线性回归,logistic回归和一般回归
1 摘要
本报告是在学习斯坦福大学机器学习课程前四节加上配套的讲义后的总结与认识。前四节主要讲述了回归问题,回归属于有监督学习中的一种方法。该方法的核心思想是从连续型统计数据中得到数学模型,然后将该数学模型用于预测或者分类。该方法处理的数据可以是多维的。
讲义最初介绍了一个基本问题,然后引出了线性回归的解决方法,然后针对误差问题做了概率解释。之后介绍了logistic回归。最后上升到理论层次,提出了一般回归。
2 问题引入
假设有一个房屋销售的数据如下:
|
面积(m^2) |
销售价钱(万元) |
|
123 |
250 |
|
150 |
320 |
|
87 |
160 |
|
102 |
220 |
|
… |
… |
这个表类似于北京5环左右的房屋价钱,我们可以做出一个图,x轴是房屋的面积。y轴是房屋的售价,如下:

如果来了一个新的面积,假设在销售价钱的记录中没有的,我们怎么办呢?
我们可以用一条曲线去尽量准的拟合这些数据,然后如果有新的输入过来,我们可以在将曲线上这个点对应的值返回。如果用一条直线去拟合,可能是下面的样子:
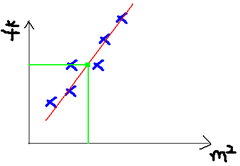
绿色的点就是我们想要预测的点。
首先给出一些概念和常用的符号。
房屋销售记录表:训练集(training set)或者训练数据(training data), 是我们流程中的输入数据,一般称为x
房屋销售价钱:输出数据,一般称为y
拟合的函数(或者称为假设或者模型):一般写做 y = h(x)
训练数据的条目数(#training set),:一条训练数据是由一对输入数据和输出数据组成的输入数据的维度n (特征的个数,#features)
这个例子的特征是两维的,结果是一维的。然而回归方法能够解决特征多维,结果是一维多离散值或一维连续值的问题。
3 学习过程
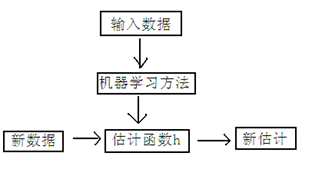
下面是一个典型的机器学习的过程,首先给出一个输入数据,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为构建一个模型。就如同上面的线性回归函数。
4 线性回归
线性回归假设特征和结果满足线性关系。其实线性关系的表达能力非常强大,每个特征对结果的影响强弱可以由前面的参数体现,而且每个特征变量可以首先映射到一个函数,然后再参与线性计算。这样就可以表达特征与结果之间的非线性关系。
我们用X1,X2..Xn 去描述feature里面的分量,比如x1=房间的面积,x2=房间的朝向,等等,我们可以做出一个估计函数:
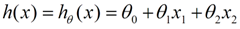
θ在这儿称为参数,在这的意思是调整feature中每个分量的影响力,就是到底是房屋的面积更重要还是房屋的地段更重要。为了如果我们令X0 = 1,就可以用向量的方式来表示了:
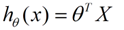
我们程序也需要一个机制去评估我们θ是否比较好,所以说需要对我们做出的h函数进行评估,一般这个函数称为损失函数(loss function)或者错误函数(error function),描述h函数不好的程度,在下面,我们称这个函数为J函数
在这儿我们可以认为错误函数如下:
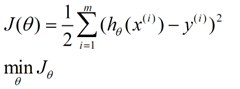
这个错误估计函数是去对x(i)的估计值与真实值y(i)差的平方和作为错误估计函数,前面乘上的1/2是为了在求导的时候,这个系数就不见了。
至于为何选择平方和作为错误估计函数,讲义后面从概率分布的角度讲解了该公式的来源。
如何调整θ以使得J(θ)取得最小值有很多方法,其中有最小二乘法(min square),是一种完全是数学描述的方法,和梯度下降法。
5 梯度下降法
在选定线性回归模型后,只需要确定参数θ,就可以将模型用来预测。然而θ需要在J(θ)最小的情况下才能确定。因此问题归结为求极小值问题,使用梯度下降法。梯度下降法最大的问题是求得有可能是全局极小值,这与初始点的选取有关。
梯度下降法是按下面的流程进行的:
1)首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量。
2)改变θ的值,使得J(θ)按梯度下降的方向进行减少。
梯度方向由J(θ)对θ的偏导数确定,由于求的是极小值,因此梯度方向是偏导数的反方向。结果为
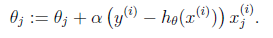
迭代更新的方式有两种,一种是批梯度下降,也就是对全部的训练数据求得误差后再对θ进行更新,另外一种是增量梯度下降,每扫描一步都要对θ进行更新。前一种方法能够不断收敛,后一种方法结果可能不断在收敛处徘徊。
一般来说,梯度下降法收敛速度还是比较慢的。
另一种直接计算结果的方法是最小二乘法。
6 最小二乘法
将训练特征表示为X矩阵,结果表示成y向量,仍然是线性回归模型,误差函数不变。那么θ可以直接由下面公式得出
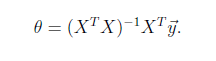
但此方法要求X是列满秩的,而且求矩阵的逆比较慢。
7 选用误差函数为平方和的概率解释
