python 36 进程池、线程池
1. 死锁与递归锁
死锁:两个或者两个以上的进程或者线程在执行过程中,因争夺资源而造成的一种等待现象,称为死锁现象。
递归锁可以解决死锁现象。
递归锁有一个计数的功能,原数字为0,锁一次计数+1,释放一次,计数-1;只要数字不为0,其他线程就不能枪锁。
from threading import RLock
from threading import Thread
import time
lock_A = lock_B = RLock() # 必须这样写
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
lock_A.acquire()
print(f'{self.name}抢到了A锁!')
lock_B.acquire()
print(f'{self.name}抢到了B锁!')
lock_B.release()
lock_A.release()
def f2(self):
lock_B.acquire()
print(f'{self.name}抢到了B锁!')
time.sleep(0.1)
lock_A.acquire()
print(f'{self.name}抢到了A锁!')
lock_A.release()
lock_B.release()
if __name__ == '__main__':
for i in range(3):
t = MyThread()
t.start()
2. 信号量Semaphor
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
能够控制同一时刻的线程数。
from threading import Thread, Semaphore, current_thread
import time
import random
sem = Semaphore(5) # 设置同一时刻只能有5个线程并发执行
def task():
sem.acquire()
print(f'{current_thread().name}进程在运行')
time.sleep(random.random())
sem.release()
if __name__ == '__main__':
for i in range(30):
t = Thread(target=task)
t.start()
3. GIL全局解释器锁:(Cpython)
Cpython规定,同一时刻只允许一个线程进入解释器,因为加了GIL。
如果不加全局解释器锁,会出现死锁现象,开发此的程序员为了方便,在进入解释器时给线程加了一个全局解释器锁,这样保证了解释器内的数据安全。
优点: 保证了Cpython解释器的数据资源的安全;
缺点: 单个进程的多线程不能利用多核cpu(缺陷)。
Jython、pypy解释器没有GIL全局解释器锁。
流程:当线程遇到IO阻塞,cpu就会无情的被操作系统切走,GIL全局解释器锁被释放,线程挂起,另一个线程进入,这样可以实现并发。
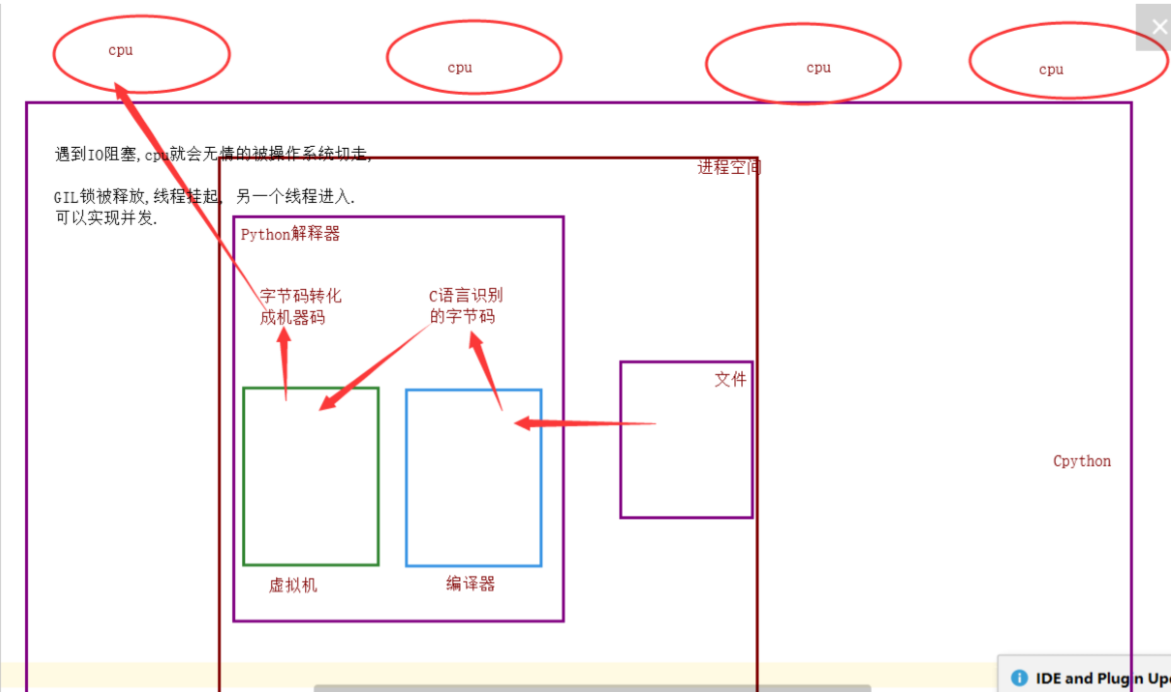
总结:
单个进程的多线程可以并发执行,但是不能利用cpu多核并行执行;
多个进程可以并发、并行执行。
4. IO、计算密集型对比
4.1 计算密集型:
单个进程的多线程 VS 多个进程的并发、并行
from threading import Thread
from multiprocessing import Process
import time
def task():
count = 0
for i in range(10000000):
count += 1
# 多线程并发
if __name__ == '__main__':
start_time = time.time()
l1 = []
for i in range(4):
p = Thread(target=task,)
l1.append(p)
p.start()
for p in l1:
p.join()
print(f'执行效率:{time.time()- start_time}') # 1.9125
# 多进程并发、并行
if __name__ == '__main__':
start_time = time.time()
l1 = []
for i in range(4):
p = Process(target=task,)
l1.append(p)
p.start()
for p in l1:
p.join()
print(f'执行效率:{time.time()- start_time}') # 0.86031
# 总结:
计算密集型:多进程并发、并行效率高。
4.2 IO密集型
