Python自学day-3
一、集合
set_1 = {1,2,3,4,5}
set1 = set([1,2,3,4,5,6])
set2 = set([4,5,6,7,8])
print(set1.intersection(set2))
set求并集(union):求两个集合元素的并集,重复的会去重。
set1 = set([1,2,3,4,5,6])
set2 = set([4,5,6,7,8])
print(set1.union(set2))
set求差集:
print(set1.difference(set2)) #set1里有,set2里没有的
print(set2.difference(set1)) #set2里有,set1里没有的
判断某个set是否为子集:
print(set2.issubset(set1)) #判断set2是否为set1的子集
判断某个set是否为超集:
print(set1.issuperset(set2)) #判断set1是否为set2的超集
对称差集:即两个集合的并集与交集之间的差集,就是取互相都没有的元素。
list_1 = set([1,2,3,4,5,6])
list_2 = set([4,5,6,7,8,9])
print(list_1.symmetric_difference(list_2)) #输出{1,2,3,7,8,9}
list_1 = set([1,2,3,4,5,6])
list_2 = set([7,8,9])
list_3 = set([6,7,8])
print(list_1.isdisjoint(list_2)) #输出True
print(list_1.isdisjoint(list_3)) #输出False
set_1.add(99)
删除元素(remove):
set_1.remove(99) #删除一个不存在的元素会报错。
print(set_1.discard(100)) #删除一个不存在的元素返回None。
判断元素是否存在:
99 in set_1 #不存在:99 not in set_1
删除任意一个元素(pop):
print(set_1.pop())
二、文件操作
- 打开文件,得到文件操作句柄,并赋值给一个变量。
- 通过句柄对文件进行操作。
- 关闭文件。
data = open("ratherbe").read()
print(data)
这种情况下会报错,提示:
data = open("ratherbe",encoding = "utf-8").read()
print(data)
打开文件,句柄赋值:f又称为文件操作句柄,即文件的内存对象。文件句柄包含文件名、文件打开模式、文件编码等。
f = open("ratherbe",encoding = "utf-8",mode = "r")
data = f.read()
print(data)
f = open("ratherbe2","w",encoding = "utf-8")
f.write("hello")
f = open("ratherbe2","a",encoding = "utf-8")
f.write("World")
读取一行:
for i in range(5): #读取5行
line = f.readline().strip()
print(line)
按行读取全部(readlines):注意文件大小,例如2G,20G的文件,不要全部读到内存中。
f.readlines() #返回一个列表,每一行是一个元素。
一行一行读(高效):内存中只保存一行,可以处理大文件,效率最高。自己使用一个count变量计数。
for line in f:
print(line.strip())
print(f.tell()) #返回当前读取光标的位置,初次打开文件,返回0
f.seek(0) #将光标重置到文件开头,然后再次读取文件内容是否可移动光标(seekable):例如tty或其他设备是不能移动光标的。
print(f.seekable())
print(f.read(11))
文件句柄在内存中的编号(fileno):
print(f.fileno())
打印文件名、编码、是否关闭等信息:
print(f.name)
print(f.closed)
print(f.encoding)
将缓存区的数据刷到磁盘中(flush):
f = open("ratherbe1","a+",encoding="utf-8")
f.write("Hello\n")
f.flush()
Linux包下载时的进度条实现:
import sys
import time
for i in range(100):
sys.stdout.write("#")
sys.stdout.flush()
time.sleep(0.2)
截断文件内容(truncate):例如参数为10,则会在文件中保留10个字符,后面的全部被删除。与光标位置无关。
f = open("ratherbe","a+",encoding="utf-8")
print(f.truncate(10))
f = open("ratherbe","r+",encoding="utf-8")
写读模式(w+):可读可写,但是用这种模式会覆盖原有文件,该模式没什么用。
f = open("ratherbe","rb")
print(f.readline()) #输出 b"We're a thousand miles from comfort,\r\n",b代表二进制
二进制写(wb):写的时候需要把字符转换成二进制。
