面试官: 聊一聊Babel
点击关注本公众号获取文档最新更新,并可以领取配套于本指南的 《前端面试手册》 以及最标准的简历模板.
前言
Babel 是现代 JavaScript 语法转换器,几乎在任何现代前端项目中都能看到他的身影,其背后的原理对于大部分开发者还属于黑盒,不过 Babel 作为一个工具真的有了解背后原理的必要吗?
如果只是 Babel 可能真没有必要,问题是其背后的原理在我们开发中应用过于广泛了,包括不限于: eslint jshint stylelint css-in-js prettier jsx vue-template uglify-js postcss less 等等等等,从模板到代码检测,从混淆压缩到代码转换,甚至编辑器的代码高亮都与之息息相关.
如果有兴趣就可以搞一些黑魔法: 前端工程师可以用编译原理做什么?
前置
Babel 大概分为三大部分:
- 解析: 将代码(其实就是字符串)转换成 AST( 抽象语法树)
- 转换: 访问 AST 的节点进行变换操作生成新的 AST
- 生成: 以新的 AST 为基础生成代码
我们主要通过打造一个微型 babel 来了解 babel 的基本原理,这个微型 babel 的功能很单一也很鸡肋,但是依然有400行代码,其实现细节与 babel 并不相同,因为我们省去了很多额外的验证和信息解析,因为单单一个兼容现代 JavaScript 语法的 parser 就需要5000行代码,并不利于我们快速了解 babel 的基本实现,所以这个微型 babel可以说比较鸡肋(因为除了展示之外没啥用处),但是比较完整展示了 babel 的基本原理,你可以以此作为入门,在入门之后如果仍有兴趣,可以阅读:
代码解析
parser 概念
代码解析,也就是我们常说的 Parser, 用于将一段代码(文本)解析成一个数据结构.
例如这段 es6的代码
const add = (a, b) => a + b
我们用 babel 解析后便是这种形式:
{
"type": "File",
"start": 0,
"end": 27,
"loc": {
"start": {
"line": 1,
"column": 0
},
"end": {
"line": 1,
"column": 27
}
},
"program": {
"type": "Program",
"start": 0,
"end": 27,
"loc": {
"start": {
"line": 1,
"column": 0
},
"end": {
"line": 1,
"column": 27
}
},
"sourceType": "module",
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 27,
"loc": {
"start": {
"line": 1,
"column": 0
},
"end": {
"line": 1,
"column": 27
}
},
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 27,
"loc": {
"start": {
"line": 1,
"column": 6
},
"end": {
"line": 1,
"column": 27
}
},
"id": {
"type": "Identifier",
"start": 6,
"end": 9,
"loc": {
"start": {
"line": 1,
"column": 6
},
"end": {
"line": 1,
"column": 9
},
"identifierName": "add"
},
"name": "add"
},
"init": {
"type": "ArrowFunctionExpression",
"start": 12,
"end": 27,
"loc": {
"start": {
"line": 1,
"column": 12
},
"end": {
"line": 1,
"column": 27
}
},
"id": null,
"generator": false,
"expression": true,
"async": false,
"params": [
{
"type": "Identifier",
"start": 13,
"end": 14,
"loc": {
"start": {
"line": 1,
"column": 13
},
"end": {
"line": 1,
"column": 14
},
"identifierName": "a"
},
"name": "a"
},
{
"type": "Identifier",
"start": 16,
"end": 17,
"loc": {
"start": {
"line": 1,
"column": 16
},
"end": {
"line": 1,
"column": 17
},
"identifierName": "b"
},
"name": "b"
}
],
"body": {
"type": "BinaryExpression",
"start": 22,
"end": 27,
"loc": {
"start": {
"line": 1,
"column": 22
},
"end": {
"line": 1,
"column": 27
}
},
"left": {
"type": "Identifier",
"start": 22,
"end": 23,
"loc": {
"start": {
"line": 1,
"column": 22
},
"end": {
"line": 1,
"column": 23
},
"identifierName": "a"
},
"name": "a"
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 26,
"end": 27,
"loc": {
"start": {
"line": 1,
"column": 26
},
"end": {
"line": 1,
"column": 27
},
"identifierName": "b"
},
"name": "b"
}
}
}
}
],
"kind": "const"
}
],
"directives": []
}
}
我们以解析上面的 es6箭头函数为目标,来写一个简单的 parser.
