〈三〉ElasticSearch的认识:搜索、过滤、排序
发表日期:2019年9月20日
上节回顾
1.讲了如何对索引CRUD
2.重新解释了type,只是元数据的效果
3.讲了如何对文档CRUD
本节前言
1.ElasticSearch的主要功能是搜索,这节也将会主要讲搜索,将会涉及到如何使用关键字进行全文搜索
2.除了讲搜索,也会讲到搜索相关的“分页”、“排序”、“聚合分析”等内容。
3.还会补充一些与搜索相关的知识。
文档的搜索
测试数据:请先插入以下数据,以便练习搜索功能
【突然看了一下之前的博文,发现我后面去准备数据的时候写错格式了。所以导致id为1,2,3的文档和后面的文档的字段不一样。你可以仅仅基于以下的数据来测试】
PUT /douban/book/5
{
"book_id":5,
"book_name":"A Boy's Own Story",
"book_author":"Edmund White",
"book_pages":217,
"book_express":"Vintage",
"publish_date":"1994-02-01",
"book_summary":"""
An instant classic upon its original publication, A Boy's Own Story is the first of Edmund White's highly acclaimed trilogy of autobiographical novels that brilliantly evoke a young man's coming of age and document American gay life through the last forty years.
The nameless narrator in this deeply affecting work reminisces about growing up in the 1950s with emotionally aloof, divorced parents, an unrelenting sister, and the schoolmates who taunt him. He finds consolation in literature and his fantastic imagination. Eager to cultivate intimate, enduring friendships, he becomes aware of his yearning to be loved by men, and struggles with the guilt and shame of accepting who he is. Written with lyrical delicacy and extraordinary power, A Boy's Own Story is a triumph."""
}
PUT /douban/book/6
{
"book_id":6,
"book_name":"The Lost Language of Cranes",
"book_author":"David Leavitt",
"book_pages":352,
"book_express":"Bloomsbury Publishing PLC",
"publish_date":"2005-05-02",
"book_summary":"""David Leavitt's extraordinary first novel, now reissued in paperback, is a seminal work about family, sexual identity, home, and loss. Set in the 1980s against the backdrop of a swiftly gentrifying Manhattan, The Lost Language of Cranes tells the story of twenty-five-year-old Philip, who realizes he must come out to his parents after falling in love for the first time with a man. Philip's parents are facing their own crisis: pressure from developers and the loss of their longtime home. But the real threat to this family is Philip's father's own struggle with his latent homosexuality, realized only in his Sunday afternoon visits to gay porn theaters. Philip's admission to his parents and his father's hidden life provoke changes that forever alter the landscape of their worlds."""
}
PUT /douban/book/7
{
"book_id":7,
"book_name":"Immortality",
"book_author":"Milan Kundera",
"book_pages":400,
"book_express":"Faber and Faber",
"publish_date":"2000-08-21",
"book_summary":"""Milan Kundera's sixth novel springs from a casual gesture of a woman to her swimming instructor, a gesture that creates a character in the mind of a writer named Kundera. Like Flaubert's Emma or Tolstoy's Anna, Kundera's Agnes becomes an object of fascination, of indefinable longing. From that character springs a novel, a gesture of the imagination that both embodies and articulates Milan Kundera's supreme mastery of the novel and its purpose: to explore thoroughly the great themes of existence."""
