AB实验的高端玩法系列2 - 更敏感的AB实验, CUPED!
背景
AB实验可谓是互联网公司进行产品迭代增加用户粘性的大杀器。但人们对AB实验的应用往往只停留在开实验算P值,然后let it go。。。let it go 。。。
让我们把AB实验的结果简单的拆解成两个方面:
\[P(实验结果显著) = P(统计检验显著|实验有效)× P(实验有效)\]
如果你的产品改进方案本来就没啥效果当然怎么开实验都没用,但如果方案有效,请不要让 statictical Hack 浪费一个优秀的idea
如果预期实验效果比较小,有哪些基础操作来增加实验显著性呢?
通常情况下为了增加一个AB实验的显著性,有两种常见做法:增加流量或者增长实验时间。但对一些可能对用户体验产生负面影响或者成本较高的实验来说,上述两种方法都略显粗糙。
对于成熟的产品来说大多数的改动带来的提升可能都是微小的!
在数据为王的今天,我们难道不应该采用更精细化的方法来解决问题么?无论是延长实验时间还是增加流量一方面都是为了增加样本量,因为样本越多,方差越小,p值越显著,越容易检测出一些微小的改进。
因此如果能合理的通过统计方法降低方差,就可能更快,更小成本的检测到微小的效果提升
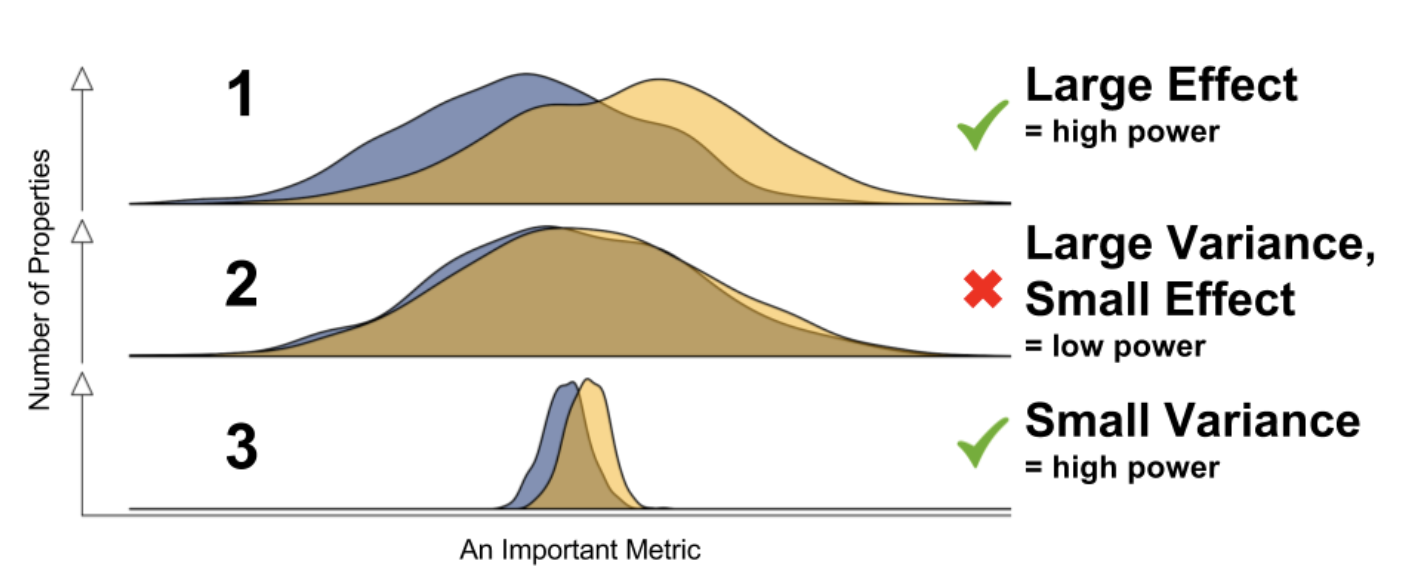
CUPED(Controlled-experiment Using Pre-Experiment Data)应运而生。 下面我会简单总结一下论文的核心方法,还有几个Bing, Netflix 以及Booking的应用案例。
论文
Deng A, Xu Y, Kohavi R, Walker T. Improving the Sensitivity of Online Controlled Experiments by Utilizing Pre-experiment Data. Proceedings of the Sixth ACM International Conference on Web Search and Data Mining. New York, NY, USA: ACM; 2013. pp. 123–132. Paper链接
核心方法总结
论文的核心在于通过实验前数据对实验核心指标进行修正,在保证无偏的情况下,得到方差更低, 更敏感的新指标,再对新指标进行统计检验(p值)。
这种方法的合理性在于,实验前核心指标的方差是已知的,且和实验本身无关的,因此合理的移除指标本身的方差不会影响估计效果。
作者给出了stratification和Covariate两种方式来修正指标,同时给出了在实际应用中可能碰到的一些问题以及解决方法.
