Python爬虫--喜马拉雅三国音频爬取
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:Botreechan 
1.进入地址我们可以发现,页面有着非常整齐的目录,那么网页源代码中肯定也有非常规律的目录,进去看看吧。如果你看不懂,建议先去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题多跟里面的人交流,进步更快哦!
2.很明显猜对了,源代码中确实有这很明显的规律,每一章节都有着及其固定的模板:
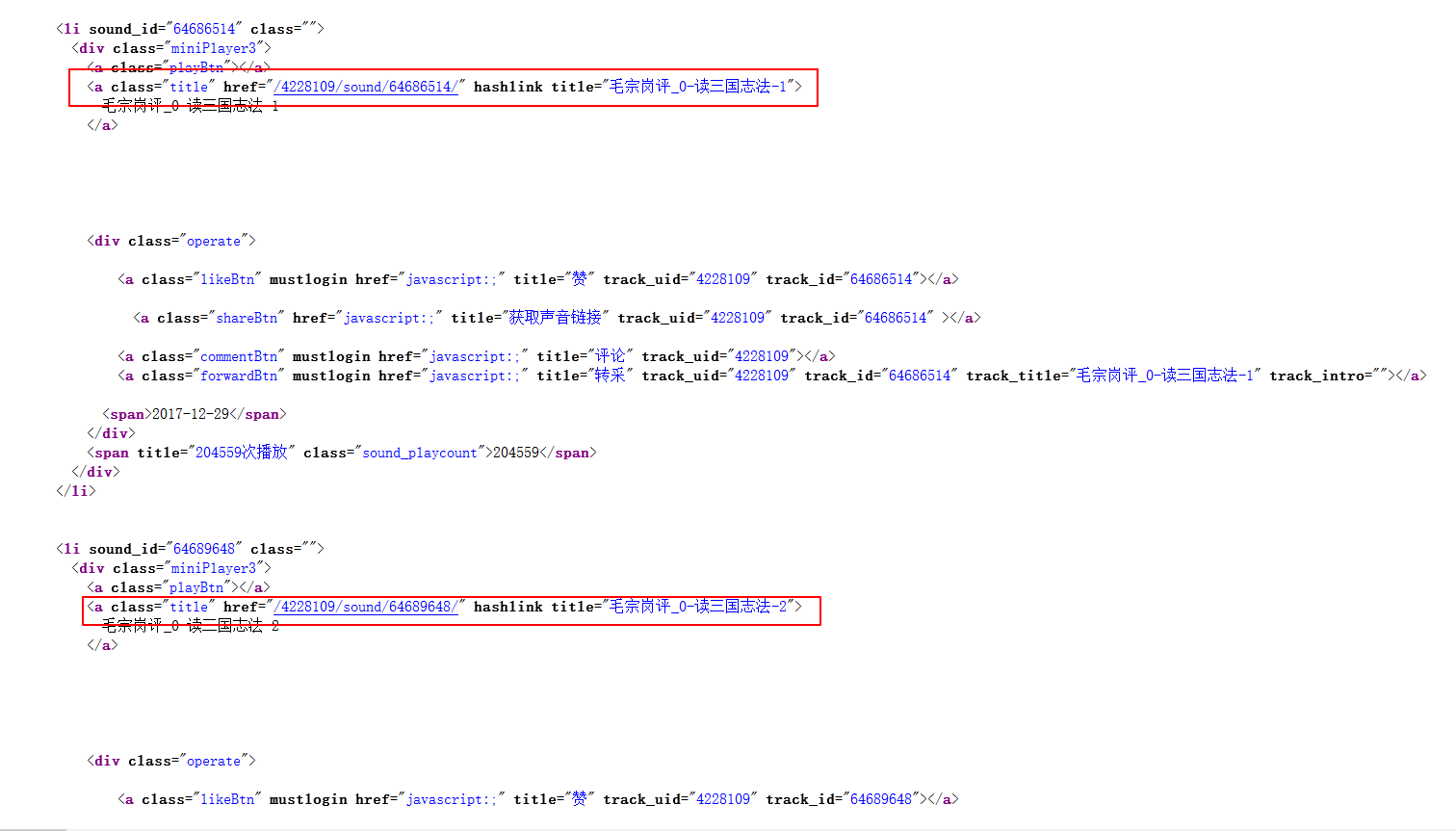
但是这时候我们并找不到深层的规律,那么下一步我们尝试下播放一条音频,但不仅仅是播放,更重要的是要抓包!!!
