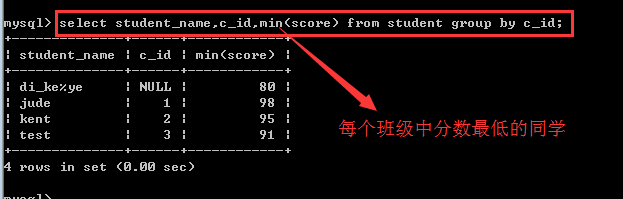
min():求某个组内某个字段的最小值
avg():求某个组内某个字段的平均值
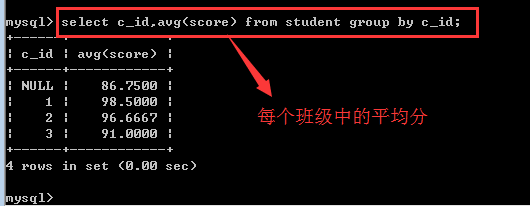
count():统计某个组内非null记录的个数,通常就是用count(*)来表示!


注意:
统计函数都是可以单独的使用的!但是,只要使用统计函数,系统默认的就是需要分组,如果没有group by子句,默认的就是把整个表中的数据当成一组!

多字段分组
group by 字段1[,字段2]……
作用是:先根据字段1进行分组,然后再根据字段2进行分组!
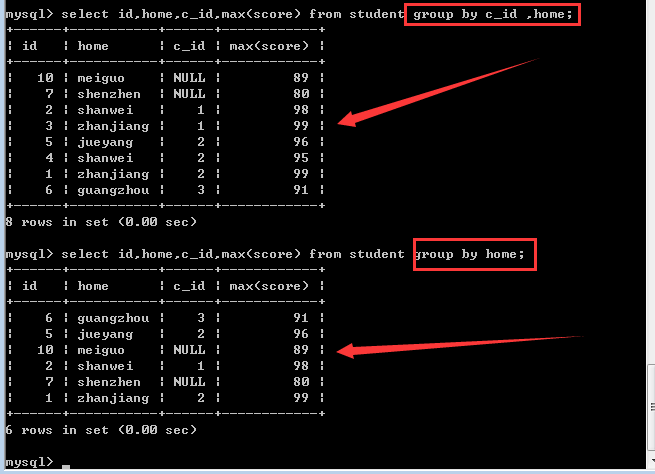
所以,多字段分组的结果就是分组变多了!
回溯(su)统计
回溯统计就是向上统计!
在进行分组统计的时候,往往需要做上级统计!
比如,先统计各个班的总人数,然后各个班的总人数再相加,就可以得到一个年级的总人数!
再比如,先统计各个班的最高分,然后各个班的最高分再进行比较,就可以得到一个年级的最高分!
如何实现?
答:在MySQL中,其实就是在语句的后面加上with rollup即可!
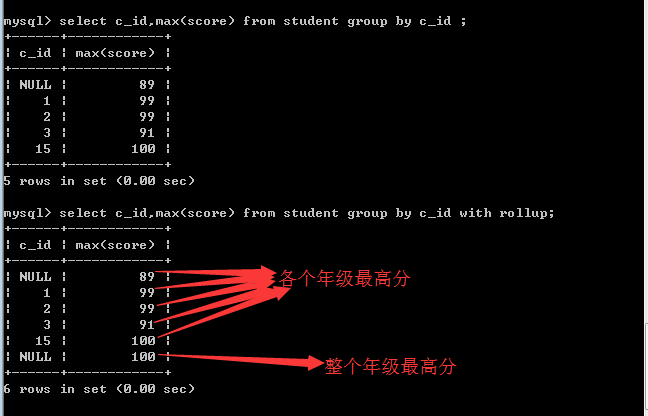


注意:
既然group by子句出现在where子句之后,说明了,我们可以先将整个数据源进行筛选,然后再进行分组统计!
三、having子句
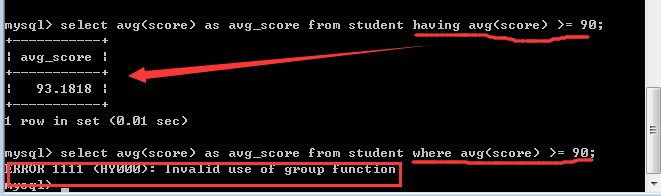
having子句和where子句一样,也是用来筛选数据的,通常是对group by之后的统计结果再次进行筛选!

