【Python3爬虫】我爬取了七万条弹幕,看看RNG和SKT打得怎么样
一、写在前面
直播行业已经火热几年了,几个大平台也有了各自独特的“弹幕文化”,不过现在很多平台直播比赛时的弹幕都基本没法看的,主要是因为网络上的喷子还是挺多的,尤其是在观看比赛的时候,很多弹幕不是喷选手就是喷战队,如果看了这种弹幕,真是让比赛减分不少。

但和别的平台比起来,B 站的弹幕会好一些。正好现在是英雄联盟的世界总决赛时间,也有不少人选择在 B 站看比赛直播,那么大家在看直播的时候会发什么弹幕呢?话不多说,这就用 Python 写个爬虫来爬取 B 站直播时的弹幕吧!
二、爬取分析
首先打开 Bilibili,然后找到英雄联盟比赛的直播间:

我得到的直播间的链接为:https://live.bilibili.com/6?broadcast_type=0&visit_id=8abcmywu95s0#/,这个链接中的 broadcast_type 和 visit_id 是随机生成的,不过对我们的爬取也没影响,只要找到直播间的链接就好了。
打开开发者工具,切换到 NetWork,点选上 XHR,在其中能找到一个请求:https://api.live.bilibili.com/ajax/msg。这个请求需要四个参数(roomid,csrf_token,csrf,visit_id),其中 roomid 为直播间的 id,csrf_token 和 csrf 可以从浏览器上 copy,visit_id 为空。该请求返回的结果中包含十条弹幕信息,包括弹幕内容、弹幕发送人昵称等等。所以要获得更多弹幕内容,我们只需要一直发送这个请求就 OK 了!
三、爬取实现
通过前面的分析可以发现要爬取 B 站直播弹幕还是很轻松的,但是要得到大量弹幕可能就需要考虑使用多线程了。对于爬取到的弹幕,还要及时地保存下来,这里我选择使用 MongoDB 数据库来保存弹幕信息。在爬取直播弹幕的时候,我开了四个线程来爬取,开了两个线程来解析和保存数据,线程之间使用队列来处理数据。
这里建了两个类 CrawlThread 和 ParseThread,CrawThread 是用于爬取弹幕的线程,ParseThread 是用于解析和保存弹幕的线程,两个类都继承了 threading.Thread,并重写了 run() 方法。下面是爬取弹幕的代码内容:
class CrawlThread(threading.Thread):
def __init__(self, url: str, name: str, data_queue: Queue):
"""
initial function
:param url: room url
:param name: thread name
:param data_queue: data queue
"""
super(CrawlThread, self).__init__()
self.room_url = url
self.room_id = re.findall(r"/(\d+)\?", url)[0]
self.headers = {
"Accept": "application/json, text/plain, */*",
"Content-Type": "application/x-www-form-urlencoded",
"Origin": "https://live.bilibili.com",
"Referer": "",
"Sec-Fetch-Mode": "cors",
"UserAgent": get_random_ua()
}
self.name = name
self.data_queue = data_queue def run(self):
"""
send request and receive response
:return:
"""
while 1:
try:
time.sleep(1)
msg_url = "https://api.live.bilibili.com/ajax/msg"
# set referer
self.headers["Referer"] = self.room_url
# set data
data = {
"roomid": self.room_id,
"csrf_token": "e7433feb8e629e50c8c316aa52e78cb2",
"csrf": "e7433feb8e629e50c8c316aa52e78cb2",
"visit_id": ""
}
res = requests.post(msg_url, headers=self.headers, data=data)
self.data_queue.put(res.json()["data"]["room"])
except Exception as e:
logging.error(self.name, e)
下面是解析和保存弹幕的代码内容,主要是一直查询队列,如果队列中有数据,就取出来进行解析和保存:
class ParseThread(threading.Thread):
def __init__(self, url: str, name: str, data_queue: Queue):
"""
initial function
:param url: room url
:param name: thread name
