爬虫---爬取b站小视频
前面通过python爬虫爬取过图片,文字,今天我们一起爬取下b站的小视频,其实呢,测试过程中需要用到视频文件,找了几个网站下载,都需要会员什么的,直接写一篇爬虫爬取视频~~~
分析b站小视频
1、进入到抓取链接地址
http://vc.bilibili.com/p/eden/rank#/?tab=%E5%85%A8%E9%83%A8
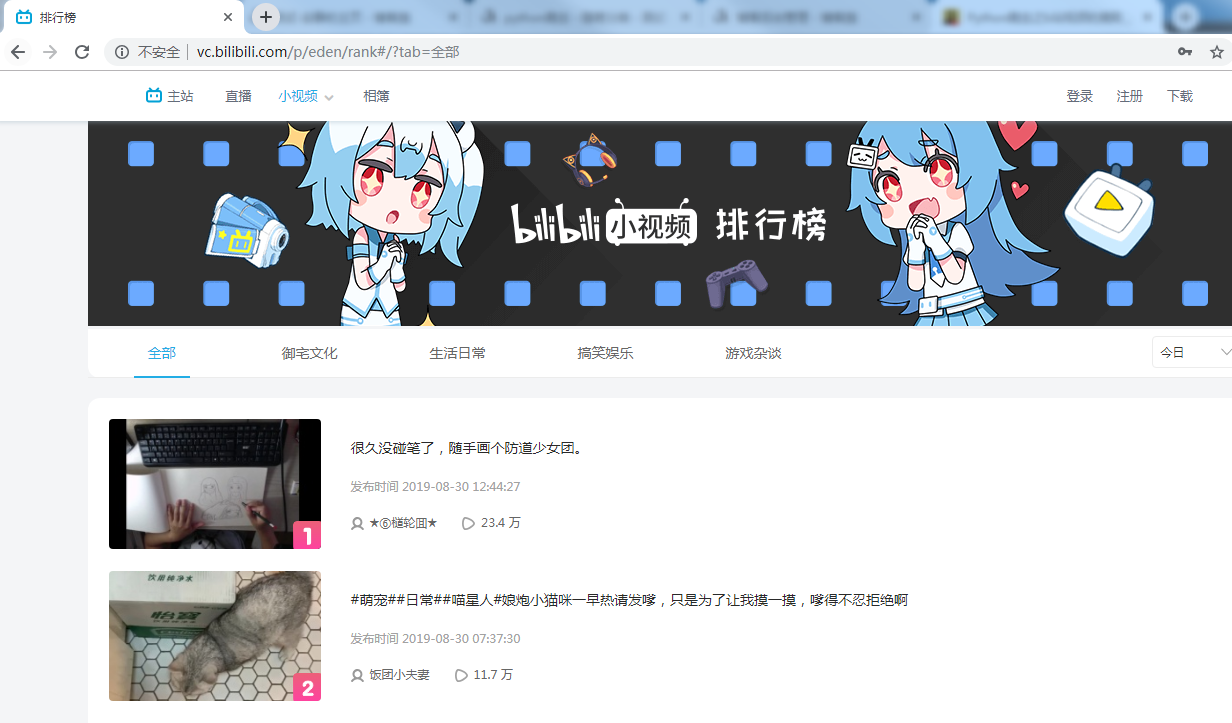
2、分析抓取链接内容
通过F12或者抓包工具进行查看我们需要爬取的视频在哪里存放,页面以ajax动态加载的
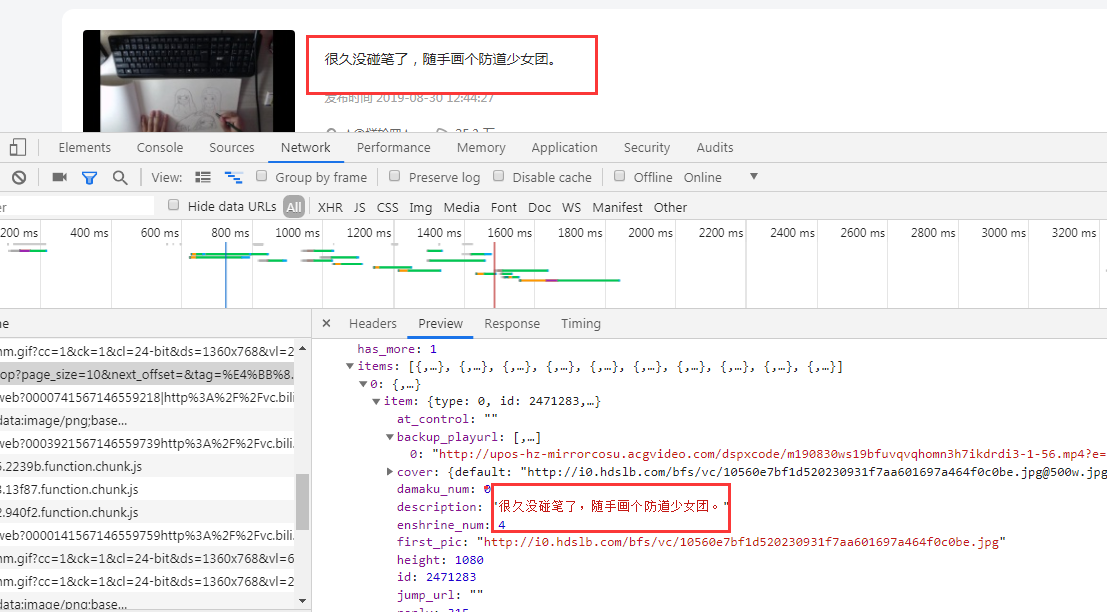
3、分析请求内容和请求参数
通过查看请求内容得到这些数据
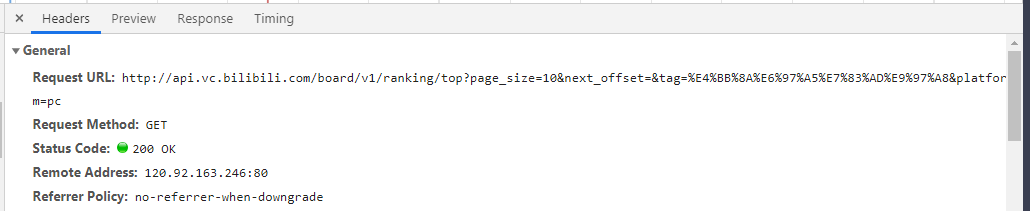
1、请求的接口地址
2、请求方式为get
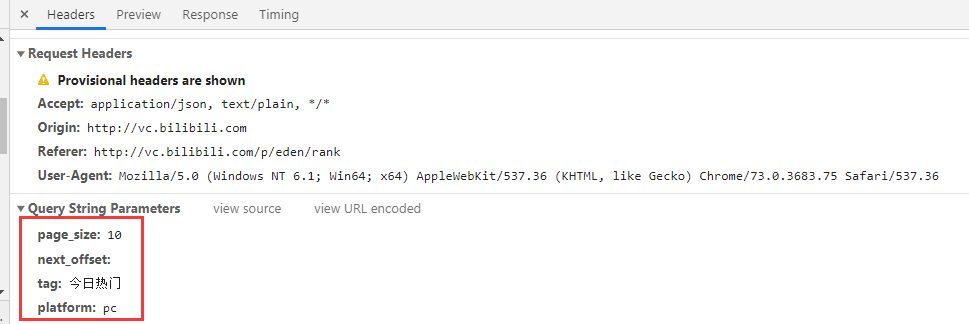
3、请求参数为
- page_size 显示的个数
- next_offset 动态跳转页面
- tag 搜索标题
- platfrom (应该是pc端)
分析了页面内容,那么动手来写代码,爬取视频下来
爬取b站小视频
开始写代码之前呢,我们也要一步一步的来,分清楚每一步都是干什么用的,这样的话才能让我们写的代码更加清除。
1、构建请求信息,请求需要爬取的地址
# 构建请求信息,获取数据信息
def get_json(url,ajax):
# 构建请求信息
params = {
'page_size':10,
'next_offset': ajax,
'tag':'今日热门',
'platform':'pc'
}
# 防止请求失败
try:
html = requests.get(url,params=params,headers=headers).json()
return html
except BaseException:
print('页面加载失败')
2、进行访问链接,下载视频
# 获取视频信息
def get_video(viedeo_url,path):
# 取出来视频的名称和地址
r2 = requests.get(viedeo_url,headers=headers)
with open(path,'wb')as f:
f.write(r2.content)
3、保存下载的视频
infos=html['data']['items']
for info in infos:
title = info['item']['description']#小视频的标题
video_url = info['item']['video_playurl']#视频地址
print(title,video_url)
#为了防止视频没有video_url
try:
get_video(video_url,path=r"E:\app\视频\%s.mp4"%title)
print("成功下载一个")
except BaseException:
print("下载失败")
pass
完整代码
import requests
import random
import time
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"
}
def get_json(url,ajax):
# 构建请求信息
params = {
'page_size':10,
'next_offset': ajax,
'tag':'今日热门',
'platform':'pc'
}
# 防止请求失败
try:
html = requests.get(url,params=params,headers=headers).json()
return html
except BaseException:
print('页面加载失败')
def get_video(viedeo_url,path):
# 取出来视频的名称和地址
r2 = requests.get(viedeo_url,headers=headers)
with open(path,'wb')as f:
f.write(r2.content)
if __name__ == '__main__':
for i in range(3):
url='http://api.vc.bilibili.com/board/v1/ranking/top?'