}
搜索的方式主要有两种,URL搜索和请求体搜索,一个是将搜索的条件写在URL中,一个是将请求写在请求体中。
URL参数条件搜索
语法:GET /index/type/_search?参数
参数解析:
- q:使用某个字段来进行查询,例如q:book_name=book,就是根据book_name中是否有book来进行搜索。
- sort:使用某个字段来进行排序,例如sort=cost:desc,就是根据cost字段来进行降序desc排序。
- 其他:fileds,timeout,analyzer【这些参数留在请求体搜索中讲】
- 不带参数时,为“全搜索”
- 多个参数使用&&拼接
示例:
GET /douban/book/_search?q=book_summary:character
GET /douban/book/_search?q=book_author:Milan
GET /douban/book/_search?q=book_summary:a
GET /douban/book/_search?q=book_summary:a&&sort=book_pages:desc
GET /douban/book/_search?q=book_summary:a&&q=book_author:Milan
【值得注意的是,请先不要对text类型的数据进行排序,这会影响搜索,对整数排序即可,后面会再细讲】
查询结果解析:
【考虑到数据太长的问题,所以我给了另一个搜索结果的返回截图】

补充:把搜索条件写在url中的搜索方式比较少用,因为查询参数拼接到URL中会比较麻烦。
请求体条件搜索
语法与示例:
//全搜索
GET /index/type/_search
GET /douban/book/_search
//全搜索
GET /index/type/_search
{
"query": {
"match_all": {}
}
}
GET /douban/book/_search
{
"query": {
"match_all": {}
}
}
// 查询指定字段的数据(全文搜索,如果搜索值有多个词,仅匹配一个词的结果也可以查询出来):
GET /index/type/_search
{
"query": {
"match": {
"字段名": "搜索值"
}
}
}
GET /douban/book/_search
{
"query": {
"match": {
"book_name": "A The"
}
}
}
// 使用同一搜索值搜索多个字段:
GET /index/type/_search
{
"query": {
"multi_match": {
"query": "搜索值",
"fields": [
"搜索的字段1","搜索的字段2"]
}
}
}
GET /douban/book/_search
{
"query": {
"multi_match": {
"query": "A",
"fields": [
"book_name","book_summary"]
}
}
}
// 短语查询:【搜索值必须完全匹配,不会把搜索值拆分来搜索】
GET /index/type/_search
{
"query": {
"match_phrase": {
"字段": "搜索值"
}
}
}
GET /douban/book/_search
{
"query": {
"match_phrase": {
"book_summary": "a character"
}
}
}
// 字段过滤,查询的结果只显示指定字段
GET /product/book/_search
{
"query": {
"查询条件"
},
"_source": [
"显示的字段1",
"显示的字段2"
]
}
GET /douban/book/_search
{
"query": {
"match": {
"book_name": "Story"
}
},
"_source": [
"book_name",
"book_id"
]
}
// 高亮查询:【根据查询的关键字来进行高亮,高亮的结果会显示在返回结果的会自动在返回结果中的highlight中,关键字会被加上<em>标签】
// 如果想要多字段高亮,也需要进行多字段搜索
GET /index/book/_search
{
"query": {
"查询条件"
},
"highlight": {
"fields": {
"高亮的字段名1": {}
}
}
}
GET /douban/book/_search
{
"query": {
"match": {
"book_summary": "Story"
}
},
"highlight": {
"fields": {
"book_summary":{}
}
}
}
GET /douban/book/_search
{
"query": {
"multi_match": {
"query": "Story",
"fields": [
