牛客网sql刷题解析-完结
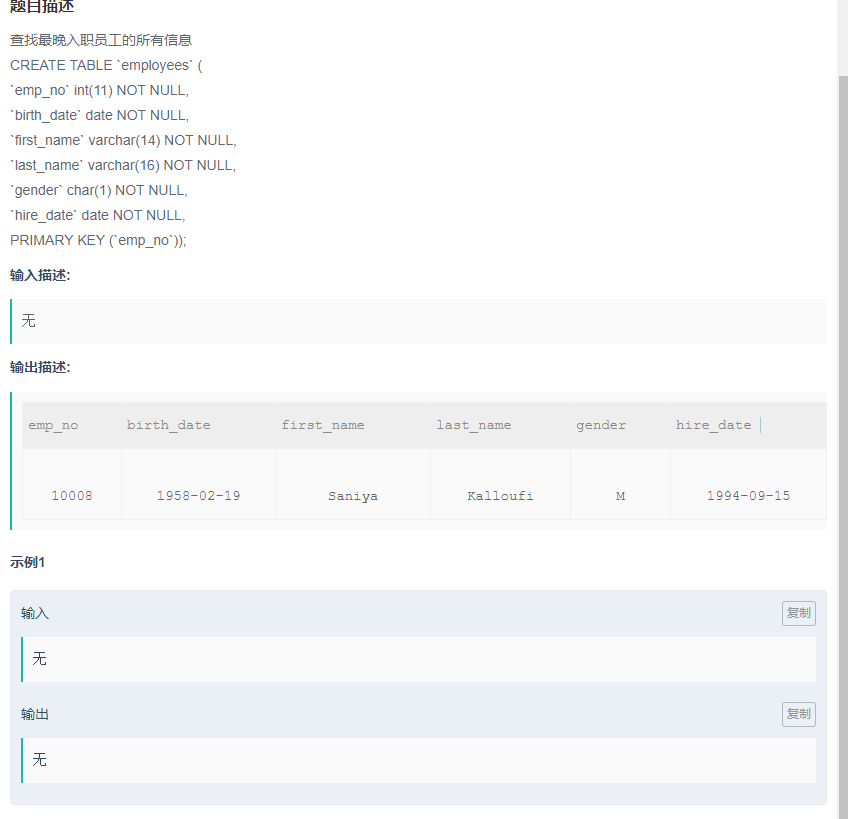
查找最晚入职员工的所有信息
解题步骤:
题目:查询最晚入职员工的所有信息
目标:查询员工的所有信息
筛选条件:最晚入职
答案:
SELECT
*--查询所有信息就用*
FROM
employees
WHERE
hire_date = (--这里是一个子查询,因为要和hire_date匹配,所以只能是一个值,注意max函数使用规则
SELECT
MAX(hire_date)
FROM
employees
)
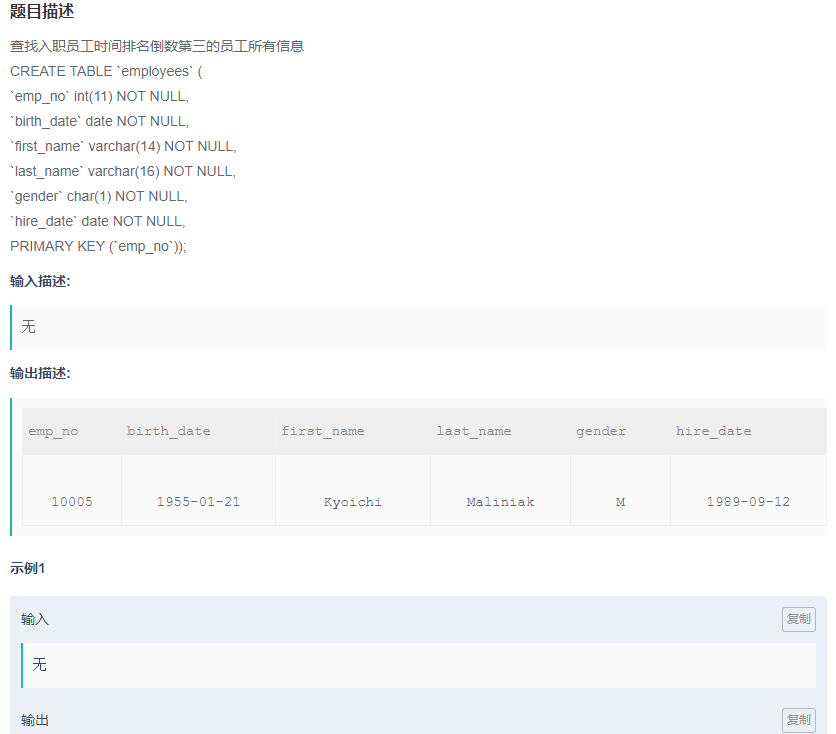
查找入职员工时间排名倒数第三的员工所有信息
解题步骤:
题目:查找入职员工时间排名倒数第三的员工所有信息
目标:查询员工的所有信息
筛选条件:入职时间到第三
答案:
SELECT
*--所有信息,用*省事
FROM
employees
where hire_date = ( SELECT DISTINCT--子查询,注意hire_date是一个值,子查询的返回值一定要是一个
hire_date
FROM
employees
ORDER BY--这里有一个小技巧,倒序排,从第三条取,去一条
hire_date DESC
limit 2,1--分页语法要仔细看看,limit m,n=> 从m+1开始取,取n条
)
查找各个部门当前(to_date='9999-01-01')领导当前薪水详情以及其对应部门编号dept_no

解题步骤:
题目:查找各个部门当前(to_date='9999-01-01')领导当前薪水详情以及其对应部门编号dept_no
目标:查询领导薪水详情,对应部门编号
筛选条件:部门表当前时间,隐藏的条件(薪水表当前时间)
答案:
SELECT
s.*,
d.dept_no
FROM
salaries s--左联到部门表,薪水表人全,所以做主表比较好,不会出现关联出空的情况
LEFT JOIN dept_manager d ON s.emp_no = d.emp_no
WHERE
s.TO_DATE = '9999-01-01'--筛选条件
AND d.TO_DATE = '9999-01-01'
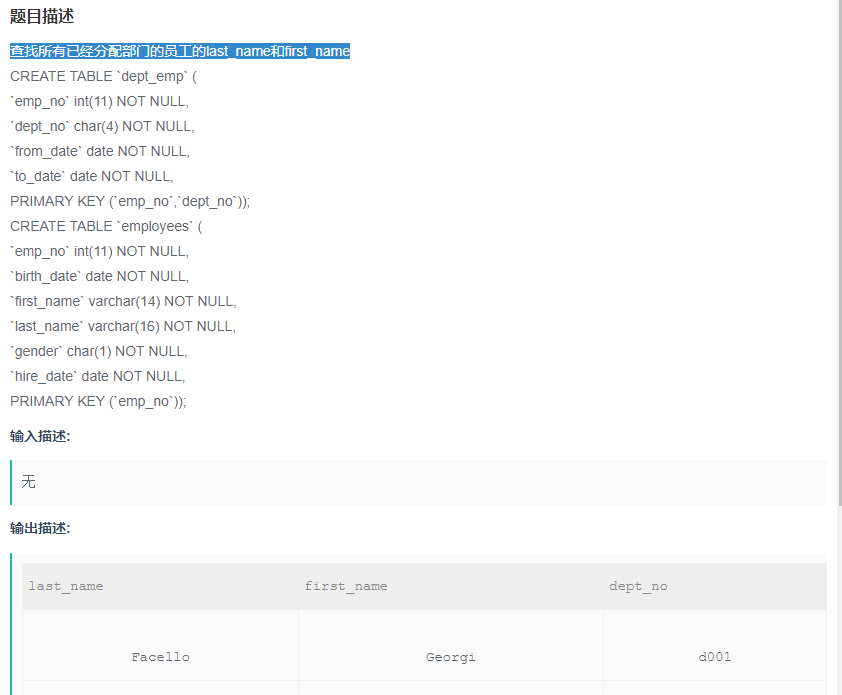
查找所有已经分配部门的员工的last_name和first_name
解题步骤:
题目:查找所有已经分配部门的员工的last_name和first_name
目标:查询员工的 last_name,first_name,题目隐藏要显示dept_no
筛选条件:已分配部门的员工
答案:
SELECT
e.last_name,
e.first_name,
d.dept_no
FROM
employees e--通过左联,确认员工已分配部门
LEFT JOIN dept_emp d ON d.emp_no = e.emp_no
WHERE
d.dept_no != ''--防止关联为空
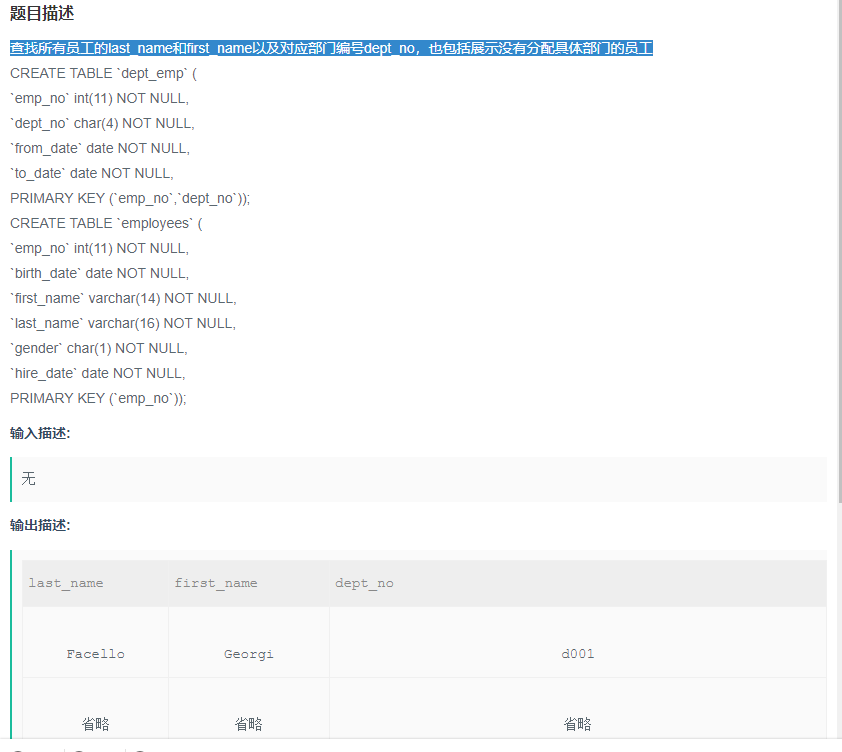
查找所有员工的last_name和first_name以及对应部门编号dept_no,也包括展示没有分配具体部门的员工
解题步骤:
题目:查找所有员工的last_name和first_name以及对应部门编号dept_no,也包括展示没有分配具体部门的员工
目标:查询员工的 last_name,first_name,题目隐藏要显示dept_no,没有分配具体部门的员工
筛选条件:已分配部门的员工
答案:
SELECT
ep.last_name,
ep.first_name,
dp.dept_no
FROM
employees ep --人员信息表为主表,左联,一位部门可能为空,所以关联后就会包含未分配部分的人
LEFT JOIN dept_emp dp ON ep.emp_no = dp.emp_no
查找所有员工入职时候的薪水情况,给出emp_no以及salary, 并按照emp_no进行逆序
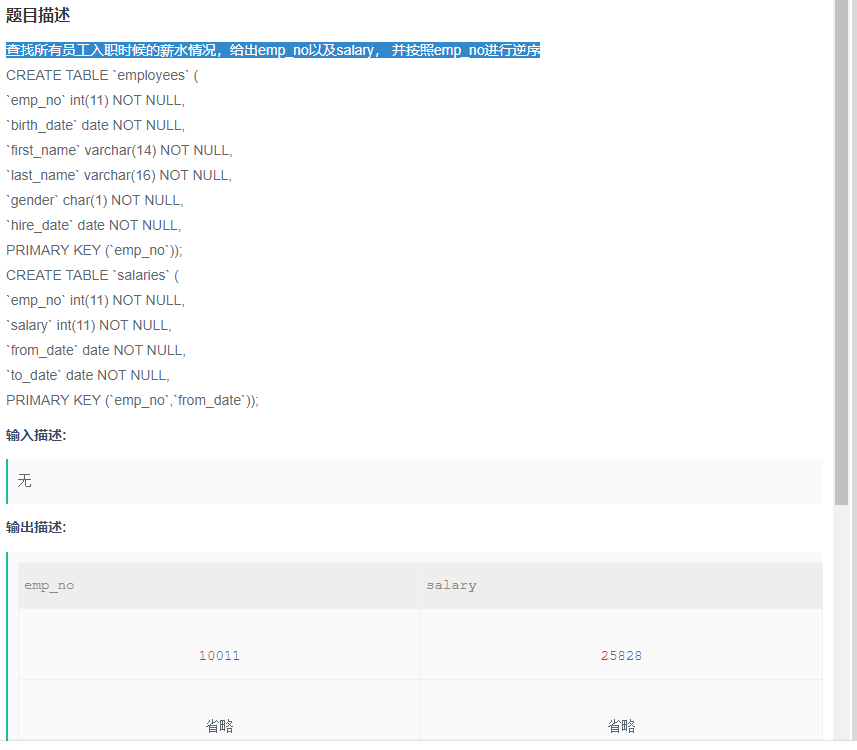
解题步骤:
题目:查找所有员工入职时候的薪水情况,给出emp_no以及salary, 并按照emp_no进行逆序
目标: 查询薪水情况,显示emp_no以及salary(select 要显示的字段)
筛选条件:员工入职时间,并按照emp_no进行逆序
答案:
SELECT --显示字段
e.emp_no,
s.salary
FROM
employees e
