python爬取新浪股票数据—绘图【原创分享】
目标:不做蜡烛图,只用折线图绘图,绘出四条线之间的关系。
注:未使用接口,仅爬虫学习,不做任何违法操作。
"""
新浪财经,爬取历史股票数据
""" # -*- coding:utf-8 -*- import numpy as np
import urllib.request, lxml.html
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re, time
import matplotlib.pyplot as plt
from datetime import datetime
# 绘图显示中文设置
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 公共模块,请求头信息
def public(link):
r = urllib.request.Request(link) ug = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0' r.add_header('User-Agent', ug) cookie = "SUB=_2AkMsqZjif8NxqwJRmfkRxG7nZYpzyg_EieKa9Wk5JRMyHRl-yD83qkJatRB6Bym2DDqPE870e3uMsySIjHjrMbMNxNqk; " \
"SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WFXmxLGpAG5k05lCJw6qgYe; " \
"SINAGLOBAL=172.16.92.24_1542789082.401113; " \
"Apache=172.16.92.24_1542789082.401115; UOR=www.baidu.com,blog.sina.com.cn,; " \
"ULV=1542789814434:1:1:1:172.16.92.24_1542789082.401115:; U_TRS1=000000d1.1f4d3546.5bf53673.955fa32e; " \
"U_TRS2=000000d1.1f593546.5bf53673.736853cc; FINANCE2=661413ac85cadaab72ec7e3d842d6a3a; _s_upa=1" r.add_header("Cookie", cookie) html = urllib.request.urlopen(r, timeout=500).read() bsObj = BeautifulSoup(html, "lxml") # 将html对象转化为BeautifulSoup对象 return bsObj # 获取股票价格
def shares_price(code, year, quarter):
link = "http://money.finance.sina.com.cn/corp/go.php/vMS_MarketHistory/stockid/%s.phtml?year=%d&jidu=%d" % (code, year, quarter) bsObj = public(link)
# print(bsObj) a = 0
# date_list为日期列表,open_list为开盘价列表,high_list为最高价列表,close_list为收盘价列表,low_list为最低价列表
price_list, date_list, open_list, high_list, close_list, low_list = [], [], [], [], [], []
# 获取股票信息
jpg_title = re.findall("(.*?\))", bsObj.title.text) prices_bs = bsObj.find_all(name='div', attrs={"align": 'center'})
# 获取并处理价格信息
for price_bs in prices_bs:
# 去除空格
price_bs_1 = price_bs.text.replace("\n\r\n\t\t\t", "")
price_bs_2 = price_bs_1.replace("\t\t\t\n", "") # 6个字符串为一个列表
if a != 6:
price_list.append(price_bs_2)
a = a + 1
else:
date_list.append(price_list[0])
open_list.append(price_list[1])
high_list.append(price_list[2])
close_list.append(price_list[3])
low_list.append(price_list[4])
a = 0
price_list = []
# 删除列表头
for b in (date_list, open_list, high_list, close_list, low_list):
b.pop(0) # 全部倒序排列(由日期远到近,从左到右排列)
for c in (date_list, open_list, high_list, close_list, low_list):
c.reverse() return date_list, open_list, high_list, close_list, low_list, jpg_title # 输入股票代码,年份,季度
code = ""
year = ""
quarter = 4
# 以下为手动输入模式,因调试方便默认上面固定模式。
# code = input("code:") # 002925
# year = input("year:") # 2018
# quarter = int(input("quarter:")) # 列表字符串转为数值date
x = [datetime.strptime(d, '%Y-%m-%d').date() for d in shares_price(code, int(year), quarter)[0]]
# 将爬取的数据(字符串)转化为浮点型
open_list = [float(i) for i in shares_price(code, int(year), quarter)[1]]
high_list = [float(i) for i in shares_price(code, int(year), quarter)[2]]
close_list = [float(i) for i in shares_price(code, int(year), quarter)[3]]
low_list = [float(i) for i in shares_price(code, int(year), quarter)[4]] # 线条设置
plt.plot(x, open_list, label='open', linewidth=1, color='red', marker='o', markerfacecolor='blue', markersize=2)
plt.plot(x, high_list, label='high', linewidth=1, color='green', marker='o', markerfacecolor='blue', markersize=2)
plt.plot(x, close_list, label='close', linewidth=1, color='blue', marker='o', markerfacecolor='blue', markersize=2)
plt.plot(x, low_list, label='low', linewidth=1, color='black', marker='o', markerfacecolor='blue', markersize=2) # 取数列最大数值与最小值做图表的边界值。
plt.ylim(min(low_list)-1, max(high_list)+1)
plt.gcf().autofmt_xdate() # 自动旋转日期标记 # 打印表头
plt.xlabel('time')
plt.ylabel('price')
# shares_price(code, int(year), quarter)[5][0]为title中的股票名称与代码
plt.title('gp_1_{0}.jpg'.format(shares_price(code, int(year), quarter)[5][0]))
plt.legend()
plt.show()
效果如下:
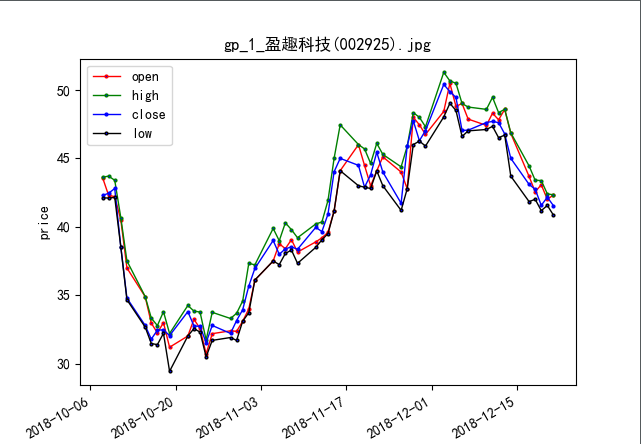
是不是有另一种看法的感觉?如:黑线下跌后向上的第一个大拐点为买入点。
python爬取新浪股票数据—绘图【原创分享】的更多相关文章
- Python抓取新浪新闻数据(二)
以下是抓取的完整代码(抓取了网页的title,newssource,dt,article,editor,comments)举例: 转载于:https://blog.51cto.com/2290153/ ...