"book_name","book_summary"]
}
},
"highlight": {
"fields": {
"book_summary":{},
"book_name":{}
}
}
}
上面展示了关于全搜索、单字段值全文搜索、多字段单一搜索值全文搜索、短语搜索、字段过滤、高亮搜索的代码。
由于对多个字段使用不同搜索值涉及条件拼接,所以单独讲。
前置知识讲解:对于条件拼接,在SQL中有and,or,not,在ElasticSearch不太一样,下面逐一讲解:
bool:用来表明里面的语句是多条件的组合,用来包裹多个条件。should:里面可以有多个条件,查询结果必须符合查询条件中的一个或多个。must:里面的多个条件都必须成立must_not:里面的多个条件必须不成立
示例:
// 书名必须包含Story的
GET /douban/book/_search
{
"query": {
"bool": {
"must": [
{
"match":{
"book_name":"Story"
}
}
]
}
}
}
// 书名必须不包含Story的
GET /douban/book/_search
{
"query": {
"bool": {
"must_not": [
{
"match":{
"book_name":"Story"
}
}
]
}
}
}
// 书名必须不包含Story,书名包含Adventures或Immortality的
GET /douban/book/_search
{
"query": {
"bool": {
"must_not": [
{
"match":{
"book_name":"Story"
}
}
],
"should": [
{
"match": {
"book_name": "Adventures"
}
},
{
"match": {
"book_name": "Immortality"
}
}
]
}
}
}
// 在should、must、must_not这些里面都可以放多个条件
GET /douban/book/_search
{
"query": {
"bool": {
"must_not": [
{
"match":{
"book_name":"Story"
}
},
{
"match": {
"book_name": "Adventures"
}
}
]
}
}
}
// 如果是单个条件的时候,还可以这样写,省去[]:
GET /douban/book/_search
{
"query": {
"bool": {
"must_not": {
"match":{
"book_name":"Story"
}
}
}
}
}
// 还可以条件嵌套,也就是再嵌套一层bool,不过要注意逻辑,例如:
// 查询出(书名有story)或者(书名有The而且作者名有David)的,第二个是可成立可不成立的。
GET /douban/book/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"book_name": "Story"
}
},
{
"bool": {
"must": [
{
"match": {
"book_name": "The"
}
},
{
"match": {
"book_author": "David"
}
}
]
}
}
]
}
}
}
补充:
- 上面讲了URL参数条件搜索和请求体条件搜索,讲了
全搜索、单字段值全文搜索、多字段单一搜索值全文搜索、短语搜索、字段过滤、高亮搜索的使用方法,还讲了基于bool、should、must、must_not的多条件搜索,上面的知识已经能基础地实现一些搜索功能了。但还是有一些知识由于比较晦涩,所以留到后面章节讲,比如给搜索指定分词器、给多条件指定匹配数量、滚动查询等等。
小节总结:
上面讲了URL参数条件搜索和请求体条件搜索。URL参数条件写在URL里面,用?来附带参数,q用来指定搜索字段。请求体参数把条件写在请求体中,query是最外层的包裹,match_all用于查询所有,match用来使用指定搜索值搜索某一字段,match_phrase用来搜索连续的搜索,_source用来字段过滤(与query同级,[]里面是字段名),highlight用来高亮搜索(与query同级,里面是{field:{字段名1:{},字段名2:{}}}),bool、should、must、must_not用来多条件搜索。
文档的过滤filter
过滤的效果其实有点像条件搜索,不过条件搜索会考虑相关度分数和考虑分词,而过滤是不考虑这些的,过滤对相关度没有影响。过滤一般用于结构化的数据上,也就是通常不用于使用了分词的数据上,通常都会用在数值类型和日期类型的数据上。
在搜索的时候,如果你不希望要搜索的条件会影响到相关度,那么就把它放在过滤中,如果希望影响相关度,那么就放在条件搜索中。
使用过滤时,由于不考虑相关度,所以score固定为1。
