巨杉Tech | SequoiaDB数据域及存储规划
1 背景
近年来,企业的各项业务发展迅猛,客户数目不断增加,后台服务系统压力也越来越大,系统的各项硬件资源也变得非常紧张。因此,在技术风险可控的基础上,希望引入大数据技术,利用大数据技术优化现有IT系统实现升级改造,搭建一个统一存储和管理历史、近线数据的服务平台,同时能够对外支持高并发、低延时的数据查询服务,以提高IT系统的计算能力,降低IT系统的建设成本,优化IT系统的服务体系,为各个业务部门提供更加优质的IT服务。
这类服务平台在整个IT系统架构中实质上是一个为核心业务系统减负的系统。SequoiaDB 巨杉数据库支持海量分布式数据存储,并且支持垂直分区和水平分区,利用这些特性可以将历史、近线数据存储到 SequoiaDB 中,并能够对外支持高并发、低延时的数据查询服务。本文主要讲解如何利用巨杉数据库域的特性在历史、近线数据应用场景下进行存储规划已满足业务系统对性能、存储、维护等方便的要求。
2 相关概念
多维度数据分区
SequoiaDB 支持水平和垂直方式分区。采用散列(hash)或范围(range)水平分区是将数据分布至多个节点,加大数据吞吐量, 加速数据查询和写入;采用范围(range)垂直分区是在一个节点内将数据逻辑划分为多个区间,每个区间作为独立的存储单元,减少查询时网络I/O, 进一步加速查询。
水平分区
散列水平分区,原理是将选择的分区键进行 hash 运算,根据 hash 值将数据分发至相应分区。范围水平分区则是直接匹配分区键和所对应的范围,存放到相应的分区。两种分区方式各有适用的场景,和运行的业务息息相关。一般不建议采用范围水平分区,除范围分区键(如月)能保证数据均衡(如每月的数据量级一致)。如图2-1所示。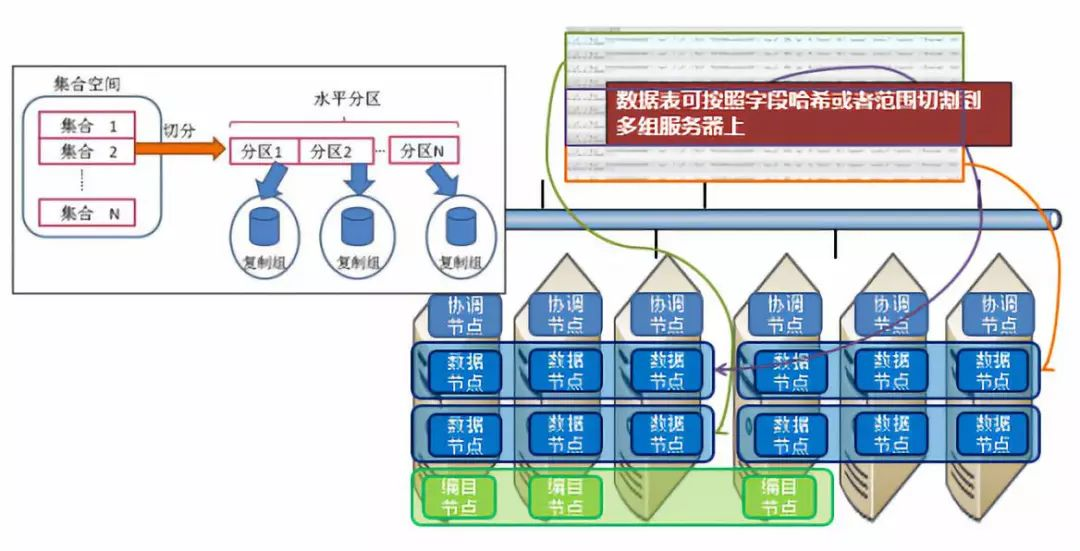
图2-1. SequoiaDB 水平分区
垂直分区
垂直分区是指在一个节点内集合数据按某字段,分成成多个数据段。每个范围代表一个垂直分区。数据查询、写入时自动分发至相应分区中。垂直分区极大减少硬盘数据访问,降低网络I/O,加速查询。垂直分区共享资源(同一台物理机),出发点在于将冷热数据隔离,如图2-2所示。
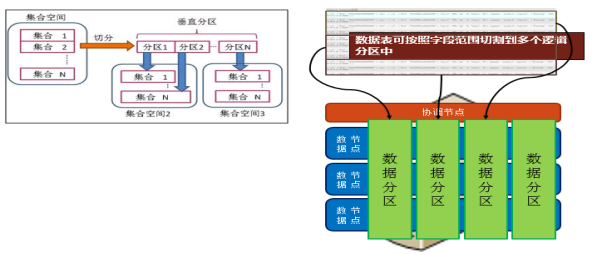
图2-2. SequoiaDB 垂直分区
复制组和域
分区组又被称为复制组,一个复制组内可以包含一个或多个数据节点(或编目节点),节点之间的数据使用异步日志复制机制,保持最终一致。
域(Domain)是由若干个复制组(ReplicaGroup)组成的逻辑单元。每个域都可以根据定义好的策略自动管理所属数据,如数据切片和数据隔离等。
