哈希算法原理【Java实现】(十)
前言
在入学时,学校为我们每位童鞋建立一个档案信息,当然每个档案信息都对应档案编号,还有比如在学校图书馆,图书馆为每本书都编了唯一的一个书籍号,那么问题来了,当我们需要通过档案号快速查到对应档案信息或者通过书记号快速查到对应书籍,这个时候我们可以通过哪种数据结构呢?前面几节我们详细讲解了ArrayList和LinkedList,我们知道ArrayList底层就是一维数组,但是我们事先不知道在数组中的索引,此时查询到对应档案编号或书籍号需要循环遍历,这个时候时间复杂度肯定不是O(1),即使我们知道索引但是若索引键很大此时不再适合作为数组的索引,若通过LinkedList双向链表查询,通过我们的分析肯定也不是O(1),这个时候就需要用到哈希算法则获取的时间复杂度为恒定时间O(1)。我们习惯称之为哈希,实际叫作散列,散列是一种用于从一组相似对象中唯一标识特定对象的技术。
散列
在散列中,通过使用散列函数将大键转换为小键,然后将这些值存储在称为哈希表的数据结构中。散列的基本思路是在数组中统一分配条目(键/值对),为每个元素分配一个键(转换键),通过键查找,我们可以在O(1)时间内访问到对应元素。使用散列函数计算到一个索引,该索引建议可以找到或插入元素的位置。散列分如下两步执行:通过使用散列函数将元素转换为整数。此元素可用作存储原始元素的索引,该元素属于哈希表。该元素存储在哈希表中,可以使用散列键快速检索它。
hash = hashfunc(key)
index = hash%array_size
上述最重要的是通过散列函数获取键的散列值,然后将得到的散列值对数组大小去模即存放到哈希表中的索引地址。到在此方法中,散列与数组大小无关,然后通过使用模运算符(%)将其缩减为索引(介于0和array_size之间的数字 - 1)。要实现良好的散列机制,具有以下基本要求的良好散列函数非常重要:
易于计算:它应该易于计算,并且不能成为算法本身(不是为了算法而算法)。
统一分布:它应该在哈希表中提供统一分布,不应导致聚集。
较少的冲突:应尽量避免不同元素映射到相同的哈希值时发生的冲突。
注意:无论散列函数有多好,发生冲突是必然的,因此,为了保持哈希表的性能,通过各种冲突解决技术来管理冲突是很重要的。使用散列函数存储对象的步骤:创建一个大小为M的数组。选择一个哈希函数h,即从对象到整数0,1,...,M-1的映射。 将这些对象放入通过散列函数index = h(object)计算的索引的数组中,这种数组称为哈希表。那么我们如何选择哈希函数? 创建哈希函数的一种方法是使用Java的hashCode()方法。 hashCode()方法在Object类中实现,因此Java中的每个类都继承它。 哈希码提供了对象的数字表示,我们来看看如下代码示例:
String obj1 = String.valueOf(4);
String obj2 = String.valueOf(16);
String obj3 = String.valueOf(68);
String obj4 = String.valueOf(125);
String obj5 = String.valueOf(255); System.out.println(obj1.hashCode() % 5);
System.out.println(obj2.hashCode() % 5);
System.out.println(obj3.hashCode() % 5);
System.out.println(obj4.hashCode() % 5);
System.out.println(obj5.hashCode() % 5);

如上哈希数组大小为5,我们创建的哈希函数是使用的Java中提供给我们的hashcode方法,上图中打印出的数字即为在哈希表中的索引存放地址。此时我们发现obj4和obj1在哈希表中的存放地址一样,这个也就是我们所说的冲突。在散列中解决冲突有四种方式:(1)开放寻址法或者叫线性探测或者叫闭合散列、(2)再哈希法、(3)链地址法、(4) 建立公共溢出区。在这里呢我给大家演示常见的两种,线性探测或称为开放寻址法和链地址法,首先我们来看看开放寻址法。
散列冲突之开放寻址法
在开放式寻址中,所有条目记录都存储在数组本身中,而非链接列表中。当我们插入新的元素或条目时,首先计算散列值的哈希索引,然后检查数组(从散列索引开始)。如果散列索引地址未被占用,则将条目记录插入散列索引处地址中,否则它将以某个探测序列继续进行,直到找到未占用的地址。探测序列是遍历条目时遵循的序列。在不同的探测序列中,连续的入口槽或探针之间可以有不同的间隔。搜索条目时,将以相同的顺序扫描阵列,直到找到目标元素或找到未使用的地址,这也就表明哈希表中没有这样的键,名为“开放寻址”指的是元素地址不是由其散列值所确定。线性探测是指连续探测之间的间隔固定(通常为1)。假设特定条目的散列索引是索引。线性探测的探测序列将是:
index = index % hashTableSize
index = (index + 1) % hashTableSize
index = (index + 2) % hashTableSize
index = (index + 3) % hashTableSize
.......