文本 ---> AST 的过程中有两个关键步骤:
- 词法分析: 将代码(字符串)分割为token流,即语法单元成的数组
- 语法分析: 分析token流(上面生成的数组)并生成 AST
词法分析(Tokenizer -- 词法分析器)
要做词法分析,首先我们需要明白在 JavaScript 中哪些属于语法单元
- 数字:JavaScript 中的科学记数法以及普通数组都属于语法单元.
- 括号:『(』『)』只要出现,不管任何意义都算是语法单元
- 标识符:连续字符,常见的有变量,常量(例如: null true),关键字(if break)等等
- 运算符:+、-、*、/等等
- 当然还有注释,中括号等
在我们 parser 的过程中,应该换一个角度看待代码,我们平时工作用的代码.本质是就是字符串或者一段文本,它没有任何意义,是 JavaScript 引擎赋予了它意义,所以我们在解析过程中代码只是一段字符串.
仍然以下面代码为例
const add = (a, b) => a + b
我们期望的结果是类似这样的
[
{ type: "identifier", value: "const" },
{ type: "whitespace", value: " " },
...
]
那么我们现在开始打造一个Tokenizer(词法分析器)
// 词法分析器,接收字符串返回token数组
export const tokenizer = (code) => {
// 储存 token 的数组
const tokens = [];
// 指针
let current = 0;
while (current < code.length) {
// 获取指针指向的字符
const char = code[current];
// 我们先处理单字符的语法单元 类似于`;` `(` `)`等等这种
if (char === '(' || char === ')') {
tokens.push({
type: 'parens',
value: char,
});
current ++;
continue;
}
// 我们接着处理标识符,标识符一般为以字母、_、$开头的连续字符
if (/[a-zA-Z\$\_]/.test(char)) {
let value = '';
value += char;
current ++;
// 如果是连续字那么将其拼接在一起,随后指针后移
while (/[a-zA-Z0-9\$\_]/.test(code[current]) && current < code.length) {
value += code[current];
current ++;
}
tokens.push({
type: 'identifier',
value,
});
continue;
}
// 处理空白字符
if (/\s/.test(char)) {
let value = '';
value += char;
current ++;
//道理同上
while (/\s]/.test(code[current]) && current < code.length) {
value += code[current];
current ++;
}
tokens.push({
type: 'whitespace',
value,
});
continue;
}
// 处理逗号分隔符
if (/,/.test(char)) {
tokens.push({
type: ',',
value: ',',
});
current ++;
continue;
}
// 处理运算符
if (/=|\+|>/.test(char)) {
let value = '';
value += char;
current ++;
while (/=|\+|>/.test(code[current])) {
value += code[current];
current ++;
}
// 当 = 后面有 > 时为箭头函数而非运算符
if (value === '=>') {
tokens.push({
type: 'ArrowFunctionExpression',
value,
});
continue;
}
tokens.push({
type: 'operator',
value,
});
continue;
}
// 如果碰到我们词法分析器以外的字符,则报错
throw new TypeError('I dont know what this character is: ' + char);
}
return tokens;
};
那么我们基本的词法分析器就打造完成,因为只针对这一个es6函数,所以没有做额外的工作(额外的工作量会非常庞大).
const result = tokenizer('const add = (a, b) => a + b')
console.log(result);
/**
[ { type: 'identifier', value: 'const' },
{ type: 'whitespace', value: ' ' },
{ type: 'identifier', value: 'add' },
{ type: 'whitespace', value: ' ' },
{ type: 'operator', value: '=' },
{ type: 'whitespace', value: ' ' },
{ type: 'parens', value: '(' },
{ type: 'identifier', value: 'a' },
{ type: ',', value: ',' },
{ type: 'whitespace', value: ' ' },
{ type: 'identifier', value: 'b' },
{ type: 'parens', value: ')' },
{ type: 'whitespace', value: ' ' },
{ type: 'ArrowFunctionExpression', value: '=>' },
{ type: 'whitespace', value: ' ' },
{ type: 'identifier', value: 'a' },
{ type: 'whitespace', value: ' ' },
{ type: 'operator', value: '+' },
{ type: 'whitespace', value: ' ' },
{ type: 'identifier', value: 'b' } ]
**/
1.3 语法分析
语法分析要比词法分析复杂得多,因为我们接下来的是示意代码,所以做了很多“武断”的判断来省略代码,即使这样也是整个微型 babel 中代码量最多的.
语法分析之所以复杂,是因为要分析各种语法的可能性,需要开发者根据token流(上一节我们生成的 token 数组)提供的信息来分析出代码之间的逻辑关系,只有经过词法分析 token 流才能成为有结构的抽象语法树.
