MapReduce案例-好友推荐
用过各种社交平台(如QQ、微博、朋友网等等)的小伙伴应该都知道有一个叫 "可能认识" 或者 "好友推荐" 的功能(如下图)。它的算法主要是根据你们之间的共同好友数进行推荐,当然也有其他如爱好、特长等等。共同好友的数量越多,表明你们可能认识,系统便会自动推荐。今天我将向大家介绍如何使用MapReduce计算共同好友
算法
假设有以下好友列表,A的好友有B,C,D,F,E,O; B的好友有A,C,E,K 以此类推
那我们要如何算出A-O用户每个用户之间的共同好友呢?
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
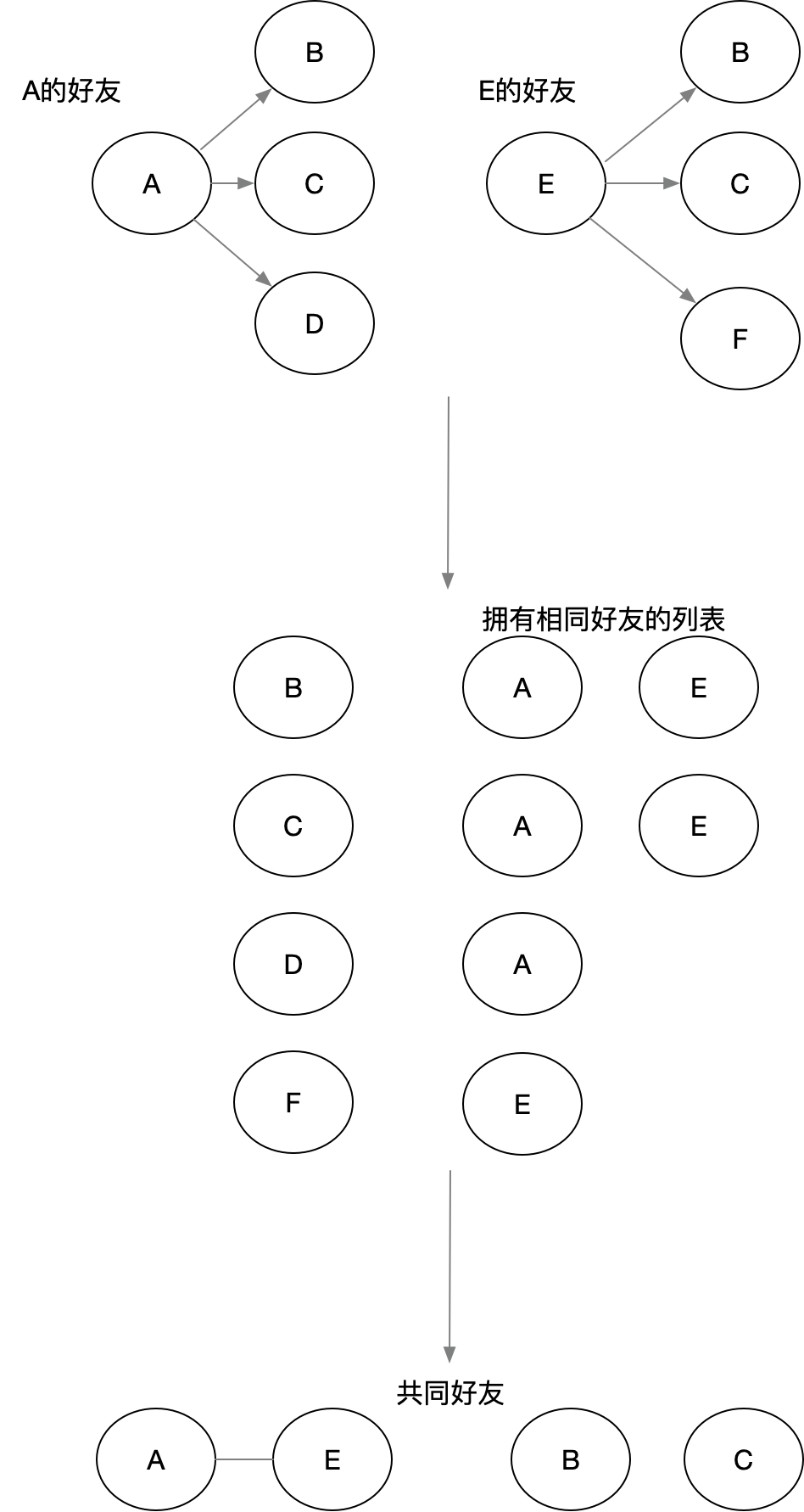
下面我们将演示分步计算,思路主要如下:先算出某个用户是哪些用户的共同好友,
如A是B,C,D,E等的共同好友。遍历B,C,D,E两两配对如(B-C共同好友A,注意防止重复B-C,C-B)作为key放松给reduce端,
这样reduce就会收到所有B-C的共同好友的集合。可能到这里你还不太清楚怎么回事,下面我给大家画一个图。
代码演示
由上可知,此次计算由两步组成,因此需要两个MapReduce程序先后执行
第一步:通过mapreduce得到 某个用户是哪些用户的共同好友。
public class FriendsDemoStepOneDriver {
static class FriendsDemoStepOneMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(":");
String user = split[0];
String[] friends = split[1].split(",");
for (String friend : friends) {
// 输出友人,人。 这样的就可以得到哪个人是哪些人的共同朋友
context.write(new Text(friend),new Text(user));
}
}
}
static class FriendsDemoStepOneReducer extends Reducer<Text,Text,Text,Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder sb = new StringBuilder();
for (Text person : values) {
sb.append(person+",");
}
context.write(key,new Text(sb.toString()));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name","local");