文档的过滤filter里面主要有五种字段,range,term,terms,exist,missing。range用于字段数据比较大小;term主要用于比较字符类型的和数值类型的数据是否相等;terms是term的复数版,里面可以有多个用于比较相等的值;exist和missing用于判断文档中是否包含指定字段或没有某个字段(仅适用于2.0+版本,目前已经移除)
语法与举例:
// range,gte是不小于,lte是不大于,eq是等于,gt是大于,lt是小于
GET / index/type/_search
{
"query": {
"range": {
"字段名": {
"gte": 比较值
[,"lte": 比较值]
}
}
}
}
GET /douban/book/_search
{
"query": {
"range": {
"book_pages": {
"gte": 352,
"lt":400
}
}
}
}
// term用于匹配字符串和数值型类型的数据(解决了range中没有eq的问题),但不能直接用于分词的字段。
//【这个并没有那么简单,会后续再讲,直接匹配一些会分词的字段时,会匹配失败,
//因为这时候这个字段拿来匹配的都是散乱的值,不是完整的原本的字段数据,所以下面用了不分词的数值型的字段来演示】
GET /douban/book/_search
{
"query": {
"term": {
"字段": "搜索值"
}
}
}
GET /douban/book/_search
{
"query": {
"term": {
"book_pages": 352
}
}
}
//terms
GET /douban/book/_search
{
"query": {
"terms": {
"字段": ["搜索值1","搜索值2"]
}
}
}
GET /douban/book/_search
{
"query": {
"terms": {
"book_pages": [
"352",
"400"
]
}
}
}
term的问题:
- 首先,提一下的是,在搜索的时候,你并不直接面向原始文档数据,而是面向倒排索引,这意思是什么呢?比如你要进行全文搜索,那么你的搜索值并不是与数据文件比对的,而是与倒排索引匹配的,也就是在我们与数据文件之间有一个专门用于搜索的层次。
- 对于match和match_all,这些都是全文搜索,就不说了,直接就是通过索引词在索引文件中找到对应的文档;比较不同的是match_phrase这个会匹配一段词的搜索,他是怎么查询的呢?他实际上也会去查索引文件中包括了搜索值中所有词并且词的在文档中的位置顺序也一致的记录,所以这个短语匹配其实也是通过倒排索引来搜索的。
- 而倒排索引中其实包含了所有字段的标识,对于分词的字段,会存储索引词;对于不分词的,会存储整个数据。【对于分词的字段可以加一个keyword来保留完整的数据,这个后面再讲。】
- 而term的搜索主要面向不分词的数据,所以无法直接用于分词的字段,除非加keyword。
官方文档中关于term
filter与bool
filter也可以用于多条件拼接。例如:
GET /douban/book/_search
{
"query": {
"bool": {
"must": [
{
"match":{
"book_name":"Story"
}
},
{
"range": {
"book_pages": {
"lte":300
}
}
}
]
}
}
}
GET /douban/book/_search
{
"query": {
"bool": {
"must": [
{
"match":{
"book_name":"Story"
}
},
{
"range": {
"book_pages": {
"lte":300
}
}
},
{
"term": {
"publish_date": "1994-02-01"
}
}
]
}
}
}
在这样条件搜索和过滤一起用的情况下,要注意filter过滤是不计算相关度的,在上面中,假设只有match,那么某个文档相关度为0.2,加上filter后,会变成1.2。因为filter默认提供的相关度为1。
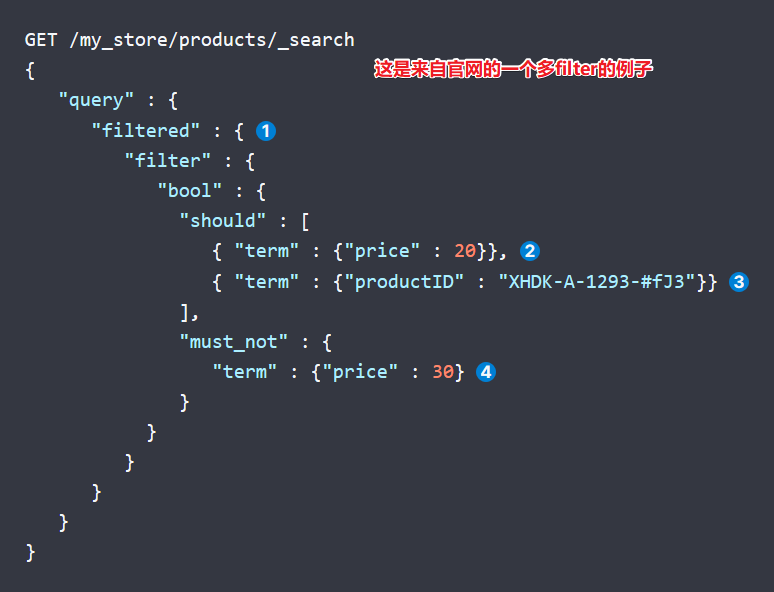
constant_score
过滤还可以这样写:
GET /douban/book/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"book_pages": {
"gte": 352,
"lt": 400
}
}
}
}
}
}
// boost设置filter提供的相关度score值
GET /douban/book/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"book_pages": {
"gte": 352,
"lt": 400
}
}
},
"boost": 1.2
}
}
}
cache
