初探爬虫 ——《python 3 网络爬虫开发实践》读书笔记
零、背景
之前在 node.js 下写过一些爬虫,去做自己的私人网站和工具,但一直没有稍微深入的了解,借着此次公司的新项目,体系的学习下。
本文内容主要侧重介绍爬虫的概念、玩法、策略、不同工具的列举和对比上,至于具体工具和框架的使用,会单独开辟独立的文章。
下面的工具排行,从上往下表示从简单到复杂,从功能少到功能丰富。
一、爬虫相关工具
爬虫可以简单分为几步:抓取页面、分析页面和存储数据。
1、抓取页面
(1)接口抓取
urlin
httplib2
requests [推荐]
aiohttp [推荐]
urlin 和 httplib2 比较基础,需要配合一些库才能实现高级功能。
requests 比较高级,可以有文件上传、会话维持(session)、Cookies、SSL 证书验证、登录验证、代理设置等。
aiohttp ,提供异步 Web 服务的库。
从 Python3.5 版本开始,Python 中加入了 async/await。
接口抓取的缺点是抓不到 js 渲染后的页面,而下面介绍的模拟抓取能很好的解决问题。
(2)模拟抓取
也就是可见即可爬。
Splash
Selenium [推荐]
Appium [推荐]
Splash 是一个 javascript 渲染服务。它是一个带有 HTTP API 的轻量级 Web 浏览器。
Selenium 是一个自动化测试工具,利用它我们可以驱动测览器执行特定的动作,如点击、下拉等操作。
Selenium + Chrome Driver,可以驱动 Chrome 浏览器完成相应的操作。
Selenium + Phantoms,这样在运行的时候就不会再弹出一个浏览器了。而且 Phantoms 的运行效率也很高。
Phantoms 是一个无界面的、可脚本编程的 Webkit 7 浏览器引擎。
Appium 是 App 版的 Selenium。
2、分析页面
抓取网页代码之后,下一步就是从网页中提取信息。
正则
lxml
Beautiful Soup
pyquery
正则是最原始的方式,写起来繁琐,可读性差。
lxml 是 Python 的一个解析库,支持 HTML 和 XML 的解析,支持 XPah 解析方式。
Beautiful Soup 的 HTML 和 XML 解析器是依赖于 lxml 库的,所以在此之前请确保已经成功安装好了 lxml。
Beautiful Soup提供好几个解析器:

pyquery 同样是一个强大的网页解析工具,它提供了和 jquery 类似的语法来解析 HTML 文档。
推荐:
Beautiful Soup(lxml)。lxml 解析器有解析 HTML 和 XML 的功能,而且速度快,容错能力强。
如果本身就熟悉 css 和 jquery 的话,就推荐 pyquery。
3、存储数据
关系型
MYSQL - python 环境需安装 PyMySQL非关系型
Mongodb - python 环境需安装 Pymongo
Redis
拓展:
NOSQL,全称 Not Only SQL,意为不仅仅是 SQL,泛指非关系型数据库。包括:
口 键值存储数据库:代表有 Redis、Voldemort 和 Oracle BDB 等
口 列存储数据库:代表有 Cassandra、Hbase 和 Riak 等。
口 文档型数据库:代表有 COUCHDB 和 Mongodb 等。
口 图形数据库:代表有 Neo4J、infogrid 和 Infinite Graph 等。
4、抓包
针对一些复杂应用,尤其是 app,请求不像在 chrome 的 console 里那么容易看到,这就需要抓包工具。
Wireshark
Fiddler
Charles [推荐]
mitmproxy(mitmdump) [推荐]
mitmproxy(mitmdump) 比 Charles 更强大的是,可以支持对接 Python 脚本去处理 resquest / response。
5、爬 APP 的最佳实践
方案:Appium + mitmdump