stratifiaction
这种方式针对离散变量,一句话概括就是分组算指标。如果已知实验核心指标的方差很大,那么可以把样本分成K组,然后分组估计指标。这样分组估计的指标只保留了组内方差,从而剔除了组间方差。
\[
\begin{align}
k &= {1,2,...,K} \\
\hat{Y}_{strat} &= \sum_{k=1}^{K} w_k * (\frac{1}{n_k}*\sum_{x_i \in k} Y_i )\\
Var(\hat{Y}) &= Var_{\text{within_strat}} + Var_{\text{between_strat}}\\
&=\sum_{k=1}^K\frac{w_k}{n} \sigma_k^2 + \sum_{k=1}^K\frac{w_k}{n} (\mu_k - \mu)^2\\
&>=\sum_{k=1}^K\frac{w_k}{n} \sigma_k^2 = Var(\hat{Y}_{strat})
\end{align}
\]
Covariate
Covariate适用于连续变量。需要寻找和实验核心指标(Y)存在高相关性的另一连续特征(X),然后用该特征调整实验后的核心指标。X和Y相关性越高方差下降幅度越大。因此往往可以直接选择实验前的核心指标作为特征。只要保证特征未受到实验影响,在随机AB分组的条件下用该指标调整后的核心指标依旧是无偏的。
\[