假设根据特征的预测结果与实际结果有误差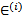 ,那么预测结果
,那么预测结果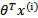 和真实结果
和真实结果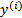 满足下式:
满足下式:
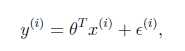
一般来讲,误差满足平均值为0的高斯分布,也就是正态分布。那么x和y的条件概率也就是
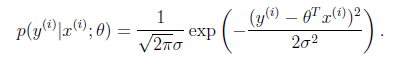
这样就估计了一条样本的结果概率,然而我们期待的是模型能够在全部样本上预测最准,也就是概率积最大。注意这里的概率积是概率密度函数积,连续函数的概率密度函数与离散值的概率函数不同。这个概率积成为最大似然估计。我们希望在最大似然估计得到最大值时确定θ。那么需要对最大似然估计公式求导,求导结果既是
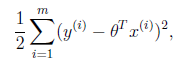
这就解释了为何误差函数要使用平方和。
当然推导过程中也做了一些假定,但这个假定符合客观规律。
8 带权重的线性回归
上面提到的线性回归的误差函数里系统都是1,没有权重。带权重的线性回归加入了权重信息。
基本假设是
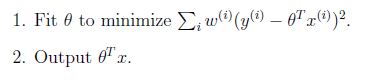
其中假设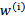 符合公式
符合公式
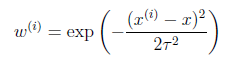
其中x是要预测的特征,这样假设的道理是离x越近的样本权重越大,越远的影响越小。这个公式与高斯分布类似,但不一样,因为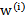 不是随机变量。
不是随机变量。
此方法成为非参数学习算法,因为误差函数随着预测值的不同而不同,这样θ无法事先确定,预测一次需要临时计算,感觉类似KNN。
9 分类和logistic回归
一般来说,回归不用在分类问题上,因为回归是连续型模型,而且受噪声影响比较大。如果非要应用进入,可以使用logistic回归。
logistic回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数g(z)将最为假设函数来预测。g(z)可以将连续值映射到0和1上。
logistic回归的假设函数如下,线性回归假设函数只是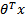 。
。
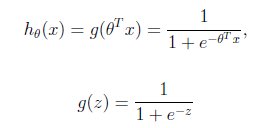
logistic回归用来分类0/1问题,也就是预测结果属于0或者1的二值分类问题。这里假设了二值满足伯努利分布,也就是
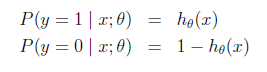
当然假设它满足泊松分布、指数分布等等也可以,只是比较复杂,后面会提到线性回归的一般形式。
与第7节一样,仍然求的是最大似然估计,然后求导,得到迭代公式结果为
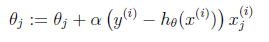
可以看到与线性回归类似,只是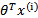 换成了
换成了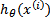 ,而
,而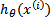 实际上就是
实际上就是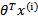 经过g(z)映射过来的。
经过g(z)映射过来的。
10 牛顿法来解最大似然估计
第7和第9节使用的解最大似然估计的方法都是求导迭代的方法,这里介绍了牛顿下降法,使结果能够快速的收敛。
当要求解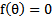 时,如果f可导,那么可以通过迭代公式
时,如果f可导,那么可以通过迭代公式
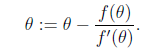
来迭代求解最小值。
当应用于求解最大似然估计的最大值时,变成求解最大似然估计概率导数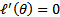 的问题。
的问题。
那么迭代公式写作
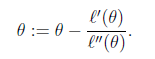
当θ是向量时,牛顿法可以使用下面式子表示
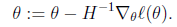
其中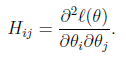 是n×n的Hessian矩阵。
是n×n的Hessian矩阵。
牛顿法收敛速度虽然很快,但求Hessian矩阵的逆的时候比较耗费时间。
当初始点X0靠近极小值X时,牛顿法的收敛速度是最快的。但是当X0远离极小值时,牛顿法可能不收敛,甚至连下降都保证不了。原因是迭代点Xk+1不一定是目标函数f在牛顿方向上的极小点。
11 一般线性模型
之所以在logistic回归时使用