f = open("ratherbe","wb")
f.write("hello world".encode())
二进制追加写(ab):
f = open("ratherbe","ab")
f.write("hello world".encode())
- 类似Linux中的vim。是将文件全部读到内存中,再在内存中修改。最后再全部写回文件。
- 一行一行读,然后匹配到要修改的部分,修改完毕后写到另外一个文件中,无需修改的部分直接写入新文件。例如:
f = open("ratherbe","r+",encoding="utf-8")
f_new = open("ratherbe.bk","w",encoding="utf-8")
for line in f:
if "继续前行" in line:
line = line.replace("继续前行","赶紧后退")
f_new.write(line)
f.close()
f_new.close()
with open("ratherbe","r+",encoding="utf-8") as f,open("ratherbe.bk","w",encoding="utf-8") as f_new:
for line in f:
if "继续前行" in line:
line = line.replace("继续前行","赶紧后退")
f_new.write(line)
with open("ratherbe","r+",encoding="utf-8") as f, \
open("ratherbe.bk","w",encoding="utf-8") as f_new:
三、字符编码与转码
参考博客:https://blog.csdn.net/qq_38412868/article/details/83278723
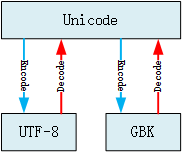

- 首先通过解码(decode)转换为Unicode编码
- 然后通过编码(encode)转换为UTF-8编码
- 反之亦然
s = "你好"
s_to_gbk = s.decode() #s的编码集默认是Unicode。所以没有decode方法。运行报错。
正确:
s = "你好"
s_to_gbk = s.encode("gbk")
再将此gbk转换为utf-8:
s = "你好"
s_to_gbk = s.encode("gbk")
s_to_gbk.decode("gbk").encode("utf-8") #先使用decode把gbk转换为Unicode,再使用encode转换为utf-8。
encode("gbk") #参数为目标编码集
解码(decode):将utf-8、GBK等编码解码为Unicode。
decode("gbk") #参数为待转换字符串的当前编码集(若不填写,则使用默认系统编码集)
import sys
print(sys.getdefaultencoding()) #python2.x默认是ascii。python3.x默认Unicode,所以默认支持中文,并且变量名也支持中文。
四、函数
- 面向对象:类,class
- 面向过程:过程,def
- 函数式编程:函数,def
def function_name( x ):
"Testing Function"
print("This is the first Function.")
y = x**2
return y
def function_1(): #这是一个函数(有返回值)
print("This is a Function")
return 0
def function_2(): #这是一个过程(没有返回值)
print("This is a Procedule") x = function_1()
y = function_2()
print(x) #输出0
print(y) #输出None(Python默认返回一个None)
结论:在Python中,函数和过程没有什么区别,会在过程的最后默认添加return None。
import time
time_format="%y.%m.%d %X"
current_time = time.strftime(time_format)
def test1():
print("Return multi value")
return 1,"hello",{"name":"leo"},["leo",32,"huadumeilinwan"] #返回值是一个元组
高阶函数:
def test2():
return test1 #test1是一个函数名,返回<function test1 at 0x00AD55D0>,函数在内存中的地址
指定参数名:关键参数是不能写在位置参数前面的
def test3(x,y):
print(x,y)
test3(y=5,x="hello") #指定参数名,可以调换参数的位置
def test3(x,y):
print(x,y)
test3(5,y="hello") #正确,先按位置参数,再按关键字。
def test3(x,y):
print(x,y)
test3(x=5,"hello") #报错
默认参数:
def test4(name = "Leo"): #默认参数name="Leo"
print(name)
test4("Kale") #若不传参,则打印"Leo"。
参数组:如何传递数目不固定的参数。
def test5(x,y=2):
print(x)
print(y)
