java数据结构和算法09(哈希表)
树的结构说得差不多了,现在我们来说说一种数据结构叫做哈希表(hash table),哈希表有是干什么用的呢?我们知道树的操作的时间复杂度通常为O(logN),那有没有更快的数据结构?当然有,那就是哈希表;
1.哈希表简介
哈希表(hash table)是一种数据结构,提供很快速的插入和查找操作(有的时候甚至删除操作也是),时间复杂度为O(1),对比时间复杂度就可以知道哈希表比树的效率快得多,并且哈希表的实现也相对容易,然而没有任何一种数据结构是完美的,哈希表也是;哈希表最大的缺陷就是基于数组,因为数组初始化的时候大小是确定的,数组创建后扩展起来比较困难;
当哈希表装满了之后,就要把数据转移到一个更大的哈希表中,这会很费时间,而且哈希表不支持有顺序的遍历,因为从哈希表中遍历数据是随机的;所以我们使用哈希表的前提是:不需要有序的遍历数据,可以大概知道数据量的多少;满足这两点就可以用哈希表;
那有人就要问了,说得这么厉害,哈希表到底是什么样子的啊?下面就随便说两个吧。。。
很经典的例子就是英语字典,我们查字典的时候可以根据这个单词就可以找到第xxx页,在这里该单词和页数就对应起来了,这可以说是一个哈希表;
再举个现实中的例子,在上学的时候每个人在学校里都会有一个学号,你这个人在学校中就对应这个学号,假如校长手上有一个记录全校学生的表,然后根据学号找一个学生时,就能很快锁定这个学生的姓名,性别,班级等信息;有没有想过假如没有学号的话,校长想找一个学生就只能根据姓名去找,可是同名同姓的人这么多,想找到目标学生不是一件容易的事。。。。。
ok,在这里哈希表可以看作是校长手上的那个表(其实就是一个数组),我们根据我们要存的信息生成一个表中的位置的号码(在这里这个号码就是数组的下标),根据这个号码我们就知道该数据存在数组的哪个位置,然后将数据保存进去就可以了;假如有个大小为20的数组,我要存“aaa”,我们可以想个很厉害的办法将这个字符串变成一个比较小的数字,比如是10,那么就把这个字符串存到数组的第10个位置,这样做的好处就是下次如果要从哈希表中查询(或删除)“aaa”这个字符串时,只需要将“aaa”字符串算出那个号码10,然后直接去数组中第10个位置找一个看有没有这个字符串,是不是很简单啊!
所以现在我们需要解决的就是想个很厉害的办法可以将字符串变成一个比较小的数字(这个过程叫做哈希化),还要保证这个数字不能超过数组的最大边界!
2 哈希化
哈希化就是想办法将我们要保存的数据对应一个数组下标,在数组的该位置下保存数据;我们可以把这个过程专业一点的说一下:把要保存的数据,通过哈希函数转化为对应的数组下标;现在我们的目标就是怎么编写一个哈希函数可以使得字符串变成数组下标;
这里我们可以假设一个字符串t数组的大小为30,String[] str = new String[30]; 要存“cats”这个单词,最容易想到的办法就是用ASCII码,但是由于ASCII码太多了不好记,于是我们可以自己设置一套规则,我就假设a到z分别对应1到26,外加空格对应0,现在一套最简陋的规则就出来了,我那么“cats”这个单词:c = 3,a = 1,t = 20,s = 19,现在“cats”有两种办法变成数组的下标;
额外补充一下:假如我们要保存的字符串有50个,那么我们new的数组大小一定要是它的两倍大,即 new String[100];,后面会说到这个原因
2.1哈希函数实现一
怎么实现比较好呢?别想那么多,直接相加就好,3+1+20+19 = 43,这个时候就有个小问题,我们的数组的大小为30,也就是说数组下标最大值是29,而这里我们的数字为43,怎么将43变成29以内的数(包括29)呢?因为任何数除以30的余数只都在0-29之间,于是我们用43除以30拿到余数13,那么我们就把”cats“放到数组下标为13的位置,str[13] = "cats";
这种哈希函数的实现很容易,但是往往越容易的东西缺点就越大,最大的缺陷就是有很多单词变成数字是相同的,比如was,tin,give等100多个单词变成数字后都是43,然后我们恰巧添加单词的时候就是这些单词,现在问题来了,多个单词最后算出来的数组下标很大概率上是一样的,也就是数组一个位置要放多个数据,怎么解决这个问题呢?我们可以换一种哈希函数的实现来降低这个概率