以3台服务器为例,每台服务器9块磁盘。复制组的物理部署和域的逻辑组成如图2-3所示: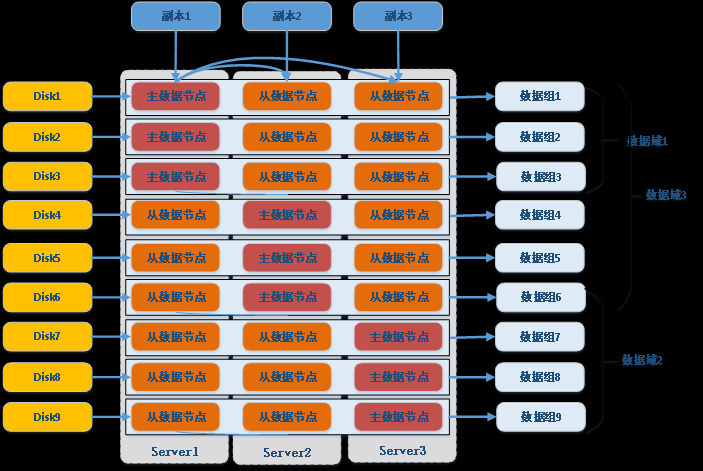
采用3副本,按磁盘部署数据节点,每台机器部署9个数据节点,3台机器横向组成数据组,共9个数据组。如图域1包括数据组1-3,域2包括数据组5-9,域3包括数据组1-6,因此域在逻辑上由数据组组成,并且组成的数据组可以重叠。
3 业务场景
随着用户的增加、业务的发展,大型企业用户的业务系统的数据量越来越大,而且原有系统绝大部分基于关系型数据构建,表结构复杂,每个查询都需要关联若干张大数据表,导致关联查询的性能非常低。
因此可以利用 SequoiaDB 存储海量历史、近线数据并开发数据查询统一入口,按照数据生命周期管理的规则对历史、近线数据进行统一在线存储。另外平台提供高并发、实时查询服务,解决了关系型数据库海量数据关联查询性能慢的问题。
根据业务系统历史、近线数据的需求,建立历史、近线数据存储区用于存储从源系统直接导入的原始数据,包括超出生产系统保存期限的数据以及需要按时点备份的数据。同时为提供在线、中高并发,小结果集的数据处理能力,可根据源系统不同划分多个存储区域,集群内部使用划分数据域的方式进行分类管理。
4 数据域划分方式
在业务系统通过接入平台将结构化数据接入到巨杉数据库时,需根据数据调研信息对业务系统进行分类,以确定业务系统的存储量、并发大小、数据生命周期等,为结构化数据在巨杉数据库中的存储规划提供信息支撑。业务系统结构化数据存储到巨杉数据库可利用数据域技术对业务系统的数据区域进行功能划分,具体划分方式如下:
海量数据或者高并发查询业务系统
这类业务系统的特点是业务查询并发较大,数据所占存储空间较大,对cpu、内存、网络要求较高,利用域对这类系统进行隔离,可以使数据在写入、读取时充分利用集群中域所在机器的物理资源以提升性能。
数据量较小或者查询并发数较小的业务系统
这类业务系统一般对cpu、内存、网络要求较低,所占存储空间较小。因此这类系统可以和其他并发、所占存储较小的业务系统的数据域共享数据组以节省机器资源。
5 利用数据域水平扩展集群
目前,企业的部分业务系统结构化数据年增长量较大并且数据越来越多。在业务系统投产后,随着业务量的增加集群可使用容量逐渐变小,因此在业务系统接入集群前需考虑存储容量耗尽后整个集群的水平扩展。SequoiaDB 是分布式数据库,因此可以通过集群的扩容实现集群性能的近线性增长。而通过扩容后主要解决两个问题是数据存储的容量问题和整个集群的性能问题。因为数据量的不断增长及上线后的推广使用,所以需要进行扩容来提升集群性能及增加数据存储空间。