做法:用 mitmdump 去监听接口数据,用 Appium 去模拟 App 的操作。
好处:即可绕过复杂的接口参数又能实现自动化提高效率。
缺点:有一些 app,如微信朋友圈的数据又经过了一次加密导致无法解析,这种情况只能纯用 Appium 了。但是对于大多数 App 来说,此种方法是奏效的。
二、爬虫框架
1、pyspider
pyspide 框架有一些缺点,比如可配置化程度不高,异常处理能力有限等,它对于一些反爬程度非常强的网站的爬取显得力不从心。
所以这里不多做介绍。
2、Scrapy
Scrapy 是一个基于 Twisted 的异步处理框架,是纯 Python 实现的爬虫框架。
Scrapy 包括:
Scrapy-Splash:一个 Scrapy 中支持 Javascript 渲染的工具。
Scrapy-Redis :Scrap 的分布式扩展模块。
Scrapyd :一个用于部署和运行 Scrapy 项目的工具。
Scrapyrt :为 Scrap 提供了一个调度的 HTTP 接口。
Gerapy :一个 Scrapy 分布式管理模块。
Scrapy 可对接:
Crawlspider : Scrap 提供的一个通用 Spider,我们可以指定一些爬取规则来实现页面的提取,
Splash / Selenium :自动化爬取
Docker
具体使用:待写
三、爬虫拓展的基础知识
1、URI、URL、URN 区别
URI 的全称为 Uniform Resource Identifier,即统一资源标志符。
URL 的全称为 Universal Resource Locator,即统一资源定位符。
URN 的全称为 Universal Resource Name,即统一资源名称。

URI 可以进一步划分为URL、URN或两者兼备。URL 和 URN 都是 URI 子集。
URN 如同一个人的名称,而 URL 代表一个人的住址。换言之,URN 定义某事物的身份,而 URL 提供查找该事物的方法。
现在常用的http网址,如 http://www.waylau.com 就是URL。
而用于标识唯一书目的 ISBN 系统, 如:isbn:0-486-27557-4 ,就是 URN 。
但是在目前的互联网中,URN 用得非常少,所以几乎所有的 URI 都是 URL。
2、Robots 协议
(1)什么是 Robots 协议
Robots 协议也称作爬虫协议、机器人协议,它的全名叫作网络爬虫排除标准(Robots Exclusion Protocol),用来告诉爬虫和搜索引擎哪些页面可以抓取,哪些不可以抓取。它通常是一个叫作robots.txt 的文本文件,一般放在网站的根目录下。
当搜索爬虫访问一个站点时,它首先会检查这个站点根目录下是否存在 robots.txt 文件,如果存在搜索爬虫会根据其中定义的爬取范围来爬取。如果没有找到这个文件,搜索爬虫便会访问所有可直接访问的页面。
(2)使用方法
robotx.txt 需要放在网站根目录。
User-agent: *
Disallow: /
Allow: /public/
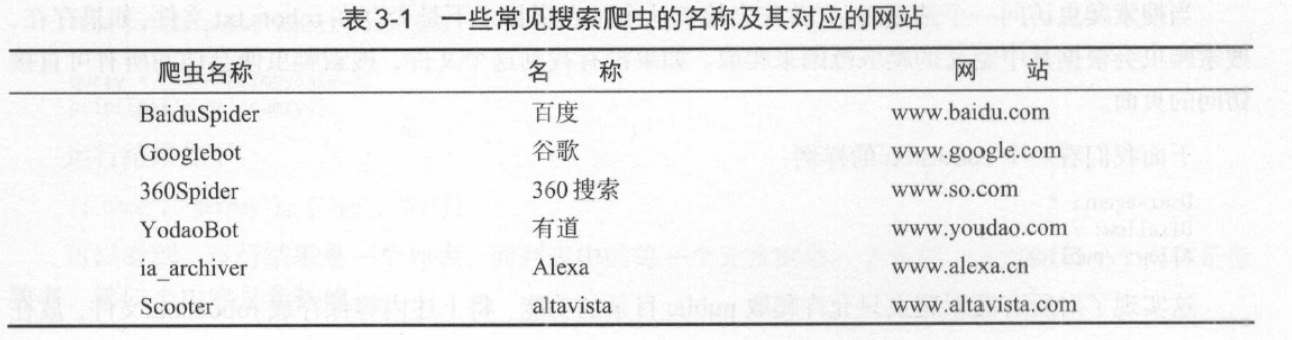
Disallow表示不允许爬的页面,Allow表示允许爬的页面,User-agent表示针对哪个常用搜索引擎。
User-agent 为约定好的值,取值如下表:
(3)什么场景下,网站不希望被搜索引擎爬到并收录
1、测试环境
2、管理后台(如 cms)
3、其它
(4)工具
1、Google的 Robots.txt 规范。
2、站长工具的 robots文件生成 工具。
3、Xpath
Xpath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中査找信息的语言。它最初是用来搜寻 XML 文档的,但是它同样适用于 HTML 文档的搜索。
Xpath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式。另外,它还提供了超过 100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等。