对于过滤,elasticsearch会临时缓存它的结果,以便可能下次仍需使用它。因为过滤是不关心相关度的。
官方文档--过滤缓存
小节总结:
这节介绍了不影响相关度的搜索--过滤,过滤通常用于过滤结构化数据,也就是那些不分词的数据,其中range用于数值范围过滤,term用于字符类型的数据或数值类型的数据的值是否相等,terms是term的复数版。过滤也支持bool拼接多个条件。过滤提供的相关度分数是一个常数,默认是1。
文档的聚合分析
准备数据
先准备一批测试数据:
PUT /people/test/1
{
"name":"lilei1",
"age":18,
"gender":1
}
PUT /people/test/2
{
"name":"lilei2",
"age":17,
"gender":0
}
PUT /people/test/3
{
"name":"lilei4",
"age":21,
"gender":1
}
PUT /people/test/4
{
"name":"lilei4",
"age":15,
"gender":0
}
PUT /people/test/5
{
"name":"lilei1 2",
"age":15,
"gender":0
}
像在SQL中会需要SUM(),MAX().AVG()函数。ElasticSearch也提供了关于聚合分析的函数。
ElasticSearch中常见的聚合分析函数有terms(分组函数)、avg(平均数)、range(区间分组)、max(求最大值)、min(求最小值)、cardinality(获取唯一值的数量)、value_count(获取值的数量,不去重,可以得出多少个值参与了聚合)。
语法与举例:
语法:
GET /index/type/_search
{
"aggs": {
"自定义聚合名称": {
"聚合函数": {
聚合参数
}
}
}
}
举例:
// 按性别分组
GET /douban/book/_search
{
"aggs": {
"groud_by_express": {
"terms": {
"field": "book_id",
"size": 10
}
}
}
}
//求年龄的平均数
GET /people/test/_search
{
"aggs": {
"avg_of_age": {
"avg": {
"field": "age"
}
}
}
}
// 求年龄的最大值:
GET /people/test/_search
{
"aggs": {
"max_of_age": {
"max": {
"field": "age"
}
}
}
}
// 把年龄[15,17]的分成一组,把年龄[18,25]的分成一组
GET /people/test/_search
{
"aggs": {
"range_by_age": {
"range": {
"field": "age",
"ranges": [
{
"from": 15,
"to": 17
},
{
"from": 18,
"to": 25
}
]
}
}
}
}
// 获取不同的年龄数:,比如有年龄[1,2,3,3,4,5],得到的结果是5,因为3只算一次
GET /people/test/_search
{
"aggs": {
"get_diff_age_count": {
"cardinality": {
"field": "age"
}
}
}
}
返回结果解析:

其他语法:
先查询后聚合:
GET /people/test/_search
{
"query": {
"match": {
"name": "lilei1"
}
},
"aggs": {
"avg_of_age": {
"avg": {
"field": "age"
}
}
}
}
先过滤后聚合:
// 先获取年龄大于15的,再求平均值
GET /people/test/_search
{
"query": {
"range": {
"age": {
"gt":15
}
}
},
"aggs": {
"avg_of_age": {
"avg": {
"field": "age"
}
}
}
}
聚合函数嵌套:
// 先按性别分组,再获取年龄平均值
GET /people/test/_search
{
"aggs": {
"groud_by_express": {
"terms": {
"field": "gender"
},
"aggs": {
"avg_of_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
聚合+排序:
// 先按性别分组,再按分组的年龄平均值降序排序,order中的avg_of_age就是下面的聚合函数的自定义名称
GET /people/test/_search
{
"aggs": {
"groud_by_express": {
"terms": {
"field": "gender",
"order": {
"avg_of_age": "desc"
}
},