:param data_queue: data queue
"""
super(ParseThread, self).__init__()
self.name = name
self.data_queue = data_queue
self.room_id = re.findall(r"/(\d+)\?", url)[0]
client = pymongo.MongoClient(host=MONGO_HOST, port=MONGO_PORT)
self.col = client[MONGO_DB][MONGO_COL + self.room_id] def run(self):
"""
get data from queue
:return:
"""
while 1:
comments = self.data_queue.get()
logging.info("Comment count: {}".format(len(comments)))
self.parse(comments) def parse(self, comments):
"""
parse comment to get message
:return:
"""
for x in comments:
comment = {
"text": x["text"],
"time": x["timeline"],
"username": x["nickname"],
"user_id": x["uid"]
}
# print(comment)
self.save_msg(comment) def save_msg(self, msg: dict):
"""
save comment to MongoDB
:param msg: comment
:return:
"""
try:
self.col.insert_one(msg)
except Exception as e:
logging.info(msg)
logging.error(e)
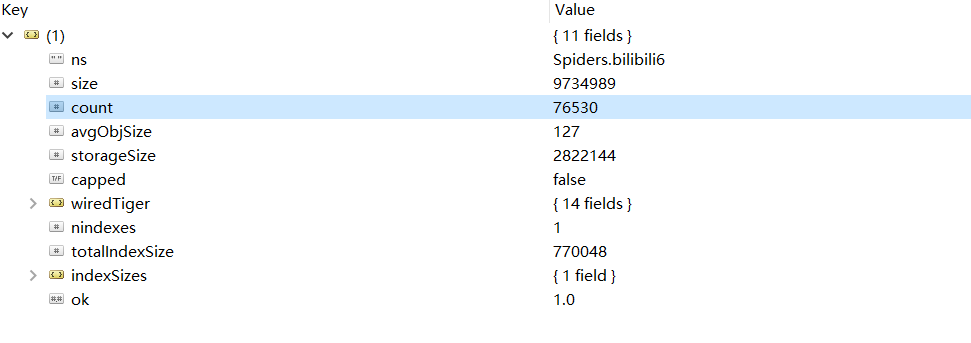
从比赛开始到比赛结束,总共爬取到了76530条弹幕,在 Robot 3T 中截图如下:
四、生成词云
弹幕信息已经存好了,但是考虑到其中有很多表情等无用内容,所以需要将这些内容给清洗掉。清洗结束之后就能够进行分词操作了,这里我选择用 jieba 库来处理,在使用 jieba 的时候,可以设置用户词典,因为像选手 ID,英雄名称这些内容是会被分词的,但设置用户词典之后就不会被分词了,设置方法如下:
jieba.load_userdict("userdict.txt")
userdict.txt 中保存了选手 ID,选手外号,英雄名称等内容,在设置了用户词典后,这些内容在分词的时候都不会被分开了。在分词结束之后,需要将那些长度为1的部分清除掉,然后将出现频次高的内容提取出来,这里用到了 collecttions 中的 Counter,利用 Counter 可以很方便地统计频次。这一部分代码内容如下:
def get_words(txt: str) -> str:
"""
use jieba to cut words
:param txt: input text
:return:
"""
# cut words
seg_list = jieba.cut(txt)
c = Counter()
# count words
for x in seg_list:
if len(x) > 1 and x != '\r\n':
c[x] += 1
result = ""
for (k, v) in c.most_common(300):
# print('%s %d' % (k, v))
result += "\n" + k
return result
在进行完上述操作之后,就可以使用 wordcloud 这个库来生成词云了,生成词云时可以设置停止词和字体,这一部分的代码如下:
def generate_word_cloud(text):
"""
generate word cloud
:param text: text
:return:
"""
# text cleaning
with open("stopwords.txt", "r", encoding='utf-8') as f:
stopwords = set(f.read().split("\n"))
wc = WordCloud(
font_path="font.ttf",
background_color="white",
width=1200,
height=800,
max_words=100,
max_font_size=200,
min_font_size=10,
stopwords=stopwords, # 设置停用词
)
# generate word cloud
wc.generate("".join(text))
# save as an image
wc.to_file("rng_vs_skt.png")
最终生成的词云图为:

可以看到很多人都在讨论 faker 的,李哥还是李哥啊,李哥的瑞兹也是强的不行,也有不少弹幕在说天使和加里奥的问题,不得不说,小虎小明的发挥是有问题的,此外还有一些说喷子的,看来 B 站的喷子也不少啊。
完整代码已上传到 GitHub!