如上意思表明当指定键的哈希值已被占用,则将哈希值以间隔为1进行递增,如此一次递增直到找到未被占用的索引存放地址,代码如下:
public class HashTable {
//数组容量
private int capacity;
//哈希键值对数组
private Entry[] entries = {};
public HashTable(int capacity) {
this.capacity = capacity;
entries = new Entry[this.capacity];
}
//添加键值对
public void put(String key, String value) {
final Entry hashEntry = new Entry(key, value);
int hash = getHash(key);
entries[hash] = hashEntry;
}
//获取键哈希值
private int getHash(String key) {
int hashCode = key.hashCode();
int hash = hashCode % capacity;
while (entries[hash] != null) {
hashCode += 1;
hash = hashCode % capacity;
}
return hash;
}
//获取指定键值
public String get(String key) {
int hashCode = key.hashCode();
int hash = hashCode % capacity;
if (entries[hash] != null) {
while (!entries[hash].key.equals(key))
{
hashCode += 1;
hash = hashCode % capacity;
}
return entries[hash].value;
}
return null;
}
private class Entry {
String key;
String value;
public Entry(String key, String value) {
this.key = key;
this.value = value;
}
}
}
我们在控制台将如上测试数据添加到我们自定义的哈希表类中,然后去查询对应键的值,如下:
public class Main {
public static void main(String[] args) {
HashTable table = new HashTable(5);
table.put(String.valueOf(4), String.valueOf(4));
table.put(String.valueOf(16), String.valueOf(16));
table.put(String.valueOf(68), String.valueOf(68));
table.put(String.valueOf(125), String.valueOf(125));
table.put(String.valueOf(255), String.valueOf(255));
System.out.println(table.get(String.valueOf(4)));
System.out.println(table.get(String.valueOf(125)));
}
}

散列冲突之链地址法
我们通过使用单链表来实现链地址法,链地址法是最常用的冲突解决技术之一,在单链表中,哈希表的每个元素都是链表,要想在哈希表中存储元素,必须将其插入特定的链表。如果存在任何冲突(即两个不同的元素具有相同的散列值),则将这两个元素存储在同一链表中,查找的成本是扫描所选链表的条目以获得所需的键,如果键的分布足够均匀,则查找的平均成本仅取决于每个链表的平均键数。对于链地址法,最坏的情况是所有条目都插入到同一个链表中。查找过程可能必须扫描其所有条目,因此最坏情况放入成本与表中条目的数量(N)成比例,链地址法存在哈希表中如下示意图:
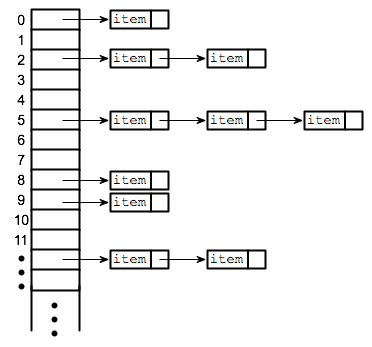
在开头我们所给的例子,键16和125的哈希值相同则我们会将其存放到同一链表中,接下来我们通过示例代码来实现链地址法,如下:
public class HashTable {
//数组容量
private int capacity;
//哈希键值对数组
private Entry[] entries = {};
public HashTable(int capacity) {
this.capacity = capacity;
entries = new Entry[this.capacity];
}
//添加键值对
public void put(String key, String value) {
//获取键哈希值
int hash = getHash(key);
//实例化类存放键和值
final Entry hashEntry = new Entry(key, value);
//如果在数组中未有冲突的键则直接存放
if(entries[hash] == null) {
entries[hash] = hashEntry;
}
//如果找到冲突的哈希值则存放到单链表中的下一引用
else {
Entry temp = entries[hash];
while(temp.next != null) {
temp = temp.next;
}
temp.next = hashEntry;
}
}
//获取键哈希值
private int getHash(String key) {
return key.hashCode() % capacity;
}
//获取指定键值
public String get(String key) {
int hash = getHash(key);
if(entries[hash] != null) {
Entry temp = entries[hash];
while( !temp.key.equals(key)
&& temp.next != null ) {
temp = temp.next;
}
return temp.value;
}
return null;
}
private class Entry {
String key;
String value;
Entry next;
public Entry(String key, String value) {
this.key = key;
this.value = value;
this.next = null;
}
}
}
控制台代码和演示开放寻址法一样且打印出的结果也一致,这里就不再给出。到这里我们实现了散列算法以及散列算法中解决冲突最常用的技术:开放寻址法和链地址法。
总结
本节我们还是一如既往先了解对应概念的算法实现为我们下一节详细分析Hashtable做铺垫,好了,本节内容我们到此为止,感谢您的阅读,我们下节见。
哈希算法原理【Java实现】(十)的更多相关文章
- 一致性哈希算法原理及Java实现
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简 单 ...