conf.set("fs.defaultFS","file:///");
Job job = Job.getInstance(conf);
job.setJarByClass(FriendsDemoStepOneDriver.class);
job.setMapperClass(FriendsDemoStepOneMapper.class);
job.setReducerClass(FriendsDemoStepOneReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path("/Users/kris/Downloads/mapreduce/friends/friends.txt"));
FileOutputFormat.setOutputPath(job,new Path("/Users/kris/Downloads/mapreduce/friends/output"));
boolean completion = job.waitForCompletion(true);
System.out.println(completion);
}
}
运行的到的结果如下:
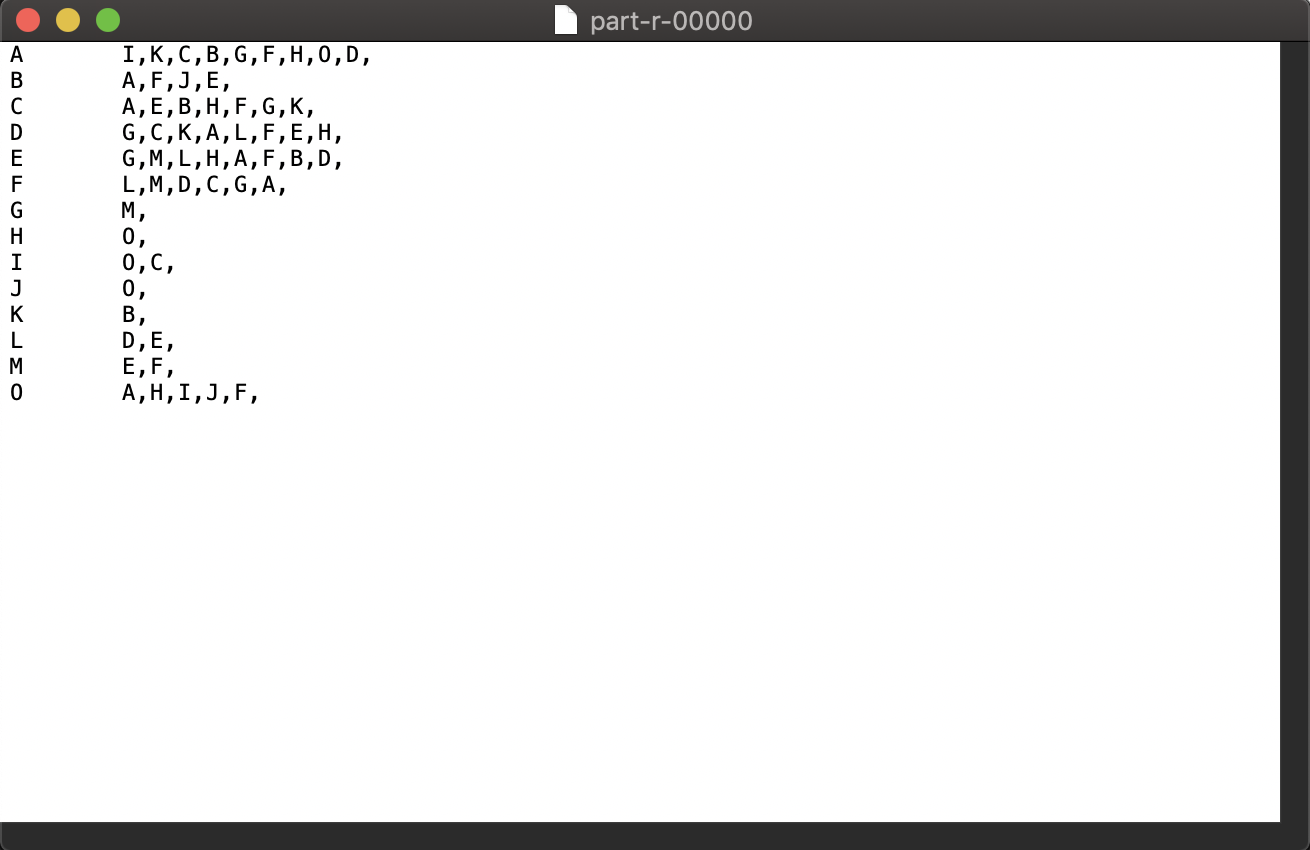
由图可见:I,K,C,B,G,F,H,O,D都有好友A;A,F,J,E都有好友B。接下来我们只需组合这些拥有相同的好友的用户,
作为key发送给reduce,由reduce端聚合d得到所有共同的好友
/**
* 遍历有同个好友的用户的列表进行组合,得到两人的共同好友
*/
public class FriendsDemoStepTwoDriver {
static class FriendDemoStepTwoMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split("\t");
String friend = split[0];
String[] persons = split[1].split(",");
Arrays.sort(persons);
for (int i = 0; i < persons.length-1; i++) {
for (int i1 = i+1; i1 < persons.length; i1++) {
context.write(new Text(persons[i]+"--"+persons[i1]),new Text(friend));
}
}
}
}
static class FriendDemoStepTwoReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder sb = new StringBuilder();