3.打开浏览器抓包工具(F12),点击任意一条音频,这里我就以第一条为例了。
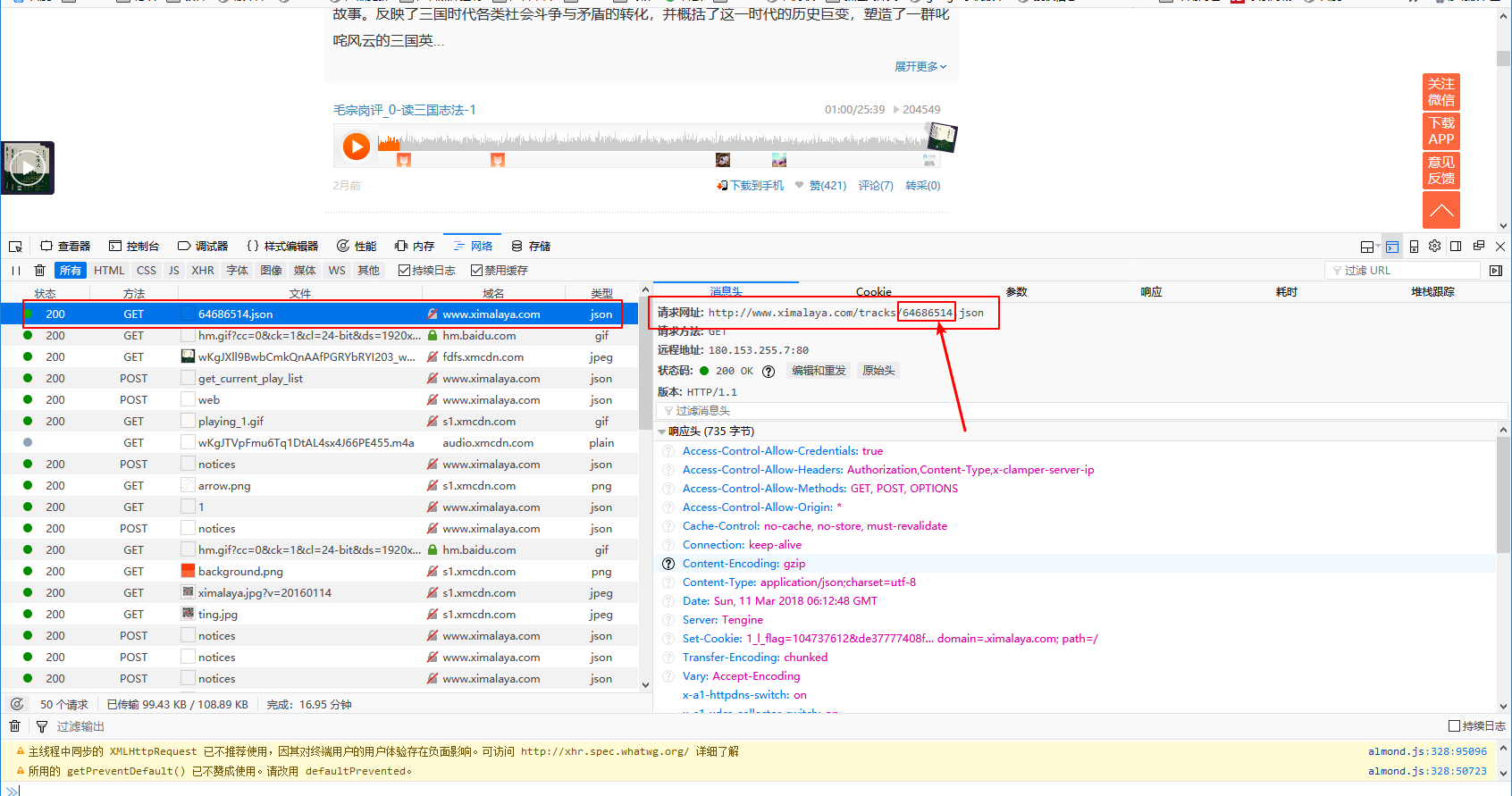
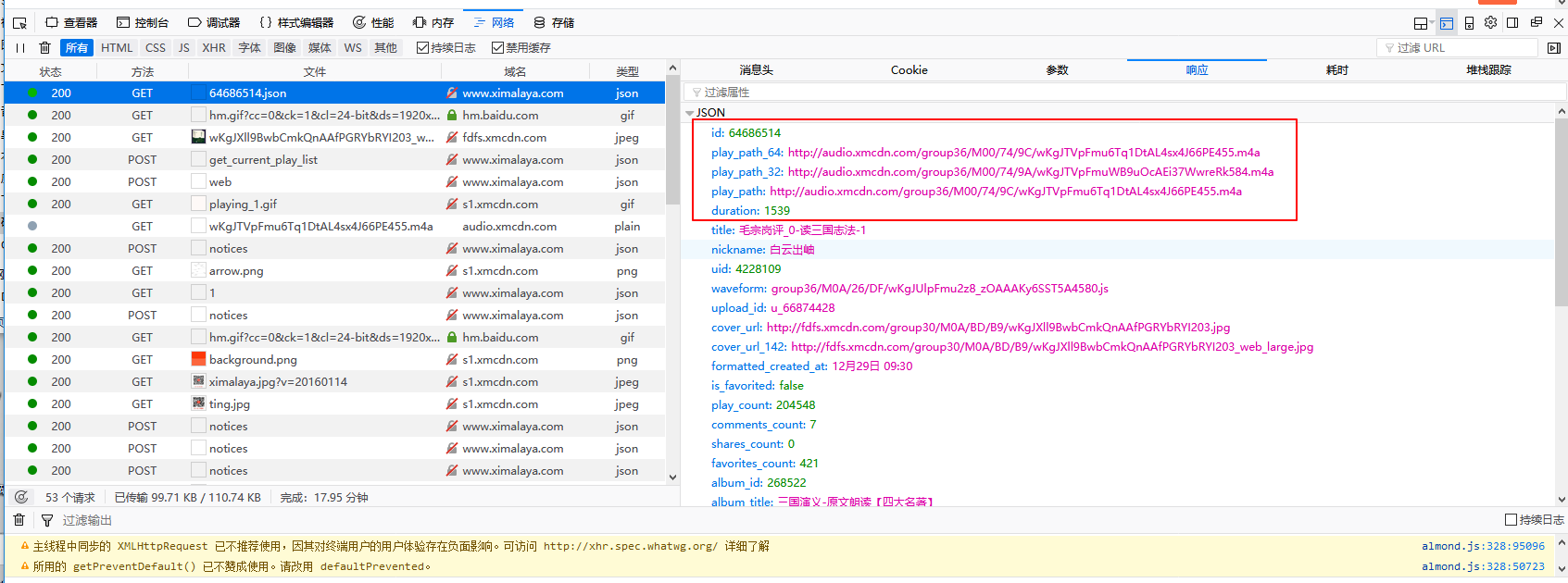
上面两张图是我抓取到的getURL和返回的json,可以看出返回的内容里确实有三条音频地址,复制到浏览器可以直接播放,听一听就是我们要的宝贝。重点来了,getURL中我圈出来的看着是不是很眼熟?不错,那个就是网页源代码里面每个章节URL里的一个值,而这个值就是每个章节的sound_id,再按照上面的步骤,操作其他章节看看,也是一样的规律。那么思路很清晰了,我们只需要把每个章节的ID的sound_id替换到getURL中不就可以获取到每个章节的音频了么?
