第十一周java课堂测试
Main.java
package class_third_copy; import java.util.Scanner; import classthird.Test;
import classthird.TestMain;
import classthird.TestTwo; public class Main {
public static void main(String[] args) {
Main tm=new Main(); tm.choice(); }
public void choice() {
int choice;
int number1;
Test1 t1=new Test1();
Test2 t2=new Test2();
Test3 t3=new Test3();
Test5 t5=new Test5();
Scanner input=new Scanner(System.in);
while(true) {
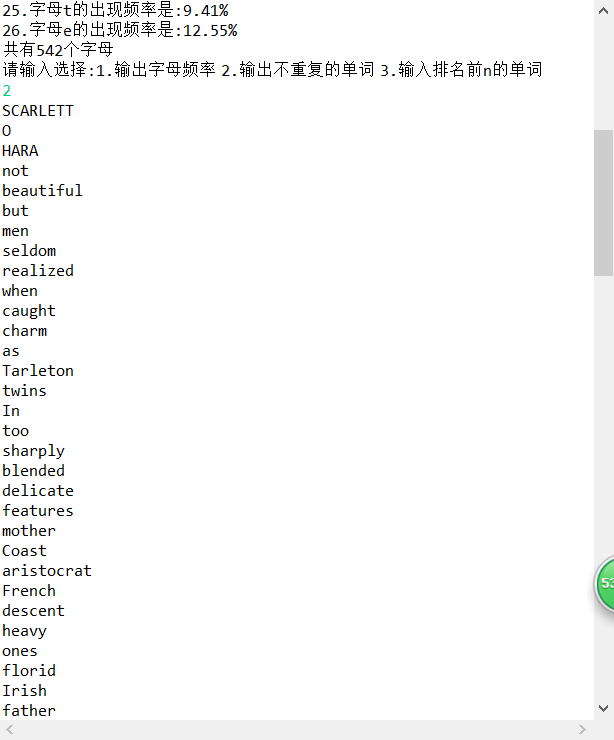
System.out.println("请输入选择:1.输出字母频率 2.输出不重复的单词 3.输入排名前n的单词");
choice=input.nextInt();
switch(choice) {
case 1:
t1.test("D:\\Test\\a.txt");
t1.display();
break;
case 2:
//te.test();
t2.test3("D:\\Test\\a.txt");
break;
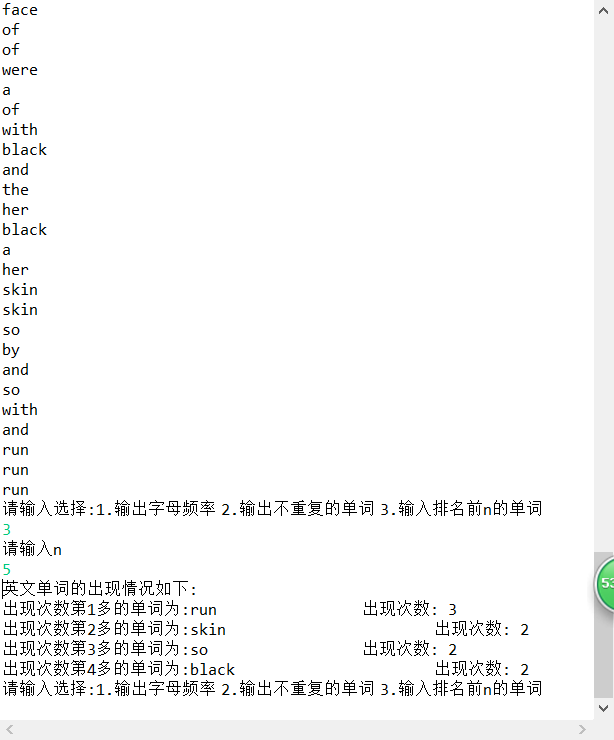
case 3:
System.out.println("请输入n");
number1=input.nextInt();
Test3 tt3=new Test3();
tt3.testthird("D:\\Test\\a.txt", number1-1);
break;
case 4:
t5.test5("D:\\Test\\a.txt");
}
} }
}
Test1.java
package class_third_copy; import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.text.DecimalFormat; public class Test1 { int j=0;
int ci=0;
double sum=0;
double a1;
static char zimu[] = new char[26];//存储字母‘a-z’
static char shu[] = new char[2000];//存储单个字母内容
double count[]=new double[26];
public static void main(String[] args) {
Test1 t1=new Test1();
t1.test("D:\\Test\\a.txt");
t1.display();
} public void test(String pathname) {
Test1 t1=new Test1();
try { File filename=new File(pathname);
InputStreamReader reader=new InputStreamReader(new FileInputStream(filename));
BufferedReader br=new BufferedReader(reader);
String line[]=new String[100];;
for(int i=0;i<line.length;i++)
{
line[i]=br.readLine();
}
br.close();
int k=0;
while(line[k]!=null)
{
for(int i=0;i<line[k].length();i++)
{
shu[j]=line[k].charAt(i);
j++;
}
k++;
} /*初始化字母数组*/
t1.reLetter(); /*依次判断字母并计数*/
for(int i=0;i<shu.length;i++)
{
switch(shu[i]) {
case 'a'|'A':count[0]++;break;
case 'b'|'B':count[1]++;break;
case 'c'|'C':count[2]++;break;
case 'd'|'D':count[3]++;break;
case 'e'|'E':count[4]++;break;
case 'f'|'F':count[5]++;break;
case 'g'|'G':count[6]++;break;
case 'h'|'H':count[7]++;break;
case 'i'|'I':count[8]++;break;
case 'j'|'J':count[9]++;break;
case 'k'|'K':count[10]++;break;
case 'l'|'L':count[11]++;break;
case 'm'|'M':count[12]++;break;
case 'n'|'N':count[13]++;break;
case 'o'|'O':count[14]++;break;
case 'p'|'P':count[15]++;break;
case 'q'|'Q':count[16]++;break;
case 'r'|'R':count[17]++;break;