那么,having子句和where子句到底有什么区别呢?
二者的比较:
1, 如果语句中只有having子句或只有where子句的时候,此时,它们的作用基本是一样的!
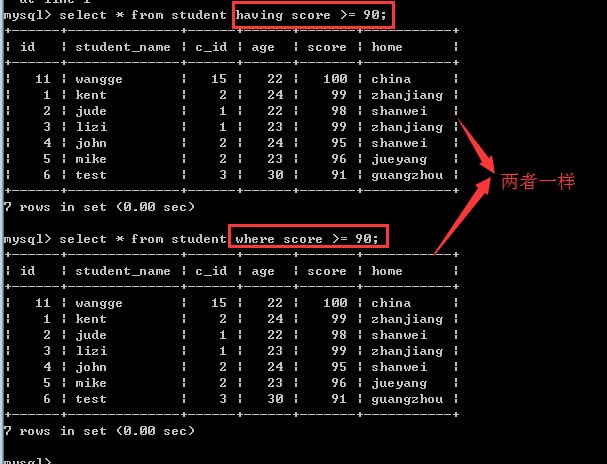
2, 二者的本质区别是:where子句是把磁盘上的数据筛选到内存上,而having子句是把内存中的数据再次进行筛选!
3, where子句的后面不能使用统计函数,而having子句可以!因为只有在内存中的数据才可以进行运算统计!
四、order by子句
语法
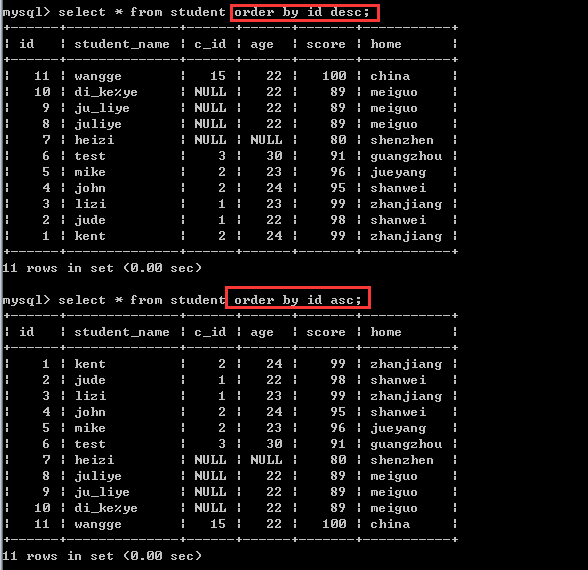
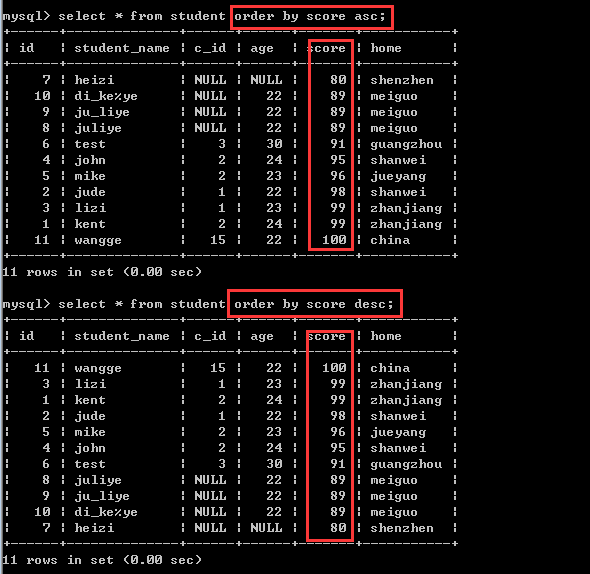
根据某个字段进行排序,有升序和降序!
语法形式为:
order by 字段1[asc|desc]
默认的是asc,也就是升序!如果要降序排序,需要加上desc!
①根据id排序
②根据成绩排序
思考:
假如现在有若干个学生的成绩score是一样的,怎么办?
此时,可以使用多字段排序!