2.2 哈希函数实现二
由2.1可以知道太多的单词变成数字的结果是一样的,那么我们就要想办法为每一个单词都对应一个独一无二的整数,然后用这个整数除以数组的大小取余数,就可以知道该单词在数组中的存放位置;
于是啊,我们可以利用幂的连乘来得到这个独一无二的整数,比如“cats”用这种计算方法:3*273+1*272+20*271+19*270,有点类似二进制变成十进制,通过这个算法,可以得到一个独一无二的整数,其他的任何单词通过这种方法算出来的结果几乎是不可能相等的,有兴趣的可以试试;然后将这个计算结果除以30取余数,就可以得到一个数组的位置,然后将该字符串丢到里面即可;

不知道大家有没有发现这种方法的一个问题,因为数组的大小是一定的,而且我们是通过取余数来得到数组的位置,那么问题来了,即使是两个不相同的整数分别除以30,最后的余数是相等的;
就比如有两个字符串通过幂的连乘最后得到32和62(当然我们这里肯定不会得到这两个整数,为了好理解随便拿两个数),虽然这两个数是独一无二的,但是除以30余数都为2,那么两个数据要保存到哈希表中肯定会有冲突,下后面我们来解决一下这个冲突;
有个简单的哈希函数实现看一下(虽然还可以进行修改一下,但是这个已经差不多了);


3.冲突
冲突的原因就是两个独一无二的整数除以数组的大小,取余数是相等的,而数组中一个位置只能存一个数据,这就导致了冲突,解决冲突的办法有两种;
3.1 解决方法一(开放地址法)
还记得前面说过数组的大小要为实际数量的两倍吗?就是为了这个时候用的,假如一个单词已经放在了数组的第15个位置那里,另外一个单词本来也要放在第15的位置,由于这个位置已经被别人占了。那就放在数组的另外一个位置上,反正还有很多数组比较大,这种方式叫做------开放地址法
3.2 解决方法二(链地址法 )
既然有两个数据都要放在数组的一个位置上,那就想办法把第二个数据连在第一个数据后面,通过第一个数据可以找到第二个数据,而数组中只保存第一个数据的地址;其实就是一句话,数组中每个位置放一个链表;
这种方法的好处很明显,完美解决上述冲突,不需要用什么花里胡哨的操作;缺陷就是当链表太长了,我们要查询这个链表的最后面的数据,只能慢慢遍历这个链表,而我们知道,链表的优势是插入和删除,而对于查询这种操作是比较坑爹的,而我们前面用了红黑树这样的结构来完美解决链表的缺点;最后,我们就差不多想到了一个比较实用的方法:数组的每个位置都存放一个链表,当链表的节点很少的时候,那就用链表吧!但是当链表慢慢的变长,当节点数目到达一个界限的时候,我们就把这个链表变成一个红黑树,比较完美的方案,这也叫做------链地址法
顺便一提,jdk7的HashMap就是数组中放链表,即使链表很长也不会变红黑树;jdk8中的HashMap才增加了变红黑树这个操作
4.开放地址法
所谓的开放地址法就是:根据我们要保存的数据计算出来的数组下标的那个位置已经存放了数据,这个时候我们就要再找一个空位置,然后将要保存的数据丢进去即可,那么怎么找比较好呢?这里提供三种方式,线性探测,二次探测和再哈希法,下面就看看这三种方式到底是怎么工作的;
4.1 线程探测
看名字线性就知道是从前往后寻找空的位置,举个很简单的例子,当一个字符串经过运算对应于数组下标为52,然而此时52这个位置上已经有了数据,那么就尝试放到53的位置,假如53的位置也已经放了数据,那就放到54位置,就这样一直往后慢慢找,直到找到一个空的位置就把数据放进去;而此时找的次数越多,假如已经找到56的位置,那么从53到56这么多位置叫做填充序列,当填充序列很长的时候,我们就称为原始聚集,下图所示:

这里填充序列的中有5个填充单元,我们也可以说步数为1,每次探测都是前进一步;我们可以知道当探测的次数越多的时候,说明聚集越严重,下一次再想添加到这个位置的数据的效率就越低;
还有就是当哈希表填充得越满,效率也就越低,所以当哈希表快满了之后就要扩展,而java中数组是不能直接进行扩展的,需要再新建一个数组,然后想办法将这个哈希表中的数据复制到新的数组中,注意,这里不能直接复制,因为新的数组的容量和原来的数组不一样,那么原来哈希表中所有的数据必须要重新哈希化,然后放入到新的数组中,非常耗时....