LEFT JOIN salaries s ON e.emp_no = s.emp_no --确定是同一个人
AND e.hire_date = s.from_date --确定是入职时间
ORDER BY
e.emp_no DESC --倒序
查找薪水涨幅超过15次的员工号emp_no以及其对应的涨幅次数t
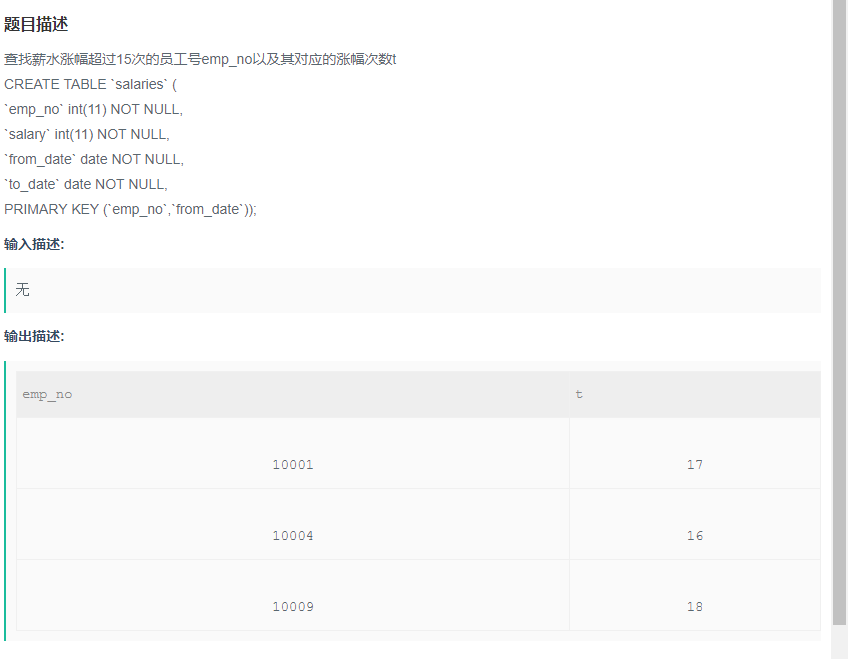
解题步骤:
题目:查找薪水涨幅超过15次的员工号emp_no以及其对应的涨幅次数t
目标: 查找员工号,涨幅次数(select 要显示的字段)
筛选条件:涨幅超过15次
答案:
SELECT
emp_no,
SUM(1) --统计次数;
FROM
salaries
GROUP BY
emp_no --对每一个员工进行分组,然后统计其涨幅次数
HAVING
COUNT(1) > 15 --进行次数过滤
如果想详细了解 sum(1),可以看这个文章:https://blog.csdn.net/qq_39313596/article/details/80623495
找出所有员工当前(to_date='9999-01-01')具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆序显示
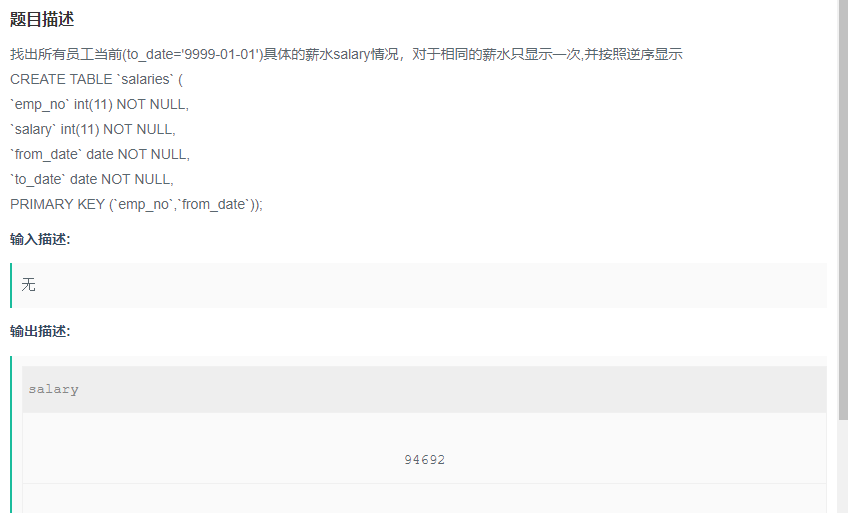
解题步骤:
题目:找出所有员工当前(to_date='9999-01-01')具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆序显示
目标: 查找薪水(select 要显示的字段)
筛选条件:当前时间(to_date),相同的仅显示一次,逆序显示
答案:
SELECT DISTINCT --去重
salary
FROM
salaries
WHERE
TO_DATE = '9999-01-01'
ORDER BY
salary DESC --倒序
获取所有部门当前manager的当前薪水情况,给出dept_no, emp_no以及salary,当前表示to_date='9999-01-01'
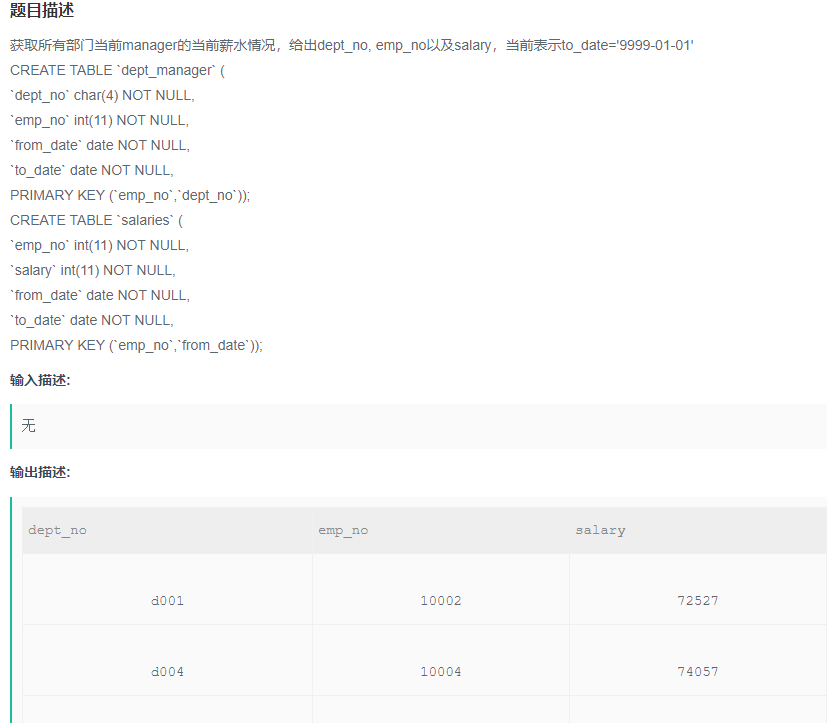
解题步骤:
题目:获取所有部门当前manager的当前薪水情况,给出dept_no, emp_no以及salary,当前表示to_date='9999-01-01'
目标: 查找dept_no, emp_no以及salary(select 要显示的字段)
筛选条件:当前表示to_date='9999-01-01'
答案:
SELECT
d.dept_no,
s.emp_no,
s.salary
FROM --注意左关联条件
dept_manager d
LEFT JOIN salaries s ON d.emp_no = s.emp_no
AND d.TO_DATE = s.TO_DATE
WHERE
d.TO_DATE = '9999-01-01'
获取所有非manager的员工emp_no

解题步骤:
题目:获取所有非manager的员工emp_no
目标: 查找emp_no(select 要显示的字段)
筛选条件:非manager的员工
答案:
SELECT
em.emp_no
FROM
employees em
WHERE
NOT EXISTS ( --此处用了一个exists表达式,是管理者的员工,然后将这些排除就时非管理员的员工,此处也可以用not in,但是效率会降低一些
SELECT
1
FROM
dept_manager dm
WHERE
em.emp_no = dm.emp_no
)
题外闲谈:exists,in;语法上区别,效率上区别;没有觉得效率高低,看实际场景
这俩篇文章说的不错,再次就不再赘述,唯一要注意的是exists的返回值是真或者假:https://blog.csdn.net/baidu_37107022/article/details/77278381,https://www.cnblogs.com/xuyufengme/p/9175929.html
获取所有员工当前的manager,如果当前的manager是自己的话结果不显示,当前表示to_date='9999-01-01'。
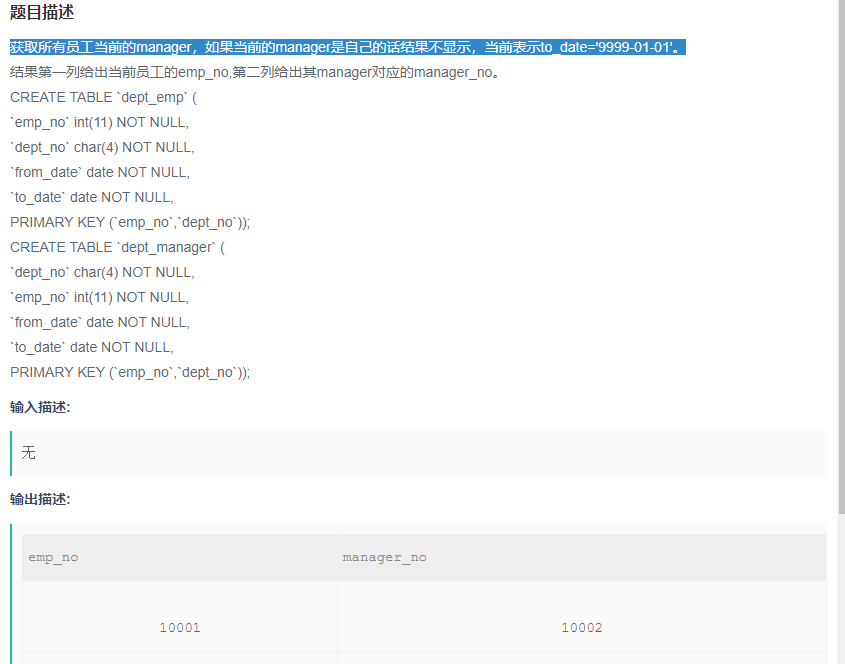
解题步骤:
题目:获取所有员工当前的manager,如果当前的manager是自己的话结果不显示,当前表示to_date='9999-01-01'