单个进程的多线程 VS 多个进程的并发并行
from threading import Thread
from multiprocessing import Process
import time
import random
def task():
count = 0
time.sleep(random.randint(1,3))
count += 1
if __name__ == '__main__':
# 多进程并发、并行
start_time = time.time()
l1 = []
for i in range(50):
p = Process(target=task,)
l1.append(p)
p.start()
for p in l1:
p.join()
print(f'执行效率:{time.time()- start_time}') # 4.52878
# 多线程并发
start_time = time.time()
l1 = []
for i in range(50):
p = Thread(target=task, )
l1.append(p)
p.start()
for p in l1:
p.join()
print(f'执行效率:{time.time() - start_time}') # 3.00845
# 总结:
对于IO密集型:单个进程的多线程的并发效率高。
5. GIL与Lock锁的区别
相同点:都是互斥锁;
GIL: 保护解释器内部的资源数据的安全,释放无需手动操作;
Lock:自定义锁,保护进程中的数据资源安全。需要手动操作。
6. 多线程实现socket通信
服务端每连接到一个客户端时,都会开启一个线程进行通信。
# server端
from threading import Thread
import socket
def accept():
server = socket.socket()
server.bind(("127.0.0.1", 8888))
server.listen(5)
while 1:
conn, addr = server.accept()
# 连接一个开启一个线程
t = Thread(target=communication, args=(conn, addr))
t.start()
def communication(conn, addr):
while 1:
try:
from_client_data = conn.recv(1024)
print(f"来自客户端{addr}的消息:{from_client_data.decode('utf-8')}")
to_client_data = input(">>>").strip().encode("utf-8")
conn.send(to_client_data)
except Exception:
break
conn.close()
if __name__ == '__main__':
accept()
# client端
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8888))
while 1:
try:
to_server_data = input(">>>").strip().encode("utf-8")
client.send(to_server_data)
from_server_data = client.recv(1024)
print(f"来自客户端的消息:{from_server_data.decode('utf-8')}")
except Exception:
break
client.close()
7. 进程池、线程池
以时间换取空间。
概念:定义一个池子,在里面放上固定数量的进程(线程),有需求来了,就拿一个池中的进程(线程)来处理任务,等到处理完毕,进程(线程)并不关闭,而是将进程(线程)再放回池中继续等待任务。如果有很多任务需要执行,池中的进程(线程)数量不够,任务就要等待之前的进程(线程)执行任务完毕归来,拿到空闲的进程(线程)才能继续执行。也就是说,池中进程(线程)的数量是固定的,那么同一时间最多有固定数量的进程(线程)在运行。这样不会增加操作系统的调度难度,还节省了开闭进程(线程)的时间,也一定程度上能够实现并发效果。
官网:https://docs.python.org/dev/library/concurrent.futures.html
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import os
import time
import random
def task(i):
print(f"第{i}:{os.getpid()}开始执行!")
