Jmeter元件——JSON Extractor后置处理器介绍2
在前段时间将JSON Extractor元件做了个简单的介绍:Jmeter元件——JSON Extractor后置处理器介绍1,今天以一个具体的json,以不同的方式提取数据做个详细的介绍。
一、模拟请求
使用java请求来模拟请求,入参json格式数据,以实例来讲解,具体如下
1.在线程组下添加一个java请求
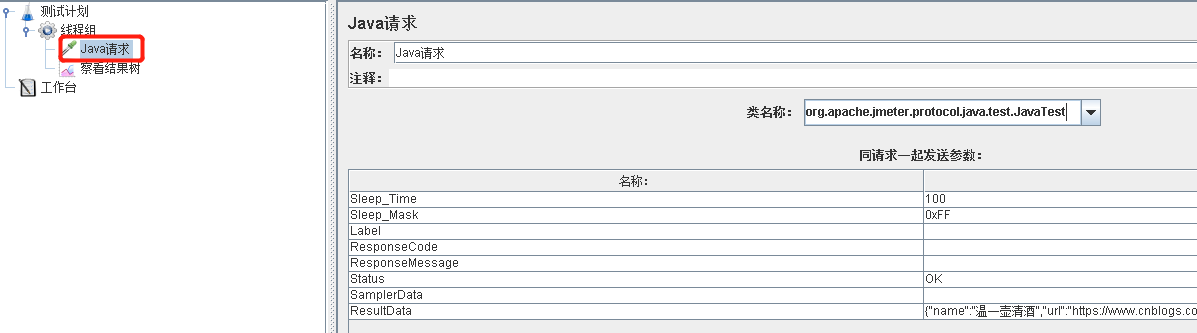
2.类名称选择org.apache.jmeter.protocol.java.test.JavaTest
3.json数据填入ResultData中

4.运行该脚本,在结果树中查看结果
二、数据提取
json示例数据如下:
{"name":"温一壶清酒","url":"https://www.cnblogs.com/hong-fithing/","page":,"isNonProfit":true,"address":{"street":"科技园路","city":"上海","country":"中国"},"data":{"Jenkins系列博客":[{"name":"Jenkins环境搭建(1)-下载与安装","url":"https://www.cnblogs.com/hong-fithing/p/10290315.html","pageview":[,],"keywords":["jenkins"]},{"name":"Jenkins环境搭建(2)-搭建jmeter