目标: 查找员工,当前的manager(select 要显示的字段)
筛选条件:当前表示to_date='9999-01-01',如果当前的manager是自己的话结果不显示
答案:
SELECT
de.emp_no,
dm.emp_no AS manager_no
FROM
dept_emp de
LEFT JOIN dept_manager dm ON de.dept_no = dm.dept_no
WHERE
de.emp_no != dm.emp_no
AND de.TO_DATE = '9999-01-01'
AND dm.TO_DATE = '9999-01-01'
获取所有部门中当前员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary
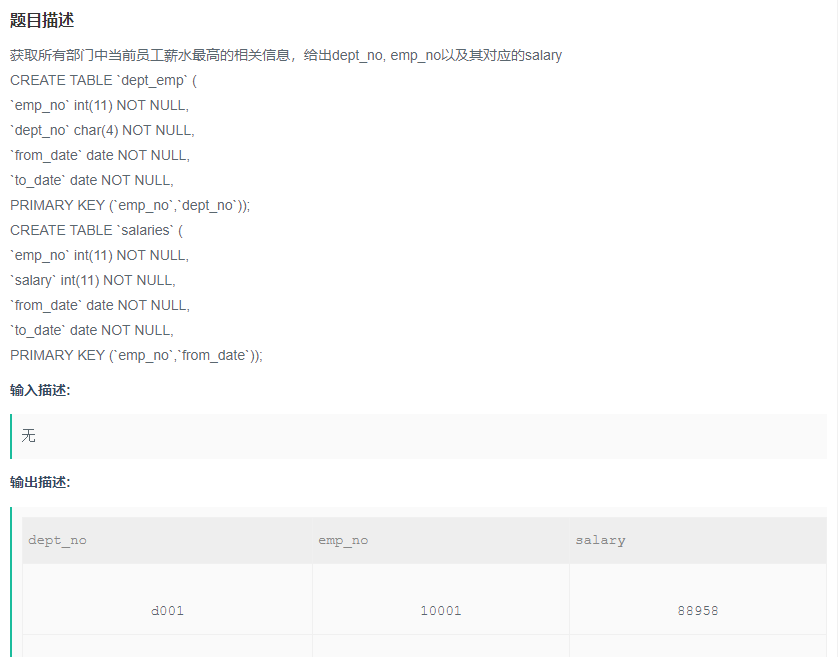
解题步骤:
题目:获取所有部门中当前员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary
目标: 查找部门,员工,薪水(select 要显示的字段)
筛选条件:当前表示to_date='9999-01-01',
答案:
SELECT
de.dept_no,
de.emp_no,
MAX(sa.salary) --注意函数使用时机,什么时候需要group by,什么时候不需要
FROM
dept_emp de
LEFT JOIN salaries sa ON de.emp_no = sa.emp_no
WHERE
de.TO_DATE = '9999-01-01' --题目中默认为当前时间
AND sa.TO_DATE = '9999-01-01'
GROUP BY
de.dept_no --每个部门中最高的薪水的人,所以需要按照部门分组
从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。
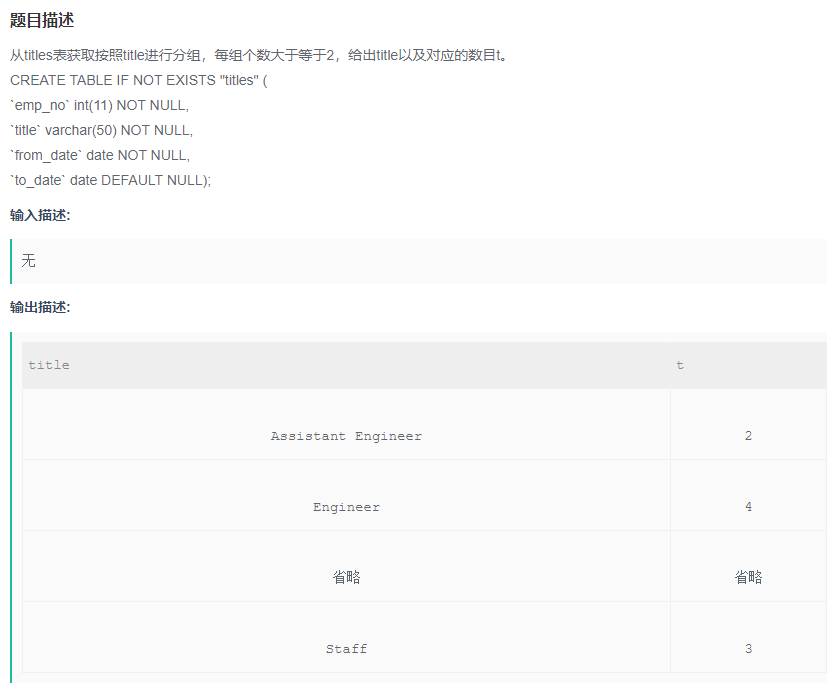
解题步骤:
题目:从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。
目标: 查找title以及对应的数目t(select 要显示的字段)
筛选条件:按照title进行分组,每组个数大于等于2
SELECT
title,
COUNT(1) AS t
FROM
titles
GROUP BY
title --分组
HAVING --配合分组使用,作用和where差不多
COUNT(1) >= 2
从titles表获取按照title进行分组,注意对于重复的emp_no进行忽略。
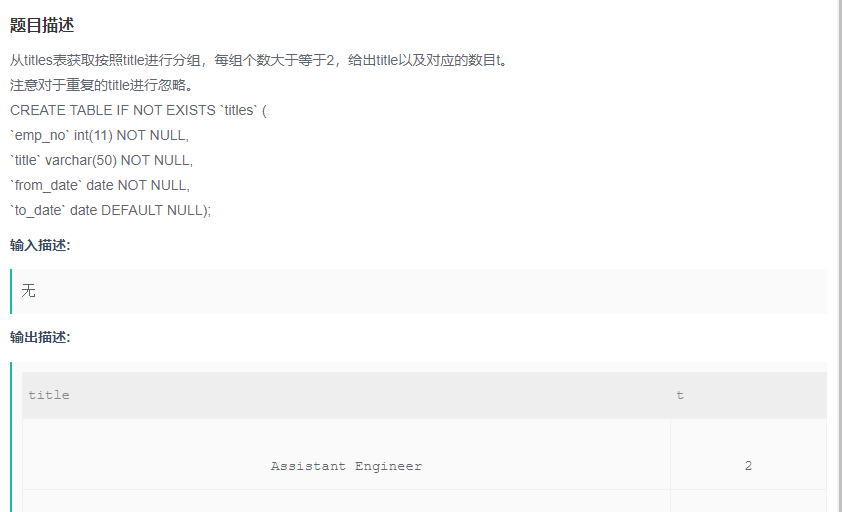
解题步骤:
题目:从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。
注意对于重复的title进行忽略。
目标: 查找title以及对应的数目t(select 要显示的字段)
筛选条件:按照title进行分组,每组个数大于等于2,注意对于重复的title进行忽略。
SELECT
title,
COUNT(DISTINCT(emp_no)) AS t --本题关键是对于重复的title进行忽略。也就是计数的时候要去重,注意 函数和distinct的使用方法
FROM
titles
GROUP BY
title
HAVING
COUNT(1) >= 2
关于count(distinct)的延伸
sql-按条件统计非重复值,count(distinct case when)使用
背景 项目中,遇到一个统计需求,从某张表中按照条件分别统计。刚开始想到用union all的写法,太臃肿,后来使用count(distinct case when)解决此问题 count 数据统计中,count出现最频繁 最简单的用法 select count(*) from table where .... select count(distinct xx) from table where ... 但最简单的用法也有其深刻的地方,比如这里其实有3种写法,count(1)、count(*)、count(字段),它们有什么区别呢? count(1) 和 count(*)
count(1)和count(*)差别不大,使用count(*)时,sql会帮你自动优化,指定到最快的字段。所以推荐使用count(*) count(*) 和 count(字段)