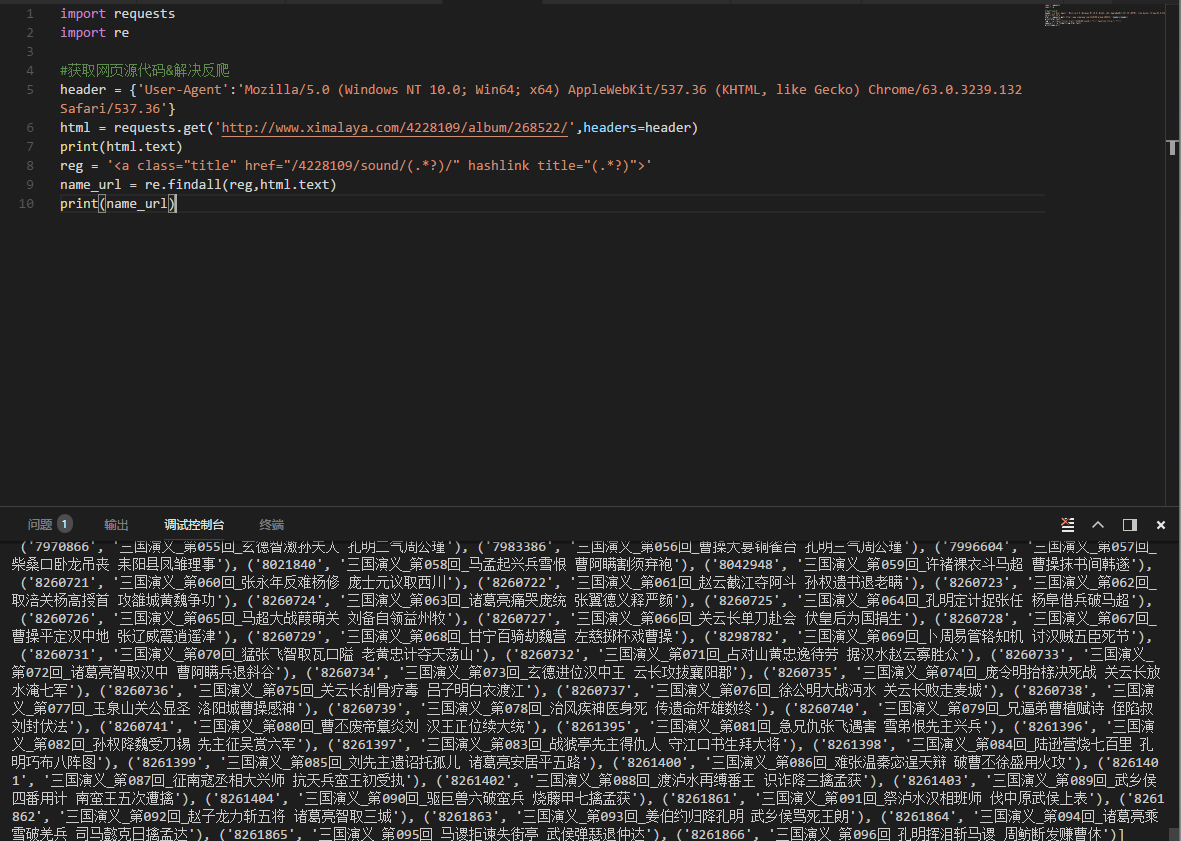
4.开始写代码:
- import requests
- import re
- #获取网页源代码&解决反爬
- header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
- html = requests.get('http://www.ximalaya.com/4228109/album/268522/',headers=header)
- print(html.text)
- reg = '<a class="title" href="/4228109/sound/(.*?)/" hashlink title="(.*?)">'
- name_url = re.findall(reg,html.text)
- print(name_url)
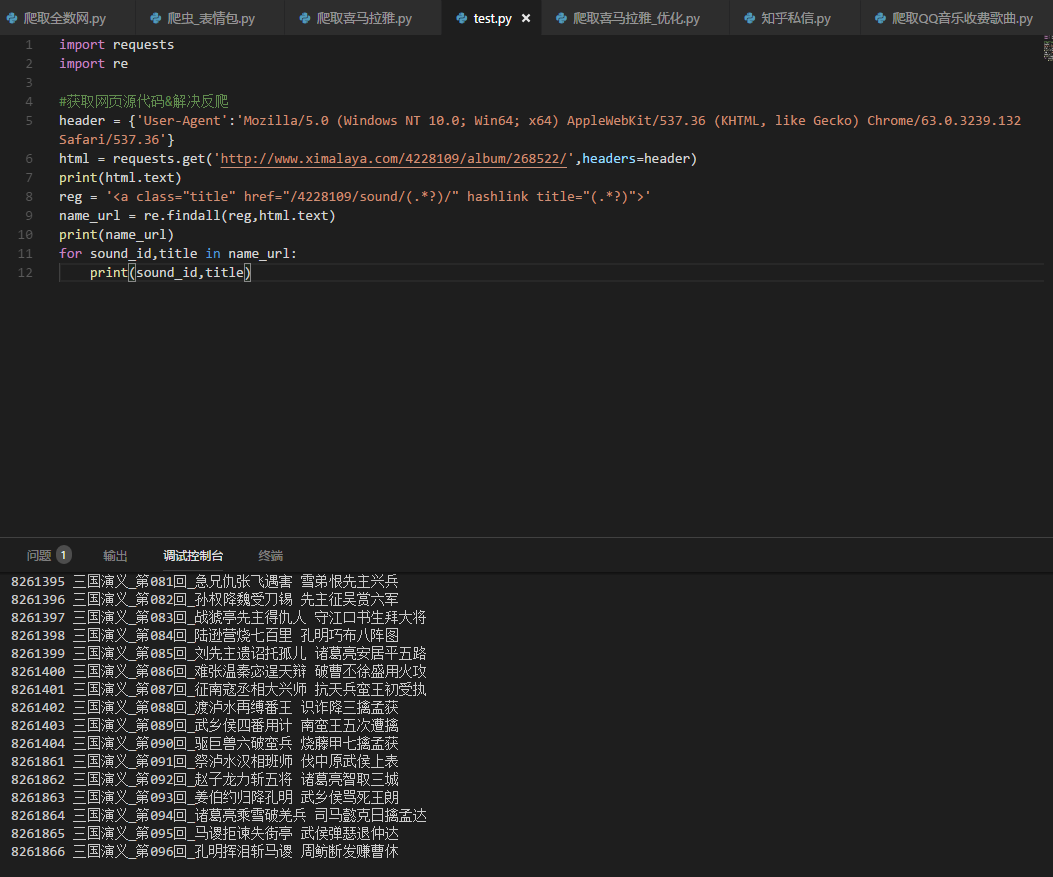
这个时候我们可以看到,网页每个章节和对应sound_id都被找出来了。
5.返回的有没有很乱?确实很乱,但是返回的都是元组类型,那么我们来定义一个ID和标题吧。
- for sound_id,title in name_url:
- print(sound_id,title)
看下效果,有没有耳目一新:
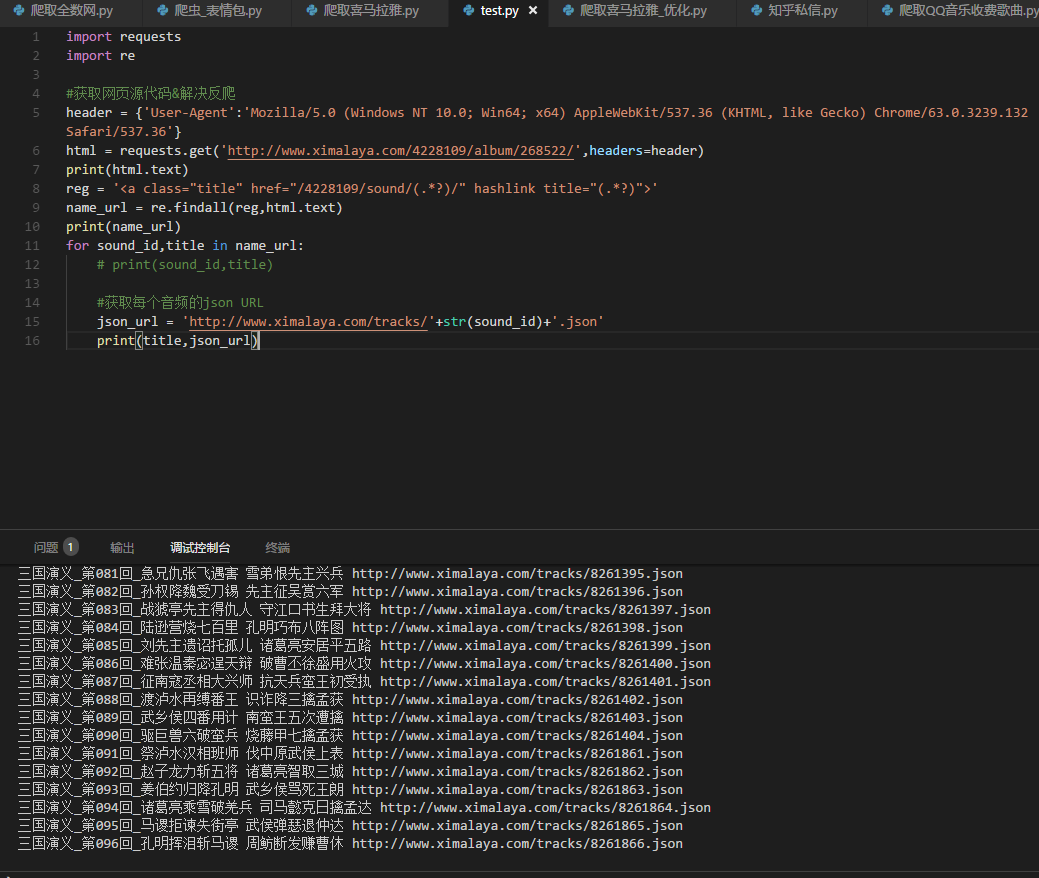
6.好了,回到最开始我们抓包的时候,我们的音频都在一个抓取的json里,开始拼接咱们的json URL
- json_url = 'http://www.ximalaya.com/tracks/'+str(sound_id)+'.json'