+ant+jenkins自动化测试环境","url":"https://www.cnblogs.com/hong-fithing/p/10462493.html","pageview":[,],"keywords":["jenkins","ant","jmeter"]},{"name":"Jenkins环境搭建(3)-配置自动发送邮件","url":"https://www.cnblogs.com/hong-fithing/p/10473996.html", "pageview":[,],"page":, "keywords":[ "jenkins", "邮件"]}],"UI自动化系列博客":[{"name":"UI自动化测试(一)简介及Selenium工具的介绍和环境搭建","url":"https://www.cnblogs.com/hong-fithing/p/7622215.html","pageview":,"keywords":[ "selenium","自动化"]},{"name":"UI自动化测试(二)浏览器操作及对元素的定位方法(xpath定位和css定位详解)","url":"https://www.cnblogs.com/hong-fithing/p/7623838.html","pageview":,"keywords":["xpath","css","自动化"]},{"name":"UI自动化测试(三)对页面中定位到的元素对象做相应操作","url":"https://www.cnblogs.com/hong-fithing/p/7625800.html","pageview":,"keywords":["自动化"]}]},"pageview": }
1.基本提取
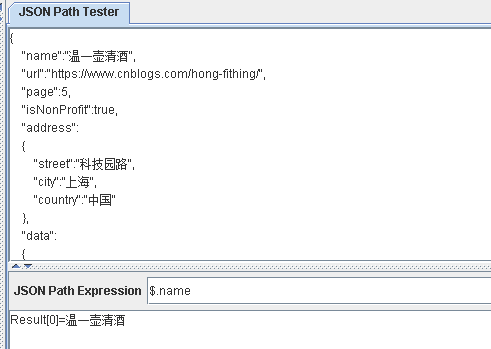
$['name']
$.name
区别:
使用符号.只能获取一个子节点
使用中括号[]可以获取多个子节点的值
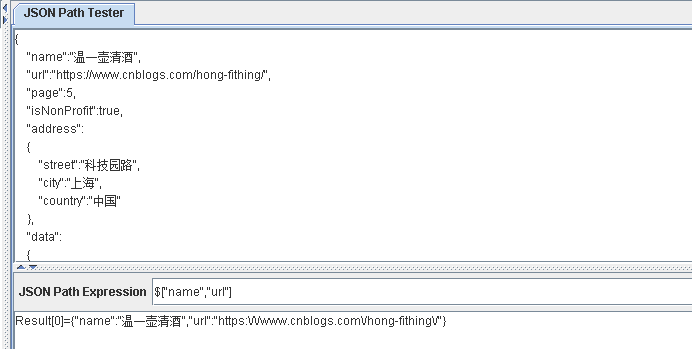
$["name","url"] 获取的是根节点下name节点和url节点,并不是值
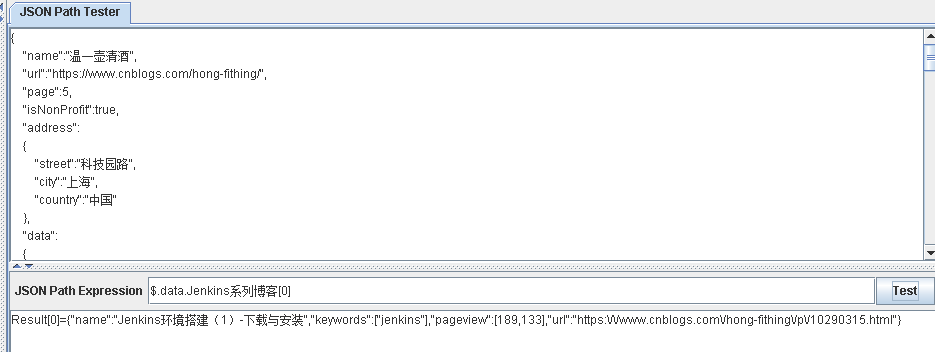
$.data.Jenkins系列博客[*]
$.data.Jenkins系列博客
区别:
使用[*],表示获取data节点下 Jenkins系列博客 数组中元素的值
不使用[*] 表示获取data节点下 Jenkins系列博客 的值


$.data.Jenkins系列博客[] 表示获取 Jenkins系列博客 数组中第一个元素
$.data.Jenkins系列博客[,] 表示获取 Jenkins系列博客 数组中第一个/第三个元素
2.切片处理
切片处理,就类似于取数据的一个范围值,格式为:$.data.Jenkins系列博客[n:m]
说明:
n:表示数组元素的起始下标,如果不填写,则默认为0,表示从第一个开始
m:表示数组原因的结束下标,如果不填写,则默认为数组的最后一个
ps:是一个半闭半开区间,即包含起始下标,不包含结束下标