test5(1) #在有默认参数的时候,可以少传,系统会默认传递y
test5(1,2,3) #不能有多余参数,报错
def test6(*args): #传递多个参数(位置参数)
print(args)
print(type(args)) #argv为参数组成的元组
test6(1,2,3,4,5)
其中 * 代表形参args接受的参数数量是不固定的。形参名args最好不要改变,这是约定俗成的规范。
def test7(**kwargs): #传递多个关键字参数,并组织成字典
print(kwargs)
print(kwargs["name"])
test7(name="Leo",age=22,sex="male") #{'name': 'Leo', 'age': 22, 'sex': 'Male'}
test7(**{"name":"Leo","age":22,"sex":"Male"}) #与上面一样
args和kwargs同时存在:
def test8(name,*args,**kwargs):
print(name)
print(args) #打印一个空的元组,()
print(kwargs) #打印字典,{'sex': 'Male', 'age': 32}
test8("Leo",sex = "Male",age=32) #由于后面都是关键字参数,所以都又kwargs接收。
def test10():
logger() test10() #报错,name 'logger' is not defined def logger():
print("logger")
name = "Leo" #全局变量name
def show_name():
name = "Kale" #局部变量name
print(name) #默认打印局部变量,输出Kale
show_name()
print(name) #默认打印全局变量,输出Leo
在函数内部声明全局变量: 坚决不建议使用global这种方式。
name = "Leo"
def show_name():
global name #在函数内部把name声明为全局变量
name = "Kale"
print(name) #输出Kale
show_name()
print(name) #输出Kale
names = ["zhengzhu","lei","li"]
def test11():
names[1] = "Leo"
print(names)
test11()
print(names)
五、递归函数
- 递归必须有一个明确的结束条件。
- 每次进入更深一层的递归时,问题规模相比上次都应该有所减少。
- 递归效率不高,递归层次过多会导致栈溢出。
def digui(x):
y = x/2
y = int(y)
if y > 0: #结束条件y=0
print(y)
return digui(y)
digui(99)
六、函数式编程
def functional(x): #函数式编程,x与y的值一一对应
y = 2x
return y
def function(x): #我们写的函数,可以根据x导致不同的返回值
if x > 0:
y = 100/x
else:
y = 100*x
return y
def add(x,y):
return x+y
def multi(x,y):
return x*y
def sub(x,y):
return x-y res = sub(multi(add(1,2),3),4)
print(res)
七、高阶函数
def func(x,y):
return x*y def function(a,b,func_name): #将一个函数名作为变量
return func(a+b,a-b) print(function(3,5,func)) #将func函数传入function函数
Python自学day-3的更多相关文章
- python自学笔记
python自学笔记 python自学笔记 1.输出 2.输入 3.零碎 4.数据结构 4.1 list 类比于java中的数组 4.2 tuple 元祖 5.条件判断和循环 5.1 条件判断 5.2 ...
- Python - 自学django,上线一套资产管理系统
一.概述 终于把公司的资产管理网站写完,并通过测试,然后上线.期间包括看视频学习.自己写前后端代码,用时两个多月.现将一些体会记录下来,希望能帮到想学django做web开发的人.大牛可以不用看了,小 ...
- 拎壶冲冲冲专业砸各种培训机构饭碗篇----python自学(一)
本人一直从事运维工程师,热爱运维,所以从自学的角度站我还是以python运维为主. 一.python自学,当然少不了从hello world开始,话不多说,直接上手练习 1.这个可以学会 print( ...
- [Python自学] day-21 (2) (Cookie、FBV|CBV装饰器)
一.什么是Cookie 1.什么是Cookie? Cookie是保存在客户端浏览器中的文件,其中记录了服务器让浏览器记录的一些键值对(类似字典). 当Cookie中存在数据时,浏览器在访问网站时会读取 ...
- [Python自学] day-21 (1) (请求信息、html模板继承与导入、自定义模板函数、自定义分页)
一.路由映射的参数 1.映射的一般使用 在app/urls.py中,我们定义URL与视图函数之间的映射: from django.contrib import admin from django.ur ...