4.2 二次探测
根据前面我们的线性探测可以知道,假如经过哈希函数计算出来的原始数组下标为x,那么线性探测的位置是x+1,x+2,x+3,x+4.....,;那么 进行二次探测找的位置就是x+12,x+22,x+32,x+42.....其实就是按照步数的平方进行探测看里面有没有数据,没有的话才放进去新的数据,二次探测可以防止聚集太长所导致的效率下降问题;
对于二次探测来说,如果当前计算出来的位置为x,首先会探测x后面一个位置,如果这个位置有数据,那就多往后4个位置看有没有数据,假如还是有数据,那么二次探测可能会觉得你这个聚集特别长,于是这次跳得更远的位置,当前位置后面的16的位置等等,直到最后跳过整个数组, 这样可以避免一个一个的位置慢慢探测的底下效率,二次探测下图所示:
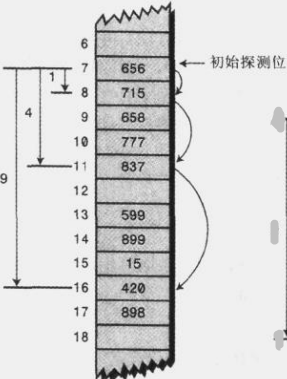
二次探测也有点问题,会导致二次聚集,那什么又是二次聚集呢?其实跟原始聚集差不多吧!比如184,302,420,544这几个整数都要放到哈希表中,而且这几个数经过哈希算法算出来的数组下标都为7,302需要以1步长进行探测,而420要先以1为步长,然后以4步长进行探测,而544要先以1为步长,然后以4为步长,最后以16步长进行探测,假如后面还有数据对应的数组下标为7,那么还是要重复这个步骤,而且是越来越长....这也是一种聚集,个人感觉从某种意义来说和原始聚集性质差不多吧!
二次探测不常用,因为有更好的办法解决,就是再哈希法;
4.3 再哈希法
用再哈希法可以消除原始聚集和二次聚集,那么什么是再哈希法呢?我们可以知道产生原始聚集和二次聚集的原因其实差不多,都是由于多个数据添加到哈希表中的同一个位置,然后根据步长一个一个位置的探测,直到找到一个空的位置,如果需要找的位置特别多,那么这就是聚集,添加的效率的就会大幅度降低;
那么我们就要想一种方法即使多个数据要放在哈希表的同一个位置,但是不需要从头开始一个一个位置的探测,如果每个数据都可以产生一个独一无二的步长那不就好了么!然后直接根据这个步长探测该位置将数据丢进去就ok了;
于是我们准备了两个哈希函数,一个哈希函数就是我们上面说到的可以产生对应的数组下标,另外一个哈希函数可以产生步长,其实就是多个数据放在同一个位置产发生冲突,就用这个哈希函数再次哈希化产生一个步长,根据这个步长进行探测就可以了,而不用每次都从第一个步长开始;比如下面就有一个产生步长的哈希函数,我们可以知道步长的范围是1-constant,注意步长不能为0,否则就原地踏步了。。。

上图中,假如我们往哈希表中添加的数据是数字,那就直接将数据和数组大小取余得到数组下标,这里的key就是我们的数据,constant只要是小于数组容量的一个质数,随便什么都可以
顺便一提:再哈希法使用的前提必须保证数组的容量为一个质数,因为这样才能使得所有位置都被探测到;可以试试假如数组容量为15,步长为5,一个数据经过计算得到额数组下标为0,那么探测的位置应该为:(0+5)%15 = 5,、(5+5)%15 = 10,(10+5)%15 = 0,只会探测0、5、10这三个位置;但是如果数组容量为质数13,步长为5,第一个数据下标还是0,那么探测位置为:(0+5)%13 = 5,、(5+5)%13 = 10,(10+5)%13 = 2、(2+5)%13 = 7,(7+5)%13 = 12,(12+5)%13 = 4,(4+5)%13 = 9等等,可以看到每次探测的位置都不一样,可以探测到数组中所有位置只要有空的就把数据当进去即可;
假如使用的是开放地址法,那么探测序列就用这个再哈希法生成,其实很容易!