SequoiaDB 在集群的管理上定义了数据域概念,一个数据域可以将多个数据组包含进来。一个集群可以根据不同的业务系统来划分不同的数据域,不仅实现将不同业务系统数据在物理层面的隔离存储,同时也实现了不同业务系统数据的统一调度管理,而且以后的集群扩容也可以根据域的使用需求而只针对此域进行集群扩容。
所以在进行扩容时,我们需要结合 SequoiaDB 数据域和业务系统需求进行扩容规划及实施。结构化数据在扩容时,可针对结构化数据所在数据域增加数据组再进行数据均衡切分到新扩容的机器上;或者使子表分散在单独的集合空间中,并使子表对应的集合空间所属数据组在新扩容机器的数据组上。
6 具体案例
某大型金融用户的某系统历史数据量60T,每天有80G左右的增量数据。假设按照3年数据总量做存储规划,则三年数据占总存储约为(60+80G*365/1024)*3=266T。
假设现在客户提供的硬件配置信息如下:
具体安装部署如图6-1所示: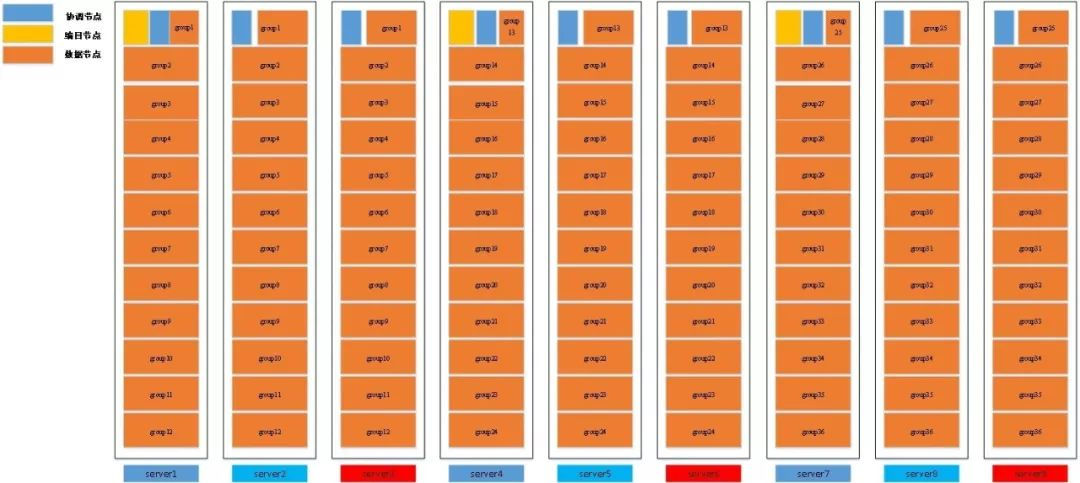
图6-1
存储规则
根据上述业务系统的信息,可将这类系统划分为高并发海量存储业务场景。结合数据域划分方式以及未来扩容需求,该业务系统的结构化数据存储在接入时数据域划分规则如下:
1、 海量数据高并发查询业务系统使用独立的域进行存储;
2、 使用主子表按照时间切分,每个子表按照ID散列分布到域所对应的所有机器上;
3、 海量数据高并发查询业务系统子表单独使用集合空间;
4、 数据量较小或者并发查询较小的业务系统可以共用域;
5、 结构化域扩容可使用增加数据组再进行数据均衡切分到新扩容的机器上,或者使子表分散在单独的集合空间中,并使子表对应的集合空间所属数据组在新扩容机器的数据组上。
集合空间和集合设计
根据上述存储规则,该业务场景下的结构化数据和非结构化数据存储方式如下:
使用主子表按照时间切分,每个子表按照ID或者业务字段散列分布,子表跨度按月进行切分,并且子表分散在单独的集合空间中。
7 总结
数据域在逻辑上由一个或多个数据组组成,在物理上对应具体的数据节点,并且不同的域之间可以重叠数据组。因此,业务系统可以根据主子表特性以及域包含数据组的灵活性将集群划分为不同的区域存储结构化数据,充分利用集群的计算、存储资源。巨杉数据库,支持海量数据存储,SequoiaDB 支持垂直分区和水平分区,提供高并发、低延时数据查询服务。
巨杉Tech | SequoiaDB数据域及存储规划的更多相关文章
- 巨杉数据库SequoiaDB】巨杉Tech | SequoiaDB 分布式事务实现原理简介
1 分布式事务背景 随着分布式数据库技术的发展越来越成熟,业内对于分布式数据库的要求也由曾经只用满足解决海量数据的存储和读取这类边缘业务向核心交易业务转变.分布式数据库如果要满足核心账务类交易需求,则 ...