time.sleep(random.random())
if __name__ == '__main__':
# 线程池
t = ThreadPoolExecutor() # 开启线程池 不写默认最大处理20个线程
for i in range(40):
t.submit(task, i+1) # 开启线程
# 进程池
p = ProcessPoolExecutor() # 开启进程池 不写默认处理cpu个数的进程
for i in range(20):
p.submit(task, i+1)
示例:使用线程池实现socket通信
# server端
from concurrent.futures import ThreadPoolExecutor
import socket
def accept():
server = socket.socket()
server.bind(("127.0.0.1", 8888))
server.listen(5)
t = ThreadPoolExecutor(2) # 设置最大2个线程的线程池
while 1:
conn, addr = server.accept()
t.submit(communication, conn, addr)
def communication(conn, addr):
while 1:
try:
from_client_data = conn.recv(1024)
print(f"来自客户端{addr}的消息:{from_client_data.decode('utf-8')}")
to_client_data = input(">>>").strip().encode("utf-8")
conn.send(to_client_data)
except Exception:
break
conn.close()
if __name__ == '__main__':
accept()
# client端
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8888))
while 1:
try:
to_server_data = input(">>>").strip().encode("utf-8")
client.send(to_server_data)
from_server_data = client.recv(1024)
print(f"来自客户端的消息:{from_server_data.decode('utf-8')}")
except Exception:
break
client.close()
python 36 进程池、线程池的更多相关文章
- 《转载》Python并发编程之线程池/进程池--concurrent.futures模块
本文转载自Python并发编程之线程池/进程池--concurrent.futures模块 一.关于concurrent.futures模块 Python标准库为我们提供了threading和mult ...
- python自带的线程池和进程池
#python自带的线程池 from multiprocessing.pool import ThreadPool #注意ThreadPool不在threading模块下 from multiproc ...
- python并发编程-进程池线程池-协程-I/O模型-04
目录 进程池线程池的使用***** 进程池/线程池的创建和提交回调 验证复用池子里的线程或进程 异步回调机制 通过闭包给回调函数添加额外参数(扩展) 协程*** 概念回顾(协程这里再理一下) 如何实现 ...
- Python学习之GIL&进程池/线程池
8.6 GIL锁** Global interpreter Lock 全局解释器锁 实际就是一把解释器级的互斥锁 In CPython, the global interpreter lock, or ...
- Python并发编程05 /死锁现象、递归锁、信号量、GIL锁、计算密集型/IO密集型效率验证、进程池/线程池
Python并发编程05 /死锁现象.递归锁.信号量.GIL锁.计算密集型/IO密集型效率验证.进程池/线程池 目录 Python并发编程05 /死锁现象.递归锁.信号量.GIL锁.计算密集型/IO密 ...
- Python标准模块--concurrent.futures 进程池线程池终极用法
concurrent.futures 这个模块是异步调用的机制concurrent.futures 提交任务都是用submitfor + submit 多个任务的提交shutdown 是等效于Pool ...