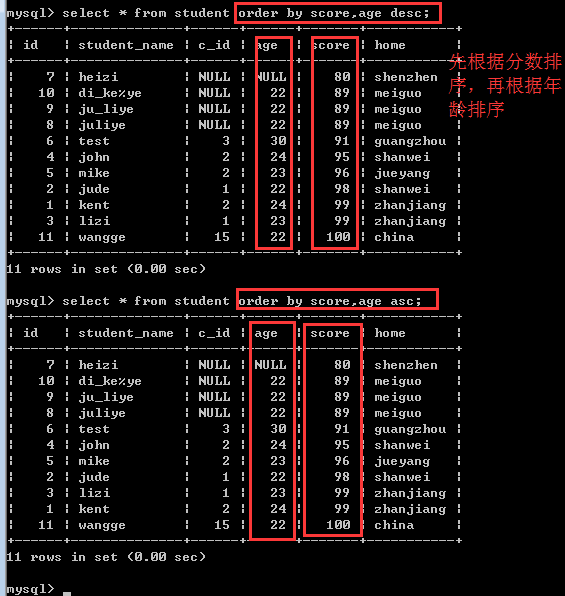
多字段排序
order by 字段1[asc|desc],字段2[asc|desc]……
比如:order by score asc,age desc
也就是说,先按分数进行升序排序,如果分数一样的时候,再按年龄进行降序排序!
五、limit子句
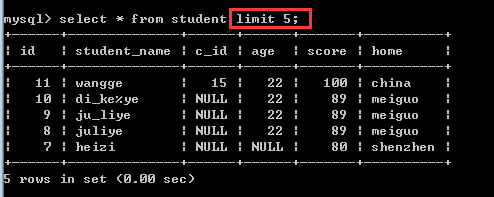
limit就是限制的意思,所以,limit子句的作用就是限制查询记录的条数!
语法
limit offset,length
其中,offset是指偏移量,默认为0,而length是指需要显示的记录数!
思考:
limit子句为什么排在最后?
因为前面所有的限制条件都处理完了,只剩下需要显示多少条记录的问题了!
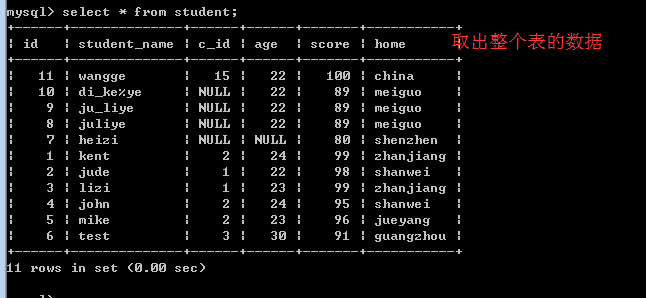
思考:
假如现在想显示记录的第4条到第8条,limit子句应该怎么写?
limit 3,5;
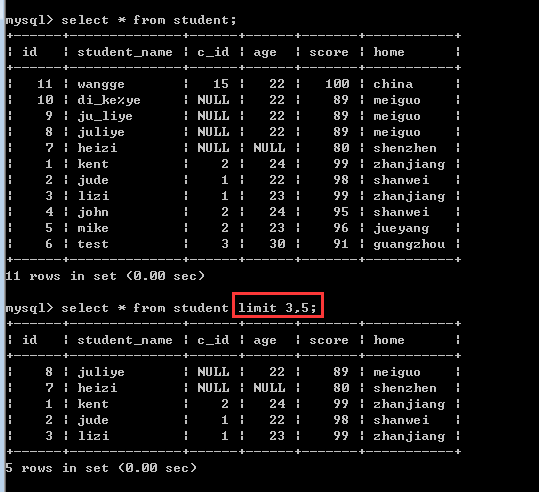
注意:这里的偏移量offset可以省略的!缺省值就代表0!
分页原理
假如在项目中,需要使用分页的效果,就应该使用limit子句!
比如,每页显示10条记录:
第1页:limit 0,10
第2页:limit 10,10
第3页:limit 20,10
如果用$pageNum代表第多少页,用$rowsPerPage代表每页显示的长度
limit ($pageNum - 1)*$rowsPerPage, $rowsPerPage
Mysql查询语句的 where子句、group by子句、having子句、order by子句、limit子句的更多相关文章
- MYSQL查询语句优化
mysql的性能优化包罗甚广: 索引优化,查询优化,查询缓存,服务器设置优化,操作系统和硬件优化,应用层面优化(web服务器,缓存)等等.这里的记录的优化技巧更适用于开发人员,都是从网络上收集和自己整 ...