- 巨杉Tech | SequoiaDB虚机镜像正式上线
数据库云化架构需求 随着云架构的发展和流行,在业务和应用进行“云化”的过程中,云数据库因为在整体架构中的重要地位,在云化改造中的重要性不言而喻.云数据库需要满足这些技术要求,除了在功能上的具体提升,在 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 分布式数据库千亿级超大表优化实践
01 引言 随着用户的增长.业务的发展,大型企业用户的业务系统的数据量越来越大,超大数据表的性能问题成为阻碍业务功能实现的一大障碍.其中,流水表作为最常见的一类超大表,是企业级用户经常碰到的性能瓶颈. ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 巨杉数据库数据高性能数据导入迁移实践
SequoiaDB 一款自研金融级分布式数据库产品,支持标准SQL和分布式事务功能.支持复杂索引查询,兼容 MySQL.PGSQL.SparkSQL等SQL访问方式.SequoiaDB 在分布式存储功 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 四步走,快速诊断数据库集群状态
1.背景 SequoiaDB 巨杉数据库是一款金融级分布式数据库,包括了分布式 NewSQL.分布式文件系统与对象存储.与高性能 NoSQL 三种存储模式,分别对应分布式在线交易.非结构化数据和内容管 ...
- 【巨杉数据库Sequoiadb】巨杉⼯具系列之一 | ⼤对象存储⼯具sdblobtool
近期,巨杉数据库正式推出了完整的SequoiaDB 工具包,作为辅助工具,更好地帮助大家使用和运维管理分布式数据库.为此,巨杉技术社区还将持续推出工具系列文章,帮助大家了解巨杉数据库丰富的工具矩阵. ...
- 巨杉Tech | SparkSQL+SequoiaDB 性能调优策略
当今时代,企业数据越发膨胀.数据是企业的价值,但数据处理也是一种技术挑战.在海量数据处理的场景,即使单机计算能力再强,也无法满足日益增长的数据处理需求.所以,分布式才是解决该类问题的根本解决方案.而在 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | “删库跑路”又出现,如何防范数据安全风险?
最近,又双叕有企业被“删库”了.来自微盟官网的消息,微盟的业务系统数据库(包括主备)遭遇其公司运维人员的删除,系统将停止运营超48小时. 频发的类似事件也让大家对于数据安全的关注不断提高.数据是一个科 ...
- 【巨杉数据库SequoiaDB】为“战疫” 保驾护航,巨杉在行动
2020年,我们经历了一个不平静的新春,在这场大的“战疫”中,巨杉数据库也积极响应号召,勇于承担新一代科技企业的社会担当,用自己的行动助力这场疫情防控阻击战! 赋能“战疫”快速响应 巨杉数据库目前服务 ...
随机推荐
- 搭建数据库galera集群
galera集群 galera简介 galera集群又叫多主集群,用于数据库的同步,保证数据安全 最少3台,最好是奇数台数,当一台机器宕掉时,因为仲裁机制,这台机器就会被踢出集群. 通过wsrep协议 ...
- APP自动化测试的环境配置
什么是Appium? 第三方自动化框架(工具),扩充了selenium webdriver 协议,在原有的基础上添加了移动端测试API selenium webdriver 指定了客户端到服务端的协议 ...
- linux centos安装zabbix 4.0服务端
1.服务器安装docker sudo yum install -y yum-utils device-mapper-persistent-data lvm2 sudo yum-config-manag ...
- 《你不知道的JavaScript》笔记(一)
用了一个星期把<你不知道的JavaScript>看完了,但是留下了很多疑惑,于是又带着这些疑惑回头看JavaScript的内容,略有所获. 第二遍阅读这本书,希望自己能够有更为深刻的理解. ...
- springboot 整合ehcache缓存
1.CacheManager Spring Boot默认集成CacheManager,如下包所示: 可以看出springboot自动配置了 JcacheCacheConfiguration. EhCa ...
- LINUX系统学习以及初学者系统下载
Linux系统常用命令大全 来源:服务器之家 [博客中所有文章如有不对的地方希望看官们指出,有问题也可以提出来相互交流,相互学习,感谢大家!] 初学者建议安装:sentOS Ubuntu系统下载连接h ...
- 蓝松SDK支持以下的AE特性
蓝松短视频SDK 支持Ae模板, 您可以在PC端用AE设计好模板,然后导入到SDK中, 蓝松SDK支持一下的AE特性:1, Ae中的图片图层,任意多个图片图层, 每个图片的移动旋转缩放透明,锚点,蒙版 ...
- windows下python和pycharm安装及其使用
1.python安装及环境变量配置 1.1 python安装 1.1.1 python下载 官网下载:https://www.python.org/ Downloads-Windows(Mac os ...
- InnoDB体系结构
1.前言 整理了下InnoDB体系结构,方便以后更简单的理解 2.思维导图 参考: https://www.cnblogs.com/tangshiguang/p/6741035.html https: ...
- java架构之路-(分布式zookeeper)zookeeper真实使用场景
上几次博客,我说了一下Zookeeper的简单使用和API的使用,我们接下来看一下他的真实场景. 一.分布式集群管理✨✨✨ 我们现在有这样一个需求,请先抛开Zookeeper是集群还是单机的概念,下面 ...