count(*)会统计所有行数,count(字段)不会统计null值 count(case when) 条件统计,即对某个table分条件统计,比如表test_db,有一个字段user_id(可能重复), gender(man、women),需要统计man和women的人数 可以使用where分别统计 select count(distinct user_id) as man_cnt from test_db where gender = 'man' select count(distinct user_id) as women_cnt from test_db where gender = 'women' 也可以使用按条件统计 select count(distinct case gender = 'man' then user_id end) as man_cnt --至于case when,本人没用过,不过也很少有这个使用场景吧 , count(distinct case gender = 'women' then user_id end) as woman_cnt from test_db
查找employees表所有emp_no为奇数,且last_name不为Mary的员工信息,并按照hire_date逆序排列
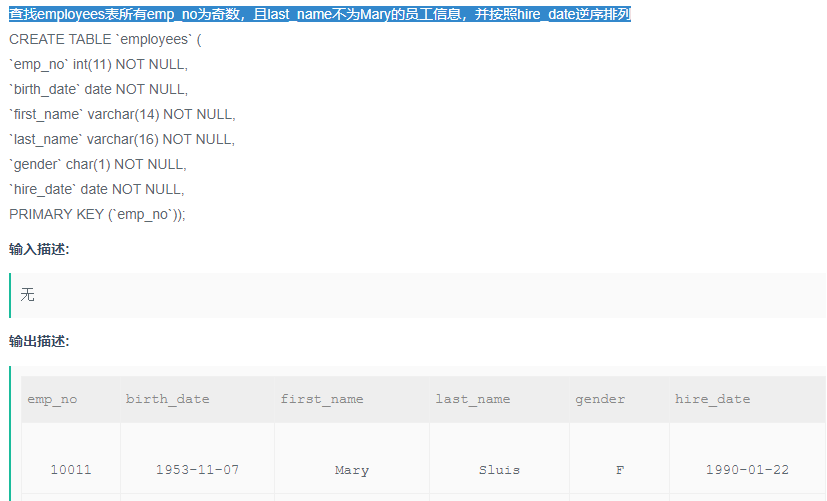
解题步骤:
题目:查找employees表所有emp_no为奇数,且last_name不为Mary的员工信息,并按照hire_date逆序排列
目标: 查找所有员工信息(select 要显示的字段)
筛选条件:ast_name不为Mary,emp_no为奇数
SELECT
*
FROM
employees
where emp_no%2 != 0 --如果emp_no为索引列,会导致索引失效
AND last_name != 'Mary'
order by hire_date desc
拓展:索引列上计算引起的索引失效及优化措施以及注意事项;索引失效的情况有哪些?索引何时会失效?(全面总结)
两个示例
例子一 表结构 DROP TABLE IF EXISTS `account`;
CREATE TABLE IF NOT EXISTS `account` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`account` int(10) unsigned NOT NULL,
`password` char(32) NOT NULL,
`ip` char(15) NOT NULL,
`time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `time` (`time`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
比如要统计2012年08月15日注册的会员数: SELECT count(id) FROM account WHERE DATEDIFF("2012-08-15",time)=0
例子二 表结构 DROP TABLE IF EXISTS `active`;
CREATE TABLE IF NOT EXISTS `user` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`userid` int(10) unsigned NOT NULL,
`lastactive` int(10) unsigned NOT NULL,
PRIMARY KEY (`id`),
KEY `lastactive` (`lastactive`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
统计最近3分钟的活跃用户 SELECT count(id) FROM user WHERE unix_timstamp()-lastactive < 180 以上两个例子中,虽然都建有索引,但是SQL执行中却不走索引,而采用全表扫描。 原因揭密
SQL语句where中如果有functionName(colname)或者某些运算,则MYSQL无法使用基于colName的索引。使用索引需要直接查询某个字段。 索引失效的原因是索引是针对原值建的二叉树,将列值计算后,原来的二叉树就用不上了; 为了解决索引列上计算引起的索引失效问题,将计算放到索引列外的表达式上。 解决办法
