day1--大数据概念,hadoop介绍,hdfs整体运行机制
1、什么是大数据
基本概念
在互联网技术发展到现今阶段,大量日常、工作等事务产生的数据都已经信息化,人类产生的数据量相比以前有了爆炸式的增长,以前的传统的数据处理技术已经无法胜任,需求催生技术,一套用来处理海量数据的软件工具应运而生,这就是大数据!
换个角度说,大数据是:
1、有海量的数据
2、有对海量数据进行挖掘的需求
3、有对海量数据进行挖掘的软件工具(hadoop、spark、storm、flink、tez、impala......)
大数据在现实生活中的具体应用
电商推荐系统:基于海量的浏览行为、购物行为数据,进行大量的算法模型的运算,得出各类推荐结论,以供电商网站页面来为用户进行商品推荐
精准广告推送系统:基于海量的互联网用户的各类数据,统计分析,进行用户画像(得到用户的各种属性标签),然后可以为广告主进行有针对性的精准的广告投放
2、什么是hadoop
hadoop中有3个核心组件:
分布式文件系统:HDFS —— 实现将文件分布式存储在很多的服务器上
分布式运算编程框架:MAPREDUCE —— 实现在很多机器上分布式并行运算
分布式资源调度平台:YARN —— 帮用户调度大量的mapreduce程序,并合理分配运算资源
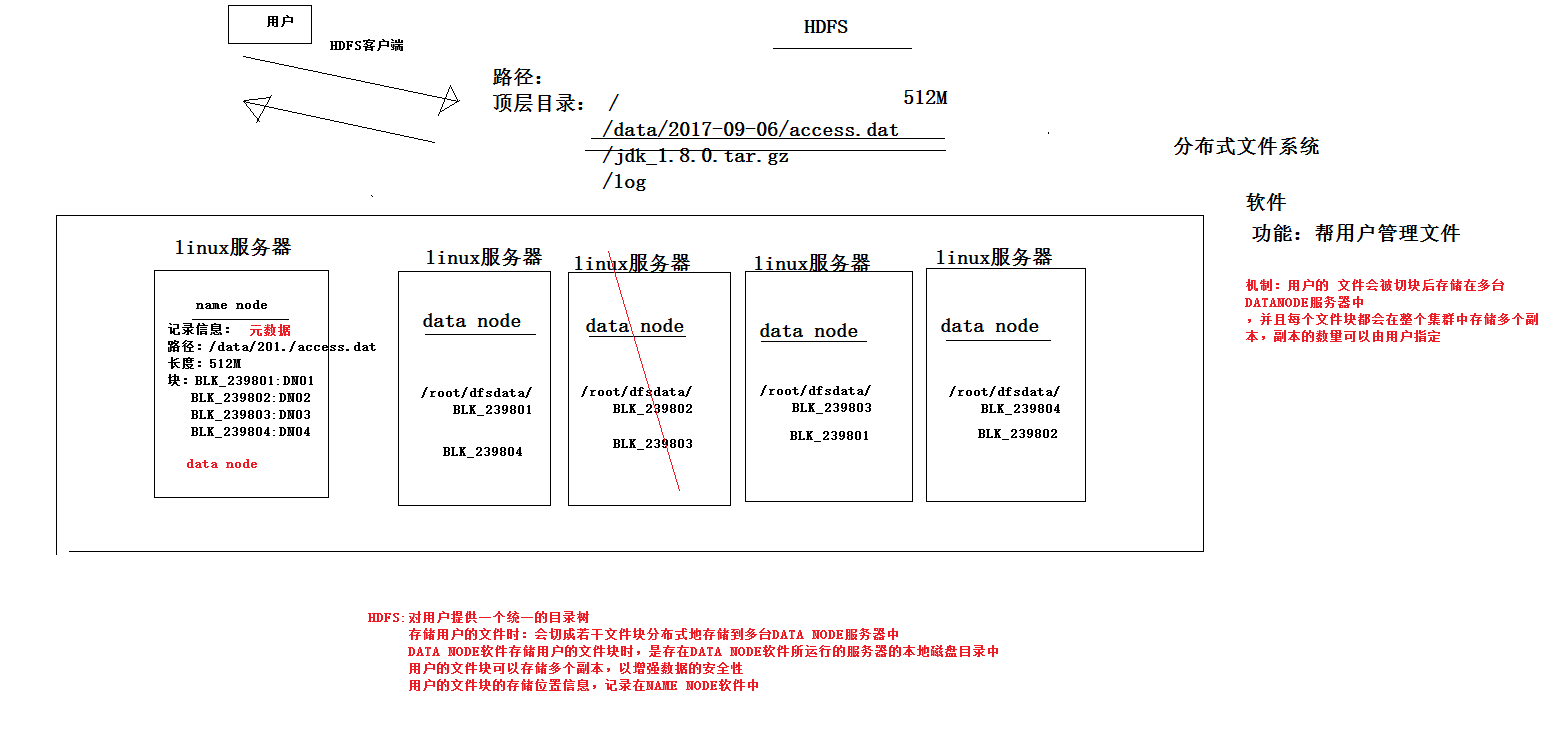
3、hdfs整体运行机制
hdfs:分布式文件系统
hdfs有着文件系统共同的特征:
1、有目录结构,顶层目录是: /
2、系统中存放的就是文件
3、系统可以提供对文件的:创建、删除、修改、查看、移动等功能
hdfs跟普通的单机文件系统有区别:
1、单机文件系统中存放的文件,是在一台机器的操作系统中
2、hdfs的文件系统会横跨N多的机器
3、单机文件系统中存放的文件,是在一台机器的磁盘上
4、hdfs文件系统中存放的文件,是落在n多机器的本地单机文件系统中(hdfs是一个基于linux本地文件系统之上的文件系统)
hdfs的工作机制:
1、客户把一个文件存入hdfs,其实hdfs会把这个文件切块后,分散存储在N台linux机器系统中(负责存储文件块的角色:data node)<准确来说:切块的行为是由客户端决定的>
2、一旦文件被切块存储,那么,hdfs中就必须有一个机制,来记录用户的每一个文件的切块信息,及每一块的具体存储机器(负责记录块信息的角色是:name node)
3、为了保证数据的安全性,hdfs可以将每一个文件块在集群中存放多个副本(到底存几个副本,是由当时存入该文件的客户端指定的)
综述:一个hdfs系统,由一台运行了namenode的服务器,和N台运行了datanode的服务器组成!

