MySQL集群之五大常见的MySQL高可用方案(转)
1. 概述
我们在考虑MySQL数据库的高可用的架构时,主要要考虑如下几方面:
- 如果数据库发生了宕机或者意外中断等故障,能尽快恢复数据库的可用性,尽可能的减少停机时间,保证业务不会因为数据库的故障而中断。
- 用作备份、只读副本等功能的非主节点的数据应该和主节点的数据实时或者最终保持一致。
- 当业务发生数据库切换时,切换前后的数据库内容应当一致,不会因为数据缺失或者数据不一致而影响业务。
关于对高可用的分级在这里我们不做详细的讨论,这里只讨论常用高可用方案的优缺点以及高可用方案的选型。
2. 高可用方案
2.1. 主从或主主半同步复制
使用双节点数据库,搭建单向或者双向的半同步复制。在5.7以后的版本中,由于lossless replication、logical多线程复制等一些列新特性的引入,使得MySQL原生半同步复制更加可靠。
常见架构如下:
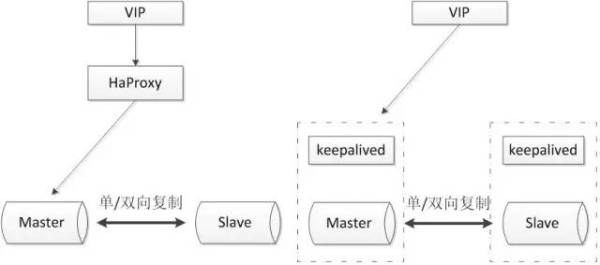
通常会和proxy、keepalived等第三方软件同时使用,即可以用来监控数据库的健康,又可以执行一系列管理命令。如果主库发生故障,切换到备库后仍然可以继续使用数据库。
优点:
- 架构比较简单,使用原生半同步复制作为数据同步的依据;
- 双节点,没有主机宕机后的选主问题,直接切换即可;
- 双节点,需求资源少,部署简单;
缺点:
- 完全依赖于半同步复制,如果半同步复制退化为异步复制,数据一致性无法得到保证;
- 需要额外考虑haproxy、keepalived的高可用机制。
2.2. 半同步复制优化
半同步复制机制是可靠的。如果半同步复制一直是生效的,那么便可以认为数据是一致的。但是由于网络波动等一些客观原因,导致半同步复制发生超时而切换为异步复制,那么这时便不能保证数据的一致性。所以尽可能的保证半同步复制,便可提高数据的一致性。
该方案同样使用双节点架构,但是在原有半同复制的基础上做了功能上的优化,使半同步复制的机制变得更加可靠。
可参考的优化方案如下:
2.2.1. 双通道复制

半同步复制由于发生超时后,复制断开,当再次建立起复制时,同时建立两条通道,其中一条半同步复制通道从当前位置开始复制,保证从机知道当前主机执行的进度。另外一条异步复制通道开始追补从机落后的数据。当异步复制通道追赶到半同步复制的起始位置时,恢复半同步复制。
2.2.2. binlog文件服务器
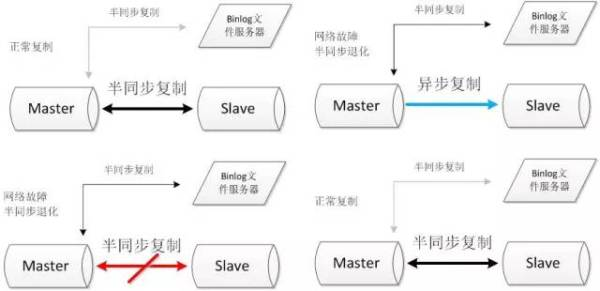