\begin{align}
Y_i^{cov} &= Y_i - \theta(X_i - E(x))\\
\hat{Y}_{cov} &= \hat{Y} - \theta(\bar{x} - E(x))\\
\theta &= cov(X,Y)/cov(X)\\
Var(\hat{Y}_{cov}) & = Var(\hat{Y}) * (1-\theta^2)
\end{align}
\]
stratification和Covariate其实是相同的原理,从两个角度来看:
- 从回归预测的角度,实验核心指标是Y,降低Y的方差就是寻找和Y相关的自变量X来解释Y中信息的过程(提升\(R^2\)),X可以是连续也可以是离散的
- 从投资组合的角度,Y是组合中的一项资产,想要降低交易Y的风险(方差),就要做空和Y相关的X资产来对冲风险,相关性越高对冲效果越好
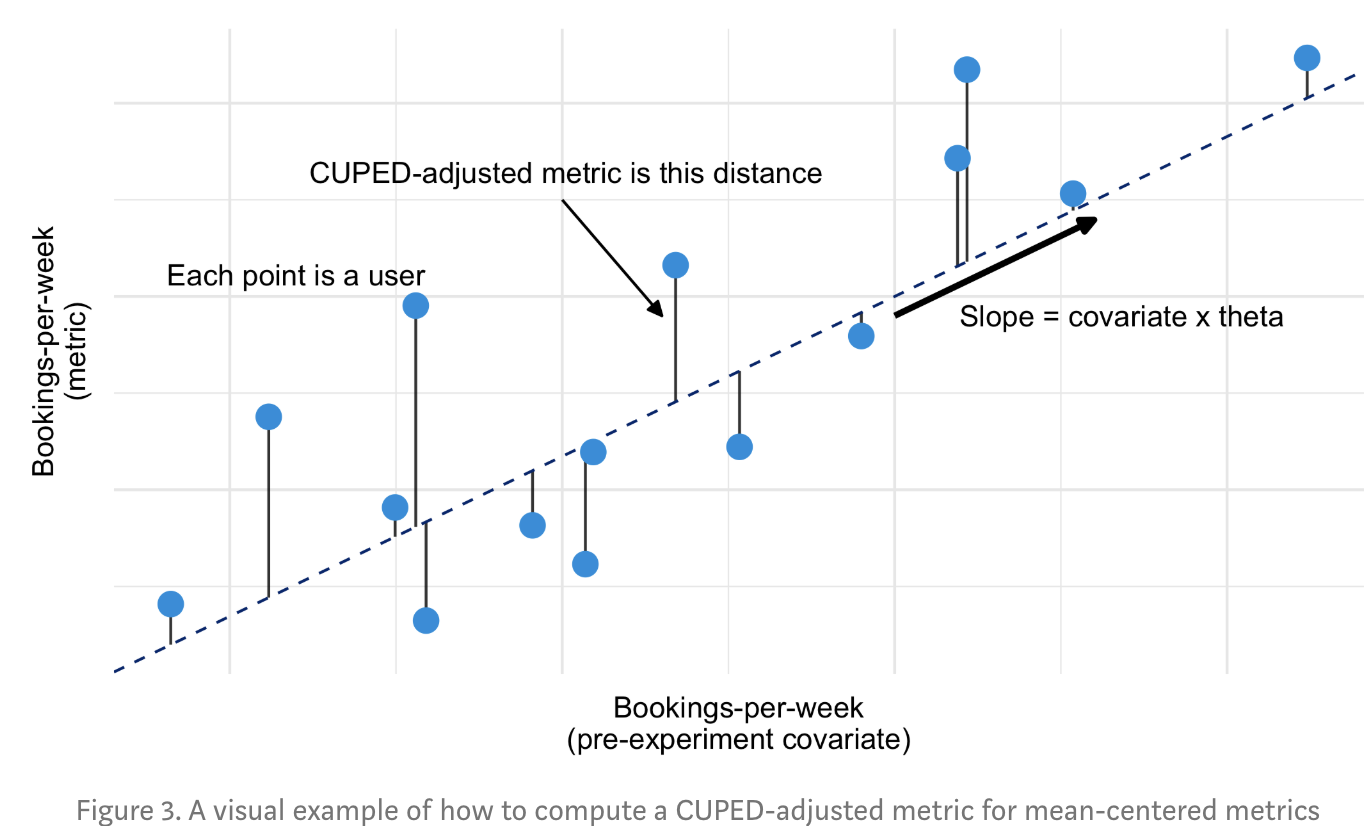
下图摘自Booking的案例,他们的核心指标是每周的房间预定量,Covariate是实验前的每周房间预定量,博客链接在案例分享里。
实战攻略
covariate的选择
这里的选择包括两个方面,特征的选择和计算特征的pre-experiment时间长度的选择。
核心指标在per-experiment的估计通常是很好的covariate的选择,且估计covariate选择的时间段相对越长效果越好。时间越长covariate的覆盖量越大,且受到短期波动的影响越小估计更稳定。