$.data.Jenkins系列博客[:] 提取数组中的所有元素
$.data.Jenkins系列博客[:] 提取第一个开始到最后的元素
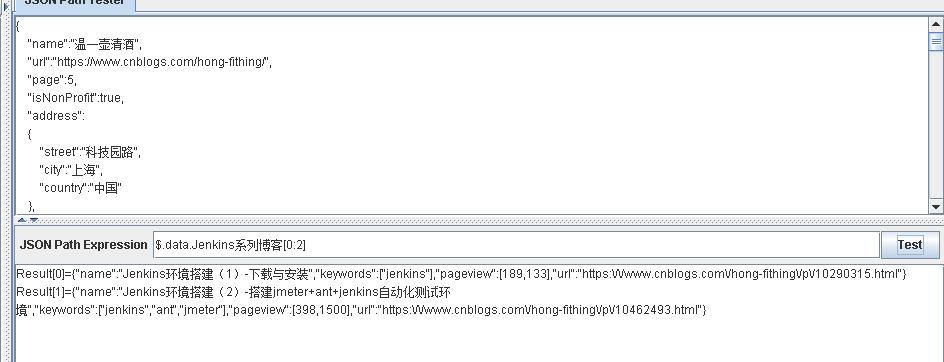
$.data.Jenkins系列博客[-n:] 提取倒数n个元素
$.data.Jenkins系列博客[:-m] 提取不包含最后m个元素的其他元素
输入负值说明,如下:
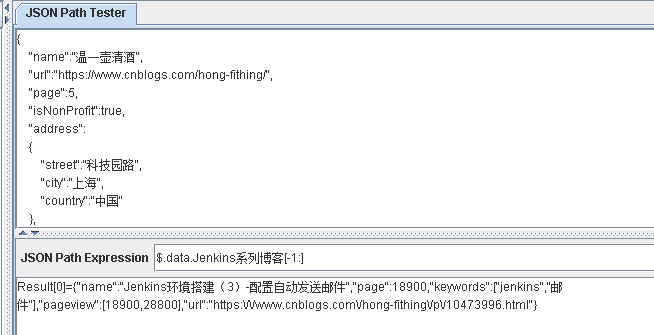
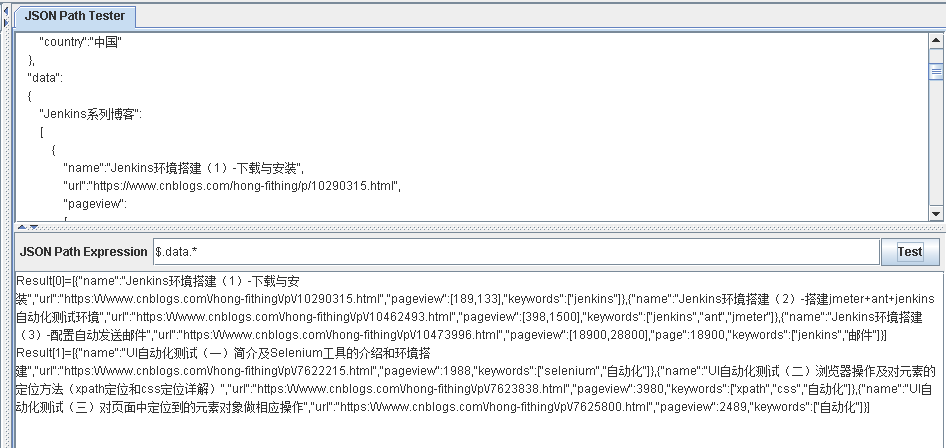
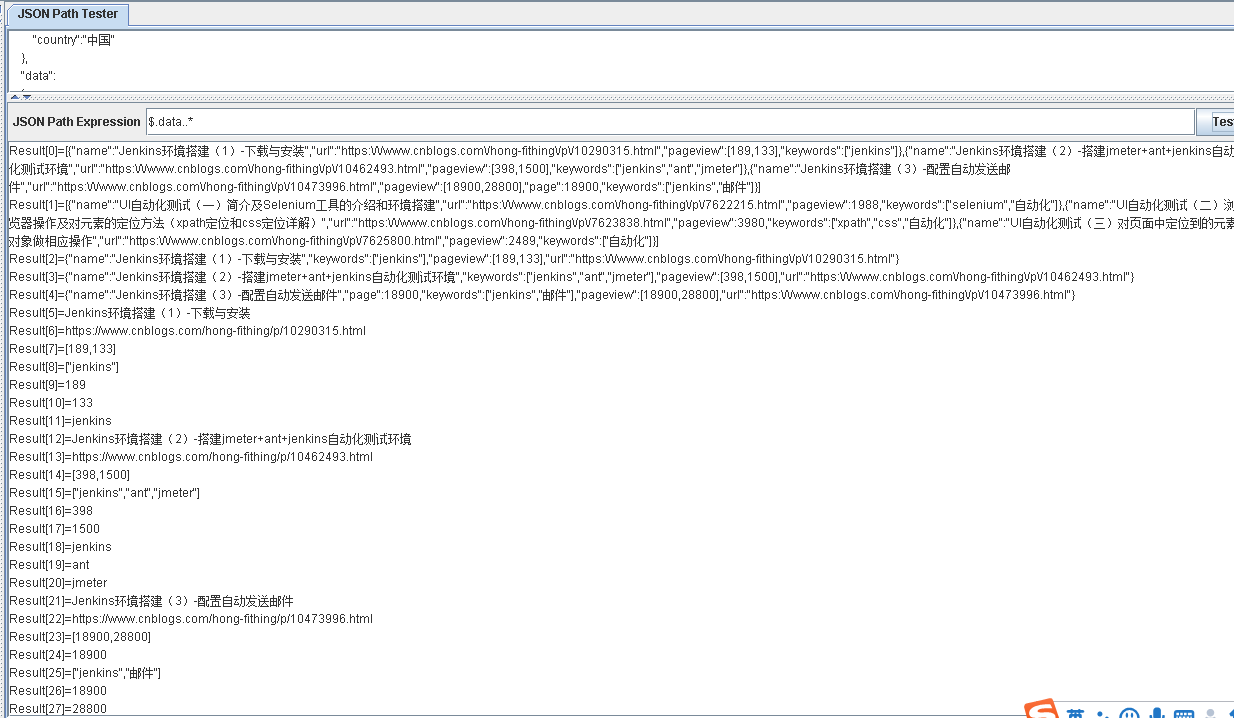
$.data.*
$.data..*
.* 表示获取data节点下的所有子节点
..* 表示获取data节点下所有符合条件的所有节点
如下图所示:
3.过滤表达式
表达式是用于数组节点的过滤处理,用来找到符合要求的节点,因为json是无序的,格式为:[?(表达式)]
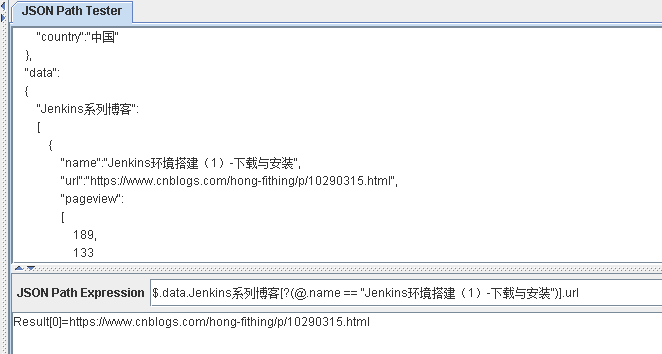
$.data.Jenkins系列博客[?(@.name == "Jenkins环境搭建(1)-下载与安装")].url
这个表达式可用sql来表达为:
select url from Jenkins系列博客 where name='Jenkins环境搭建(1)-下载与安装'
同样的取值,只是写法不一样而已
4.表达式操作
==、!= < <= > >=