- 一致性哈希算法原理、避免数据热点方法及Java实现
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简 单 ...
- 感知哈希算法的java实现
一.原理讲解 实现这种功能的关键技术叫做"感知哈希算法"(Perceptual Hash Algorithm), 意思是为图片生成一个指纹(字符串格式), 两张图片的指纹 ...
- Java_一致性哈希算法与Java实现
摘自:http://blog.csdn.net/wuhuan_wp/article/details/7010071 一致性哈希算法是分布式系统中常用的算法.比如,一个分布式的存储系统,要将数据存储到具 ...
- 一致性哈希算法与Java实现
原文:http://blog.csdn.net/wuhuan_wp/article/details/7010071 一致性哈希算法是分布式系统中常用的算法.比如,一个分布式的存储系统,要将数据存储到具 ...
- 负载均衡-基础-一致性哈希算法及java实现
一致性hash算法,参考: http://www.blogjava.net/hello-yun/archive/2012/10/10/389289.html 针对这篇文章,加入了自己的理解,在原有的代 ...
- 一致性哈希算法(consistent hashing)(转)
原文链接:每天进步一点点——五分钟理解一致性哈希算法(consistent hashing) 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网 ...
- 对一致性Hash算法,Java代码实现的深入研究(转)
转载:http://www.cnblogs.com/xrq730/p/5186728.html 一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读 ...
- 白话解析:一致性哈希算法 consistent hashing【转】
学习一致性哈希算法原理的时候看到博主朱双印的一片文章,看完就懂,大佬! 白话解析:一致性哈希算法 consistent hashing
随机推荐
- Unity各平台宏定义
属性 方法 UNITY_EDITOR #define directive for calling Unity Editor scripts from your game code. UNITY_EDI ...
- hdu 5532 Almost Sorted Array (水题)
Almost Sorted Array Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Ot ...
- 使用mongoshake进行oplog同步读取,解决乱码问题
mongoshake 是个开源的用户mongo数据迁移和同步的工具,支持往各种目标源头写数据 具体:https://github.com/alibaba/MongoShake 有业务场景想把oplog ...
- [ASP.NET Core 3框架揭秘] 依赖注入[7]:服务消费
包含服务注册信息的IServiceCollection集合最终被用来创建作为依赖注入容器的IServiceProvider对象.当需要消费某个服务实例的时候,我们只需要指定服务类型调用IService ...
- github克隆项目缓慢
github浏览或者克隆项目的时候,总是十分缓慢,下面是亲自自测的一种方式,克隆速度可以稍快一些 第一步 访问域名解析网站:https://www.ipaddress.com/ 在网页下方可以看见一个 ...
- keras图片数据增强ImageDataGenerator
datagen = ImageDataGenerator( rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shea ...
- OLTP
On-Line Transaction Processing,联机事务处理过程(OLTP),也称为面向交易的处理过程 其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出 ...
- 阿里云服务器搭建web项目小结
前言 最近恰好有时间,自己搞了个云服务器试着搭建了个网站,遇到了一些问题,通过踩坑也涨了一些经验,遂记录一二,与后来者分享. 正文 1.博主用的阿里云服务器,为什么用它呢?一个是恰逢双十一,有优惠:另 ...
- Ajax之处理不同格式的JSON数据
JSON是一种网络中的数据格式,主要用于网络间的数据传输,它比XML格式的数据传输速度快,使用更广. 1.Ajax处理对象格式的JSON数据: <script src="../JS/j ...
- Java连接MySQL数据库及简单的增删查改操作
主要摘自 https://www.cnblogs.com/town123/p/8336244.html https://www.runoob.com/java/java-mysql-connect.h ...