没有pre-experiment数据怎么办
这个现象在互联网中很常见,新用户或者很久不活跃的用户都会面临没有近期行为特征的问题。作者认为可以结合stratification方法对有/无covariate的用户进一步打上标签。或者其实不仅局限于pre-experiment特征,只要保证特征不受到实验影响post-experiment特征也是可以的。
而在Booking的案例中,作者选择对这部分样本不作处理,因为通常缺失值是用样本均值来填充,在上述式子中就等于是不做处理。
Attention
Covariate选择的核心是\(E(X^{treatment}) = E(X^{control})\),这一点不论你选择什么特征, 是pre-experiment还是post-experiment都要保证。
当然也有用CUPED来矫正实验组对照组差异的,但这个内容不在这里讨论。
应用案例
Bing 加载时间对用户点击率的影响
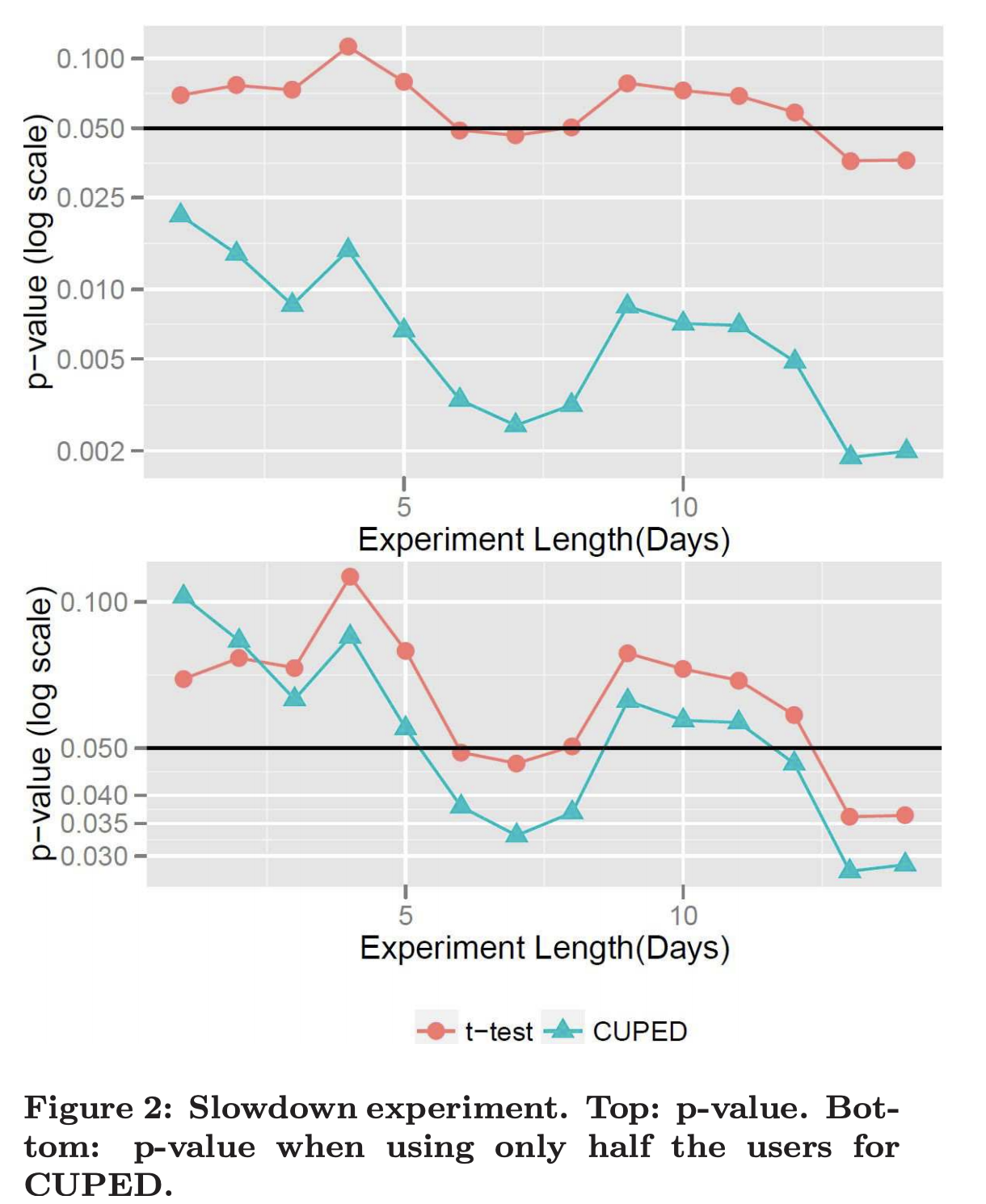
论文中作者在实际AB实验中检验了CUPED的效果。Bing实验检测检测加载时间对用户点击率的影响。 一个原本运行两周只有个别天显著的实验在用CUPED调整后在第一天就显著,当把CUPED估计用的样本减少一半后显著性依旧超过直接使用T-test.