"aggs": {
"avg_of_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
补充:
上面只讲了一些基础的聚合,聚合分析是一个比较重要的内容,会在后面的再讲。
小节总结:
本节主要讲了ElasticSearch中关于数据聚合的使用方法,aggs是与query同级的,使用聚合函数需要自己定义一个外层的聚合函数名称,avg用于求平均值,max用于求最大值,range用于范围分组,term用于数据分组。分组可以与条件搜索和过滤一起使用,aggs是与query同级的,聚合函数也可以嵌套使用。
文档的分页、排序
【使用一下上一节准备的数据】
分页
// 从第一条开始,获取两条数据
GET /people/test/_search
{
"from": 0,
"size": 2
}
// 可以先查询,再分页
GET /people/test/_search
{
"query": {
"match": {
"name": "lilei1"
}
},
"from": 0,
"size": 1
}
排序
【请注意,下面的结果中你可以看到score为null,因为这时候你使用了age字段来排序,而不是相关性,所以此时相关性意义不大,则不计算。】
排序处理:【sort与query同级别,是一个数组,里面可以有多个排序参数,参数以{"FIELD":{"order":"desc/asc"}}为格式】
GET /people/test/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
deep paging
对于分页和排序,需要共同面对一个问题:
首先,你要想到一个索引中的数据是散落在多个分片上的,你如何确定另一个分片上的数据与其他分片上的顺序问题?,比如可能A分片上的有数值为1和数值为3的数据,而B分片上有数值为2和数值为4的数据,所以B分片的部分数据与A分片数据的大小是不确定的。那么排序的时候怎么处理这些散落的数据呢?(就算是依据相对度来排序,这个时候散落的数据的相关度也是不太好确定的)
分页需要面对的问题也同样是因为数据散落的而不好排序的问题,因为分页也是要排序的,默认是按相关度排序。因为散落的数据的值的大小不确定,所以就需要把所有可能的数据取出来排完序再分页,这就会导致需要取出远远超出“页数”的数据来计算。
- 有两个primary shard(命名为A和B),现在要取第1000页的数据,假设每一页10条记录,那么理论上是只需要取第10000到第10010条记录出来即可。
- 但这时候我们并不知道A和B中的_score的大小如何,可能A中的最小的_score要比B中的最大的_score都要大,反过来也有可能,(所以我们并不能说仅仅从A和B中分别取10000到10010出来进行比较即可,我们需要对前面的数据都进行比较,以避免最小的_score都比另一个shard上的_score大的情况),为了确保数据的正确性,我们需要从A和B中都取出1到10010的数据来进行排序比较,然后再取出里面的10000到10010条。
- 所以,你看到了,我们只是为了拿十条数据,竟然要查10010数据出来。这就是deep paging了。
补充:
- 除了上述的内容,一个没讲的而且比较重要的内容应该是滚动查询,滚动查询有点类似分页查询,但它会提前准备好数据,我暂时没想好放在哪里讲合适,可能会在后面写,也有可能某一天补充在这里。
小节总结:
上面讲了怎么进行数据的分页获取和数据的排序,使用from和size分页,使用sort排序;还讲了一个如果查询时页数太深而可能导致的deep paging问题,问题的原因是多个分片上的数据大小不确定,不方便排序。
〈三〉ElasticSearch的认识:搜索、过滤、排序的更多相关文章
- 〈一〉ElasticSearch的介绍
目录 什么是ElasticSearch 核心能力 ES的搜索核心 搜索引擎选择 搜索的处理 补充: 小节总结: 基本学习环境搭建 如何操作ElasticSearch 下载.安装和运行(Based Wi ...
- 〈四〉ElasticSearch的认识:基础原理的补充
目录 想想我们漏了什么 回顾 补回 集群的建立 集群发现机制 配置文件 健康状态 补充: 小节总结 分片的管理 梳理 分片的均衡分配 主副分片的排斥 容错性: 数据路由 对于集群健康状态的影响 小节总 ...
- 〈二〉ElasticSearch的认识:索引、类型、文档
目录 上节回顾 本节前言 索引index 创建索引 查看索引 查看单个索引 查看所有索引 删除索引 修改索引 修改副本分片数量 关闭索引 索引别名 增加索引别名: 查看索引别名: 删除索引别名: 补充 ...
- 数往知来C#面向对象〈三〉
C# 基础方法篇 一.复习 1)方法的重载 方法的重载并不是一个方法,实际上方法的重载就是一些不同的 方法,目的是为了方便程序员编码,所以将功能相近的方法命名相同 根据参数,编译器自动的去匹配方法体, ...
