论文阅读 Prefetch-aware fingerprint cache management for data deduplication systems
论文链接 https://link.springer.com/article/10.1007/s11704-017-7119-0
这篇论文试图解决的问题是在cache 环节之前,prefetch-cache 进来的可能无关的 fingerprint 造成的cache pollution问题,即可能把没有用的 fingerprint 换入 cache,造成 cache 污染的问题。
这篇论文的贡献:提出了一种新的针对 prefetch 进来的 fingerprint 替换策略,并且提出了一种 adaptive 的方法,针对不同的 fingerprint 有与其对应的替换策略,提高了 deduplication throughput 和 deduplication ratio. 本文并不是试图提出一种新的对 fingerprint 如何进行 prefetch 的方法,而是针对不同种类的,已经做过了 prefetch 操作的 fingerprint,针对他们不同的种类,做不同的replacement。同时,这种 replacement policy 并不和 LRU 等 policy 相冲突,反而可以和之前的 LRU policy 相结合。
具体方法框架如图所示:
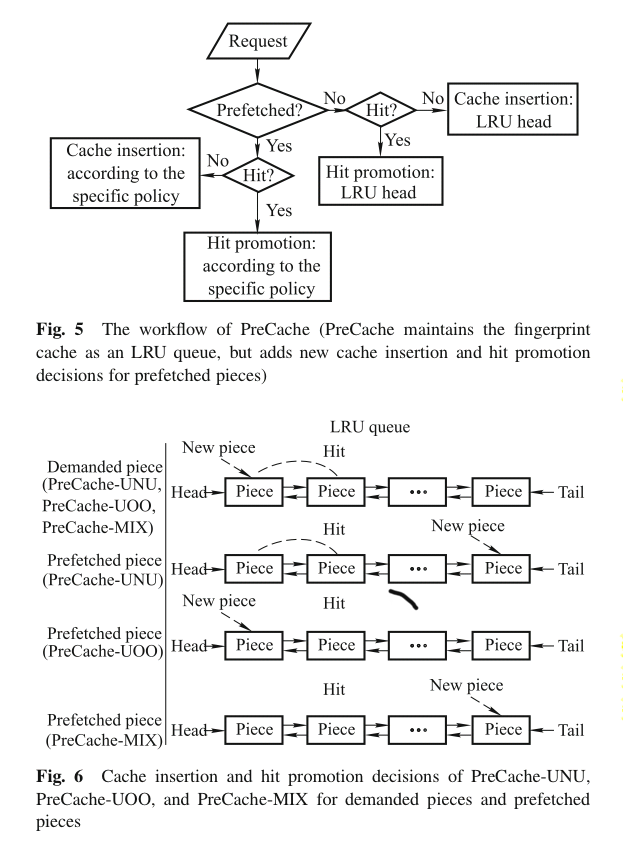
细节:针对一个被 prefetch 的 fingerprint 分为了两大类,一类是 accurate 的fingerprint,一类是 inaccurate 的fingerprint。accurate 的 fingerprint 是说那些prefetch 进 cache 之后,hit 了超过不止一次的 fingerprint,反之则是 inaccurate。对于 inaccurate fingerprint 又可以划分为不同的种类,有 Unused prefetched fingerprint,used only once fingerprint,mixed pattern fingerprint,针对这三种不同的 fingerprint,提出了不同的替换策略,分别是 PreCache-UNU, PreCache-UOO,PreCache-MIX。不同的替换策略都有不同的假设,自然也有不同的操作。
PreCache-UNU 预测所有新被 prefetch 的 fingerprint 都不会被用到(distant future)所以应该直接要被 LRU 算法替换出去(evicted quickly)针对这些 fingerprint,采用的方法是把他们直接移动到 LRU queue 的尾端,这样当 LRU 进行替换的时候,他们就是第一批被替换出去的 fingerprint。如果这些被认为是 UNU 的fingerprint 被使用了(即这个时候我们错误的划分了 fingerprint)那么根据 LRU 的规则他们也会被放到 head 端,这就是没有直接把这些 fingerprint 剔除的原因。
PreCache-UOO 预测所有的新的被 prefetch 的 fingerprint 只会被使用一次,然后就不会被使用。所以,他把这些 fingerprint 放在 LRU 队列的 head 端,并且当这些 fingerprint 被 hit 的时候,并不会重新调整他们的位置。(因为预测他们只会被使用一次,如果调整了他们的位置,就和传统的并无差别)。针对一些被 prefetch 进 cache,并且较长时间没有被使用,到快被替换出去的时候才被hit了一次,然后又不会被 hit 的fingerprint 而言,这种策略能够很快的将他们替换出去(因为并没有调整他们的位置)。
PreCache-MIX 给所有的 fingerprint 一个统一的策略,放在 LRU 队列的 tail 端,并且即使命中也不会调整位置。
同时,还存在一个问题,针对一个 fingerprint,如何把它进行分类,如何去选择一个适合他的替换策略。提出了一种动态适应的选择器,可以根据预测的历史结果,动态选择合适的策略去替换不同的 fingerprint。
选择器的功能:针对一个 fingerprint,去预测这个 fingerprint 是属于 accurate 还是 inaccurate 的,如果是 inaccurate 的,那么是 UNU 的,还是 UOO 的,还是 MIX 的。
选择器维护了几个计数器:
- total 记录了所有被 prefetch 的 fingerprint 个数。
- use_over_once,记录了cache中所有被 hit 超过一次的 fingerprint 的个数
- unused,记录了被 prefetch 的,但是没有被使用的 fingerprint 的个数。
- Use_only_once 记录了只被使用过一次的 fingerprint 的个数。
- hit_evice_buf 记录了一个main cache miss 在 evicted 中被 hit 的个数。
选择器主要的 idea:根据历史信息来预测。
每个种类都有一个对应的判别阈值和公式去决定这个 prefetch 的 fingerprint 是否是对应的种类。
效果评估:
在 BLC 和 SiLO 这两个系统的基础上加入了 PreCache 算法,使用的数据是 Kernel,MacOS 和 Homes 三种。BLC 系统代表的是 exact deduplication 系统,SiLO 系统代表的是 near exact deduplication 系统,针对两个不同的系统,采取的评价指标也不一样。BLC 中,因为 fingerprint 无法完全被存入cache,所以使用 look up index 的次数去评价系统,而 SiLO 因为 采用的是 sample feature 的方式,所以使用 deduplication ratio 去评价系统。
论文阅读 Prefetch-aware fingerprint cache management for data deduplication systems的更多相关文章
- 论文阅读《ActiveStereoNet:End-to-End Self-Supervised Learning for Active Stereo Systems》
本文出自谷歌与普林斯顿大学研究人员之手并发表于计算机视觉顶会ECCV2018.本文首次提出了应用于主动双目立体视觉的深度学习解决方案,并引入了一种新的重构误差,采用自监督的方法来解决缺少ground ...
- 论文阅读:FlexGate: High-performance Heterogeneous Gateway in Data Centers
摘要: 大型数据中心通过边界上的网关对每个传入的数据包执行一系列的网络功能,例如,ACL被部署来阻止不合格的流量,而速率限制被用于防止供应商过度使用带宽,但是由于流量的规模巨大,给网关的设计和部署带来 ...
- [论文阅读笔记] Community aware random walk for network embedding
[论文阅读笔记] Community aware random walk for network embedding 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 先前许多算法都 ...
- [论文阅读]阿里DIN深度兴趣网络之总体解读
[论文阅读]阿里DIN深度兴趣网络之总体解读 目录 [论文阅读]阿里DIN深度兴趣网络之总体解读 0x00 摘要 0x01 论文概要 1.1 概括 1.2 文章信息 1.3 核心观点 1.4 名词解释 ...
- [论文阅读笔记] Are Meta-Paths Necessary, Revisiting Heterogeneous Graph Embeddings
[论文阅读笔记] Are Meta-Paths Necessary? Revisiting Heterogeneous Graph Embeddings 本文结构 解决问题 主要贡献 算法原理 参考文 ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
随机推荐
- GAN算法笔记
本篇文章为Goodfellow提出的GAN算法的开山之作"Generative Adversarial Nets"的学习笔记,若有错误,欢迎留言或私信指正. 1. Introduc ...
- docker服务在Mac上的启动与使用
在mac上打开安装的docker软件就可以启动docker服务了 点击顶部状态栏中鲸鱼图标会弹出操作菜单,显示着服务的状态,如下图所示: 只有在docker服务启动了之后,才可以在终端使用docker ...
- A-02 梯度下降法
目录 梯度下降法 一.梯度下降法详解 1.1 梯度 1.2 梯度下降法和梯度上升法 1.3 梯度下降 1.4 相关概念 1.4.1 步长 1.4.2 假设函数 1.4.3 目标函数 二.梯度下降法流程 ...
- LeetCode_225-Implement Stack using Queues
使用队列实现栈的操作 class MyStack { public: /** Initialize your data structure here. */ MyStack() { } /** Pus ...
- Proving Equivalences UVA - 12167
题文:https://vjudge.net/problem/UVA-12167 题解: 很明显,先要缩点.然后画一下图就会发现是入度为0的点和出度为0的点取max. 代码: #include < ...
- 最长上升子序列 LIS nlogn
给出一个 1 ∼ n (n ≤ 10^5) 的排列 P 求其最长上升子序列长度 Input 第一行一个正整数n,表示序列中整数个数: 第二行是空格隔开的n个整数组成的序列. Output 最长上升子序 ...
- [AI开发]视频结构化类应用的局限性
算法不是通用的,基于深度学习的应用系统不但做不到通用,即使对于同一类业务场景,还需要为每个场景做定制.特殊处理,这样才能有可能到达实用标准.这种局限性在计算机视觉领域的应用中表现得尤其突出,本文介绍基 ...
- 如何在Linux服务器上部署Mysql
一.安装mysql 1.通过文件上传工具,将mysql安装包上传到linux服务器上 2.卸载mariadb包,由于系统中存在mariadb包会导致mysql安装时报错mariadb-libs被mys ...
- Java反序列化漏洞总结
本文首发自https://www.secpulse.com/archives/95012.html,转载请注明出处. 前言 什么是序列化和反序列化 Java 提供了一种对象序列化的机制,该机制中,一个 ...
- python-函数相关
一.函数: 函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段. 函数能提高应用的模块性,和代码的重复利用率.你已经知道Python提供了许多内建函数,比如print(). 但你也可以自 ...