例子一:SELECT count(id) FROM account WHERE time between "2012-08-15 00:00:00" and "2012-08-15 23:59:59" 例子二:SELECT count(id) FROM user WHERE lastactive > unix_timstamp() - 180 相关内容
1、如果对时间字段进行查找,可以将时间设置为int unsigned类型,存取UNIX时间戳。因为整型比较速度快
2、当我们执行查询的时候,MySQL只能使用一个索引。
3、MySQL只有对以下操作符才使用索引: < , <= , = , > , >= , BETWEEN , IN ,以及某些时候的LIKE。可以在LIKE操作中使用索引的情形是指另一个操作数不是以通配符( % 或者 _ )开头的情形。例如, “SELECT peopleid FROM people WHERE firstname LIKE 'Mich%';” 这个查询将使用索引,但 “SELECT peopleid FROM people WHERE firstname LIKE '%ike';” 这个查询不会使用索引。 不得不说
创建索引、优化查询以便达到更好的查询优化效果。但实际上,MySQL有时并不按我们设计的那样执行查询。MySQL是根据统计信息来生成执行计划的,这就涉及索引及索引的刷选率,表数据量,还有一些额外的因素。 Each table index is queried, and the best index is used unless the optimizer believes that it is more efficient to use a table scan. At one time, a scan was used based on whether the best index spanned more than 30% of the table, but a fixed percentage no longer determines the choice between using an index or a scan. The optimizer now is more complex and bases its estimate on additional factors such as table size, number of rows, and I/O block size. 简而言之,当MYSQL认为符合条件的记录在30%以上,它就不会再使用索引,因为mysql认为走索引的代价比不用索引代价大,所以优化器选择了自己认为代价最小的方式。事实也的确如此 实例检测
表结构 DROP TABLE IF EXISTS `active`;
CREATE TABLE IF NOT EXISTS `active` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`userid` int(10) unsigned NOT NULL,
`lastactive` int(10) unsigned NOT NULL,
PRIMARY KEY (`id`),
KEY `lastactive` (`lastactive`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
插入数据 insert into active values
(null,10000, unix_timestamp("2012-08-20 15:10:02")),
(null,10001, unix_timestamp("2012-08-20 15:10:02")),
(null,10002, unix_timestamp("2012-08-20 15:10:03")),
(null,10003, unix_timestamp("2012-08-20 15:10:03")),
(null,10004, unix_timestamp("2012-08-20 15:10:03")),
(null,10005, unix_timestamp("2012-08-20 15:10:04")),
(null,10006, unix_timestamp("2012-08-20 15:10:04")),
(null,10007, unix_timestamp("2012-08-20 15:10:05")),
(null,10008, unix_timestamp("2012-08-20 15:10:06"))