Netflix 多种方法的实际效果对比
Netflix尝试了一种新的stratification, 上述论文中的stratification被称作post-stratification因为它只在估计实验效果时用到分组,这时用pre-experiment估计的分组概率会和随机AB分组得到的实验中的分组概率存在一定差异,所以Netflix尝试在实验前就进行分层分组。通过多个实验结果,Netflix得到以下结论:
- 大样本下,post-strat在实际中更灵活和pre-strat表现相当
- 能否成功找到和实验核心指标相关的covariate是成功的关键
Booking.com 新日历交互对用户影响
How Booking.com increases the power of online experiments with CUPED
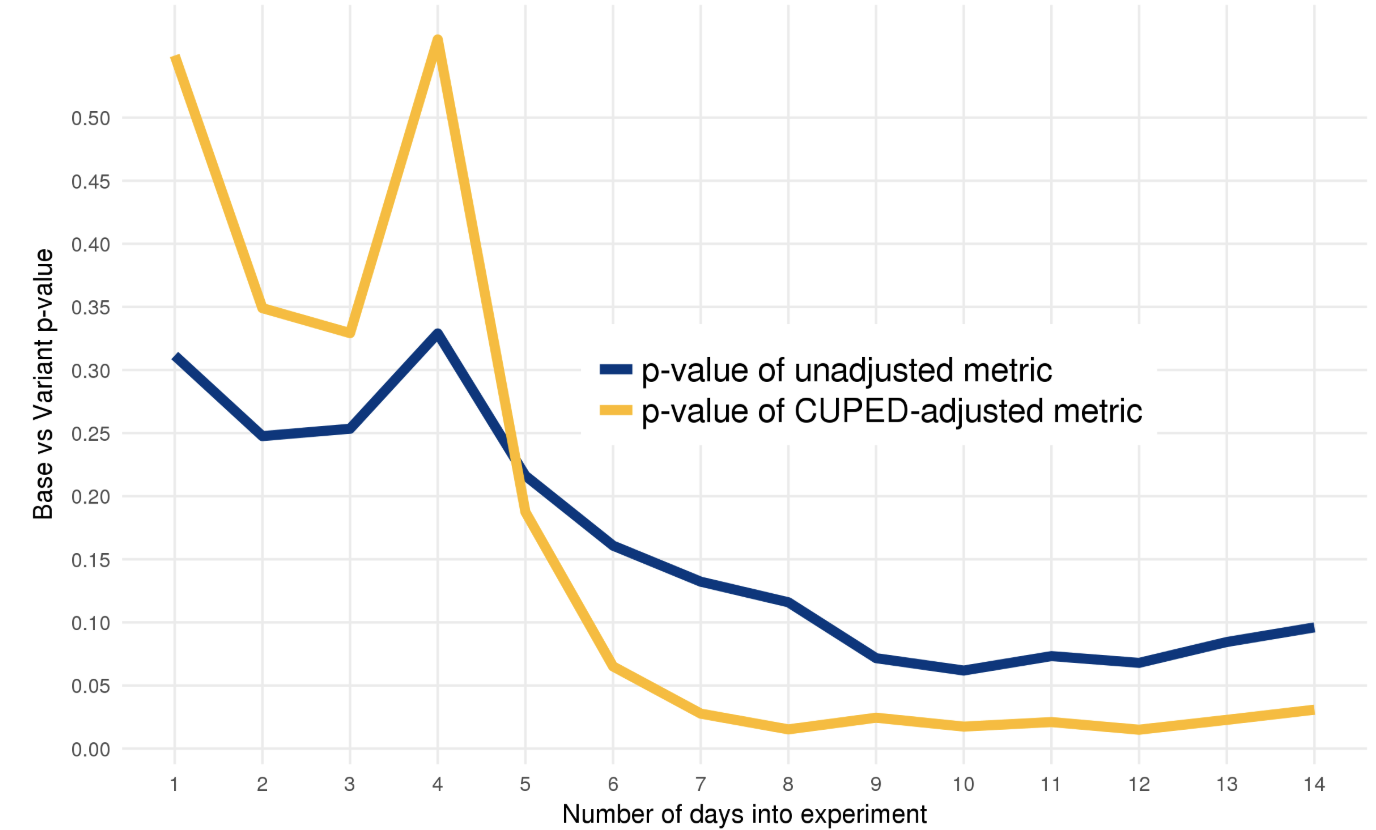
实验效果对比如下,CUPED用更少的样本更短的时间得到了显著的结果。了解细节请戳上面的博客,作者讲的非常通俗易懂。
想更多了解AB实验高端系列的朋友,戳这里呦
AB实验的高端玩法系列2 - 更敏感的AB实验, CUPED!的更多相关文章
- AB实验的高端玩法系列3 - AB组不随机?观测试验?Propensity Score
背景 都说随机是AB实验的核心,为什么随机这么重要呢?有人说因为随机所以AB组整体不存在差异,这样才能准确估计实验效果(ATE) \[ ATE = E(Y_t(1) - Y_c(0)) \] 那究竟随 ...