for (Text friend : values) {
sb.append(friend + ",");
}
context.write(key,new Text(sb.toString()));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name","local");
conf.set("fs.defaultFS","file:///");
Job job = Job.getInstance(conf);
job.setJarByClass(FriendsDemoStepOneDriver.class);
job.setMapperClass(FriendDemoStepTwoMapper.class);
job.setReducerClass(FriendDemoStepTwoReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path("/Users/kris/Downloads/mapreduce/friends/output"));
FileOutputFormat.setOutputPath(job,new Path("/Users/kris/Downloads/mapreduce/friends/output2"));
boolean completion = job.waitForCompletion(true);
System.out.println(completion);
}
}
得到的结果如下:

如图,我们就得到了拥有共同好友的用户列表及其对应关系,在实际场景中再根据用户关系(如是否已经是好友)进行过滤,在前端展示,就形成了我们所看到"可能认识"或者"好友推荐"啦~
今天给大家分享的好友推荐算法就是这些,今天的只是一个小小的案例,现实场景中的运算肯定要比这个复杂的多,
但是思路和方向基本一致,如果有更好的建议或算法,欢迎与小吴一起讨论喔~
如果您喜欢这篇文章的话记得like,share,comment喔(^^)MapReduce案例-好友推荐的更多相关文章
- 【大数据系列】MapReduce示例好友推荐
package org.slp; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import ...
- MapReduce -- 好友推荐
MapReduce实现好友推荐: 张三的好友有王五.小红.赵六; 同样王五.小红.赵六的共同好友是张三; 在王五和小红不认识的前提下,可以通过张三互相认识,给王五推荐的好友为小红, 给小红推荐的好友是 ...