- print(title,json_url)
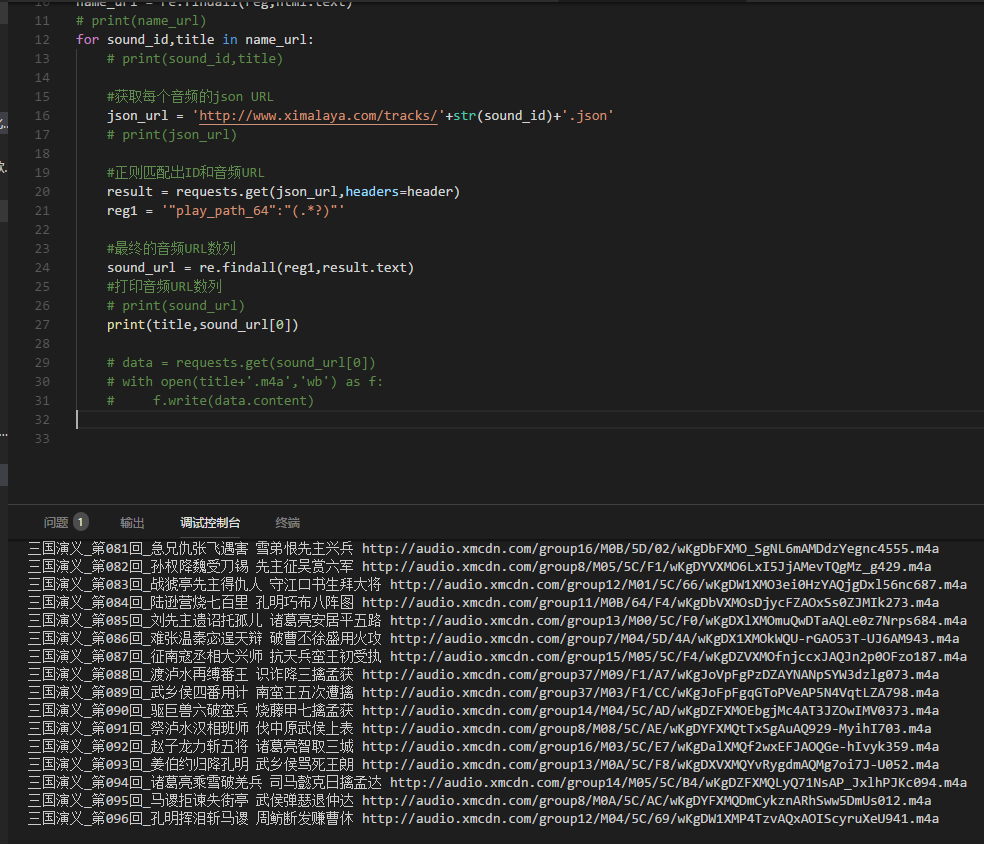
7.既然已经获取到了每个URL,那么现在去json里面取最终的音频URL吧
首先去请求下每个音频的json URL,然后正在匹配出最终的URL吧,另外如果你刚学不久,建议如果你看不懂,建议先去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题多跟里面的人交流,进步更快哦!
- #获取每个音频的json URL
- json_url = 'http://www.ximalaya.com/tracks/'+str(sound_id)+'.json'
- # print(json_url)
- result = requests.get(json_url,headers=header)
- reg1 = '"play_path_64":"(.*?)"'
- #最终的音频URL数列
- sound_url = re.findall(reg1,result.text)
- #打印音频URL数列
- print(title,sound_url)
8.好了,URL都拿到了,可以去下载了。。。
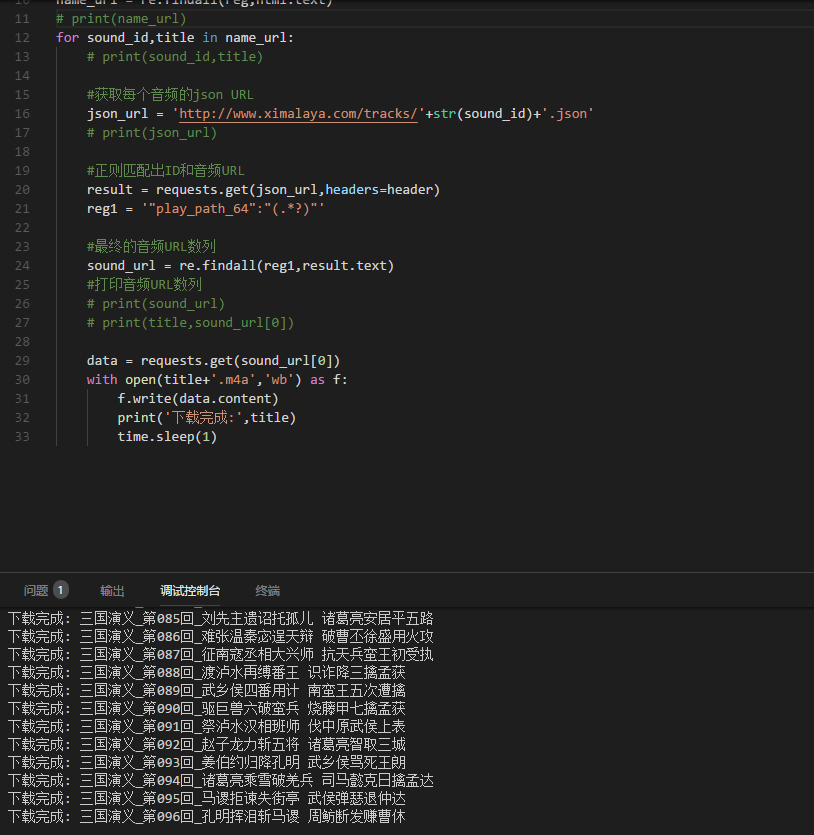
最后,贴上完整代码:
- import requests
- import re
- import time
- #获取网页源代码&解决反爬
- header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