Xpath 于 1999 年 11 月 16 日成为 W3C 标准。
就好像 css 选择器。
四、验证码的识别
1、图形验证码
可以使用 Tesseract ,它是 Python 的一个 OCR 识别库。
2、滑动验证码
市面上用的最多的是这家提供的滑动验证码:http://www.geetest.com/ ,如 bilibili。
可以用自动化库,如 Selenium 模拟滑动(注意人去滑动按钮是先快后慢)。
3、微博宫格验证码
解决思路:模板匹配+模拟拖动
4、点触验证码
还有一个专门提供点触验证码服务的站点 Touclick,例如 12306 网站。
5、总结
上面说的第四个:点触验证码,应该是最难识别的了。
但互联网上有很多验证码服务平台,平台 7×24 小时提供验证码识别服务,一张图片几秒就会获得识别结果,准确率可达 90%以上。
个人比较推荐的一个平台是超级鹰,其官网为 https://www.chaoying.com 。其提供的服务种类非常广泛,可识别的验证码类型非常多,其中就包括点触验证码。
五、代理的使用 - 代理池
1、代理分类
(1)根据协议区分
ロ FTP 代理服务器:主要用于访问 FTP 服务器,一般有上传、下载以及缓存功能,端口一般为 21、2121 等。
ロ HTP 代理服务器:主要用于访问网页,一般有内容过滤和缓存功能,端口一般为 80、8080、3128等。
口 SSL/TLS代理:主要用于访问加密网站,一般有SSL或TLS加密功能(最高支持 128 位加密强度),端口一般为 443。
口 RTSP 代理:主要用于访问 Real 流媒体服务器,一般有缓存功能,端口一般为 554。
口 Telnet 代理:主要用于 telnet 远程控制(黑客入侵计算机时常用于隐藏身份),端口一般为 23。
口 POP3 SMTP 代理:主要用于 POP3 SMTP 方式收发邮件,一般有缓存功能,端口一般为 11025 。
口 SOCKS 代理:只是单纯传递数据包,不关心具体协议和用法,所以速度快很多,一般有缓存功能,端口一般为 1080。SOCKS 代理协议又分为 SOCKS4 和 SOCKS5,前者只支持 TCP,而后者支持 TCP 和 UDP,还支持各种身份验证机制、服务器端域名解析等。简单来说,SOCKS4 能做到的 SOCKS5 都可以做到,但 SOCKS5 能做到的 SOCKS4 不一定能做到。
(2)根据匿名程度区分
口 高度匿名代理:会将数据包原封不动地转发,在服务端看来就好像真的是一个普通客户端在访问,而记录的 IP 是代理服务器的 IP。
ロ 普通匿名代理:会在数据包上做一些改动,服务端上有可能发现这是个代理服务器,也有一定几率追查到客户端的真实 IP。代理服务器通常会加入的 HTIP 头有 HTTPVIA 和 HTTPXFORWARDEDFOR。
口 透明代理:不但改动了数据包,还会告诉服务器客户端的真实 IP。这种代理除了能用缓存技术提高浏览速度,能用内容过滤提高安全性之外,并无其他显著作用,最常见的例子是内网中的硬件防火墙。
口 间谍代理:指组织或个人创建的用于记录用户传输的数据,然后进行研究、监控等目的的代理服务器。
2、购买代理
(1) 免费代理
网站上会有很多免费代理,比如西刺:http://www.xicidaili.com 。但是这些免费代理大多数情况下都是不好用的,所以比较靠谱的方法是购买付费代理。
(2) 收费代理
1、提供接口获取海量代理,按天或者按量收费,如讯代理;
如果信赖讯代理的话,我们也可以不做代理池筛选,直接使用代理。不过我个人还是推荐使用代理池筛选,以提高代理可用概率。自己再做一次筛选,以确保代理可用。
2、搭建了代理隧道,直接设置固定域名代理,如阿布云代理。云代理在云端维护一个全局 IP 池供代理隧道使用,池中的 IP 会不间断更新。代理隧道,配置简单,代理速度快且非常稳定。
等于帮你做了一个云端的代理池,不用自己实现了。
需要注意的是,代理 IP 池中部分 IP 可能会在当天重复出现多次。
3、ADSL 拨号代理