case 's'|'S':count[18]++;break;
case 't'|'T':count[19]++;break;
case 'u'|'U':count[20]++;break;
case 'v'|'V':count[21]++;break;
case 'w'|'W':count[22]++;break;
case 'x'|'X':count[23]++;break;
case 'y'|'Y':count[24]++;break;
case 'z'|'Z':count[25]++;break;
}
} }catch (Exception e)
{
e.printStackTrace();
}
} public void display() {
DecimalFormat df = new DecimalFormat("0.00");
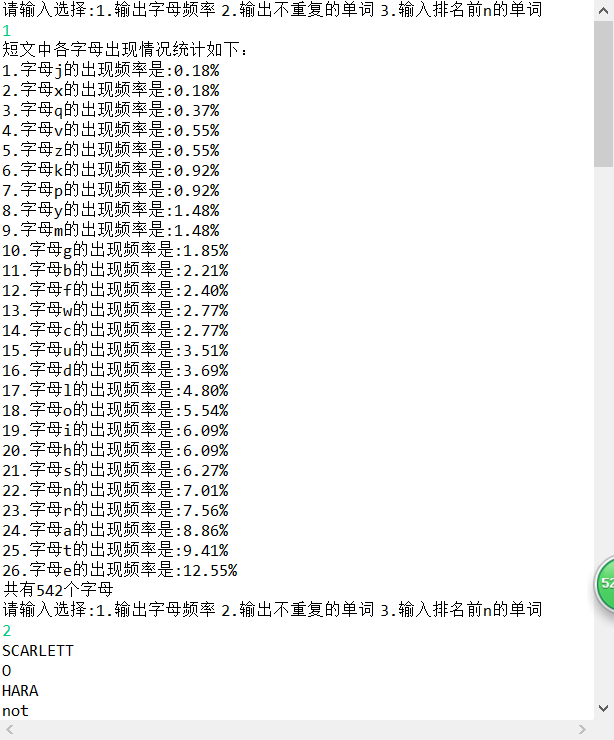
System.out.println("短文中各字母出现情况统计如下:");
/*求字母总数*/
for(int i=0;i<26;i++)
{
sum+=count[i];
} /*比较出现频率大小排序、冒泡法、相同频率按字母先后顺序排序*/
for(int x=0;x<26-1;x++)
{
for (int y=x+1;y<26;y++)
{
if (count[x]>count[y])
{
double temp=count[x];
count[x]=count[y];
count[y]=temp;
char temp1=zimu[x];
zimu[x]=zimu[y];
zimu[y]=temp1;
}
}
} /*循环显示字母出现频率*/
for(int i=0;i<=25;i++)
{
ci++;
a1=count[i]/sum*100;
System.out.println(ci+".字母"+zimu[i]+"的出现频率是:"+df.format(a1)+"%");
} /*显示字母总数*/
System.out.println("共有"+(int)sum+"个字母"); } /*初始化字母数组*/
public void reLetter()
{
for(int i=0;i<26;i++)
{
zimu[0]='a';
zimu[1]='b';
zimu[2]='c';
zimu[3]='d';
zimu[4]='e';
zimu[5]='f';
zimu[6]='g';
zimu[7]='h';
zimu[8]='i';
zimu[9]='j';
zimu[10]='k';
zimu[11]='l';
zimu[12]='m';
zimu[13]='n';
zimu[14]='o';
zimu[15]='p';
zimu[16]='q';
zimu[17]='r';
zimu[18]='s';
zimu[19]='t';
zimu[20]='u';
zimu[21]='v';
zimu[22]='w';
zimu[23]='x';
zimu[24]='y';
zimu[25]='z';
}
} }
Test2.java
package class_third_copy;
import class_third_copy.Test1; public class Test2 extends Test1{ static String wd="";
static String le[]=new String[1000];
static String wd2[]=new String[1000];
static String wd3[]=new String[1000];
public static void main(String[] args) {
Test2 t2=new Test2();
//t1.test("D:\\Test\\a.txt");
//t1.display();
//t2.test2();
t2.test2("D:\\Test\\b.txt");
} /*提取出单词*/
public void test2(String path) {
Test1 t1=new Test1();
int count1=0; try {
t1.test(path);
for(int i=0;i<Test1.shu.length;i++)
{ if((Test1.shu[i]>='a'&&Test1.shu[i]<='z')||(Test1.shu[i]>='A'&&Test1.shu[i]<='Z'))
{
wd+=Test1.shu[i];
continue;
}else {
wd2[count1]=wd;
wd="";
//System.out.println(count1);
if(wd2[count1]!=""||wd2[count1]==null) {
//System.out.println(wd2[count1]);
count1++;
}
}
}
for(int i=0;i<count1;i++) { }
}catch(Exception e) {
e.printStackTrace();
}
} /*去掉重复的单词*/
public void test3(String path) {
Test1 t1=new Test1();
int count1=0; try {
t1.test(path);
for(int i=0;i<Test1.shu.length;i++)