- AB实验的高端玩法系列4- 实验渗透低?用户未被触达?CACE/LATE
CACE全称Compiler Average Casual Effect或者Local Average Treatment Effect.在观测数据中的应用需要和Instrument Variable ...
- 第四模块MySQL50题作业,以及由作业引申出来的一些高端玩法
一.表关系 先参照如下表结构创建7张表格,并创建相关约束 班级表:class 学生表:student cid caption grade_id ...
- Word 查找替换高级玩法系列之 -- 把论文中的缩写词快速变成目录下边的注释表
1. 前言 问题:Word写论文如何把文中的缩写快速转换成注释表? 原来样子: 想要的样子: 2. 步骤 使用查找替换高级用法,替换缩写顺序 选中所有文字 打开查找替换对话框,输入以下表达式: 替换后 ...
- windows下mongodb基础玩法系列二CURD附加一
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
- windows下mongodb基础玩法系列二CURD操作(创建、更新、读取和删除)
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
- windows下mongodb基础玩法系列一介绍与安装
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
- Word 查找替换高级玩法系列之 -- 段首批量添加字符
打开「查找和替换」输入框,按照下图操作: 更多查找替换高级玩法,参看:Word查找替换高级玩法系列 -- 目录篇 未完 ...... 点击访问原文(进入后根据右侧标签,快速定位到本文)
- Hadoop大数据零基础高端实战培训系列配文本挖掘项目
随机推荐
- .NET分布式大规模计算利器-Orleans(一)
写在前面 Orleans是基于Actor模型思想的.NET领域的框架,它提供了一种直接而简单的方法来构建分布式大规模计算应用程序,而无需学习和应用复杂的并发或其他扩展模式.我在2015年下半年开始 ...
- Spring Cloud异步场景分布式事务怎样做?试试RocketMQ
一.背景 在微服务架构中,我们常常使用异步化的手段来提升系统的 吞吐量 和 解耦 上下游,而构建异步架构最常用的手段就是使用 消息队列(MQ),那异步架构怎样才能实现数据一致性呢?本文主要介绍如何使用 ...
- Docker学习之docker-compose
docker-compose 安装 1.Mac/Windows: 安装docker的时候附带安装了. 2.Linux: curl https://github.com/docker/compose L ...
- Flutter学习笔记(27)--数据共享(InheritedWidget)
如需转载,请注明出处:Flutter学习笔记(27)--数据共享(InheritedWidget) InheritedWidget是Flutter中非常重要的一个功能型组件,它提供了一种数据在widg ...
- 第六届蓝桥杯java b组第8题
乐羊羊饮料厂正在举办一次促销优惠活动.乐羊羊C型饮料,凭3个瓶盖可以再换一瓶C型饮料,并且可以一直循环下去,但不允许赊账. 请你计算一下,如果小明不浪费瓶盖,尽量地参加活动,那么,对于他初始买入的n瓶 ...
- 自定义构建基于.net core 的基础镜像
先说一个问题 首先记录一个问题,今天在用 Jenkins 构建项目的时候突然出现包源的错误: /usr/share/dotnet/sdk/2.2.104/NuGet.targets(114,5): e ...
- 【ADO.NET基础】后台获取前台控件
C# 后台获取前台 input 文本框值.string aa=Request.Form[headself]; 那么要是后台给前台input文本框赋值呢? 后台 public string Headse ...