- selenium+BeautifulSoup+phantomjs爬取新浪新闻
一 下载phantomjs,把phantomjs.exe的文件路径加到环境变量中,也可以phantomjs.exe拷贝到一个已存在的环境变量路径中,比如我用的anaconda,我把phantomjs. ...
- Python3:爬取新浪、网易、今日头条、UC四大网站新闻标题及内容
Python3:爬取新浪.网易.今日头条.UC四大网站新闻标题及内容 以爬取相应网站的社会新闻内容为例: 一.新浪: 新浪网的新闻比较好爬取,我是用BeautifulSoup直接解析的,它并没有使用J ...
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- 手把手教你使用Python爬取西刺代理数据(下篇)
/1 前言/ 前几天小编发布了手把手教你使用Python爬取西次代理数据(上篇),木有赶上车的小伙伴,可以戳进去看看.今天小编带大家进行网页结构的分析以及网页数据的提取,具体步骤如下. /2 首页分析 ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- 【转】Python爬虫:抓取新浪新闻数据
案例一 抓取对象: 新浪国内新闻(http://news.sina.com.cn/china/),该列表中的标题名称.时间.链接. 完整代码: from bs4 import BeautifulSou ...
- Python爬虫:抓取新浪新闻数据
案例一 抓取对象: 新浪国内新闻(http://news.sina.com.cn/china/),该列表中的标题名称.时间.链接. 完整代码: from bs4 import BeautifulSou ...
- Python 爬虫实例(7)—— 爬取 新浪军事新闻
我们打开新浪新闻,看到页面如下,首先去爬取一级 url,图片中蓝色圆圈部分 第二zh张图片,显示需要分页, 源代码: # coding:utf-8 import json import redis i ...
随机推荐
- NET C#创建WINDOWS系统用户
原文:NET C#创建WINDOWS系统用户 /前提是当前用户有相应的权限 /WinNT用户管理 using System; using System.DirectoryServices; na ...
- 解决手机提示TF卡受损需要格式化问题
昨晚因为上QQ FOR PAD后.关机.结果又杯具了.上次无意看到一个SD卡修复命令,收藏起来了.一试,还真管用.现把它写出来.分享给大家.以后出现SD卡受损,千万不要再格式化内存卡了.修复过程:1. ...
- Windows 10 UWP开发:如何去掉ListView默认的选中效果
原文:Windows 10 UWP开发:如何去掉ListView默认的选中效果 开发UWP的时候,很多人会碰到一个问题,就是ListView在被数据绑定之后经常有个默认选中的效果,就像这样: 而且它不 ...
- Android零基础入门第74节:Activity启动和关闭
上一期我们学习了Activity的创建和配置,当时留了一个悬念,如何才能在默认启动的Activity中打开其他新建的Activity呢?那么本期一起来学习如何启动和关闭Activity. 一.概述 经 ...
- C#实现任意源组播与特定源组播
IP组播通信需要一个特殊的组播地址,IP组播地址是一组D类IP地址,范围从224.0.0.0 到 239.255.255.255.其中还有很多地址是为特殊的目的保留的.224.0.0.0到224.0. ...
- C++中的new,operator new与placement new
以下是C++中的new,operator new与placement new进行了详细的说明介绍,需要的朋友可以过来参考下 new operator/delete operator就是new和 ...
- Spring Boot之Actuator的端点
Spring Boot Actuator的关键特性是在应用程序里提供众多Web端点,通过它们了解应用程序 运行时的内部状况.有了Actuator,你可以知道Bean在Spring应用程序上下文里是如何 ...
- java统计文本中单词出现的个数
package com.java_Test; import java.io.File; import java.util.HashMap; import java.util.Iterator; imp ...
- SpringBoot(十九)_spring.profiles.active=@profiles.active@ 的使用
现在在的公司用spring.profiles.active=@profiles.active@ 当我看到这个的时候,一脸蒙蔽,这个@ 是啥意思. 这里其实是配合 maven profile进行选择不同 ...
- 附006.Kubernetes RBAC授权
一 RBAC 1.1 RBAC授权 基于角色的访问控制(RBAC)是一种基于个人用户的角色来管理对计算机或网络资源的访问的方法. RBAC使用rbac.authorization.k8s.io API ...