搭建两条半同步复制通道,其中连接文件服务器的半同步通道正常情况下不启用,当主从的半同步复制发生网络问题退化后,启动与文件服务器的半同步复制通道。当主从半同步复制恢复后,关闭与文件服务器的半同步复制通道。
优点:
- 双节点,需求资源少,部署简单;
- 架构简单,没有选主的问题,直接切换即可;
- 相比于原生复制,优化后的半同步复制更能保证数据的一致性。
缺点:
- 需要修改内核源码或者使用mysql通信协议。需要对源码有一定的了解,并能做一定程度的二次开发。
- 依旧依赖于半同步复制,没有从根本上解决数据一致性问题。
2.3. 高可用架构优化
将双节点数据库扩展到多节点数据库,或者多节点数据库集群。可以根据自己的需要选择一主两从、一主多从或者多主多从的集群。
由于半同步复制,存在接收到一个从机的成功应答即认为半同步复制成功的特性,所以多从半同步复制的可靠性要优于单从半同步复制的可靠性。并且多节点同时宕机的几率也要小于单节点宕机的几率,所以多节点架构在一定程度上可以认为高可用性是好于双节点架构。
但是由于数据库数量较多,所以需要数据库管理软件来保证数据库的可维护性。可以选择MMM、MHA或者各个版本的proxy等等。常见方案如下:
2.3.1. MHA+多节点集群
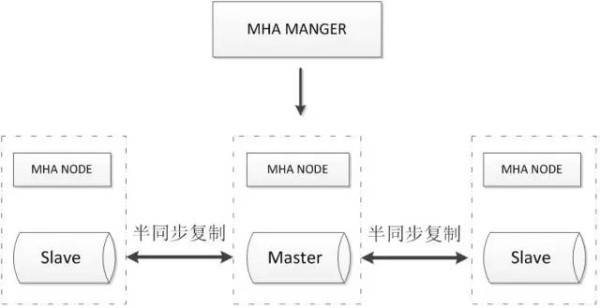
MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master,整个故障转移过程对应用程序完全透明。
MHA Node运行在每台MySQL服务器上,主要作用是切换时处理二进制日志,确保切换尽量少丢数据。
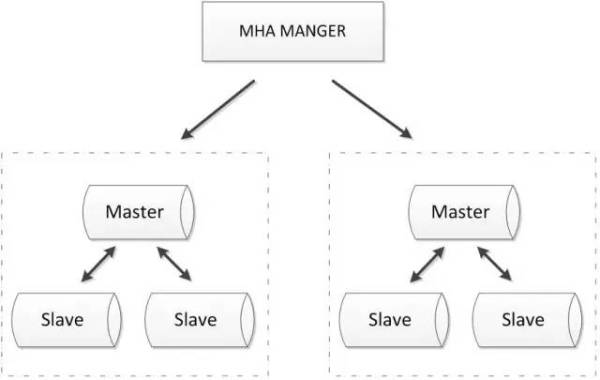
MHA也可以扩展到如下的多节点集群:
优点:
- 可以进行故障的自动检测和转移;
- 可扩展性较好,可以根据需要扩展MySQL的节点数量和结构;
- 相比于双节点的MySQL复制,三节点/多节点的MySQL发生不可用的概率更低
缺点:
- 至少需要三节点,相对于双节点需要更多的资源;
- 逻辑较为复杂,发生故障后排查问题,定位问题更加困难;
- 数据一致性仍然靠原生半同步复制保证,仍然存在数据不一致的风险;
- 可能因为网络分区发生脑裂现象;
2.3.2. zookeeper+proxy
Zookeeper使用分布式算法保证集群数据的一致性,使用zookeeper可以有效的保证proxy的高可用性,可以较好的避免网络分区现象的产生。
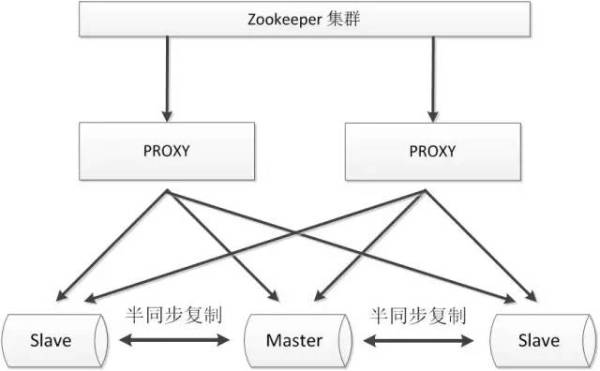
优点:
- 较好的保证了整个系统的高可用性,包括proxy、MySQL;
- 扩展性较好,可以扩展为大规模集群;