- pikachu-数字型注入(post)#手工注入
1, 因为是post型,所以需要抓取数据包 2, 测试结果为数字型注入 提交恒等的语句可以查询到所有的数据信息 3, 使用UNION联合查询法 判断字段数,测试为2个字段时没有报错,所以可以判断字段数 ...
- Docker系列(四):容器之间的网络通信
首先我们需要知道:两个容器要能通信,必须要有属于同一个网络的网卡. 先来看下正常情况下我们的容器默认是否是能通信的,这里运行两个测试容器: docker run -it --name=bbox1 bu ...
- 创建一个自己的Vue UI组件库,并将它发布在npm上
本文仅限于入门级,没有成规模制作,希望能对你有所帮助. 因为在开发多个项目中可能会用到同一个组件,那么我们通过复制粘贴的形式更新,无异于是笨拙的,我们可以通过上传到npm后,不断迭代npm包来实现更新 ...
背景 都说随机是AB实验的核心,为什么随机这么重要呢?有人说因为随机所以AB组整体不存在差异,这样才能准确估计实验效果(ATE) \[ ATE = E(Y_t(1) - Y_c(0)) \] 那究竟随 ...
CACE全称Compiler Average Casual Effect或者Local Average Treatment Effect.在观测数据中的应用需要和Instrument Variable ...
一.表关系 先参照如下表结构创建7张表格,并创建相关约束 班级表:class 学生表:student cid caption grade_id ...
1. 前言 问题:Word写论文如何把文中的缩写快速转换成注释表? 原来样子: 想要的样子: 2. 步骤 使用查找替换高级用法,替换缩写顺序 选中所有文字 打开查找替换对话框,输入以下表达式: 替换后 ...
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
打开「查找和替换」输入框,按照下图操作: 更多查找替换高级玩法,参看:Word查找替换高级玩法系列 -- 目录篇 未完 ...... 点击访问原文(进入后根据右侧标签,快速定位到本文)
写在前面 Orleans是基于Actor模型思想的.NET领域的框架,它提供了一种直接而简单的方法来构建分布式大规模计算应用程序,而无需学习和应用复杂的并发或其他扩展模式.我在2015年下半年开始 ...
一.背景 在微服务架构中,我们常常使用异步化的手段来提升系统的 吞吐量 和 解耦 上下游,而构建异步架构最常用的手段就是使用 消息队列(MQ),那异步架构怎样才能实现数据一致性呢?本文主要介绍如何使用 ...
docker-compose 安装 1.Mac/Windows: 安装docker的时候附带安装了. 2.Linux: curl https://github.com/docker/compose L ...
如需转载,请注明出处:Flutter学习笔记(27)--数据共享(InheritedWidget) InheritedWidget是Flutter中非常重要的一个功能型组件,它提供了一种数据在widg ...
乐羊羊饮料厂正在举办一次促销优惠活动.乐羊羊C型饮料,凭3个瓶盖可以再换一瓶C型饮料,并且可以一直循环下去,但不允许赊账. 请你计算一下,如果小明不浪费瓶盖,尽量地参加活动,那么,对于他初始买入的n瓶 ...
先说一个问题 首先记录一个问题,今天在用 Jenkins 构建项目的时候突然出现包源的错误: /usr/share/dotnet/sdk/2.2.104/NuGet.targets(114,5): e ...
C# 后台获取前台 input 文本框值.string aa=Request.Form[headself]; 那么要是后台给前台input文本框赋值呢? 后台 public string Headse ...
1, 因为是post型,所以需要抓取数据包 2, 测试结果为数字型注入 提交恒等的语句可以查询到所有的数据信息 3, 使用UNION联合查询法 判断字段数,测试为2个字段时没有报错,所以可以判断字段数 ...
首先我们需要知道:两个容器要能通信,必须要有属于同一个网络的网卡. 先来看下正常情况下我们的容器默认是否是能通信的,这里运行两个测试容器: docker run -it --name=bbox1 bu ...
本文仅限于入门级,没有成规模制作,希望能对你有所帮助. 因为在开发多个项目中可能会用到同一个组件,那么我们通过复制粘贴的形式更新,无异于是笨拙的,我们可以通过上传到npm后,不断迭代npm包来实现更新 ...