做语法分析最好依照标准,大多数 JavaScript Parser 都遵循estree规范
由于标准内容很多,感兴趣的可以去阅读,我们目前只介绍几个比较重要的标准:
语句(Statements): 语句是 JavaScript 中非常常见的语法,我们常见的循环、if 判断、异常处理语句、with 语句等等都属于语句
// 典型的for 循环语句
for (var i = 0; i < 7; i++) {
console.log(i);
}
表达式(Expressions): 表达式是一组代码的集合,它返回一个值,表达式是另一个十分常见的语法,函数表达式就是一种典型的表达式,如果你不理解什么是表达式, MDN上有很详细的解释.
// 函数表达式
var add = function(a, b) {
return a + b
}
声明(Declarations): 声明分为变量声明和函数声明,表达式(Expressions)中的函数表达式的例子用声明的写法就是下面这样.
// 函数声明
function add(a, b) {
return a + b
}
你可能有点糊涂,为了理清其中的关系,我们就下面的代码为例来解读
// 函数表达式
var add = function(a, b) {
return a + b
}
首先这段代码的整体本质是是一个变量声明(VariableDeclarator):
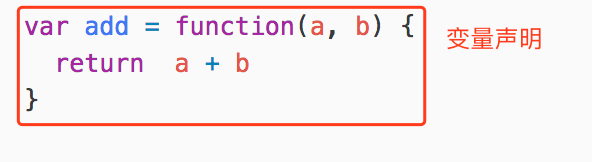
而变量被声明为一个函数表达式(FunctionExpression):

函数表达式中的大括号在内的为块状语句(BlockStatement):
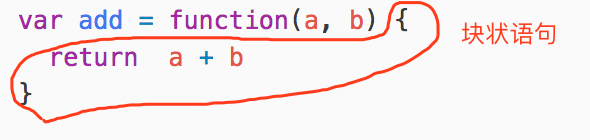
块状语句内 return 的部分是返回语句(ReturnStatement):

而 return 的其实是一个二元运算符或者叫二元表达式(BinaryExpression):

上面提到的这些有些属于表达式,有些属于声明也有些属于语句,当然还有更多我们没提到的,它们被语法分析之后被叫做AST(抽象语法树).
我们做语法分析的时候思路也是类似的,要分析哪一层的 token 到底属于表达式或者说语句,如果是语句那么是块状语句(BlockStatement)还是Loops,如果是 Loops 那么属于while 循环(WhileStatement)还是for 循环(ForStatement)等等,其中甚至难免要考虑作用域的问题,因此语法分析的复杂也体现在此.
const parser = tokens => {
// 声明一个全时指针,它会一直存在
let current = -1;
// 声明一个暂存栈,用于存放临时指针
const tem = [];
// 指针指向的当前token
let token = tokens[current];
const parseDeclarations = () => {
// 暂存当前指针
setTem();
// 指针后移
next();
// 如果字符为'const'可见是一个声明
if (token.type === 'identifier' && token.value === 'const') {
const declarations = {
type: 'VariableDeclaration',
kind: token.value
};
next();
// const 后面要跟变量的,如果不是则报错
if (token.type !== 'identifier') {
throw new Error('Expected Variable after const');
}
// 我们获取到了变量名称
declarations.identifierName = token.value;
next();
// 如果跟着 '=' 那么后面应该是个表达式或者常量之类的,额外判断的代码就忽略了,直接解析函数表达式
if (token.type === 'operator' && token.value === '=') {
declarations.init = parseFunctionExpression();
}
return declarations;
}
};
const parseFunctionExpression = () => {
next();
let init;
// 如果 '=' 后面跟着括号或者字符那基本判断是一个表达式
if (
(token.type === 'parens' && token.value === '(') ||
token.type === 'identifier'
) {
setTem();
next();
while (token.type === 'identifier' || token.type === ',') {
next();
}
// 如果括号后跟着箭头,那么判断是箭头函数表达式
if (token.type === 'parens' && token.value === ')') {
next();
if (token.type === 'ArrowFunctionExpression') {
init = {
type: 'ArrowFunctionExpression',
params: [],
body: {}
};
backTem();
// 解析箭头函数的参数
init.params = parseParams();
// 解析箭头函数的函数主体
init.body = parseExpression();
} else {
backTem();
}
}
}
return init;
};
const parseParams = () => {
const params = [];
if (token.type === 'parens' && token.value === '(') {
next();
while (token.type !== 'parens' && token.value !== ')') {
if (token.type === 'identifier') {
params.push({
type: token.type,
identifierName: token.value
});
}
next();
}
}
return params;
};
const parseExpression = () => {
next();
let body;