- html = requests.get('http://www.ximalaya.com/4228109/album/268522/',headers=header)
- # print(html.text)
- reg = '<a class="title" href="/4228109/sound/(.*?)/" hashlink title="(.*?)">'
- name_url = re.findall(reg,html.text)
- # print(name_url)
- for sound_id,title in name_url:
- # print(sound_id,title)
- #获取每个音频的json URL
- json_url = 'http://www.ximalaya.com/tracks/'+str(sound_id)+'.json'
- # print(json_url)
- #正则匹配出ID和音频URL
- result = requests.get(json_url,headers=header)
- reg1 = '"play_path_64":"(.*?)"'
- #最终的音频URL数列
- sound_url = re.findall(reg1,result.text)
- #打印音频URL数列
- # print(sound_url)
- # print(title,sound_url[0])
- data = requests.get(sound_url[0])
- with open(title+'.m4a','wb') as f:
- f.write(data.content)
- print('下载完成:',title)
- time.sleep(1)
Python爬虫--喜马拉雅三国音频爬取的更多相关文章
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一.搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界 ...
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
随机推荐
- spring+struts2引起的错误被记忆问题
标题表述的比较模糊,详细情况是这样的: 目前开发的一个管理系统,当使用出现异常时会自动跳转到错误页.其处理流程是“发生异常——跳转到错误处理action——错误页”. 但是出现了一个bug,即某个操作 ...
- Download-学习资源下载
小白求关爱:链接为本人工作中学习所碰到的,如有不对之处,请及时联系加以改正,后续仍会追加新链接地址并及时更新旧链接地址 Jdk历史版本 https://www.oracle.com/technetwo ...
- SpringBoot基本配置详解
SpringBoot项目有一些基本的配置,比如启动图案(banner),比如默认配置文件application.properties,以及相关的默认配置项. 示例项目代码在:https://githu ...
- 在C\C++中char 、short 、int各占多少个字节
在C\C++中char .short .int各占多少个字节 : #include <bits/stdc++.h> using namespace std; int main() { co ...
- hdu 5901 Count primes (meisell-Lehmer)
Count primes Time Limit: 12000/6000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Tot ...
- 搭建Nginx七层反向代理
基于https://www.cnblogs.com/Dfengshuo/p/11911406.html这个基础上,在来补充下七层代理的配置方式.简单理解下四层和七层协议负载的区别吧,四层是网络层,负载 ...
- devicemapper存储驱动下镜像的存储
docker配置devicemapper存储驱动 #查看当前使用的存储驱动,默认为overlay docker info | grep -i storage #停止dockersystemctl st ...
- Django安装和使用---python(3)
一.安装 一般使用cmd 安装就可以 pip install django // 这是最新版本 pip install django==2.0.2(自定义安装2.0.2版本) 手动安装通过下载方式 d ...
- day 24 组合的补充
一.组合的补充: 1.类或对象可以做字典的key 2.对象中到底有什么? # class Foo(object): # # def __init__(self,age): # self.age = a ...
- mysql数据库终端上的增删改查及权限等相关操作
ctrl + c 终止 [linux] service mysql start 启动mysql service mysql stop 停止mysql service mysql restart 重启m ...