explain select * from active where lastactive > unix_timestamp()-3; 上面这句索引起作用。 但是我在测试中,因为插入的日期与我测试的当前日期相差不少时间。所以我改写为以下内容: explain select * from active where lastactive > unix_timestamp("2012-08-20 15:10:06") - 3; 但是数据显示,TYPE为ALL,key为NULL。也就是说索引不起作用。 我在改写以下语句测试: explain select * from active where lastactive > unix_timestamp("2012-08-20 15:10:06"); 上面这个语句,索引又起作用了。 一个疑惑
正好手头上有一个12016条记录的数据,证实一下“当MYSQL认为符合条件的记录在30%以上,它就不会再使用索引”的结论。经过测试,在总记录12016条记录的表中,查询小于1854条记录时走索引,大于该记录时不走索引。符合条件的记录在15.4%。这....,30%的数据可能有待确认,正如上面说的那样,MySQL的优化器是考虑多方面因素,并选择自己认为代价最小的方式。 mysql自己判断是否使用索引,如果你自己确信使用索引可以提高效率,你也可以强行实用索引force index(index_name)
统计出当前各个title类型对应的员工当前(to_date='9999-01-01')薪水对应的平均工资。结果给出title以及平均工资avg。
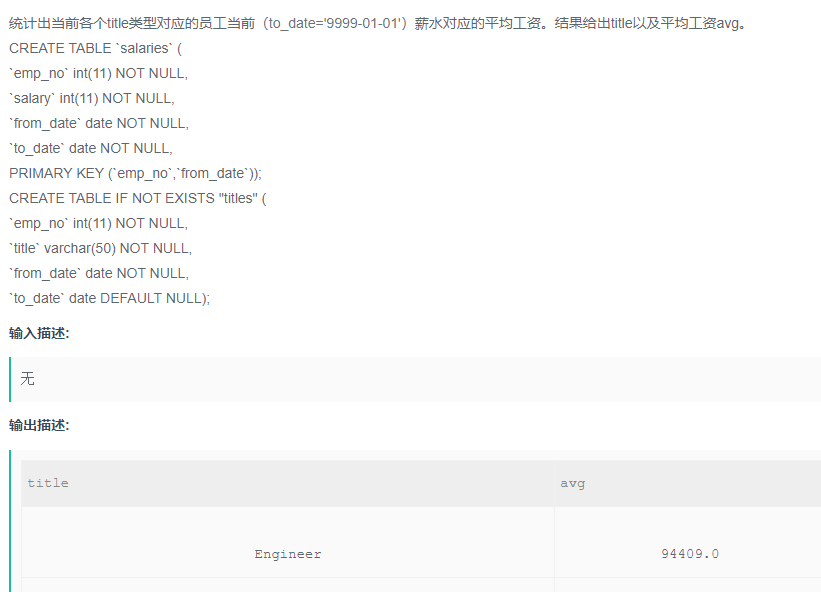
解题步骤:
题目:统计出当前各个title类型对应的员工当前(to_date='9999-01-01')薪水对应的平均工资。结果给出title以及平均工资avg。
目标: 查找结果给出title以及平均工资avg。(select 要显示的字段)
筛选条件:默认为当前时间
SELECT
t.title,
AVG(s.salary) AS avg
FROM
salaries s
LEFT JOIN titles t ON s.emp_no = t.emp_no
WHERE
s.TO_DATE = '9999-01-01'
AND t.TO_DATE = '9999-01-01'
GROUP BY
t.title
获取当前(to_date='9999-01-01')薪水第二多的员工的emp_no以及其对应的薪水salary
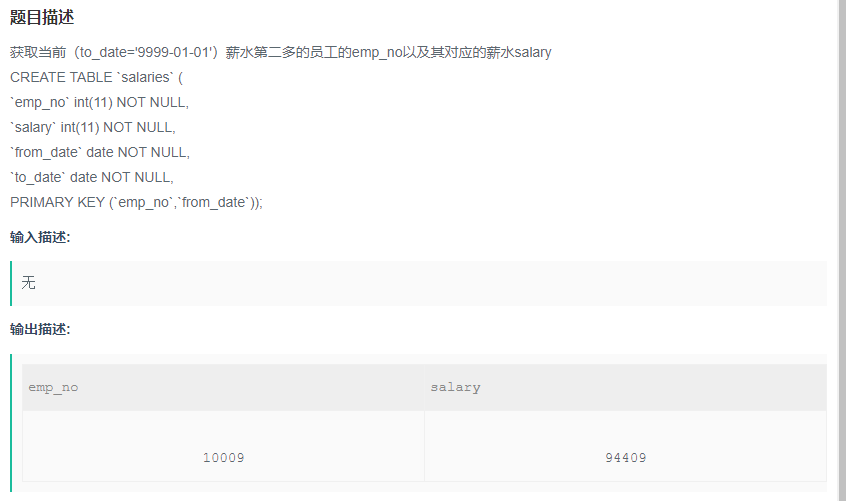
题目:获取当前(to_date='9999-01-01')薪水第二多的员工的emp_no以及其对应的薪水salary
目标: 查找emp_no以及其对应的薪水salary(select 要显示的字段)
筛选条件:薪水第二多
SELECT
emp_no,
salary
FROM
salaries
WHERE
TO_DATE = '9999-01-01'
ORDER BY
salary DESC --本题精髓,第二多,可以理解成倒序排第二的人
limit
1,1 --从第二条开始,去一条;也就是取得第二条
查找员工编号emp_no为10001其自入职以来的薪水salary涨幅值growth
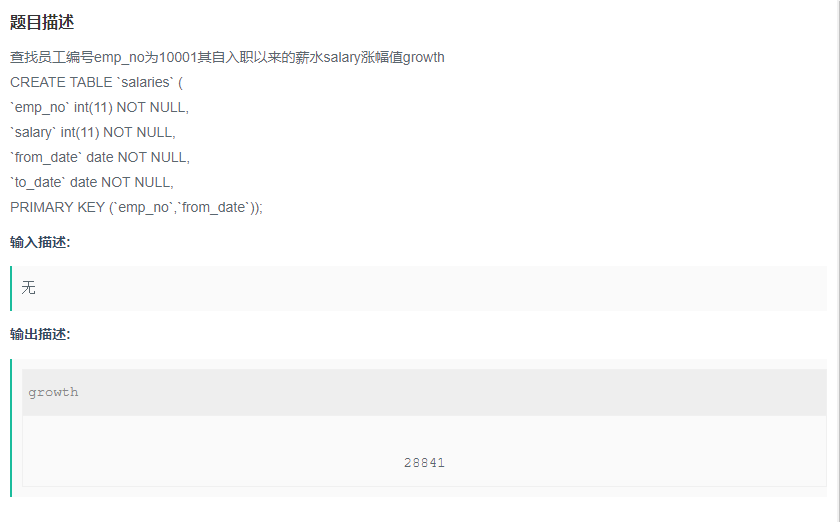
题目:查找员工编号emp_no为10001其自入职以来的薪水salary涨幅值growth
目标: 查找涨幅值growth(select 要显示的字段)
筛选条件:自入职以来,号emp_no为10001
SELECT
MAX(salary) - MIN(salary) AS growth --函数的使用,计算,以及起别名 as的语法
FROM
salaries
WHERE
emp_no = '';
针对actor表创建视图actor_name_view,只包含first_name以及last_name两列,并对这两列重新命名,first_name为first_name_v,last_name修改为last_name_v:

终于到了听起来牛逼点的题目啦!!!,其实也没啥~~~,还是查询
题目:针对actor表创建视图actor_name_view,只包含first_name以及last_name两列,并对这两列重新命名,first_name为first_name_v,last_name修改为last_name_v:
目标: 创建这个视图
筛选条件:
CREATE VIEW actor_name_view AS