5.链地址法
可以看到上面的开放地址法有点麻烦,需要找到探测序列真的是日了狗了,麻烦的我都不想看了,如果可以不用这么麻烦那该多好呀,ok,那就用链地址法吧!就类似下面这样的结构,原始的数组中不直接保存数据,每个位置只是保存第一个数据的引用,通过该位置第一个引用就可以取到后面所有的数据!如果链表太长遍历起来就比较费劲,可以转为红黑树效率就高了很多;
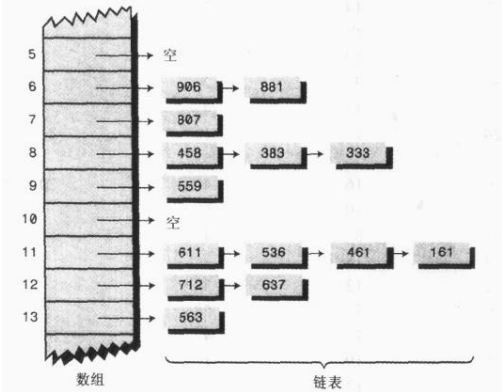
这里其实没什么好说的,因为数组和链表的使用很熟悉了,没什么特别难的东西,基本逻辑:只需要新建一个MyHashTable的类,这个类中有几个属性:一个数组,一个int类型的属性标识数组真实容量的大小;最好有个节点类为静态内部类,这个静态内部类中实现了对链表的增删改查的操作;然后在MyHashTable类中写一个哈希函数的方法,根据这个哈希函数得出来的数组下标,最后对数组的增删改查了!
6.总结
哈希表其实还可以用在外部存储中,也就是硬盘中,有兴趣的可以看看,不过我感觉到这里就差不多了!其实哈希表的内容没多少吧,最主要的就是哈希函数的选取,选择一个好的哈希函数可以使得我们的哈希表的效率更高!然后就是数组中存数据的方式,可以直接在数组中存数据,也可以在数组中存节点的引用,其实吧,知不知道二维数组?在我们这个数组中每个位置存的是另外一个数组的引用,这样其实也行,由于扩展起来很困难,使用链表比使用二维数组好。。。
java数据结构和算法09(哈希表)的更多相关文章
- Java数据结构和算法之哈希表
五.哈希表 一般的线性表.树中,记录在结构中的相对位置是随机的即和记录的关键字之间不存在确定的关系,在结构中查找记录时需进行一系列和关键字的比较.这一类查找方法建立在“比较”的基础上,查找的效率与比较 ...
- 自己动手实现java数据结构(五)哈希表
1.哈希表介绍 前面我们已经介绍了许多类型的数据结构.在想要查询容器内特定元素时,有序向量使得我们能使用二分查找法进行精确的查询((O(logN)对数复杂度,很高效). 可人类总是不知满足,依然在寻求 ...
