【深度学习】K-L 散度,JS散度,Wasserstein距离
度量两个分布之间的差异
(一)K-L 散度
K-L 散度在信息系统中称为相对熵,可以用来量化两种概率分布 P 和 Q 之间的差异,它是非对称性的度量。在概率学和统计学上,我们经常会使用一种更简单的、近似的分布来替代观察数据或太复杂的分布。K-L散度能帮助我们度量使用一个分布来近似另一个分布时所损失的信息量。一般情况下,P 表示数据的真实分布,Q 表示数据的理论分布,估计的模型分布或者 P 的近似分布。
(二)K-L 散度公式
Note:KL 散度仅当概率 \(P\) 和 \(Q\) 各自总和均为1,且对于任何 \(i\) 皆满足 \(Q(i)>0\) , \(P(i)>0\) 时,才有定义。
\[
D_{KL}(P||Q) = - \sum_i P(i) \ln \frac{Q(i)}{P(i)} = \sum_i P(i) \ln \frac{P(i)}{Q(i)}
\]
(三)使用 K-L 散度对比两种分布
假设真实分布为 \(P\),\(P\) 的两个近似分布为 \(Q_1, Q_2\),对于这两个近似分布我们应该选择哪一个?K-L 散度可以解决这个问题:如果 \(D_{KL}(P||Q_1) < D_{KL}(P||Q_2)\),那么我们选择 \(Q_1\) 作为 \(P\) 的近似分布。
(四)散度并非距离
我们不能把 K-L 散度看作是两个分布之间距离的度量。首先距离度量需要满足对称性,但是 K-L 散度不具备对称性,即:
\[
D_{KL}(P||Q) \neq D_{KL}(Q||P)
\]
(五)问答环节
Q1:信息熵,交叉熵,相对熵的区别是什么?
A1:(1)信息熵,即熵,是编码方案完美时的最短平均编码长度;(2)交叉熵,即 Cross Entropy,是编码方案不一定完美时(对概率分布的估计不一定正确)的平均编码长度,在神经网络中常用作损失函数;(3)相对熵,即 K-L 散度,是编码方案不一定完美时,平均编码长度相对于最短平均编码长度的增加值。简单推理:

Q2:为什么在深度学习中使用 Cross Entropy 损失函数,而不是 K-L 散度?
A2:首先,损失函数的功能是衡量由样本计算所得的分布与目标分布之间的差异。在分布差异计算中,K-L散度是最合适的。但在实际中,某一事件的标签是已知不变的(比如猫狗分类中,猫的标签是1,那么数据集中所有关于猫的标签都要标记为1),即目标分布的熵为常数。根据公式:K-L散度 - 目标分布熵 = 交叉熵(这里的 - 代表裁剪),所以我们不用计算K-L散度,只需计算交叉熵就可以得到模型分布与目标分布的损失值。
换句话说,通常一个标签都是设置为 one-hot 模式,即我们常说的硬分布,\(\log1=0\),所以一般都是只用交叉熵。如果标签不是这样的硬分布,而是软分布(比如有两张猫的图片,一张预测为0.6,另一张预测为0.8),K-L散度才能发挥比较好的作用。
Q3:K-L散度和JS散度存在什么问题?有什么解决方法?
A3:如果两个分布 \(P\) 和 \(Q\) 相离很远,甚至完全没有重叠,那么 K-L 散度值是没有意义的,而 JS 散度值是一个常数,意味着梯度为0,即发生了梯度消失,这在学习算法中是非常严重的问题。Wasserstein距离 (又名推土机距离)的提出就是为了解决这个问题,它的优越性在于即使两个分布没有重叠,Wasserstein 距离仍然能够反映它们的远近。以下图为例:
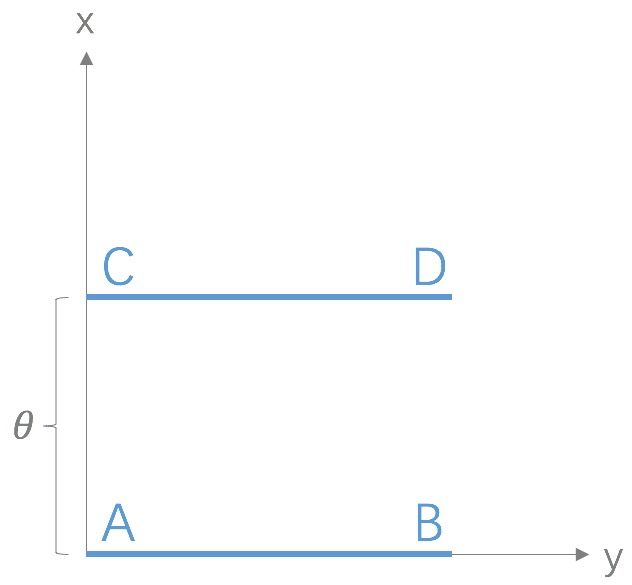
以上是二维空间中的两个分布 \(P_1\) 和 \(P_2\),\(P_1\) 在线段 AB 上均匀分布,\(P_2\) 在线段 CD 上均匀分布,通过参数 \(\theta\) 控制两个分布的距离远近,由以上公式容易得到:
K-L 散度:
\[
D_{KL}(P_1||P_2)=
\begin{cases}
+ \infin & \text{if} & \theta \neq 0 \\
0 & \text{if} & \theta = 0 \\
\end{cases}
\]
JS 散度:
\[
JS(P_1||P_2)=
\begin{cases}
\log2 & \text{if} & \theta \neq 0 \\
0 & \text{if} & \theta = 0 \\
\end{cases}
\]
Wasserstein 距离:
\[
W(P_0, P_1) = |\theta|
\]
观察以上公式可知,K-L 散度和 JS 散度取值是突变的,要么最大要么最小,Wasserstein 距离却是平滑的。如果我们要用梯度下降法优化 \(\theta\) 这个参数,前两者根本提供不了梯度,Wasserstein 距离却可以。类似地,在高维空间中如果两个分布不重叠或者重叠部分可忽略,则 KL 和 JS 既反映不了远近,也提供不了梯度,但是Wasserstein却可以提供有意义的梯度。
References:
[1] 如何理解K-L散度(相对熵)
[2] 相对熵——维基百科
【深度学习】K-L 散度,JS散度,Wasserstein距离的更多相关文章
- 【python深度学习】KS,KL,JS散度 衡量两组数据是否同分布
目录 KS(不需要两组数据相同shape) JS散度(需要两组数据同shape) KS(不需要两组数据相同shape) 奇怪之处:有的地方也叫KL KS距离,相对熵,KS散度 当P(x)和Q(x)的相 ...