SELECT
first_name AS first_name_v,
last_name AS last_name_v
FROM
actor
针对salaries表emp_no字段创建索引idx_emp_no,查询emp_no为10005, 使用强制索引。
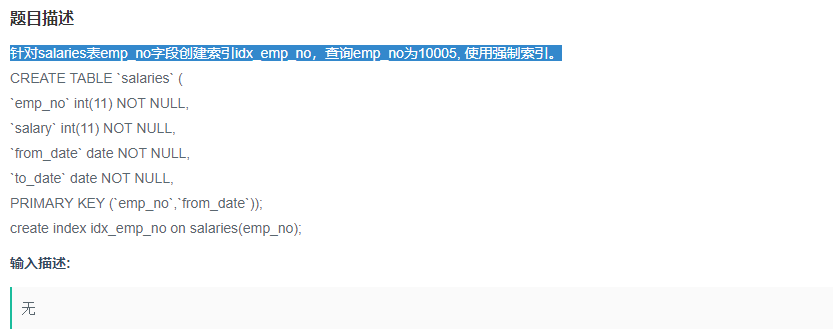
题目:针对salaries表emp_no字段创建索引idx_emp_no,查询emp_no为10005, 使用强制索引。
目标:使用强制索引
筛选条件:
SELECT
*
FROM
salaries indexed
by idx_emp_no --使用强制索引
WHERE
emp_no = 10005
拓展:使用强制索引的案例
在last_update后面新增加一列名字为create_date
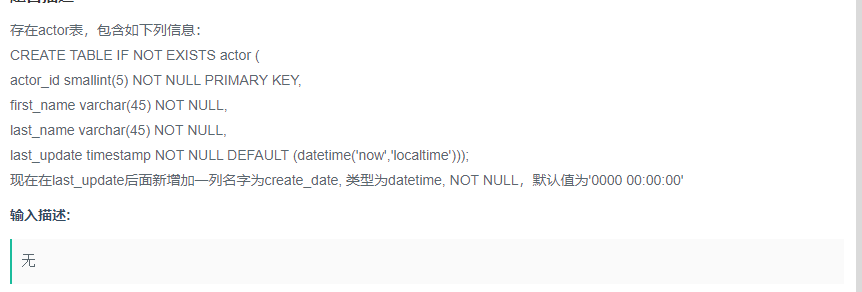
题目:修改表结构,用sql(这样比手写显得牛逼)
目标:alter用法
筛选条件:
ALTER TABLE actor ADD 'create_date' datetime NOT NULL DEFAULT '0000-00-00 00:00:00'
构造一个触发器audit_log,在向employees_test表中插入一条数据的时候,触发插入相关的数据到audit中。

题目: 构造一个触发器audit_log,在向employees_test表中插入一条数据的时候,触发插入相关的数据到audit中。(听着就很高级,虽然实际中从未用过)
目标:
筛选条件:
CREATE TRIGGER audit_log AFTER
INSERT ON employees_test
BEGIN
INSERT INTO audit VALUES (
new.id,
new.name
); END;
使用含有关键字exists查找未分配具体部门的员工的所有信息。
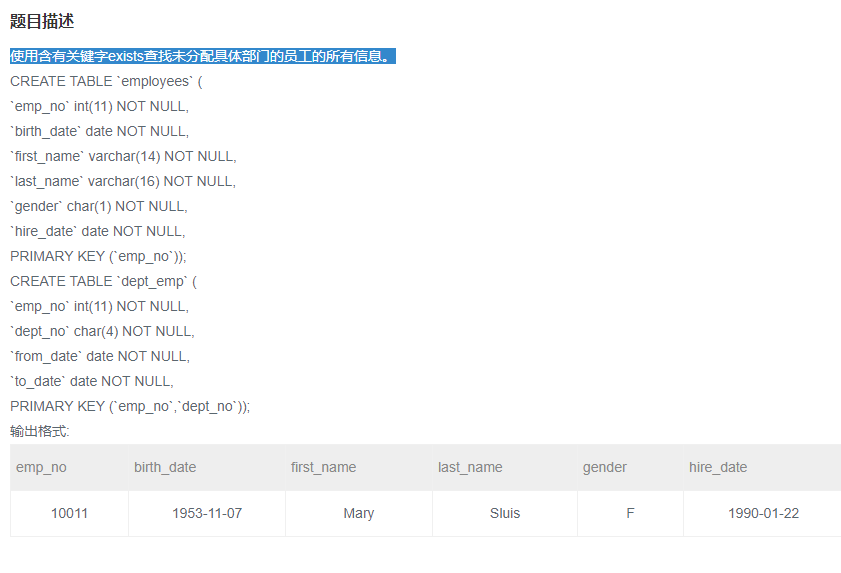
题目: 使用含有关键字exists查找未分配具体部门的员工的所有信息。
目标:查找员工的所有信息。
筛选条件:未分配具体部门
SELECT
*
FROM
employees e
WHERE
NOT EXISTS ( --就是exists的使用,上面有详细讲解过的,注意返回值是逻辑真假
SELECT
1
FROM
dept_emp de
WHERE
e.emp_no = de.emp_no
)
牛客网sql刷题解析-完结的更多相关文章
- 牛客网Java刷题知识点之什么是进程、什么是线程、什么是多线程、多线程的好处和弊端、多线程的创建方式、JVM中的多线程解析、多线程运行图解
不多说,直接上干货! 什么是进程? 正在进行中的程序(直译). 什么是线程? 就是进程中一个负责程序执行的控制单元(执行路径). 见 牛客网Java刷题知识点之进程和线程的区别 什么是多线程? 一个进 ...
- 牛客网Java刷题知识点之TCP、UDP、TCP和UDP的区别、socket、TCP编程的客户端一般步骤、TCP编程的服务器端一般步骤、UDP编程的客户端一般步骤、UDP编程的服务器端一般步骤
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- 牛客网Java刷题知识点之为什么HashMap和HashSet区别
不多说,直接上干货! HashMap 和 HashSet的区别是Java面试中最常被问到的问题.如果没有涉及到Collection框架以及多线程的面试,可以说是不完整.而Collection框架的 ...
- 牛客网Java刷题知识点之为什么HashMap不支持线程的同步,不是线程安全的?如何实现HashMap的同步?
不多说,直接上干货! 这篇我是从整体出发去写的. 牛客网Java刷题知识点之Java 集合框架的构成.集合框架中的迭代器Iterator.集合框架中的集合接口Collection(List和Set). ...
- 牛客网Java刷题知识点之Map的两种取值方式keySet和entrySet、HashMap 、Hashtable、TreeMap、LinkedHashMap、ConcurrentHashMap 、WeakHashMap
不多说,直接上干货! 这篇我是从整体出发去写的. 牛客网Java刷题知识点之Java 集合框架的构成.集合框架中的迭代器Iterator.集合框架中的集合接口Collection(List和Set). ...