num=i*10+1
html=get_json(url,num)
infos=html['data']['items']
for info in infos:
title = info['item']['description']#小视频的标题
video_url = info['item']['video_playurl']#视频地址
print(title,video_url)
#为了防止视频没有video_url
try:
get_video(video_url,path=r"E:\app\视频\%s.mp4"%title)
print("成功下载一个")
except BaseException:
print("下载失败")
pass
# 设置加载时间
time.sleep(random.random() * 3)
写的时间有点紧急,大概的写了下过程,如果不懂的地方可以下方留言,看到后第一时间会进行回复,感觉写的对您有帮助,点个关注~~~~
爬虫---爬取b站小视频的更多相关文章
- Python爬虫一爬取B站小视频源码
如果要爬取多页的话 在最下方循环中 填写好循环的次数就可以了 项目源码 from fake_useragent import UserAgent import requests import time ...
- 抓取B站小视频
抓取B站小视频的代码如下: #请求库import requests #请求头部信息(用户代理)headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; ...
- Python爬虫---爬取抖音短视频
目录 前言 抖音爬虫制作 选定网页 分析网页 提取id构造网址 拼接数据包链接 获取视频地址 下载视频 全部代码 实现结果 待解决的问题 前言 最近一直想要写一个抖音爬虫来批量下载抖音的短视频,但是经 ...
- 爬取b站互动视频信息
首先分辨视频是不是互动视频可以看 https://api.bilibili.com/x/player.so?id=cid:1&aid=89017 这个api返回的xml中的 <inter ...
- 简单的方法爬取b站dnf视频封面步骤解释
这随笔代码链接:http://www.cnblogs.com/yinghualuowu/p/8186375.html 首先我们要知道,一个分区封面显示到底在哪里可以找到. 很明显,查看审查元素并不能找 ...
- python爬虫——爬取B站用户在线人数
国庆期间想要统计一下bilibili网站的在线人数变化,写了一个简单的爬虫程序.主要是对https://api.bilibili.com/x/web-interface/online返回的参数进行分析 ...
- python爬取b站排行榜视频信息
和上一篇相比,差别不是很大 import xlrd#读取excel import xlwt#写入excel import requests import linecache import wordcl ...
- python3爬虫-爬取B站排行榜信息
import requests, re, time, os category_dic = { "all": "全站榜", "origin": ...
- Python 简单的方法爬取b站dnf视频封面
import urllib.request cnt=0 def instr(keystr): st=keystr.find('(')+1 strhtml=keystr[st:len(keystr)-1 ...
随机推荐
- 如何在在手机上安装linux(ubuntu )关键词:Termux
目录 Termux软件 @(如何在在手机上安装ubuntu 关键词:Termux) Termux软件 Termux是一款开源且不需要root,运行在Android终端上极其强大的linux模拟器. 首 ...
- 网络编程~~~osi五层协议
物理层 / 数据链路层 / 网络层 / 传输层 / 应用层(表示层/会话层) 一 物理层 物理层指的就是网线,光纤, 双绞线等物理传输介质 物理层发送的是数据(比特流) 二 数据链路层 数据链路层对数 ...
- 如何快速查看 group 对应的id
最近需要获取group 对应的id 数字号码,突然想不起来怎么获得了,现在在这里进行备忘一下: $ cut -d: -f3 < <(getent group sudo) getent gr ...
- 005 C/C++ 数据类型_void
1.void的字面意思是'无类型'.void * 是无类型指针,void * 可以指向任何类型的数据. 2.数据类型的分装: int InitHardEnv(void ** handle); 典型的内 ...
- 【使用篇二】SpringBoot整合aop(13)
AOP为Aspect Oriented Programming的缩写,意为:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术.AOP是Spring框架中的一个重要内容,它通 ...
- Python解释器和Python集成环境小结
目录 一.执行Python程序的两种方式 1.1 交互式 1.2 命令行式 二.执行Python程序的两种IDE 2.1 Pycharm 2.2 Jupyter 一.执行Python程序的两种方式 1 ...
- php date获取当前时间
结果: 结论: 本以为第一种方式最快,第三种方式竟超乎想象的快且稳定
- Linux中Swap与Memory内存简单介绍
1.背景介绍 这篇文章介绍一下Linux中swap与memory.对于memory没什么可说的就是机器的物理内存,读写速度低于cpu一个量级,但是高于磁盘不止一个量级.所以,程序和数据如果在内存的 ...
- Zabbix 数据清理
目录 Zabbix 数据清理的一系列操作 一.问题 二.解决办法 Zabbix 数据清理的一系列操作 基本信息: Zabbix 版本 4.0.9 MySQL 版本 5.5 一.问题 我们将 Zabbi ...
- OpenGL光照2:材质和光照贴图
本文是个人学习记录,学习建议看教程 https://learnopengl-cn.github.io/ 非常感谢原作者JoeyDeVries和多为中文翻译者提供的优质教程 的内容为插入注释,可以先跳过 ...