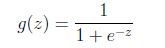
的公式是由一套理论作支持的。
这个理论便是一般线性模型。
首先,如果一个概率分布可以表示成
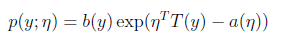
时,那么这个概率分布可以称作是指数分布。
伯努利分布,高斯分布,泊松分布,贝塔分布,狄特里特分布都属于指数分布。
在logistic回归时采用的是伯努利分布,伯努利分布的概率可以表示成
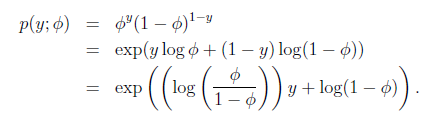
其中
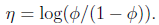
得到
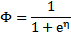
这就解释了logistic回归时为了要用这个函数。
一般线性模型的要点是
1) 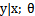 满足一个以
满足一个以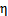 为参数的指数分布,那么可以求得
为参数的指数分布,那么可以求得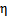 的表达式。
的表达式。
2) 给定x,我们的目标是要确定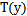 ,大多数情况下
,大多数情况下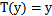 ,那么我们实际上要确定的是
,那么我们实际上要确定的是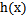 ,而
,而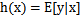 。(在logistic回归中期望值是
。(在logistic回归中期望值是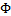 ,因此h是
,因此h是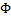 ;在线性回归中期望值是
;在线性回归中期望值是 ,而高斯分布中
,而高斯分布中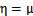 ,因此线性回归中h=
,因此线性回归中h=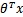 )。
)。
3) 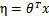
12 Softmax回归
最后举了一个利用一般线性模型的例子。
假设预测值y有k种可能,即y∈{1,2,…,k}
比如k=3时,可以看作是要将一封未知邮件分为垃圾邮件、个人邮件还是工作邮件这三类。
定义
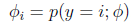
那么
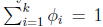
这样
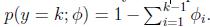
即式子左边可以有其他的概率表示,因此可以当作是k-1维的问题。
为了表示多项式分布表述成指数分布,我们引入T(y),它是一组k-1维的向量,这里的T(y)不是y,T(y)i表示T(y)的第i个分量。
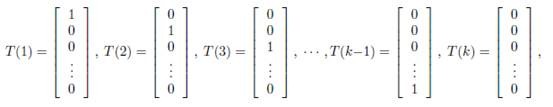
应用于一般线性模型,结果y必然是k中的一种。1{y=k}表示当y=k的时候,1{y=k}=1。那么p(y)可以表示为
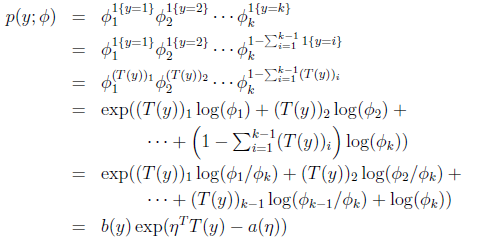
其实很好理解,就是当y是一个值m(m从1到k)的时候,p(y)=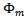 ,然后形式化了一下。
,然后形式化了一下。
那么
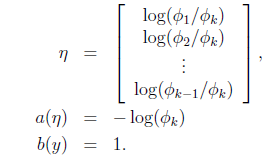
最后求得
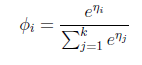
而y=i时
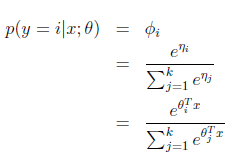
求得期望值

那么就建立了假设函数,最后就获得了最大似然估计
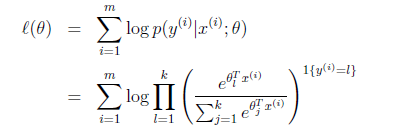
对该公式可以使用梯度下降或者牛顿法迭代求解。
解决了多值模型建立与预测问题。
学习总结
该讲义组织结构清晰,思路独特,讲原因,也讲推导。可贵的是讲出了问题的基本解决思路和扩展思路,更重要的是讲出了为什么要使用相关方法以及问题根源。在看似具体的解题思路中能引出更为抽象的一般解题思路,理论化水平很高。
该方法可以用在对数据多维分析和多值预测上,更适用于数据背后蕴含某种概率模型的情景。
几个问题
一是采用迭代法的时候,步长怎么确定比较好
而是最小二乘法的矩阵形式是否一般都可用
线性回归,logistic回归和一般回归的更多相关文章
- 对线性回归,logistic回归和一般回归的认识
原文:http://www.cnblogs.com/jerrylead/archive/2011/03/05/1971867.html#3281650 对线性回归,logistic回归和一般回归的认识 ...