- concurrent.futures模块(进程池/线程池)
需要注意一下不能无限的开进程,不能无限的开线程最常用的就是开进程池,开线程池.其中回调函数非常重要回调函数其实可以作为一种编程思想,谁好了谁就去掉 只要你用并发,就会有锁的问题,但是你不能一直去自己加 ...
- Python-GIL 进程池 线程池
5.GIL vs 互斥锁(*****) 1.什么是GIL(Global Interpreter Lock) GIL是全局解释器锁,是加到解释器身上的,保护的就是解释器级别的数据 (比如垃圾回收的数据) ...
- 13 并发编程-(线程)-异步调用与回调机制&进程池线程池小练习
#提交任务的两种方式 #1.同步调用:提交完任务后,就在原地等待任务执行完毕,拿到结果,再执行下一行代码,导致程序是串行执行 一.提交任务的两种方式 1.同步调用:提交任务后,就在原地等待任务完毕,拿 ...
- 并发编程---线程queue---进程池线程池---异部调用(回调机制)
线程 队列:先进先出 堆栈:后进先出 优先级:数字越小优先级越大,越先输出 import queue q = queue.Queue(3) # 先进先出-->队列 q.put('first') ...
随机推荐
- LeetCode_32
LeetCode 32 题目描述: 给定一个只包含 '(' 和 ')' 的字符串,找出最长的包含有效括号的子串的长度. 示例 1: 输入: "(()" 输出: 2 解释: 最长有效 ...
- 浅入深出Vue:代码整洁之去重
在开始本篇的主题之前,让我们把上次遗留下来的问题都清理一下: 将其他组件中 axios 请求的地方封装起来. 这里就不把代码放在开头了,相关代码都放在文末,有兴趣了解的童鞋可以先往下翻. 好了, 我们 ...
- Java 集合框架部分面试题
1.Java集合框架是什么?说出一些集合框架的优点? 每种编程语言中都有集合,最初的Java版本包含几种集合类:Vector.Stack.HashTable和Array.随着集合的广泛使用,Java1 ...
- sql format 格式化数字(前面补0)
将一个数字例如33,或1使用t-sql语句转换成033或001 以下是详细分析: 1.select power(10,3)得到1000 2.select cast(1000+33 as varchar ...
- Codeforces Round #479 (Div. 3) D. Divide by three, multiply by two
传送门 D. Divide by three, multiply by two •题意 给你一个数 x,有以下两种操作,x 可以任选其中一种操作得到数 y 1.如果x可以被3整除,y=x/3 2.y= ...
- 0 MapReduce实现Reduce Side Join操作
一.准备两张表以及对应的数据 (1)m_ys_lab_jointest_a(以下简称表A) 建表语句: create table if not exists m_ys_lab_jointest_a ( ...
- poj 3714 寻找最近点对
参考自<编程之美>169页,大概原理就是把区间分成两部分,然后递归找每一部分中最近的点对,还有一种情况就是这个点对分属于这两部分,然后选两部分中的部分点枚举即可,取其最小值. //2013 ...
- [nghttp2]压测工具,源码编译并进行deb打包过程
编译环境:deepin 15.11桌面版 nghttp2下载地址:https://github.com/nghttp2/nghttp2 环境要求 emm只能在类Linux环境才能完整编译,想在Wind ...
- Docker笔记(七):常用服务安装——Nginx、MySql、Redis
开发中经常需要安装一些常用的服务软件,如Nginx.MySql.Redis等,如果按照普通的安装方法,一般都相对比较繁琐 —— 要经过下载软件或源码包,编译安装,配置,启动等步骤,使用 Docker ...
- 4、一个打了鸡血的for循环(增强型for循环)
对于循环,我们大家应该都不陌生,例如do-while循环,while循环,for循环,今天给大家介绍一个有趣的东西——打了鸡血的for循环(增强型for循环). 首先看代码,了解一下for循环的结构: ...