- [Python自学] day-20 (Django-ORM、Ajax)
一.外键跨表操作(一对多) 在 [Python自学] day-19 (2) (Django-ORM) 中,我们利用外键实现了一对多的表操作. 可以利用以下方式来获取外键指向表的数据: def orm_ ...
- [Python自学] day-19 (2) (Django-ORM)
一.ORM的分类 ORM一般分为两类: 1.DB first:先在DB中创建数据库.表结构,然后自动生成代码中的类.在后续操作中直接在代码中操作相应的类即可. 2.Code first:直接在代码中实 ...
- [Python自学] day-19 (1) (FBV和CBV、路由系统)
一.获取表单提交的数据 在 [Python自学] day-18 (2) (MTV架构.Django框架)中,我们使用过以下方式来获取表单数据: user = request.POST.get('use ...
- [Python自学] day-18 (2) (MTV架构、Django框架、模板语言)
一.实现一个简单的Web服务器 使用Python标准库提供的独立WSGI服务器来实现MVC架构. 首先,实现一个简单的Web服务器: from wsgiref.simple_server import ...
- Python自学之路---Day13
目录 Python自学之路---Day13 常用的三个方法 匹配单个字符 边界匹配 数量匹配 逻辑与分组 编译正则表达式 其他方法 Python自学之路---Day13 常用的三个方法 1.re.ma ...
随机推荐
- Android于popWindow写弹出菜单
1.什么是popWindow? popWindow这是对话的方式!文字解说android的方式来使用对话框,这就是所谓的popWindow. 2.popWindow特征 Android的对话框有两种: ...
- win10 uwp 使用 asp dotnet core 做图床服务器客户端
原文 win10 uwp 使用 asp dotnet core 做图床服务器客户端 本文告诉大家如何在 UWP 做客户端和 asp dotnet core 做服务器端来做一个图床工具 服务器端 从 ...
- Entity Framework加载数据的三种方式。
MSDN文章Loading Related Entities 有 Eagerly Loading Lazy Loading Explicitly Loading 三种方式. 而看到查询中包含Inclu ...
- matlab 读写其他格式数据文件(excel)
1. excel matlab和excel 中的数据互相导入 xlswrite() mat ⇒ excel 请问怎么把大容量的mat文件导出到excel文件中 – MATLAB中文论坛 % data. ...
- 李开复:VC看不上你的五个原因
[编者按]:此文是李开复先生发表于其LinkedIn主页上的一篇文章,简单列举了五条与VC接触常忽略的经验.如果你是一位正准备和VC谈判取得资金上帮助的创业者,那么应该避免企业家常常犯下的五条错误. ...
- 机器学习:DeepDreaming with TensorFlow (三)
我们看到,利用TensorFlow 和训练好的Googlenet 可以生成多尺度的pattern,那些pattern看起来比起单一通道的pattern你要更好,但是有一个问题就是多尺度的pattern ...
- Oltu在Jersey框架上实现oauth2.0授权模块
oltu是一个开源的oauth2.0协议的实现,本人在此开源项目的基础上进行修改,实现一个自定义的oauth2.0模块. 关于oltu的使用大家可以看这里:http://oltu.apache.org ...
- Matlab随笔之线性规划
原文:Matlab随笔之线性规划 LP(Linear programming,线性规划)是一种优化方法,在优化问题中目标函数和约束函数均为向量变量的线性函数,LP问题可描述为:min xs.t. ...
- Spring MVC 专题
Spring静态资源路径是指系统可以直接访问的路径,且路径下的所有文件均可被用户直接读取.在Springboot中默认的静态资源路径有:classpath:/META-INF/resources/,c ...
- 1 min 数据查询 SQL 优化
问题 前几天线上数据库 IOPS 飙升,一直居高不下,最近并没有升级.遂查看数据库正在执行的 SQL 语句,发现有个查询离线设备的语句极其缓慢. 探寻原因 SELECT o.* FROM ( SELE ...