while (token.type === 'ArrowFunctionExpression') {
next();
}
// 如果以(开头或者变量开头说明不是 BlockStatement,我们以二元表达式来解析
if (token.type === 'identifier') {
body = {
type: 'BinaryExpression',
left: {
type: 'identifier',
identifierName: token.value
},
operator: '',
right: {
type: '',
identifierName: ''
}
};
next();
if (token.type === 'operator') {
body.operator = token.value;
}
next();
if (token.type === 'identifier') {
body.right = {
type: 'identifier',
identifierName: token.value
};
}
}
return body;
};
// 指针后移的函数
const next = () => {
do {
++current;
token = tokens[current]
? tokens[current]
: { type: 'eof', value: '' };
} while (token.type === 'whitespace');
};
// 指针暂存的函数
const setTem = () => {
tem.push(current);
};
// 指针回退的函数
const backTem = () => {
current = tem.pop();
token = tokens[current];
};
const ast = {
type: 'Program',
body: []
};
while (current < tokens.length) {
const statement = parseDeclarations();
if (!statement) {
break;
}
ast.body.push(statement);
}
return ast;
};
至此我们暴力 parser 了token 流,最终得到了简陋的抽象语法树:
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"identifierName": "add",
"init": {
"type": "ArrowFunctionExpression",
"params": [
{
"type": "identifier",
"identifierName": "a"
},
{
"type": "identifier",
"identifierName": "b"
}
],
"body": {
"type": "BinaryExpression",
"left": {
"type": "identifier",
"identifierName": "a"
},
"operator": "+",
"right": {
"type": "identifier",
"identifierName": "b"
}
}
}
}
]
}
代码转换
如何转换代码?
在 Babel 中我们使用者最常使用的地方就是代码转换,大家常用的 Babel 插件就是定义代码转换规则而生的,而代码解析和生成这一头一尾都主要是 Babel 负责。
比如我们要用 babel 做一个React 转小程序的转换器,babel工作流程的粗略情况是这样的:
- babel 将 React 代码解析为抽象语法树
- 开发者利用 babel 插件定义转换规则,根据原本的抽象语法树生成一个符合小程序规则的新抽象语法树
- babel 则根据新的抽象语法树生成代码,此时的代码就是符合小程序规则的新代码
例如 Taro就是用 babel 完成的小程序语法转换.
到这里大家就明白了,我们转换代码的关键就是根据当前的抽象语法树,以我们定义的规则生成新的抽象语法树,转换的过程就是生成新抽象语法树的过程.
遍历抽象语法树(实现遍历器traverser)
抽象语法树是一个树状数据结构,我们要生成新语法树,那么一定需要访问 AST 上的节点,因此我们需要一个工具来遍历抽象语法树的节点.
const traverser = (ast, visitor) => {
// 如果节点是数组那么遍历数组
const traverseArray = (array, parent) => {
array.forEach((child) => {
traverseNode(child, parent);
});
};
// 遍历 ast 节点
const traverseNode = (node, parent) => {
const method = visitor[node.type];
if (method) {
method(node, parent);
}
switch (node.type) {
case 'Program':
traverseArray(node.body, node);
break;
case 'VariableDeclaration':
traverseArray(node.init.params, node.init);
break;
case 'identifier':
break;
default:
throw new TypeError(node.type);
}
};
traverseNode(ast, null);
};
转换代码(实现转换器transformer)
我们要转换的代码const add = (a, b) => a + b其实是个变量声明,按理来讲我们要转换为es5的代码也应该是个变量声明,比如这种:
var add = function(a, b) {
return a + b
}
当然也可以不按规则,直接生成一个函数声明,像这样:
function add(a, b) {
return a + b
}
这次我们把代码转换为一个es5的函数声明

我们之前的遍历器traverser接收两个参数,一个是 ast 节点对象,一个是 visitor,visitor本质是挂载不同方法的 JavaScript 对象,visitor 也叫做访问者,顾名思义它会访问 ast 上每个节点,然后根据针对不同节点用相应的方法做出不同的转换.