- 信息论相关概念:熵 交叉熵 KL散度 JS散度
目录 机器学习基础--信息论相关概念总结以及理解 1. 信息量(熵) 2. KL散度 3. 交叉熵 4. JS散度 机器学习基础--信息论相关概念总结以及理解 摘要: 熵(entropy).KL 散度 ...
- 【GAN与NLP】GAN的原理 —— 与VAE对比及JS散度出发
0. introduction GAN模型最早由Ian Goodfellow et al于2014年提出,之后主要用于signal processing和natural document proces ...
- KL散度与JS散度
1.KL散度 KL散度( Kullback–Leibler divergence)是描述两个概率分布P和Q差异的一种测度.对于两个概率分布P.Q,二者越相似,KL散度越小. KL散度的性质:P表示真实 ...
- Python深度学习读书笔记-1.什么是深度学习
人工智能 什么是人工智能.机器学习与深度学习(见图1-1)?这三者之间有什么关系?
- KL散度、JS散度、Wasserstein距离
1. KL散度 KL散度又称为相对熵,信息散度,信息增益.KL散度是是两个概率分布 $P$ 和 $Q$ 之间差别的非对称性的度量. KL散度是用来 度量使用基于 $Q$ 的编码来编码来自 $P$ 的 ...
- 深度学习中交叉熵和KL散度和最大似然估计之间的关系
机器学习的面试题中经常会被问到交叉熵(cross entropy)和最大似然估计(MLE)或者KL散度有什么关系,查了一些资料发现优化这3个东西其实是等价的. 熵和交叉熵 提到交叉熵就需要了解下信息论 ...
- KL与JS散度学习[转载]
转自:https://www.jianshu.com/p/43318a3dc715?from=timeline&isappinstalled=0 https://blog.csdn.net/e ...
- 深度学习-Wasserstein GAN论文理解笔记
GAN存在问题 训练困难,G和D多次尝试没有稳定性,Loss无法知道能否优化,生成样本单一,改进方案靠暴力尝试 WGAN GAN的Loss函数选择不合适,使模型容易面临梯度消失,梯度不稳定,优化目标不 ...
随机推荐
- C++ std::vector 基本用法2
#include <iostream> #include <vector> using namespace std; int main() { int ar[10] = { 1 ...
- centos安装jdk10
下载一个jdk10文件到linux : wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=ac ...
- 多线程编程学习七( Fork/Join 框架).
一.介绍 使用 java8 lambda 表达式大半年了,一直都知道底层使用的是 Fork/Join 框架,今天终于有机会来学学 Fork/Join 框架了. Fork/Join 框架是 Java 7 ...
- Springcloud 微服务 高并发(实战1):第1版秒杀
疯狂创客圈 Java 高并发[ 亿级流量聊天室实战]实战系列之15 [博客园总入口 ] 前言 前言 疯狂创客圈(笔者尼恩创建的高并发研习社群)Springcloud 高并发系列文章,将为大家介绍三个版 ...
- Python爬虫基础——HTML、CSS、JavaScript、JQuery网页前端技术
一.HTML HTML是Hyper Text Markup Language(超文本标记语言)的缩写. HTML不是一种编程语言,而是标记语言. HTML的语法 双标签: 单标签: HTML的元素和属 ...
- Elasticsearch 6.x版本全文检索学习之集群调优建议
1.系统设置要到位,遵照官方建议设置所有的系统参数. https://www.elastic.co/guide/en/elasticsearch/reference/6.7/setup.html 部署 ...
- NuGet Install-Package 命令
例: Install-Package CefSharp.Wpf -Version 73.1.130 Install-Package CefSharp.Common -Version 73.1.130 ...
- Vim 宏实战操作
宏的概念 什么是宏呢?英文名:macro,代表一串命令的集合. 示例操作文本 SELECT * FROM `edu_ocr_task` WHERE ((`userId`=284871) AND (`u ...
- SSM框架之Mybatis(7)延迟加载、缓存及注解
Mybatis(7)延迟加载.缓存及注解 1.延迟加载 延迟加载: 就是在需要用到数据时才进行加载,不需要用到数据时就不加载数据.延迟加载也称懒加载. **好处:**先从单表查询,需要时再从关联表去关 ...
- react-native 键盘遮挡输入框
Android上已经自动对键盘遮挡输入框做了处理,所以我们只需要关注ios. 1.首先引入 KeyboardAvoidingView import { KeyboardAvoidingView } f ...