- 19-hadoop-fof好友推荐
好友推荐的案例, 需要两个job, 第一个进行好友关系度计算, 第二个job将计算的关系进行推荐 1, fof关系类 package com.wenbronk.friend; import org.a ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:qq好友推荐算法
实验目的 初步认识图计算的知识点 复习mapreduce的知识点,复习自定义排序分组的方法 学会设计mapreduce程序解决实际问题 实验原理 QQ好友推荐算法是所有推荐算法中思路最简单的,我们利用 ...
- mapreduce案例:获取PI的值
mapreduce案例:获取PI的值 * content:核心思想是向以(0,0),(0,1),(1,0),(1,1)为顶点的正方形中投掷随机点. * 统计(0.5,0.5)为圆心的单位圆中落点占总落 ...
- 【Hadoop离线基础总结】MapReduce案例之自定义groupingComparator
MapReduce案例之自定义groupingComparator 求取Top 1的数据 需求 求出每一个订单中成交金额最大的一笔交易 订单id 商品id 成交金额 Order_0000005 Pdt ...
- 【Hadoop学习之十】MapReduce案例分析二-好友推荐
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 最应该推荐的好友TopN,如何排名 ...
- MapReduce案例二:好友推荐
1.需求 推荐好友的好友 图1: 2.解决思路 3.代码 3.1MyFoF类代码 说明: 该类定义了所加载的配置,以及执行的map,reduce程序所需要加载运行的类 package com.hado ...
- 【尚学堂·Hadoop学习】MapReduce案例2--好友推荐
案例描述 根据好友列表,推荐好友的好友 数据集 tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive ...
随机推荐
- Mysql分区实战
一,什么是数据库分区 前段时间写过一篇关于MySQL分表的的文章,下面来说一下什么是数据库分区,以mysql为例.mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面 ...
- poj 2352 & Ural 1028 数星星 题解
一道水题,由于x坐标递增y坐标也递增于是前缀和统计即可,用树状数组实现. #include<bits/stdc++.h> using namespace std; const int ma ...
- 使用Elastic APM监控你的.NET Core应用
作者:Jax 前言 在应用实际的运维过程中,我们需要更多的日志和监控来让我们对自己的应用程序的运行状况有一个全方位的了解.然而对于大部分开发者而言,平时大家所关注的更多的是如何更优雅的实现业务,或者是 ...
- 环境变量_JAVA_LAUNCHER_DEBUG,它能给你更多的JVM信息
关于环境: 本文中的实战都是在docker容器中进行的,容器的出处请参照<在docker上编译openjdk8>一文,里面详细的说明了如何构造镜像和启动容器. 在上一篇文章<修改,编 ...
- 深入SpringMVC视图解析器
ViewResolver的主要职责是根据Controller所返回的ModelAndView中的逻辑视图名,为DispatcherServlet返回一个可用的View实例.SpringMVC中用于把V ...
- jupyter notebook快速入门教程
什么是jupyter notebook? 官网:https://jupyter.org/ 上面是官方网址,就简单的介绍下,就不多做解释了,juoyter notebook,就是一个web应用,比较强大 ...
- Python远程连接MySQL数据库
使用Python连接数据库首先需要安装Python的数据库驱动. 我的本地只装了Python,并没有装MySQL,当我使用命令: sudo pip install mysql-python 安装驱动( ...
- Mysql 获取当月和上个月第一天和最后一天的SQL
Mysql 获取当月和上个月第一天和最后一天的SQL #获取当前日期select curdate(); #获取当月最后一天select last_day(curdate()); #获取本月的第一天se ...
- WEB应用中普通java代码如何读取资源文件
首先: 资源文件分两种:后缀.xml文件和.properties文件 .xml文件:当数据之间有联系时用.xml .properties文件:当数据之间没有联系时用.properties 正题: ...
- 洛谷 P1181数列分段Section I
星爆气流(弃疗)斩! ——<刀剑神域> 题目:https://www.luogu.org/proble ...