const transformer = (ast) => {
// 新 ast
const newAst = {
type: 'Program',
body: []
};
// 在老 ast 上加一个指针指向新 ast
ast._context = newAst.body;
traverser(ast, {
// 对于变量声明的处理方法
VariableDeclaration: (node, parent) => {
let functionDeclaration = {
params: []
};
if (node.init.type === 'ArrowFunctionExpression') {
functionDeclaration.type = 'FunctionDeclaration';
functionDeclaration.identifierName = node.identifierName;
}
if (node.init.body.type === 'BinaryExpression') {
functionDeclaration.body = {
type: 'BlockStatement',
body: [{
type: 'ReturnStatement',
argument: node.init.body
}],
};
}
parent._context.push(functionDeclaration);
},
//对于字符的处理方法
identifier: (node, parent) => {
if (parent.type === 'ArrowFunctionExpression') {
// 忽略我这暴力的操作....领略大意即可..
ast._context[0].params.push({
type: 'identifier',
identifierName: node.identifierName
});
}
}
});
return newAst;
};
生成代码(实现生成器generator)
我们之前提到过,生成代码这一步实际上是根据我们转换后的抽象语法树来生成新的代码,我们会实现一个函数, 他接受一个对象( ast),通过递归生成最终的代码
const generator = (node) => {
switch (node.type) {
// 如果是 `Program` 结点,那么我们会遍历它的 `body` 属性中的每一个结点,并且递归地
// 对这些结点再次调用 codeGenerator,再把结果打印进入新的一行中。
case 'Program':
return node.body.map(generator)
.join('\n');
// 如果是FunctionDeclaration我们分别遍历调用其参数数组以及调用其 body 的属性
case 'FunctionDeclaration':
return 'function' + ' ' + node.identifierName + '(' + node.params.map(generator) + ')' + ' ' + generator(node.body);
// 对于 `Identifiers` 我们只是返回 `node` 的 identifierName
case 'identifier':
return node.identifierName;
// 如果是BlockStatement我们遍历调用其body数组
case 'BlockStatement':
return '{' + node.body.map(generator) + '}';
// 如果是ReturnStatement我们调用其 argument 的属性
case 'ReturnStatement':
return 'return' + ' ' + generator(node.argument);
// 如果是ReturnStatement我们调用其左右节点并拼接
case 'BinaryExpression':
return generator(node.left) + ' ' + node.operator + ' ' + generator(node.right);
// 没有符合的则报错
default:
throw new TypeError(node.type);
}
};
至此我们完成了一个简陋的微型 babel,我们开始试验:
const compiler = (input) => {
const tokens = tokenizer(input);
const ast = parser(tokens);
const newAst = transformer(ast);
const output = generator(newAst);
return output;
};
const str = 'const add = (a, b) => a + b';
const result = compiler(str);
console.log(result);
// function add(a,b) {return a + b}
我们成功地将一个es6的箭头函数转换为es5的function函数.
最后
我们可以通过这个微型 babel 了解 babel 的工作原理,如果让你对编译原理产生兴趣并去深入那是更好的, babel集合包 是有数十万行代码的巨大工程,我们用区区几百行代码只能展示其最基本的原理,代码有很多不合理之处,如果想真正的了解 babel 欢迎阅读器源码.
前端可以利用编译原理相关的东西还有很多,除了我们常见的es6转换工具 babel,代码检测的 eslint等等,我们还可以:
- 小程序多端转义Taro
- 小程序热更新js 解释器
- babel与错误监控浏览器端 JavaScript 异常监控
- 模板引擎
- css 预处理后处理等等
- ...
这篇文章受the-super-tiny-compiler启发而来.
公众号
想要实时关注笔者最新的文章和最新的文档更新请关注公众号程序员面试官,后续的文章会优先在公众号更新.
简历模板: 关注公众号回复「模板」获取
《前端面试手册》: 配套于本指南的突击手册,关注公众号回复「fed」获取

面试官: 聊一聊Babel的更多相关文章
- 面试官:我们来聊一聊Redis吧,你了解多少就答多少
哈喽!大家好,我是小奇,一位不靠谱的程序员 小奇打算以轻松幽默的对话方式来分享一些技术,如果你觉得通过小奇的文章学到了东西,那就给小奇一个赞吧 文章持续更新,建议收藏关注 一.前言 作为一名Java程 ...
- 面试官问:JS的this指向
前言 面试官出很多考题,基本都会变着方式来考察this指向,看候选人对JS基础知识是否扎实.读者可以先拉到底部看总结,再谷歌(或各技术平台)搜索几篇类似文章,看笔者写的文章和别人有什么不同(欢迎在评论 ...
- 面试官:自己搭建过vue开发环境吗?