- 牛客网Java刷题知识点之ArrayList 、LinkedList 、Vector 的底层实现和区别
不多说,直接上干货! 这篇我是从整体出发去写的. 牛客网Java刷题知识点之Java 集合框架的构成.集合框架中的迭代器Iterator.集合框架中的集合接口Collection(List和Set). ...
- 牛客网Java刷题知识点之垃圾回收算法过程、哪些内存需要回收、被标记需要清除对象的自我救赎、对象将根据存活的时间被分为:年轻代、年老代(Old Generation)、永久代、垃圾回收器的分类
不多说,直接上干货! 首先,大家要搞清楚,java里的内存是怎么分配的.详细见 牛客网Java刷题知识点之内存的划分(寄存器.本地方法区.方法区.栈内存和堆内存) 哪些内存需要回收 其实,一般是对堆内 ...
- 牛客网Java刷题知识点之HashMap的实现原理、HashMap的存储结构、HashMap在JDK1.6、JDK1.7、JDK1.8之间的差异以及带来的性能影响
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
- 牛客网Java刷题知识点之UDP协议是否支持HTTP和HTTPS协议?为什么?TCP协议支持吗?
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
随机推荐
- Solr实现全文搜索
1.1 Solr是什么? Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器.Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置.可扩展 ...
- Kafka 的No kafka server to stop报错处理
使用kafka-server-stop.sh命令关闭kafka服务,发现无法删除,报错如下图No kafka server to stop 下面修改kafka-server-stop.sh将 PIDS ...
- 【转载】【笔记】vue-router之路由传递参数
参考博客地址:https://blog.51cto.com/4547985/2390799 1.通过<router-link> 标签中的to传参 基本语法: <router-link ...
- unittest---unittest中verbosity参数设置
我们在做自动化测试的时候,有时候想要很清楚的看到每条用例执行的详细信息,我们可以通过unittest中verbosity参数进行设置 verbosity参数设置 verbosity表示在只执行用例的过 ...
- JMeter系列教程
认识JMeter工具 JMeter常用元件功能介绍 JMeter线程组 JMeter脚本三种录制方法 Jmeter组件介绍及其作用域和执行顺序 JMeter参数化 JMeter集合点 JMeter关联 ...
- Less(6)
1.先判断注入类型 (1)首先看到要求,要求传一个ID参数,并且要求是数字型的:?id=1 (2)再输入?id=1' (3)再输入?id=1 and 1=1 (4)再输入?id=1 and 1=2 ( ...
- 【使用篇二】SpringBoot集成SpringSecurity(22)
SpringSecurity是专门针对基于Spring项目的安全框架,充分利用了依赖注入和AOP来实现安全管控.在很多大型企业级系统中权限是最核心的部分,一个系统的好与坏全都在于权限管控是否灵活,是否 ...
- laravel实现多模块
一.这里使用Caffienate Modules 网址:modules maintained by caffeinated 二.根据自己的版本选择包的版本 三.在项目composer.json文件中加 ...
- 【Linux命令】用户身份(useradd,groupadd,usermod,passwd,userdel)
目录 用户身份 useradd userdel usermod groupadd groupdel passwd chage 用户身份 在linux系统中和windows一样有用户之分.root用户为 ...
- Linux系统:centos7下搭建Nginx和FastDFS文件管理中间件
本文源码:GitHub·点这里 || GitEE·点这里 一.FastDFS简介 1.基础概念 FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储.文件同步.文件上传 ...