{ if((Test1.shu[i]>='a'&&Test1.shu[i]<='z')||(Test1.shu[i]>='A'&&Test1.shu[i]<='Z'))
{
wd+=Test1.shu[i];
continue;
}else {
wd2[count1]=wd;
wd="";
//System.out.println(count1);
if(wd2[count1]!=""||wd2[count1]==null) {
//System.out.println(wd2[count1]);
count1++;
}
}
}
//System.out.println(count1);
int count2=0;
for(int i=0;i<count1;i++) {
for(int j=0;j<count1;j++) {
if(j!=i) {
if(wd2[i].equals(wd2[j])==true) {
break;
}
}
if(j==count1-1)
{
wd3[count2]=wd2[i];
/*System.out.println(wd2[i]);
System.out.println(wd3[count2]);*/
count2++;
}
}
}
for(int i=0;i<count1;i++) {
for(int j=0;j<count1;j++) {
if(j!=i) {
if(wd2[i].equals(wd2[j])==true) {
wd3[count2]=wd2[i];
count2++;
break;
}
}
}
} for(int i=0;i<count2;i++) {
System.out.println(wd3[i]);
}
}catch(Exception e) {
e.printStackTrace();
}
}
}
Test3.java
package class_third_copy; import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.HashMap;
import java.util.Map; import classone.Test;
import classthird.TestTwo; public class Test3 {
public static void main(String[] args) {
Test3 tt3=new Test3();
tt3.testthird("D:\\Test\\a.txt", 5);
}
static String sw[]=new String[100];
public Map<String,Integer> map1=new HashMap<String,Integer>();
public void daoru(String path) throws IOException
{ File a=new File(path);
FileInputStream b = new FileInputStream(a);
InputStreamReader c=new InputStreamReader(b,"UTF-8");
String string2=new String();
while(c.ready())
{
char string1=(char) c.read();
if(!isWord(string1))
{
if(map1.containsKey(string2))
{
Integer num1=map1.get(string2)+1;
map1.put(string2,num1);
}
else
{
Integer num1=1;
map1.put(string2,num1);
}
string2="";
}
else
{
string2+=string1;
}
}
if(!string2.isEmpty())
{
if(map1.containsKey(string2))
{
Integer num1=map1.get(string2)+1;
map1.put(string2,num1);
}
else
{
Integer num1=1;
map1.put(string2,num1);
}
string2="";
}
c.close();
b.close();
}
public void testthird(String path,int number) {
String sz[];
Integer num[];
int MAXNUM=number; //统计的单词出现最多的前n个的个数
sz=new String[MAXNUM+1];
num=new Integer[MAXNUM+1];
TestTwo tt=new TestTwo();
int account =1;
//Vector<String> ve1=new Vector<String>();
try {
tt.daoru(path);
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
System.out.println("英文单词的出现情况如下:");
int g_run=0;
//System.out.println("ssssssssss");
Test3 t3=new Test3();
t3.stopWrod();
for(int i=0;i<=20;i++) {
//System.out.println(sw[i]);
}
for(g_run=0;g_run<MAXNUM+1;g_run++)
{
account=1;
for(Map.Entry<String,Integer> it : tt.map1.entrySet())