ADSL (Asymmetric Digital Subscriber Line,非对称数字用户环路),它的上行和下行带宽不对称,它采用频分复用技术把普通的电话线分成了电话、上行和下行 3 个相对独立的信道,从而避免了相互之间的干扰。
我们利用了 ADSL 通过拨号的方式上网,需要输入 ADSL 账号和密码,每次拨号就更换一个 IP 这个特性。
所以我们可以先购买一台动态拨号 VPS 主机,这样的主机服务商相当多。在这里使用了云立方,官方网站: http://www.yunlifang.cn/dynamicvps.asp
3、代理池的实现
代理不论是免费的还是付费的,都不能保证都是可用的,因为:
1、此 IP 可能被其他人使用来爬取同样的目标站点而被封禁。
2、代理服务器突然发生故障。
3、网络繁忙。
4、购买的代理到期。
5、等等
所以,我们需要提前做筛选,将不可用的代理剔除掉,保留可用代理。这就需要代理池,来获取随机可用的代理。

代理池分为 4 个模块: 存储模块、获取模块、检测模块、接口模块。
口 存储模块使用 Redis 的有序集合,用来做代理的去重和状态标识,同时它也是中心模块和基础模块,将其他模块串联起来。
口 获取模块定时从代理网站获取代理,将获取的代理传递给存储模块,并保存到数据库。
口 检测模块定时通过存储模块获取所有代理,并对代理进行检测,根据不同的检测结果对代理设置不同的标识。
口 接口模块通过WebAPI 提供服务接口,接口通过连接数据库并通过Web 形式返回可用的代理。
对于这里的检测模块,建议使用 aiohttp 而不是 requests,原因是:
对于响应速度比较快的网站来说,requests 同步请求和 aiohttp 异步请求的效果差距没那么大。但对于检测代理来说,检测一个代理一般需要十多秒甚至几十秒的时间,这时候使用 aiohttp 异步请求库的优势就大大体现出来了,效率可能会提高几十倍不止。
六、模拟登录 - cookies 池
1、为什么需要模拟登录
(1)有的数据必须要登录才能抓取。
(2)有时候,登录账号也可以降低被封禁的概率。
2、Cookies 池的实现
做大规模抓取,我们就需要拥有很多账号,每次请求随机选取一个账号,这样就降低了单个账号的访问颍率,被封的概率又会大大降低。
所以,我们可以维护一个登录用的 Cookies 池。
架构跟代理池一样。可参考上文。
七、分布式爬虫 & 分布式爬虫的部署
待写
拓展
1、打开文件的模式
python 的 open() 支持的模式可以是只读/写入/追加,也是可以它们的组合型,具体如下:
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
1、r+ 和 w+ 都是读写,有什么区别?
答:前者是如果没有找到文件则抛错,后者是如果没有找到文件则自动创建文件。
2、a 可以看成是 w 的变种,附加上了”追加内容“的特性。
一般调用 open() 的时候还需要再调用 close()。 python 提供了一种简写方法,那就是使用 with as 语法。在 with 控制块结束时,文件会自动关闭,不需要 close() 了。调用写法如下:
with open('explore.txt', 'a', encoding ='utf-8') as file:
file.write('123' + '\n')
初探爬虫 ——《python 3 网络爬虫开发实践》读书笔记的更多相关文章
- JavaScript设计模式与开发实践——读书笔记1.高阶函数(上)
说来惭愧,4个多月未更新了.4月份以后就开始忙起来了,论文.毕设.毕业旅行等七七八八的事情占据了很多时间,毕业之后开始忙碌的工作,这期间一直想写博客,但是一直没能静下心写.这段时间在看<Java ...
- JavaScript设计模式与开发实践——读书笔记1.高阶函数(下)
上部分主要介绍高阶函数的常见形式,本部分将着重介绍高阶函数的高级应用. 1.currying currying指的是函数柯里化,又称部分求值.一个currying的函数会先接受一些参数,但不立即求值, ...