- MYSQL查询语句大全集锦
MYSQL查询语句大全集锦 1:使用SHOW语句找出在服务器上当前存在什么数据库: mysql> SHOW DATABASES; 2:2.创建一个数据库MYSQLDATA mysql> C ...
- mysql查询语句的执行顺序(重点)
一 SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOI ...
- php面试专题---MYSQL查询语句优化
php面试专题---MYSQL查询语句优化 一.总结 一句话总结: mysql的性能优化包罗甚广: 索引优化,查询优化,查询缓存,服务器设置优化,操作系统和硬件优化,应用层面优化(web服务器,缓存) ...
- mysql 查询语句的执行顺序(重重点)
一 SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOI ...
- mysql查询语句集
1. mysql 查询出某字段的值不为空的语句 1.不为空 select * from table where id <> ""; select * from tabl ...
- [转]MySQL查询语句执行过程详解
Mysql查询语句执行原理 数据库查询语句如何执行?语法分析:首先进行语法分析,对使用sql表示的查询进行语法分析,生成查询语法分析树.语义检查:检查sql中所涉及的对象以及是否在数据库中存在,用户是 ...
- MySQL查询语句执行过程及性能优化(JOIN/ORDER BY)-图
http://blog.csdn.net/iefreer/article/details/12622097 MySQL查询语句执行过程及性能优化-查询过程及优化方法(JOIN/ORDER BY) 标签 ...
- mysql查询语句,通过limit来限制查询的行数。
mysql查询语句,通过limit来限制查询的行数. 例如: select name from usertb where age > 20 limit 0, 1; //限制从第一条开始,显示1条 ...
- MySQL查询语句执行过程及性能优化-基本概念和EXPLAIN语句简介
网站或服务的性能关键点很大程度在于数据库的设计(假设你选择了合适的语言开发框架)以及如何查询数据上. 我们知道MySQL的性能优化方法,一般有建立索引.规避复杂联合查询.设置冗余字段.建立中间表.查询 ...
随机推荐
- GB2312,GBK,GB18030,UTF8四种汉字编码标准有什么差别和联系
从GB2312.GBK 到 GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有同样的编码,后面的标准支持很多其它的字符.在这些编码中,英文和中文能够统一地处理. 区分中文编 ...
- TC SRM 582 DIV 2
Rating又跌了,第二个题,没想好就乱开始乱写了.. 我写乱搞贪心,没过...如果总人数很多judge函数写的不好,DIV2数据很水,直接暴力就行. #include <cstring> ...
- python day- 6 is 和 ==的区别 encode 和 decode
1.is 和 == 的区别. == 是由来判断左右两边的内容是否相等. is 是用来判断内存地址是否相同. 引进 id ( )函数 小数据池: 对于字符串 ,数字 ,bool 值进行 id()计 ...
- Lambda Architecture
Lambda Architecture » λ lambda-architecture.net http://lambda-architecture.net/ Twitter's tweets ana ...
- React创建组件的三种方式比较和入门实例
推荐文章: https://www.cnblogs.com/wonyun/p/5930333.html 创建组件的方式主要有: 1.function 方式 2.class App extends Re ...
- js Date.parse()兼容性问题
最近在做一个日历控件,网上copy了一段代码然后自己又改改. 标准浏览器下正常,结果ie全部不支持,搞不懂,原来Date.parse在IE下有兼容性问题 //beginData格式为'yyyy-mm- ...
- POJ1459 Power Network —— 最大流
题目链接:https://vjudge.net/problem/POJ-1459 Power Network Time Limit: 2000MS Memory Limit: 32768K Tot ...
- 花式GCD
#include<iostream> #include<stdio.h> #include<string.h> #include<algorithm> ...
- [SHOI 2009] 会场预约
[题目链接] https://www.lydsy.com/JudgeOnline/problem.php?id=2028 [算法] 直接用std :: set维护即可 时间复杂度 : O(NlogN) ...
- web项目中url-pattern改成'/'后,js、css、图片等静态资源(404)无法访问问题解决办法
感谢http://blog.csdn.net/this_super/article/details/7884383的文章 1.增加静态资源url映射 如Tomcat, Jetty, JBoss, Gl ...