{ int thought_2=0;
for(int i=0;i<=20;i++) {
//System.out.println(sw[i]);
if(it.getKey().equals(sw[i]))
{
thought_2=1;
}
}
if(thought_2==1) {
continue;
}
if(account==1)
{
sz[g_run]=it.getKey();
num[g_run]=it.getValue();
account=2;
}
if(account==0)
{
account=1;
continue;
}
if(num[g_run]<it.getValue())
{
sz[g_run]=it.getKey();
num[g_run]=it.getValue();
}
//System.out.println("英文单词: "+it.getKey()+" 该英文单词出现次数: "+it.getValue());
}
tt.map1.remove(sz[g_run]);
}
int g_count=1;
String tx1=new String();
for(int i=0;i<g_run;i++)
{
if(sz[i]==null)
continue;
if(sz[i].equals(""))
continue;
tx1+="出现次数第"+(g_count)+"多的单词为:"+sz[i]+"\t\t\t出现次数: "+num[i]+"\r\n";
System.out.println("出现次数第"+(g_count)+"多的单词为:"+sz[i]+"\t\t\t出现次数: "+num[i]);
g_count++;
}
try {
tt.daochu(tx1);
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
public void daochu(String txt) throws IOException
{
File fi=new File("tongji.txt");
FileOutputStream fop=new FileOutputStream(fi);
OutputStreamWriter ops=new OutputStreamWriter(fop,"UTF-8");
ops.append(txt);
ops.close();
fop.close();
} public boolean isWord(char a)
{
if(a<='z'&&a>='a'||a<='Z'&&a>='A')
return true;
return false;
}
public void stopWrod() {
Test2 t2=new Test2(); t2.test2("D:\\Test\\b.txt");
for(int i=0;i<100;i++) {
if(Test2.wd2[i]!=null) {
sw[i]=Test2.wd2[i];
//System.out.println(sw[i]);
} }
}
}
Test4.java
package class_third_copy; import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.text.DecimalFormat; public class Test4 { static String word5[]=new String[1000]; //存储单词
public static void test(String pathname) {
try {
char shu[] = new char[1000];//存储单个字母内容
char zimu[] = new char[26];//存储字母‘a-z’
String h1[]=new String[1000]; //存储原文内容
String word3[]=new String[1000]; //存储单词
String word4[]=new String[1000]; //存储单词 String countword[]=new String[1000];
int countwordtwo=0;
int countwordthree=0;
double count[]=new double[26];
int j=0; File filename=new File(pathname);
InputStreamReader reader=new InputStreamReader(new FileInputStream(filename));
BufferedReader br=new BufferedReader(reader);
String line[]=new String[100];;
for(int i=0;i<line.length;i++)
{
line[i]=br.readLine();
}
br.close();
int k=0;
while(line[k]!=null)
{
for(int i=0;i<line[k].length();i++)
{
shu[j]=line[k].charAt(i);
j++;
}
k++;
}
for(int i=0;i<shu.length;i++)
{
switch(shu[i]) {
case 'a':zimu[0]='a';count[0]++;break;
case 'b':zimu[1]='b';count[1]++;break;