【Python3爬虫】我爬取了七万条弹幕,看看RNG和SKT打得怎么样的更多相关文章
- 【Python3爬虫】爬取美女图新姿势--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- python3 爬虫之爬取安居客二手房资讯(第一版)
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author;Tsukasa import requests from bs4 import Beau ...
- Python3爬虫之爬取某一路径的所有html文件
要离线下载易百教程网站中的所有关于Python的教程,需要将Python教程的首页作为种子url:http://www.yiibai.com/python/,然后按照广度优先(广度优先,使用队列:深度 ...
- python3爬虫应用--爬取网易云音乐(两种办法)
一.需求 好久没有碰爬虫了,竟不知道从何入手.偶然看到一篇知乎的评论(https://www.zhihu.com/question/20799742/answer/99491808),一时兴起就也照葫 ...
- 这届网友实在是太有才了!用python爬取15万条《我是余欢水》弹幕
年初时我们用数据解读了几部热度高,但评分差强人意的国产剧,而最近正午阳光带着两部新剧来了,<我是余欢水>和<清平乐>,截止到目前为止,这两部剧在豆瓣分别为7.5分和7.9分,算 ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 【Python】【爬虫】爬取酷狗TOP500
好啦好啦,那我们来拉开我们的爬虫之旅吧~~~ 这一只小爬虫是爬取酷狗TOP500的,使用的爬取手法简单粗暴,目的是帮大家初步窥探爬虫长啥样,后期会慢慢变得健壮起来的. 环境配置 在此之前需要下载一个谷 ...
- scrapy-redis实现爬虫分布式爬取分析与实现
本文链接:http://blog.csdn.net/u012150179/article/details/38091411 一 scrapy-redis实现分布式爬取分析 所谓的scrapy-redi ...
随机推荐
- Linux中新建用户用不了sudo命令问题:rootr is not in the sudoers file.This incident will be reported解决
参考:https://blog.csdn.net/lichangzai/article/details/39501025 如果执行sudo命令的用户没有执行sudo的权限,执行sudo命令时会报下面的 ...
- xshell使用小技巧
1. 方便复制:Tool --> options --> right buttion(paste the clipboard contents) and copy selected te ...
- 解决在Filter中读取Request中的流后,后续controller或restful接口中无法获取流的问题
首先我们来描述一下在开发中遇到的问题,场景如下: 比如我们要拦截所有请求,获取请求中的某个参数,进行相应的逻辑处理:比如我要获取所有请求中的公共参数 token,clientVersion等等:这个时 ...
- Linux 笔记 - 第十二章 Shell 脚本
博客地址:http://www.moonxy.com 一.前言 常见的编程语言分为两类:一类是编译型语言,如:C.C++ 和 Java等,它们远行前要经过编译器的编译.另一类是解释型语言,不需要编译, ...
- mybatis源码专题(1)--------复习jdbc操作,编译mybatis源码,准备为你的简历加分吧
本文是作者原创,版权归作者所有.若要转载,请注明出处.文章中若有错误和疏漏之处,还请各位大佬不吝指出,谢谢大家. 1.mybatis的底层是jdbc操作,我们来回顾一下,如下 运行以后的结果如下图: ...
- Day3 目录结构及文件管理
Windows:以多根的方式组织文件C : D: E: F: linux:以单根的方式组织文件 / 2.存放命令相关的目录 /bin 普通用户的使用的命令 /bin /ls ,/bin/da ...
- cocos 微信小游戏切后台卡住
1.cocos 安装目录下搜索以下代码并注掉opts["preserveDrawingBuffer"] = true;”2.CocosCreator\resources\engin ...
- JQuery发送ajax请求时中文乱码
先排除项目故障: 1.web.xml中是否配置了字符拦截器 <filter> <filter-name>encodingFilter</filter-name> & ...
- C#深入学习笔记 - 可空类型与构造函数默认参数
在实际开发中或许可能会遇到某个属性需要提供一个默认参数,如果该参数是引用类型的话,可以通过 使用 null 来表示未知的值,但如果是int或 其他值类型的话就有点不好办了,因为如果需要一个int或fl ...
- 从 Int 到 Integer 对象,细细品来还是有不少东西
int 是 Java 八大原始类型之一,是 Java 语言中为数不多不是对象的东西,Integer 是 int 的包装类,里面使用了一个 int 类型的变量来存储数据,提供了一些整数之间的常用操作,常 ...