- Javascript设计模式与开发实践读书笔记(1-3章)
第一章 面向对象的Javascript 1.1 多态在面向对象设计中的应用 多态最根本好处在于,你不必询问对象“你是什么类型”而后根据得到的答案调用对象的某个行为--你只管调用行为就好,剩下的一切 ...
- Python 3网络爬虫开发实战》中文PDF+源代码+书籍软件包
Python 3网络爬虫开发实战>中文PDF+源代码+书籍软件包 下载:正在上传请稍后... 本书书籍软件包为本人原创,在这个时间就是金钱的时代,有些软件下起来是很麻烦的,真的可以为你们节省很多 ...
- Python 3网络爬虫开发实战中文 书籍软件包(原创)
Python 3网络爬虫开发实战中文 书籍软件包(原创) 本书书籍软件包为本人原创,想学爬虫的朋友你们的福利来了.软件包包含了该书籍所需的所有软件. 因为软件导致这个文件比较大,所以百度网盘没有加速的 ...
- Python 3网络爬虫开发实战中文PDF+源代码+书籍软件包(免费赠送)+崔庆才
Python 3网络爬虫开发实战中文PDF+源代码+书籍软件包+崔庆才 下载: 链接:https://pan.baidu.com/s/1H-VrvrT7wE9-CW2Dy2p0qA 提取码:35go ...
- 《Python 3网络爬虫开发实战中文》超清PDF+源代码+书籍软件包
<Python 3网络爬虫开发实战中文>PDF+源代码+书籍软件包 下载: 链接:https://pan.baidu.com/s/18yqCr7i9x_vTazuMPzL23Q 提取码:i ...
- Python 3网络爬虫开发实战书籍
Python 3网络爬虫开发实战书籍,教你学会如何用Python 3开发爬虫 本书介绍了如何利用Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib.reques ...
- Python即时网络爬虫项目启动说明
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心. 我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级了,推翻了老版本 ...
- Python即时网络爬虫项目: 内容提取器的定义(Python2.7版本)
1. 项目背景 在Python即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间太多了(见上图),从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端 ...
随机推荐
- ios中日期处理
- python-14-文件操作
前言 python中对文件的读写也是非常方便的,本章节将讲解读.写.读写等常用操作.下面讲师必要的参数: 1.文件路径:必须得知道文件的路径,不然怎样进行读写? 2.编码方式:utf-8,gbk,gb ...
- IDEA如何重置窗口布局
如何重置窗口布局 我不知道怎么搞的,左边的,上边的,下边的,视图都没有了 , 重启了一下,然后重置为默认视图,就好了
- Thinkphp5——实现分页(模型和Db分页,多种方法)
现在很多网站的数据量的很多,如果全部在一页里显示效果不好,数据量太大,那怎么办?这时我们就需要分页,而分页的好处就是分段显示数据,这样页面就不用加载很多数据,需要时才加载,下面我教大家实现ThinkP ...
- Javascript实现百度API
百度地图JavaScript API是一套由JavaScript语言编写的应用程序接口,可帮助您在网站中构建功能丰富.交互性强的地图应用,支持PC端和移动端基于浏览器的地图应用开发,且支持HTML5特 ...
- 漫谈LiteOS之开发板-GPIO(基于GD32450i-EVAL)
[摘要] 本文主要从GPIO的定义.工作模式.特色.工作场合.以及GD32450i-EVAL开发板的引脚.对应的寄存器以及GPIO的流水灯示例对GPIO加以介绍,希望对你有所帮助. 1定义 GPIO( ...
- su和sudo的区别与使用
一. 使用 su 命令临时切换用户身份 1.su 的适用条件和威力 su命令就是切换用户的工具,怎么理解呢?比如我们以普通用户beinan登录的,但要添加用户任务,执行useradd ,beina ...
- imageView的使用
转自:http://www.runoob.com/ios/att-ios-ui-imageview.html 图像视图用于显示单个图像或动画序列的图像. 重要的属性 image highlighted ...
- Python字符串学习
Python字符串(不可变的): 一.相关的运算: 1.字符串的拼接: str = str1 + str2 2.字符串的重复: print(str * 3) 3.下标访问字符串某个字符: str[1] ...
- 2018HDU多校训练一 D Distinct Values
hiaki has an array of nn positive integers. You are told some facts about the array: for every two e ...