spark 在yarn模式下提交作业
1、spark在yarn模式下提交作业需要启动hdfs集群和yarn,具体操作参照:hadoop 完全分布式集群搭建
2、spark需要配置yarn和hadoop的参数目录
将spark/conf/目录下的spark-env.sh.template文件复制一份,加入配置:
YARN_CONF_DIR=/opt/hadoop/hadoop-2.8.3/etc/hadoop
HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.8.3/etc/hadoop
3、将spark整个目录分发到hdfs集群中每台机器上,分发命令可以参考:linux rsync
如果不想用rsync也可以直接用scp -r拷贝,测试环境下差别不大。
4、提交作业测试
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.4.4.jar 200
正常情况下很快就能计算完成:

在yarn的UI可以监控到执行的作业:
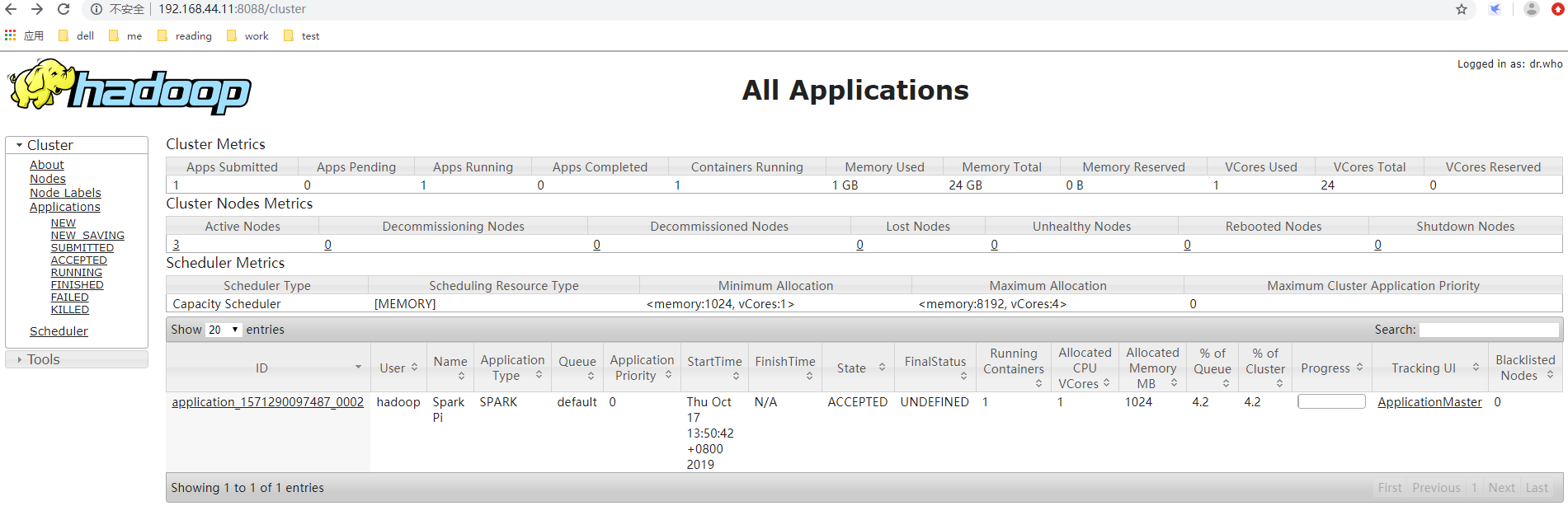
5、spark参数优先级
Spark加载属性参数的优先顺序是:
(1)直接在SparkConf设置的属性参数
(2)通过 spark-submit 或 spark-shell 方式传递的属性参数
(3)最后加载 spark-defaults.conf 配置文件的属性参数
如果在程序里指定了SparkConf的参数,则spark缺省参数以及命令行参数都将失效,如果想灵活一下,我们可以在SparkConf加载缺省配置(spark-defaults.conf),然后在命令方式下覆盖参数。
val conf: SparkConf = new SparkConf(true).setAppName("SparkWordCount")
master这个参数就可以指定local或者yarn等模式,但是name参数在命令指定是无效的,因为已经内置了。
bin/spark-submit --master yarn --name myWordCount --class com.home.spark.WordCount --executor-memory 512M ~/sparkWordCount.jar hdfs://vmhome10.com:9000/input
spark 在yarn模式下提交作业的更多相关文章
- spark on yarn模式下配置spark-sql访问hive元数据
spark on yarn模式下配置spark-sql访问hive元数据 目的:在spark on yarn模式下,执行spark-sql访问hive的元数据.并对比一下spark-sql 和hive ...