缺点:
- 数据一致性仍然依赖于原生的mysql半同步复制;
- 引入zk,整个系统的逻辑变得更加复杂;
2.4. 共享存储
共享存储实现了数据库服务器和存储设备的解耦,不同数据库之间的数据同步不再依赖于MySQL的原生复制功能,而是通过磁盘数据同步的手段,来保证数据的一致性。
2.4.1. SAN共享储存
SAN的概念是允许存储设备和处理器(服务器)之间建立直接的高速网络(与LAN相比)连接,通过这种连接实现数据的集中式存储。常用架构如下:
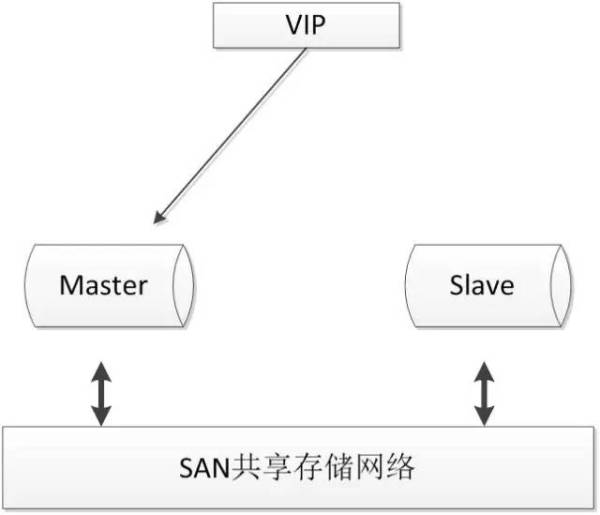
使用共享存储时,MySQL服务器能够正常挂载文件系统并操作,如果主库发生宕机,备库可以挂载相同的文件系统,保证主库和备库使用相同的数据。
优点:
- 两节点即可,部署简单,切换逻辑简单;
- 很好的保证数据的强一致性;
- 不会因为MySQL的逻辑错误发生数据不一致的情况;
缺点:
- 需要考虑共享存储的高可用;
- 价格昂贵;
2.4.2. DRBD磁盘复制
DRBD是一种基于软件、基于网络的块复制存储解决方案,主要用于对服务器之间的磁盘、分区、逻辑卷等进行数据镜像,当用户将数据写入本地磁盘时,还会将数据发送到网络中另一台主机的磁盘上,这样的本地主机(主节点)与远程主机(备节点)的数据就可以保证实时同步。常用架构如下:
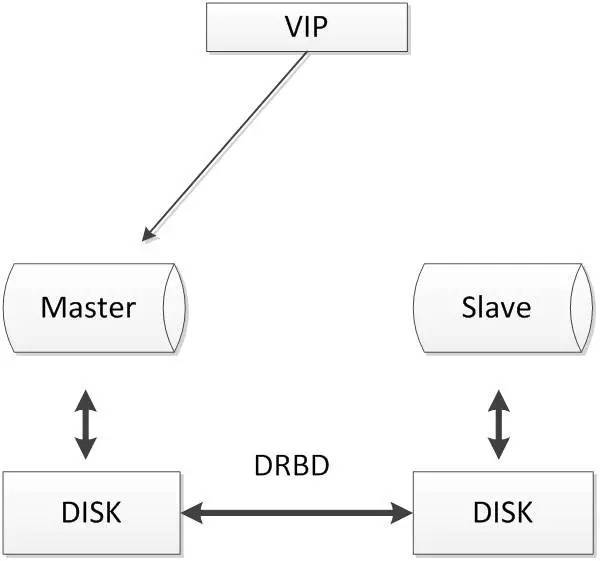
当本地主机出现问题,远程主机上还保留着一份相同的数据,可以继续使用,保证了数据的安全。
DRBD是linux内核模块实现的快级别的同步复制技术,可以与SAN达到相同的共享存储效果。
优点:
- 两节点即可,部署简单,切换逻辑简单;
- 相比于SAN储存网络,价格低廉;
- 保证数据的强一致性;
缺点:
- 对io性能影响较大;
- 从库不提供读操作;
2.5. 分布式协议
分布式协议可以很好解决数据一致性问题。比较常见的方案如下:
2.5.1. MySQL cluster
MySQL cluster是官方集群的部署方案,通过使用NDB存储引擎实时备份冗余数据,实现数据库的高可用性和数据一致性。
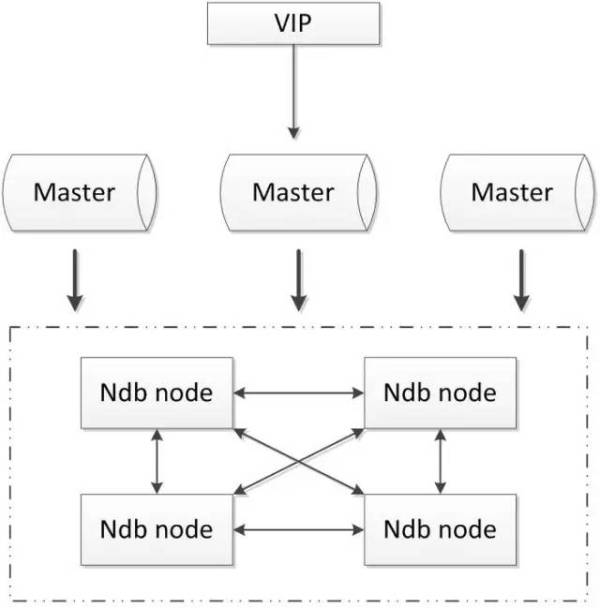
优点:
- 全部使用官方组件,不依赖于第三方软件;
- 可以实现数据的强一致性;
缺点:
- 国内使用的较少;
- 配置较复杂,需要使用NDB储存引擎,与MySQL常规引擎存在一定差异;
- 至少三节点;
2.5.2. Galera
基于Galera的MySQL高可用集群, 是多主数据同步的MySQL集群解决方案,使用简单,没有单点故障,可用性高。常见架构如下:
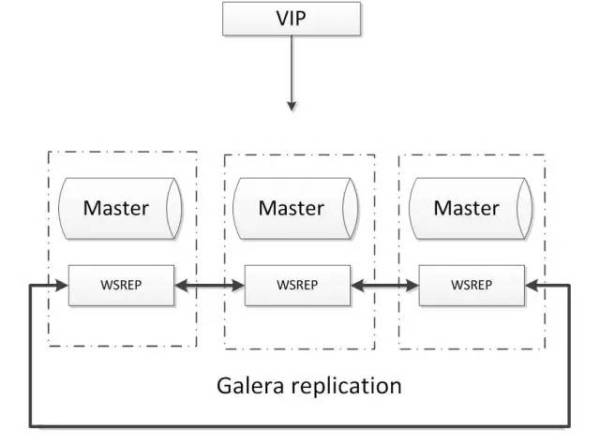
优点:
- 多主写入,无延迟复制,能保证数据强一致性;
- 有成熟的社区,有互联网公司在大规模的使用;
- 自动故障转移,自动添加、剔除节点;
缺点:
- 需要为原生MySQL节点打wsrep补丁
- 只支持innodb储存引擎
- 至少三节点;
2.5.3. POAXS
Paxos 算法解决的问题是一个分布式系统如何就某个值(决议)达成一致。这个算法被认为是同类算法中最有效的。Paxos与MySQL相结合可以实现在分布式的MySQL数据的强一致性。常见架构如下

优点:
- 多主写入,无延迟复制,能保证数据强一致性;
- 有成熟理论基础;
- 自动故障转移,自动添加、剔除节点;
缺点:
- 只支持innodb储存引擎
- 至少三节点;
3. 总结
随着人们对数据一致性的要求不断的提高,越来越多的方法被尝试用来解决分布式数据一致性的问题,如MySQL自身的优化、MySQL集群架构的优化、Paxos、Raft、2PC算法的引入等等。
而使用分布式算法用来解决MySQL数据库数据一致性的问题的方法,也越来越被人们所接受,一系列成熟的产品如PhxSQL、MariaDB Galera Cluster、Percona XtraDB Cluster等越来越多的被大规模使用。
随着官方MySQL Group Replication的GA,使用分布式协议来解决数据一致性问题已经成为了主流的方向。期望越来越多优秀的解决方案被提出,MySQL高可用问题可以被更好的解决。
参考文献
[2015 OTN]彭立勋-DoubleBinlog方案.pdf
参考:
https://zhuanlan.zhihu.com/p/25960208(以上内容转自此篇文章)
MySQL集群之五大常见的MySQL高可用方案(转)的更多相关文章
- MySQL集群搭建(6)-双主+keepalived高可用
双主 + keepalived 是一个比较简单的 MySQL 高可用架构,适用于中小 MySQL 集群,今天就说说怎么用 keepalived 做 MySQL 的高可用. 1 概述 1.1 keepa ...
- Dubbo入门到精通学习笔记(十四):ActiveMQ集群的安装、配置、高可用测试,ActiveMQ高可用+负载均衡集群的安装、配置、高可用测试
文章目录 ActiveMQ 高可用集群安装.配置.高可用测试( ZooKeeper + LevelDB) ActiveMQ高可用+负载均衡集群的安装.配置.高可用测试 准备 正式开始 ActiveMQ ...