day1--大数据概念,hadoop介绍,hdfs整体运行机制的更多相关文章
- 大数据笔记04:大数据之Hadoop的HDFS(基本概念)
1.HDFS是什么? Hadoop分布式文件系统(HDFS),被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点. 2.HDFS ...
- 大数据:Hadoop(HDFS 的设计思路、设计目标、架构、副本机制、副本存放策略)
一.HDFS 的设计思路 1)思路 切分数据,并进行多副本存储: 2)如果文件只以多副本进行存储,而不进行切分,会有什么问题 缺点 不管文件多大,都存储在一个节点上,在进行数据处理的时候很难进行并行处 ...
- 大数据笔记07:大数据之Hadoop的HDFS(特点)
1. HDFS的特点: (1)数据冗余,硬件容错 (2)流式的数据访问(写一次读多次,不能直接修改已写入的数据,只能删除之后再去写入) (3)存储大文件 2. HDFS适用性和局限性 适用性:(1)适 ...
- 大数据:Hadoop(HDFS 读写数据流程及优缺点)
一.HDFS 写数据流程 写的过程: CLIENT(客户端):用来发起读写请求,并拆分文件成多个 Block: NAMENODE:全局的协调和把控所有的请求,提供 Block 存放在 DataNode ...
- 大数据笔记05:大数据之Hadoop的HDFS(数据管理策略)
HDFS中数据管理与容错 1.数据块的放置 每个数据块3个副本,就像上面的数据库A一样,这是因为数据在传输过程中任何一个节点都有可能出现故障(没有办法,廉价机器就是这样的) ...
- 大数据笔记06:大数据之Hadoop的HDFS(文件的读写操作)
1. 首先我们看一看文件读取: (1)客户端(java程序.命令行等等)向NameNode发送文件读取请求,请求中包含文件名和文件路径,让NameNode查询元数据. (2)接着,NameNode返回 ...
- 大数据笔记09:大数据之Hadoop的HDFS使用
1. HDFS使用: HDFS内部中提供了Shell接口,所以我们可以以命令行的形式操作HDFS
- 大数据学习之路-hdfs
1.什么是hadoop hadoop中有3个核心组件: 分布式文件系统:HDFS —— 实现将文件分布式存储在很多的服务器上 分布式运算编程框架:MAPREDUCE —— 实现在很多机器上分布式并行运 ...
- 大数据和Hadoop平台介绍
大数据和Hadoop平台介绍 定义 大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获.管理和处理的数据集.这些困难包括数据的收入.存储.搜索.共享.分析和 ...
随机推荐
- workstation服务丢失 共享打不开 0x80070035
这个问题困扰一个星期了,希望能帮到人.
- c# winform如何屏蔽键盘上下左右键
重写事件: protected override bool ProcessDialogKey(Keys keyData) { if (keyData == Keys.Up || keyData == ...
- 洛谷 P1886 滑动窗口 (数据与其他网站不同。。)
题目描述 现在有一堆数字共N个数字(N<=10^6),以及一个大小为k的窗口.现在这个从左边开始向右滑动,每次滑动一个单位,求出每次滑动后窗口中的最大值和最小值. 例如: The array i ...
- CAD交互绘制带颜色宽度的直线(com接口)
用户可以在控件视区任意位置绘制直线. 主要用到函数说明: _DMxDrawX::DrawLine 绘制一个直线.详细说明如下: 参数 说明 DOUBLE dX1 直线的开始点x坐标 DOUBLE dY ...
- 01Hibernate
Hibernate Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自 ...
- Mysql--查询相关语句总结
一.查询各个部门的最高工资及姓名,其中薪资字段是字符串类型: 优化前: SELECT *FROM (SELECT a.`deptno`, a.`sal`, a.`ename` FROM emp a O ...
- 树莓派 -- i2c学习 续(1) DeviceTree Overlay实例化rtc
上文中讨论了通过sysfs来实例化i2c设备 (rtc ds3231) https://blog.csdn.net/feiwatson/article/details/81048616 本文继续看看如 ...
- 每周一赛(E题,广搜求方案)
Description In this problem, you are given an integer number s. You can transform any integer number ...
- Linux 文件与目录结构
[Linux文件] Linux 系统中一切皆文件. [Linux目录结构] --/bin 是Binary的缩写, 这个目录存放着最经常使用的命令. --/sbin s就是Super User的意思,这 ...
- Qt Widgets Application可执行程序发布方式
前言 写好的Qt程序想打包发布,之前按照Qt快速入门系列教程里的方法,直接选release,构建,之后找到exe,拷贝几个dll,然而报错如图: 后来找到教程:http://tieba.baidu.c ...