- spark on yarn模式下内存资源管理(笔记1)
问题:1. spark中yarn集群资源管理器,container资源容器与集群各节点node,spark应用(application),spark作业(job),阶段(stage),任务(task) ...
- spark on yarn模式下内存资源管理(笔记2)
1.spark 2.2内存占用计算公式 https://blog.csdn.net/lingbo229/article/details/80914283 2.spark on yarn内存分配** 本 ...
- Spark在StandAlone模式下提交任务,spark.rpc.message.maxSize太小而出错
1.错误信息org.apache.spark.SparkException: Job aborted due to stage failure:Serialized task 32:5 was 172 ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)(转)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- flink on yarn模式下两种提交job方式
yarn集群搭建,参见hadoop 完全分布式集群搭建 通过yarn进行资源管理,flink的任务直接提交到hadoop集群 1.hadoop集群启动,yarn需要运行起来.确保配置HADOOP_HO ...
- Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
说白了 Spark on YARN模式的安装,它是非常的简单,只需要下载编译好Spark安装包,在一台带有Hadoop YARN客户端的的机器上运行即可. Spark on YARN简介与运行wor ...
- spark on yarn模式里需要有时手工释放linux内存
为什么要提出这个问题? spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED) 然后执行 [spark@master spark--bin- ...
随机推荐
- PHP+Ajax实现文章心情投票功能实例
一个PHP+Ajax实现文章心情投票功能实例,可以学习了解实现投票的基本流程:通过ajax获取心情图标及柱状图相关数据,当用户点击其中的一个心情图标时,向Ajax.php发送请求,PHP验证用户coo ...
- extjs 动态加载列表,优化思路
功能截图 之前做法,先查询每一行的前4个字段,然后动态拼接出其他的字段,效率极低,以下是优化后的代码,供参考,只提供一个优化思路,授人以鱼不如授人以渔 后台Sql语句优化(语法仅支持Oracle) S ...
- Python计算美国总统的身高并实现数据可视化
代码如下: import numpy as np import pandas as pd import matplotlib.pyplot as plt data=pd.read_csv('presi ...
- 为什么AlertDialog要使用Builder来构建呢
为什么 AlertDialog 使用Builder 模式呢? 首先说句废话,因为 AlertDialog 太过复杂,内部参数太多,然后不使用构建者模式那么 AlertDialog 的构造方法就可能是: ...
- 默认VS 下machine.config的位置
- Ubuntu 18.04 安装 python 的 redis 库
安装 如果只是安装了 python2.x 或者 python3.x,直接安装即可,命令如下: pip install redis 如果是同时安装了 python2.x 和 python3.x 的,则需 ...
- NOIP 2016 玩具谜题
洛谷 P1563 玩具谜题 洛谷传送门 JDOJ 3136: [NOIP2016]玩具谜题 D1 T1 JDOJ传送门 Description 小南有一套可爱的玩具小人, 它们各有不同的职业. 有一天 ...
- Vue 组件通信的多种方式(props、$ref、$emit、$attr、 $listeners)
prop和$ref之间的区别: prop 着重于数据的传递,它并不能调用子组件里的属性和方法.像创建文章组件时,自定义标题和内容这样的使用场景,最适合使用prop. $ref 着重于索引,主要用来调用 ...
- Sphinx 2.0.8 发布,全文搜索引擎 Installing Sphinx on Windows
参考资料地址信息 http://sphinxsearch.com/docs/latest/installing-windows.html http://my.oschina.net/melonol/b ...
- 关于scanf的一些知识
10.22,对现阶段已知道的scanf的一些用法或注意事项的一些总结: 1.scanf中,赋值的那个数据前面一定加&! 2.若情景要求必须输入空格的,scanf("%d%c%d&qu ...