=~ 正则匹配
in 存在于
nin 不存在于
subsetof 子集 || 或者
&& 并且
示例如下:
$.data.Jenkins系列博客[?(@.pageview > )]
$.data.Jenkins系列博客[?(@.name != "Jenkins环境搭建(1)-下载与安装")].pageview
$.data.Jenkins系列博客[?(@.pageview in [])]
如上简单表达式,就无须过多解释了,一看就明白。
来个正则匹配示例:
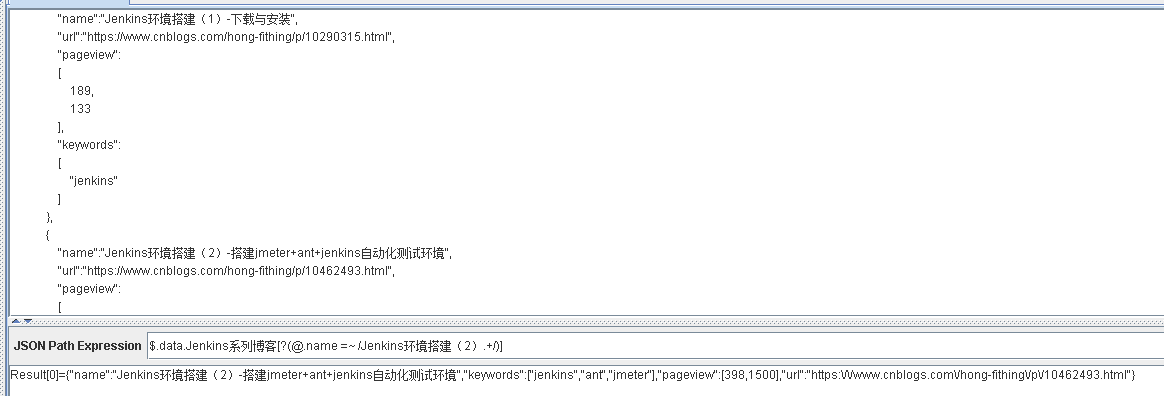
$.data.Jenkins系列博客[?(@.name =~ /Jenkins环境搭建(2).+/)]
表示从 Jenkins系列博客 获取 name 为Jenkins环境搭建(2)开头的元素
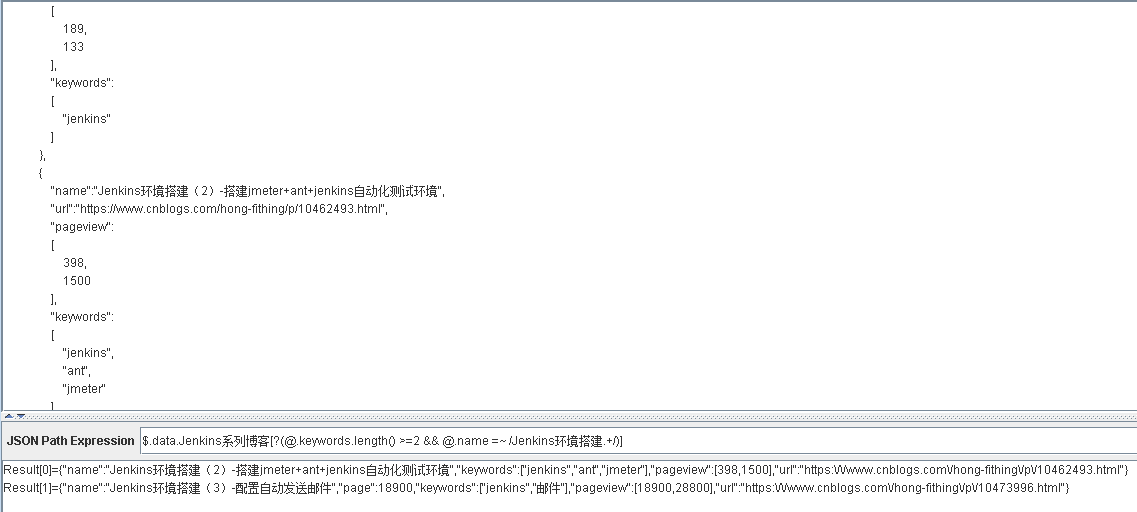
$.data.Jenkins系列博客[?(@.keywords.length() >= && @.name =~ /Jenkins环境搭建.+/)]
表示从 Jenkins系列博客 获取 keywords大于等于2 并且 name 为Jenkins环境搭建开头的元素
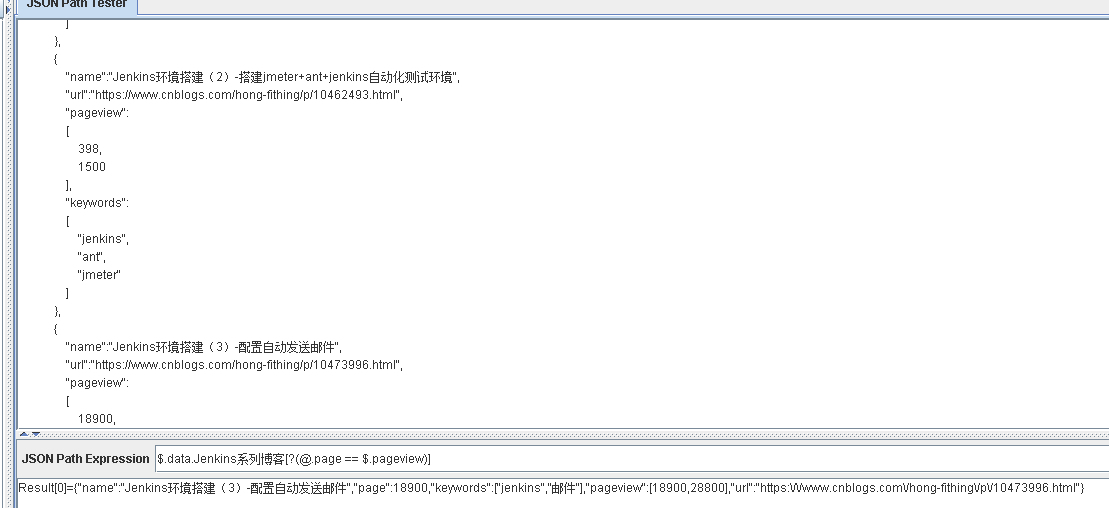
$.data.Jenkins系列博客[?(@.page == $.pageview)]
表示从 Jenkins系列博客 获取 page == 根节点下的pageview 的元素