- Dubbo入门到精通学习笔记(十三):ZooKeeper集群的安装、配置、高可用测试、升级、迁移
文章目录 ZooKeeper集群的安装.配置.高可用测试 ZooKeeper 与 Dubbo 服务集群架构图 1. 修改操作系统的/etc/hosts 文件,添加 IP 与主机名映射: 2. 下载或上 ...
- Dubbo入门到精通学习笔记(二十):MyCat在MySQL主从复制的基础上实现读写分离、MyCat 集群部署(HAProxy + MyCat)、MyCat 高可用负载均衡集群Keepalived
文章目录 MyCat在MySQL主从复制的基础上实现读写分离 一.环境 二.依赖课程 三.MyCat 介绍 ( MyCat 官网:http://mycat.org.cn/ ) 四.MyCat 的安装 ...
- 使用Haproxy代理rabbitmq集群,用keepalive保证haproxy高可用
原文地址:https://www.jianshu.com/p/440b8e1d5339 使用Haproxy代理rabbitmq集群 上一篇文章教了rabbitmq集群搭建.但是这样搭建出来的集群是3个 ...
- 分布式架构高可用架构篇_01_zookeeper集群的安装、配置、高可用测试
参考: 龙果学院http://www.roncoo.com/share.html?hamc=hLPG8QsaaWVOl2Z76wpJHp3JBbZZF%2Bywm5vEfPp9LbLkAjAnB%2B ...
- ZooKeeper集群的安装、配置、高可用测试
Dubbo注册中心集群Zookeeper-3.4.6 Dubbo建议使用Zookeeper作为服务的注册中心. Zookeeper集群中只要有过半的节点是正常的情况下,那么整个集群对外就是可用的.正是 ...
- 集群相关、用keepalived配置高可用集群
1.集群相关 2.keepalived相关 3.用keepalived配置高可用集群 安装:yum install keepalived -y 高可用,主要是针对于服务器硬件或服务器上的应用服务而 ...
- Linux 笔记 - 第十八章 Linux 集群之(一)Keepalived 高可用集群
一.前言 Linux 集群从功能上可以分为两大类:高可用集群和负载均衡集群.此处只讲高可用集群,负载均衡放在下一篇博客讲解. 高可用集群(High Availability Cluster,简称 HA ...
随机推荐
- css中display设置为table、table-row、table-cell后的作用及其注意点
html: <div class="table"> <div class="row"> <div class="cell ...
- shiro 通过jdbc连接数据库
本文介绍shiro通过jdbc连接数据库,连接池采用阿里巴巴的druid的连接池 参考文档:https://www.w3cschool.cn/shiro/xgj31if4.html https://w ...
- oracle 时间格式转化以及计算
--A表中的日期字段 create_date 例如:2017-08-05 转化为2017年8月5日 oracle 在这里的双引号会忽略 select to_char(to_date(tt.c ...
- iOS Programming View Controllers 视图控制器
iOS Programming View Controllers 视图控制器 1.1 A view controller is an instance of a subclass of UIVi ...
- ASP.NET Excel下载方法一览
方法一 通过GridView(简评:方法比较简单,但是只适合生成格式简单的Excel,且无法保留VBA代码),页面无刷新 aspx.cs部分 using System; using System.Co ...
- Node.js——基本服务开启
标注模式 var http = require('http'); var server = http.createServer(); server.on('request', function (re ...
- 解决国内无法安装android sdk的问题
在使用 Android SDK Manager 的时候,主要会连接到两个地址 dl.google.com 和 dl-ssl.google.com,key发现这两个地址都是无法正常访问的,如何解决呢? ...
- Java Socket 连接 Client端 和 Server端
Client端: import java.io.DataInputStream;import java.io.DataOutputStream;import java.io.IOException;i ...
- 迅为7寸Android嵌入式安卓触摸屏,工业一体机方案
嵌入式安卓触摸屏板卡介绍-工业级核心板: 嵌入式安卓触摸屏功能接口介绍: 品质保障: 核心板连接器:进口连接器,牢固耐用,国产连接器无法比拟(为保证用户自行设计的产品品质,购买核心板用户可免费赠送底板 ...
- 迅为4412全新升级版|3G开发板|4G开发板
iTOP-Exynos4412开发板采用 Exynos4412的主芯片,具有更高的主频和更丰富外设,配置 2GB 双通道 DDR3的内存及 16GB 存储,支持3G/G模块.GPS模块.陀螺仪.HDM ...