case 'c':zimu[2]='c';count[2]++;break;
case 'd':zimu[3]='d';count[3]++;break;
case 'e':zimu[4]='e';count[4]++;break;
case 'f':zimu[5]='f';count[5]++;break;
case 'g':zimu[6]='g';count[6]++;break;
case 'h':zimu[7]='h';count[7]++;break;
case 'i':zimu[8]='i';count[8]++;break;
case 'j':zimu[9]='j';count[9]++;break;
case 'k':zimu[10]='k';count[10]++;break;
case 'l':zimu[11]='l';count[11]++;break;
case 'm':zimu[12]='m';count[12]++;break;
case 'n':zimu[13]='n';count[13]++;break;
case 'o':zimu[14]='o';count[14]++;break;
case 'p':zimu[15]='p';count[15]++;break;
case 'q':zimu[16]='q';count[16]++;break;
case 'r':zimu[17]='r';count[17]++;break;
case 's':zimu[18]='s';count[18]++;break;
case 't':zimu[19]='t';count[19]++;break;
case 'u':zimu[20]='u';count[20]++;break;
case 'v':zimu[21]='v';count[21]++;break;
case 'w':zimu[22]='w';count[22]++;break;
case 'x':zimu[23]='x';count[23]++;break;
case 'y':zimu[24]='y';count[24]++;break;
case 'z':zimu[25]='z';count[25]++;break;
case 'A':zimu[0]='a';count[0]++;break;
case 'B':zimu[1]='b';count[1]++;break;
case 'C':zimu[2]='c';count[2]++;break;
case 'D':zimu[3]='d';count[3]++;break;
case 'E':zimu[4]='e';count[4]++;break;
case 'F':zimu[5]='f';count[5]++;break;
case 'G':zimu[6]='g';count[6]++;break;
case 'H':zimu[7]='h';count[7]++;break;
case 'I':zimu[8]='i';count[8]++;break;
case 'J':zimu[9]='g';count[9]++;break;
case 'K':zimu[10]='k';count[10]++;break;
case 'L':zimu[11]='l';count[11]++;break;
case 'M':zimu[12]='m';count[12]++;break;
case 'N':zimu[13]='n';count[13]++;break;
case 'O':zimu[14]='o';count[14]++;break;
case 'P':zimu[15]='p';count[15]++;break;
case 'Q':zimu[16]='q';count[16]++;break;
case 'R':zimu[17]='r';count[17]++;break;
case 'S':zimu[18]='s';count[18]++;break;
case 'T':zimu[19]='t';count[19]++;break;
case 'U':zimu[20]='u';count[20]++;break;
case 'V':zimu[21]='v';count[24]++;break;
case 'W':zimu[22]='w';count[22]++;break;
case 'X':zimu[23]='x';count[23]++;break;
case 'Y':zimu[24]='y';count[24]++;break;
case 'Z':zimu[25]='z';count[25]++;
}
}
int ci=0;
double sum=0;
double a1;
double max=0;
DecimalFormat df = new DecimalFormat( "0.00");
// System.out.println("短文中各字母出现情况统计如下:");
for(int i=0;i<26;i++) {
if(count[i]!=0) {
sum+=count[i];
}
}///求字母总数
for (int x = 0; x < 26 - 1; x++) {
for (int y = x + 1; y < 26; y++) {
if (count[x] > count[y]) {
double temp = count[x];
count[x] = count[y];
count[y] = temp;
char temp1=zimu[x];
zimu[x] = zimu[y];