- 机器学习之线性回归---logistic回归---softmax回归
在本节中,我们介绍Softmax回归模型,该模型是logistic回归模型在多分类问题上的推广,在多分类问题中,类标签 可以取两个以上的值. Softmax回归模型对于诸如MNIST手写数字分类等问题 ...
- 对线性回归,logistic回归和一般回归
对线性回归,logistic回归和一般回归 [转自]:http://www.cnblogs.com/jerrylead JerryLead 2011年2月27日 作为一个机器学习初学者,认识有限,表述 ...
- 线性回归、Logistic回归、Softmax回归
线性回归(Linear Regression) 什么是回归? 给定一些数据,{(x1,y1),(x2,y2)…(xn,yn) },x的值来预测y的值,通常地,y的值是连续的就是回归问题,y的值是离散的 ...
- 1.线性回归、Logistic回归、Softmax回归
本次回归章节的思维导图版总结已经总结完毕,但自我感觉不甚理想.不知道是模型太简单还是由于自己本身的原因,总结出来的东西感觉很少,好像知识点都覆盖上了,但乍一看,好像又什么都没有.不管怎样,算是一次尝试 ...
- 机器学习---三种线性算法的比较(线性回归,感知机,逻辑回归)(Machine Learning Linear Regression Perceptron Logistic Regression Comparison)
最小二乘线性回归,感知机,逻辑回归的比较: 最小二乘线性回归 Least Squares Linear Regression 感知机 Perceptron 二分类逻辑回归 Binary Logis ...
- 【转】Logistic regression (逻辑回归) 概述
Logistic regression (逻辑回归)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性.比如某用户购买某商品的可能性,某病人患有某种疾病的可能性,以及某广告被用户点击的可能性等 ...
- 转:Logistic regression (逻辑回归) 概述
Logistic regression (逻辑回归)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性.比如某用户购买某商品的可能性,某病人患有某种疾病的可能性,以及某广告被用户点击的可能性等 ...
- logistic回归和softmax回归
logistic回归 在 logistic 回归中,我们的训练集由 个已标记的样本构成:.由于 logistic 回归是针对二分类问题的,因此类标记 . 假设函数(hypothesis functi ...
随机推荐
- SpringMVC4 + Spring + MyBatis3
SpringMVC4 + Spring + MyBatis3 本文使用最新版本(4.1.5)的springmvc+spring+mybatis,采用最间的配置方式来进行搭建. 1. web.xml 我 ...
- Linux下Nagios
Linux下Nagios的安装与配置 一.Nagios简介 Nagios是一款开源的电脑系统和网络监视工具,能有效监控Windows.Linux和Unix的主机状态,交换机路由器等网络设置,打印机 ...
- SQLServer 使用 @@ERROR
原文:SQLServer 使用 @@ERROR 使用 @@ERROR 如果最后的 Transact-SQL 语句执行成功,则 @@ERROR 系统函数返回 0:如果此语句产生错误,则 @@ERROR ...
- linux_解压缩详解
.tar 解包:tar xvf FileName.tar打包:tar cvf FileName.tar DirName(注:tar是打包,不是压缩!)———————————————.gz解压1:gun ...
- Windows 注册和取消注册一个dll或者ocx
原文:Windows 注册和取消注册一个dll或者ocx 一.DLL是什么 DLL,是Dynamic Link Library 的缩写形式,中文名称为动态链接库. DLL是 ...
- 基于OCR的SeeTest框架可行性分析总结
总的来说相比其他几个免费框架,SeeTest功能更全面和易用,但收费有点昂贵:License 3500/年:多平台和多语言(基于OCR)还需要额外购买,分别是500/Year和1750$/.详情请查看 ...
- MVC页面声命周期
MVC页面声命周期 ASP.Net请求处理机制初步探索之旅 - Part 4 WebForm页面生命周期 开篇:上一篇我们了解了所谓的请求处理管道,在众多的事件中微软开放了19个重要的事件给我们, ...
- android 控制手机的体积的大小 切换音效模式
(1)项目介绍 于android API的AudioManager于,它提供了一种方法来调整电话音量. audioMa.adjustVolume(AudioManager.ADJUST_LOWER, ...
- Node.js连接MySQL数据库及构造JSON的正确姿势
做一下整理,以前也很随意的引入包链接数据库,后来发现常常连接出问题,异常退出,后来使用在网上一个方法解决问题,网址由于书签丢失,抱歉不能引用了.再有就是简单的模块化下,使得目录合理点,再有就是说明一下 ...
- 基于EF+WCF的通用三层架构及解析
分享基于EF+WCF的通用三层架构及解析 本项目结合EF 4.3及WCF实现了经典三层架构,各层面向接口,WCF实现SOA,Repository封装调用,在此基础上实现了WCFContext,动态服务 ...