- 三 drf 认证,权限,限流,过滤,排序,分页,异常处理,接口文档,集xadmin的使用
因为接下来的功能中需要使用到登陆功能,所以我们使用django内置admin站点并创建一个管理员. python manage.py createsuperuser 创建管理员以后,访问admin站点 ...
- elasticsearch的rest搜索--- 查询
目录: 一.针对这次装B 的解释 二.下载,安装插件elasticsearch-1.7.0 三.索引的mapping 四. 查询 五.对于相关度的大牛的文档 四. 查询 1. 查询的官网的文档 ...
- Elasticsearch入门教程(三):Elasticsearch索引&映射
原文:Elasticsearch入门教程(三):Elasticsearch索引&映射 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文 ...
- elasticsearch实现网站搜索
使用elasticsearch 实现网站搜索,可以支持商品搜索,筛选项过滤搜索 ,价格排序, 打分 筛选项聚合,还有其他综合排序 后续推出搜索人工干预排序,根据销量,好评率,售卖率 进行全方位的搜索实 ...
- Python 和 Elasticsearch 构建简易搜索
Python 和 Elasticsearch 构建简易搜索 作者:白宁超 2019年5月24日17:22:41 导读:件开发最大的麻烦事之一就是环境配置,操作系统设置,各种库和组件的安装.只有它们都正 ...
随机推荐
- CSV Data Set Config 详细使用说明
JMeter 5.1.1 CSV Data Set Config 场景一:线程组中设置:单线程执行1次 如上图所示:变量名称为空时JMeter默认把new 1.txt的文件首行作为变量名 再如:此时A ...
- ThreadLocalSingleton.h——base
#ifndef MUDUO_BASE_THREADLOCALSINGLETON_H #define MUDUO_BASE_THREADLOCALSINGLETON_H #include <boo ...
- Tomcat源码分析 (十)----- 彻底理解 Session机制
Tomcat Session 概述 首先 HTTP 是一个无状态的协议, 这意味着每次发起的HTTP请求, 都是一个全新的请求(与上个请求没有任何联系, 服务端不会保留上个请求的任何信息), 而 Se ...
- OpenXML性能真的低下吗?
博文NET导出Excel的四种方法及评测 中对比了4个库的导出性能,但对OpenXML的评价并不高,本人觉得不合理,所以我重新测试下性能 基于OpenXML的包装类 ExcelDownWorker p ...
- Python-demo(video)
#!/usr/bin/env python# #-*-coding:utf-8-*-import requestsimport randomimport timedef get_json(url): ...
- HOWTO: Amira/Avizo中如何设置数据尺度单位
很多朋友是数据量化完成后,问统计表中的数据尺度单位,这种情况恐怕需要从头再处理一次,所以对于Amira/Avizo的新用户来说,在准备进行量化分析之前就应该设置好尺度单位,设置步骤如下: 1. 在A ...
- 设置ABP默认使用中文
ABP提供的启动模板, 默认使用是英文: 虽然可以通过右上角的菜单切换成中文, 但是对于国内项目来说, 默认使用中文是很正常的需求. 本文介绍了如何实现默认语言的几种方法, 希望能对ABP爱好者有所帮 ...
- C++ 线程安全的单例模式总结
什么是线程安全? 在拥有共享数据的多条线程并行执行的程序中,线程安全的代码会通过同步机制保证各个线程都可以正常且正确的执行,不会出现数据污染等意外情况. 如何保证线程安全? 给共享的资源加把锁,保证每 ...
- PythonWeb框架Django:虚拟环境安装(virtualenv)
虚拟环境的用处: 当我们有多个项目要使用不同的第三方类库的时候,就会发生冲突,因为Python的环境内只允许一个版本的第三方类库. 比如说 有A,B两个Web项目,但是A项目的Django的环境为2. ...
- Delphi - 获取文件大小
GetFileSize获取文件大小 封装成如下函数,可以直接使用: ///函数功能:获取文件大小,单位取KB,小数自动进位 ///参数:sFilePath文件全路径 ///Result: 成功是返回文 ...