开篇 前段时间,看到群里一些小伙伴面试的时候被面试官问到这类题目.平时大家开发vue项目的时候,相信大部分人都是使用 vue-cli脚手架生成的项目架构,然后 npm run install 安装依赖 ...
- 跟面试官侃半小时MySQL事务,说完原子性、一致性、持久性的实现
提到MySQL的事务,我相信对MySQL有了解的同学都能聊上几句,无论是面试求职,还是日常开发,MySQL的事务都跟我们息息相关. 而事务的ACID(即原子性Atomicity.一致性Consiste ...
- 【我给面试官画饼】Python自动化测试面试题精讲
那今天给家分享的是一个面试主题. 就比如说我们的自动化测试,自动化如何去应对面试官,和面试官去聊一聊自动化的心得,自动化你现在去面试的时候是一个非常重要的一个关键点,所以如果你在这方面有一定的心得.那 ...
- 面试官:如何实现LRU?你学会了吗?
面试官:来了,老弟,LRU缓存实现一下? 我:直接LinkedHashMap就好了. 面试官:不要用现有的实现,自己实现一个. 我:..... 面试官:回去等消息吧.... 大家好,我是程序员学长,今 ...
- 面试官:Redis如何实现持久化的、主从哨兵又是什么?
哈喽!大家好,我是小奇,一位不靠谱的程序员 小奇打算以轻松幽默的对话方式来分享一些技术,如果你觉得通过小奇的文章学到了东西,那就给小奇一个赞吧 文章持续更新 一.前言 作为一名Java程序员,Redi ...
- 每日一问:面试结束时面试官问"你有什么问题需要问我呢",该如何回答?
面试结束时面试官问"你有什么问题需要问我呢",该如何回答?
- 面试官的七种武器:Java篇
起源 自己经历过的面试也不少了,互联网的.外企的,都有.总结一下这些面试的经验,发现面试官问的问题其实不外乎几个大类,玩不出太多新鲜玩意的.细细想来,面试官拥有以下七种武器.恰似古龙先生笔下的武侠世界 ...
随机推荐
- 线上ZK问题排查
问题描述 测试环境ZK集群的三个节点中zk1状态虽然是follower,启动也能正常启动(通过telnet也能telnet 2181端口); 无法通过zk客户端去连接2181端口,状态一致是CONNE ...
- js学习重点难点知识总结 (巩固闭包、原型、原型链)
学习重点知识总结 1.闭包知识点巩固 闭包函数: 1.可以实现函数外部访问函数内部的变量 2.在Java ...
- jquery实现表格导入到Excel(加图片)
话不多说直接上代码 第一步:导入jquery的插件https://github.com/rainabba/jquery-table2excel HTML部分: 第二步:添加一个按钮 <but ...
- python 16 模块
目录 模块 1. 自定义模块 1.1 模块分类 1.2 模块的导入 1.3 import 和 from 1.4 from 模块名 import * 1.5 模块的用法: 1.6 导入路径 2. tim ...
- js 前端实现打印功能
// 此处是一个打印的方法 可以在点击事件的时候调用 dayin = () =>{ // 获取当前页面要打印的内容 // 这里的className(‘print’)是我给要打印的区域起的 ...
- unity编辑器扩展_01(在工具栏中创建一个按钮)
代码: [MenuItem("Tools/Test",false,1)] static void Test() { Debug.Log("tes ...
- python程序中使用MySQL数据库
目录 python程序中使用MySQL数据库 1 pymysql连接数据库 2 sql 注入 3 增删改查操作 4 pymysql使用总结 python程序中使用MySQL数据库 1.python中使 ...
- Scala 系列(十二)—— 类型参数
一.泛型 Scala 支持类型参数化,使得我们能够编写泛型程序. 1.1 泛型类 Java 中使用 <> 符号来包含定义的类型参数,Scala 则使用 []. class Pair[T, ...
- 算法与数据结构基础 - 贪心(Greedy)
贪心基础 贪心(Greedy)常用于解决最优问题,以期通过某种策略获得一系列局部最优解.从而求得整体最优解. 贪心从局部最优角度考虑,只适用于具备无后效性的问题,即某个状态以前的过程不影响以后的状态. ...
- Delphi - Indy TIdThreadComponent 线程研究
Indy IdThreadComponent 线程研究 前几天在开发数据实时解析功能模块的时候,发现解析数据量巨大,特别耗时,程序一跑起来界面假死. 为了优化用户体验,采用了Indy 自带的IdThr ...