zimu[y] = temp1;
}
}
}
// for(int i=0;i<26;i++)
// {
// if(count[i]!=0)
// {
// ci++;
// a1=count[i]/sum*100;
// System.out.println(ci+".字母"+zimu[i]+"的出现频率是:"+df.format(a1)+"%");
// }
// } // System.out.println("字母共计:"+sum+"个");
for(int i=0;i<shu.length;i++)
{
h1[i] = String.valueOf(shu[i]);
}
int msg1=0;
int count1=0; //判断单词个数
String word2 ="";
for(int i=0;i<shu.length;i++)
{ if((shu[i]>='a'&&shu[i]<='z')||(shu[i]>='A'&&shu[i]<='Z'))
{
word2+=h1[i];
}else
{
msg1=1;
}
if(word3[i]==" ")
{ //考虑标点加空格的情况
msg1=0; //msg1初始化
word3[i]="";
continue; //跳出循环
}
if(msg1==1)
{ //如果中间出现非字母
word3[i]=word2; //word2存入数组
word2=""; //word2初始化
msg1=0; //msg1初始化 }
if(word3[i]==null)
{ //判断为空,防止空指针
msg1=0; //msg1初始化
word3[i]="空";
continue; //跳出循环
}
if(word3[i]=="")
{ //判断为空,防止空指针
msg1=0; //msg1初始化
word3[i]="空";
continue; //跳出循环
}
if(word3[i].length()==1)
{ //若长度为一,是单字母不为单词
msg1=0; //msg1初始化
word3[i]="";
continue; //跳出循环
}
//System.out.println(word3[i]);
word4[count1]=word3[i];
count1++;
if(word3[i]==""&&word3[i-1]=="")
{
break;
}
}
int length=0;
for(int i=0;i<word4.length;i++)
{
if(word4[i]!=null) {
System.out.println(word4[i]);
word5[length]=word4[i];
length++;
}else {
break;
}
}
}catch (Exception e)
{
e.printStackTrace();
}
}
public static void main(String[] args) {
Test2 t2=new Test2();
String sw[]=new String[1000];
t2.test3("D:\\Test\\b.txt");
for(int i=0;i<100;i++) {
if(Test2.wd3[i]!=null) {
sw[i]=Test2.wd3[i];
System.out.println(Test2.wd3[i]);
} }
}
}
Test5.java
package class_third_copy;
public class Test5 {
public static void main(String[] args) {
Test5 t5=new Test5();
t5.test5("D:\\Test\\a.txt");
}
Test2 t2=new Test2();
Test3 t3=new Test3();
static String wdc[]=new String[1000];
public void test5(String path) {
t2.test2(path);
t3.stopWrod();
String wdc_1 = null;
int thought_1=0;
int count=1;
for(int i=0;i<t2.wd2.length;i++) {
for(int j=0;j<20;j++) {
if(t2.wd2[i]!=null) {
if(t2.wd2[i].equals(t3.sw[j]))
{
break;
}
if(j==19) {
thought_1=1;
}
}
}
if(thought_1==1)
{
thought_1=0;
wdc_1+=t2.wd2[i];
}else {
wdc[count]=wdc_1;
wdc_1=null;
}
}
for(int i=0;i<wdc.length;i++) {
System.out.println(wdc[i]);
}
}
}
第十一周java课堂测试的更多相关文章
- 20155237 第十一周java课堂程序
20155237 第十一周java课堂程序 内容一:后缀表达式 abcde/-f+ 内容二:实现Linux下dc的功能,计算后缀表达式的值 填充下列代码: import java.util.Scann ...
- 20155201 第十一周Java课堂实践
一.表达式后缀表达式: a b x c d e / - f x + 二.mini dc MyDC.java import java.util.StringTokenizer; import java. ...