再来讲个获取子集的表达式
$.data.Jenkins系列博客[?(@.keywords subsetof ["jmeter","jenkins","ant","邮件"])]
表示从 Jenkins系列博客 数组中,获取keywords为 jmeter jenkins ant 邮件 四者的子集的元素
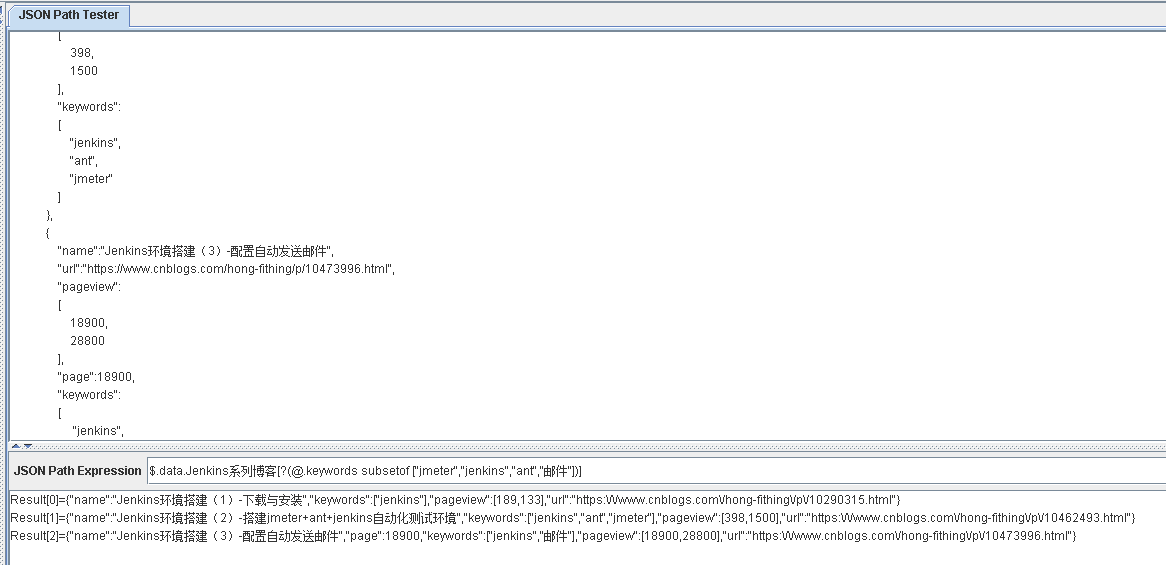
修改表达式如下:
$.data.Jenkins系列博客[?(@.keywords subsetof ["jenkins","邮件","ant"])]
获取到的值如下:

jmeter中的JSON Extractor就介绍到这了,都是些很基础的使用方式,希望对需要的人有所帮助。
Jmeter元件——JSON Extractor后置处理器介绍2的更多相关文章
- Jmeter元件——JSON Extractor后置处理器
场景使用 json extractor后置处理器用在返回格式为json的HTTP请求中,用来获取返回的json中的某个值.并保存成变量供后面的请求进行调用或断言等. 使用方法 1.常规操作 路径:选择 ...
- jmeter数据关联_后置处理器_正则表达式提取器
- Spring之BeanPostProcessor(后置处理器)介绍
为了弄清楚Spring框架,我们需要分别弄清楚相关核心接口的作用,本文来介绍下BeanPostProcessor接口 BeanPostProcessor 该接口我们也叫后置处理器,作用是在Be ...