- Java数据结构与算法(1) - ch02有序表(OrderedArray)
有序表需要掌握的插入方法,删除方法和二分法查找方法. 插入方法: 从前往后找到比要插入的值大的数组项,将该数组项及之后的项均后移一位(从最后一项起依次后移),最后将要插入的值插入当前数组项. 删除方法 ...
- 《Java数据结构与算法》笔记-CH5-链表-4用链表实现堆栈
//用链表实现堆栈 /** * 节点类 */ class LinkS { private long data; public LinkS next; public LinkS(long d) { th ...
- 《Java数据结构与算法》笔记-CH5-链表-3双端链表
/** * 双端链表的实现 */ class LinkA { public long dData; public LinkA next; public LinkA(long d) { dData = ...
- 《Java数据结构与算法》笔记-CH5-链表-2单链表,增加根据关键字查找和删除
/** * Link节点 有数据项和next指向下一个Link引用 */ class Link { private int iData;// 数据 private double dData;// 数据 ...
- 《Java数据结构与算法》笔记-CH5-链表-1单链表
/** * Link节点 * 有数据项和next指向下一个Link引用 */ class Link { private int iData;//数据 private double dData;//数据 ...
- Java数据结构和算法 - 哈希表
Q: 如何快速地存取员工的信息? A: 假设现在要写一个程序,存取一个公司的员工记录,这个小公司大约有1000个员工,每个员工记录需要1024个字节的存储空间,因此整个数据库的大小约为1MB.一般的计 ...
- 【算法】哈希表的诞生(Java)
参考资料 <算法(java)> — — Robert Sedgewick, Kevin Wayne <数据结构> ...
随机推荐
- ubuntu系统apache日志文件的位置
Debian,Ubuntu或Linux Mint上的Apache错误日志位置 默认的错误日志 在基于Debian的Linux上,系统范围的Apache错误日志默认位置是/var/log/apache2 ...
- hasChildNodes()方法,nodeName、nodeValue、nodeType介绍
Document对象的使用:hasChildNodes()方法,nodeName.nodeValue.nodeType的简单介绍 一.hasChildNodes() 说明: (1) 该方法 ...
- pytorch系列 -- 9 pytorch nn.init 中实现的初始化函数 uniform, normal, const, Xavier, He initialization
本文内容:1. Xavier 初始化2. nn.init 中各种初始化函数3. He 初始化 torch.init https://pytorch.org/docs/stable/nn.html#to ...
- java文件上传,自动判断文件类型
public enum FileType { /** * JEPG. */ JPEG("FFD8FF"), /** * PNG. */ PNG("89504E47&quo ...
- layer层次
Core Animation的基本使用(十六) 发表于2013/08/25由juluren layer tree addSublayer: 将层追加到接受者的子层数组中. insertSublayer ...
- HNOI2006 潘多拉的盒子
题目描述 题解: 题目的描述比较长,理解起来也有一定难度.仔细读题后我们发现整个任务可以分成两个部分:找出咒语机之间所有的升级关系.求最长升级序列. 1. 求升级关系: 容易看出,咒语机i可以抽象成一 ...
- MySQL数据库文件
MySQL数据库文件 本文档从MySQL数据库和存储引擎层面介绍各种类型的文件. 参数文件(my.cnf) 错误日志(error log) 二进制日志文件(binary log) 慢查询日志(slow ...
- Ubuntu、CentOS 解决docker命令权限问题(sudo)
#创建docker组 weiyj@ubuntu18:~$ sudo groupadd docker groupadd: group 'docker' already exists #将当前用户加入do ...
- 性能优化 java 24 次阅读 · 读完需要 15 分钟 0
摘要: 技术传播的价值,不仅仅体现在通过商业化产品和开源项目来缩短我们构建应用的路径,加速业务的上线速率,也会体现在优秀程序员在工作效率提升.产品性能优化和用户体验改善等小技巧方面的分享,以提高我们的 ...
- c++_等差素数列
标题:等差素数列 2,3,5,7,11,13,....是素数序列.类似:7,37,67,97,127,157 这样完全由素数组成的等差数列,叫等差素数数列.上边的数列公差为30,长度为6. 2004年 ...