- 20155301第十一周java课栈程序
20155301第十一周java课栈程序 内容一:后序表达式: abcde/-f+ 内容二:根据填充以下代码: import java.util.Scanner; public class MyDCT ...
- 第十一周java学习总结
目录 第十一周java学习总结 学习内容 学习总结 提交代码截图 代码推送 第十一周java学习总结 学习内容 第13章 Java网络编程 主要内容 URL类 InetAdress类 套接字 UDP数 ...
- Java课堂测试--实现ATM的基本操作体会
9月20的周四的Java课堂第一节课上就是有关于实现ATM的考试内容,在实现的过程中我了解到自己本身还是有很多的不足之处,例如在实现工程方面的相似性上面还有些许就的欠缺,再者就是回宿舍拿电源的原因导致 ...
- 20175215 2018-2019-2 第十一周java课程学习总结
第13章 Java网络编程 13.1 URL类 URL类是java.net包中的一个重要的类,URL的实例封装着一个统一资源定位符(Uniform Resource Locator),使用URL创建对 ...
- java课堂测试2(两种方式)
实验源代码 这是不使用数组形式的源代码 /* 2017/10/10 王翌淞 课堂测试2 */import java.util.Scanner; public class Number { public ...
- Java课堂测试01及感想
上周进行了Java的开学第一次测验,按要求做一个模拟ATM机功能的程序,实现存取款.转账汇款.修改密码.查询余额的操作.这次测验和假期的试题最大的不同还是把数组存储改成的文件存储,在听到老师说要用文件 ...
- java课堂测试—根据模板完成一个简单的技术需求征集系统
课堂上老师发布了一个页面模板要求让我们实现一个系统的功能,模仿以后后端的简单工作情况. 然后在这个模板的基础上,提供了一个注册的网页模板,接着点击注册的按钮,发现register里面调用了zhu/zh ...
随机推荐
- centos7配置JDK
CentOS7自带jdk1.8 查看当前系统jdk的版本:java -version 列举匹配已安装的java的软件包:yum list installed | grep java 卸载安装的jdk: ...
- Comupter Tools 清单------包含但不限于此
- CentOS -- RocketMQ HA & Monitoring
RocketMQ Architecture NameServer Cluster Name Servers provide lightweight service discovery and rout ...
- Leetcode之回溯法专题-51. N皇后(N-Queens)
Leetcode之回溯法专题-51. N皇后(N-Queens) n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击. 上图为 8 皇后问题的一种解法. 给 ...
- HTML 参考手册(摘自菜鸟教程)
标签 描述 基础 <!DOCTYPE> 定义文档类型. <html> 定义一个 HTML 文档 <title> 为文档定义一个标题 <body> ...
- hdu-6644 11 Dimensions
题目链接 11 Dimensions Problem Description 11 Dimensions is a cute contestant being talented in math. On ...
- 牛客暑假多校第六场 I Team Rocket
题意: 现在有n条火车, 每条火车都有一个运行 [ Li, Ri ], 现在有m支火箭队, 每次火箭队都会破坏这整条铁路上的一个点, 如果一条火车的运行区间[Li, Ri] 被破坏了, 那么这条火车会 ...
- codeforces 735C. Tennis Championship(贪心)
题目链接 http://codeforces.com/contest/735/problem/C 题意:给你一个数n表示有几个人比赛问最多能赢几局,要求两个比赛的人得分不能相差超过1即得分为2的只能和 ...
- dp递推题2010年吉林省省赛 1456: 逃票的chanming(3)
1456: 逃票的chanming(3) 时间限制: 2 Sec 内存限制: 128 MB提交: 326 解决: 48[提交][状态][讨论版] 题目描述 这是一个神奇的国度. 这个国度一 ...
- yzoj 1201数字三角形3题解
题意 如下图所示为一个数字三角形: 7 3 8 8 1 0 2 7 4 4 4 5 2 6 5 请编程计算从顶至底部某处的一条路径,使该路径所经过的数字的总和最大.约定: (1)每一步可沿直线向下或右 ...