- 获取响应数据___JSON Extractor 后置处理器
对于大部分请求返回的结果,都是json,有一个更方便使用的插件:JSON Extractor 不过得首先下载插件 https://jmeter-plugins.org/wiki/JSONPathExt ...
- Jmeter --Json Extractor (后置处理器)
一.使用场景 Json Extractor 后置处理器用在返回格式为json的HTTP请求中, 用来获取返回的json中的某个值.并保存成变量供后面的请求进行调用或者断言等. 二.使用方法 1.创建H ...
- Jmeter 后置处理器
1.JSON Extractor Json extractor 后置处理器用在返回格式为 Json 的 HTTP 请求中,用来获取返回的 Json 中的某个值.并保存成变量供后面的请求进行调用或断言等 ...
- Jmeter 后置处理器--jp@gc - JSON/YAML Path Extractor & JSON Extractor
后置处理器--jp@gc - JSON/YAML Path Extractor 1.需要下载插件,地址: 解压后把对应jar包放置对应的lib和lib/ext目录下,重启Jmeter: 2.在需要提取 ...
- 通过JMETER后置处理器JSON Path Extractor插件来获取响应结果
学生金币充值接口:该接口有权限验证,需要admin用户才可以做操作,需要添加cookie.cookie中key为登录的用户名,value从登录接口中获取,登陆成功之后会返回sign. 通常做法是在HT ...
- jmeter后置处理器 JSON Extractor取多个变量值
1.需要获取响应数据的请求右键添加-后置处理器-JSON Extractor 2.如果要获取json响应数据多个值时,设置的Variable names (后续引用变量值的变量名设置)与JSON Pa ...
随机推荐
- python GUI编程tkinter示例之目录树遍历工具
摘录 python核心编程 本节我们将展示一个中级的tkinter应用实例,这个应用是一个目录树遍历工具:它会从当前目录开始,提供一个文件列表,双击列表中任意的其他目录,就会使得工具切换到新目录中,用 ...
- python单元测试unittest、setUp、tearDown()
单元测试反应的是一种以测试为驱动的开发模式,最大的好处就是保证一个程序模块的行为符合我们设计的测试用例,在将来修改的时候,可以极大程度保证该模块行为仍然是正确的. 下面我编写一个Dict来,这个类的行 ...
- SAP B1:如何在水晶报表中插入二维码
动态二维码API接口地址:http://www.liantu.com/api.php?text=x备注: 动态网址内可自定义相应的字段拼接(如图5为 [批号]+[质检员]字段) 若API接口链接失效, ...
- monkey命令解析详解
我面试时遇到过几次让背个monkey命令的,可以这样简单说一个:adb shell monkey -p(约束包名) -s 200 -v -v --throttle 300 1500000 > ...
- React: 通过React.Children访问特定子组件
一.简介 React中提供了很多常用的API,其中有一个React.Children可以用来访问特定组件的子元素.它允许用来统计个数.map映射.循环遍历.转换数组以及显示指定子元素,如下所示: va ...
- 用Python在25行以下代码实现人脸识别
在本文中,我们将看到一种使用Python和开放源码库开始人脸识别的非常简单的方法. OpenCV OpenCV是最流行的计算机视觉库.最初是用C/C++编写的,现在它提供了Python的API. Op ...
- Redux学习及应用
Redux学习及应用 一:Redux的来源? Redux 是 JavaScript 状态容器,提供可预测化的状态管理.Redux是由 Flux 演变而来,但受 Elm 的启发,避开了 Flux 的复杂 ...
- 设置tomcat为自动启动
第一步:设置tomcat为服务启动项 进入dos窗口,输入service.bat install,启动服务, 这里要注意的是,如果直接在cmd输入报错,需要你进入到tomcat的目录下执行cmd 第二 ...
- How to: Implement File Data Properties 如何:实现文件数据属性
This topic demonstrates how to implement a business class with a file data property and a file colle ...
- Git实战指南----跟着haibiscuit学Git(第十一篇)
笔名: haibiscuit 博客园: https://www.cnblogs.com/haibiscuit/ Git地址: https://github.com/haibiscuit?tab=re ...